面向开发者的 NVIDIA NeMo Evaluator
NVIDIA NeMo™ Evaluator 是一个可扩展的评估解决方案,用于评估生成式 AI 应用——包括大型语言模型 (LLM)、检索增强生成 (RAG) 流程和 AI 智能体。它既可作为用于实验的开源 SDK,也可作为适用于自动化、企业级工作流程的云原生微服务。NeMo Evaluator SDK 支持超过 100 个内置学术基准测试,并通过开源贡献提供了便捷的自定义指标添加流程。除学术基准外,NeMo Evaluator 微服务还提供基于 LLM 的评审评分、RAG 和智能体指标,帮助用户在不同环境中轻松评估和优化模型性能。NeMo Evaluator 是 NVIDIA NeMo™ 软件套件的一部分,该套件用于在企业级规模下构建、监控和优化 AI 智能体的全生命周期。
NVIDIA NeMo Evaluator 的主要特性
NeMo Evaluator 基于同一核心引擎构建,该引擎同时驱动开源 SDK 和企业级微服务。
SDK
一个开源 SDK,可用于以可复现性和可扩展性运行学术基准测试。该 SDK 基于 nemo-evaluator core and launcher 构建,为大型语言模型 (LLM)、嵌入模型和重排序模型的实验提供原生代码访问能力。
默认可复制:捕获配置、种子和软件出处,以获得可审计、可重复的结果。
完整的基准测试:涵盖主流评测框架和多种模态的 100 多项学术基准测试,并持续更新。
Python 原生且随时可运行:配置和容器直接在 notebook 或脚本中提供结果。
灵活且可扩展:使用 Docker 在本地运行或横向扩展至 Slurm 集群。
微服务
企业级云原生 REST API,可自动执行可扩展的评估流程。团队可以集中提交作业、配置参数并监控结果,非常适合 CI/ CD 集成和生产就绪型生成式 AI 运营工作流。
使用简单的 REST API 自动执行可扩展的评估流程。
抽象复杂性:集中提交“作业”、配置参数并监控结果。
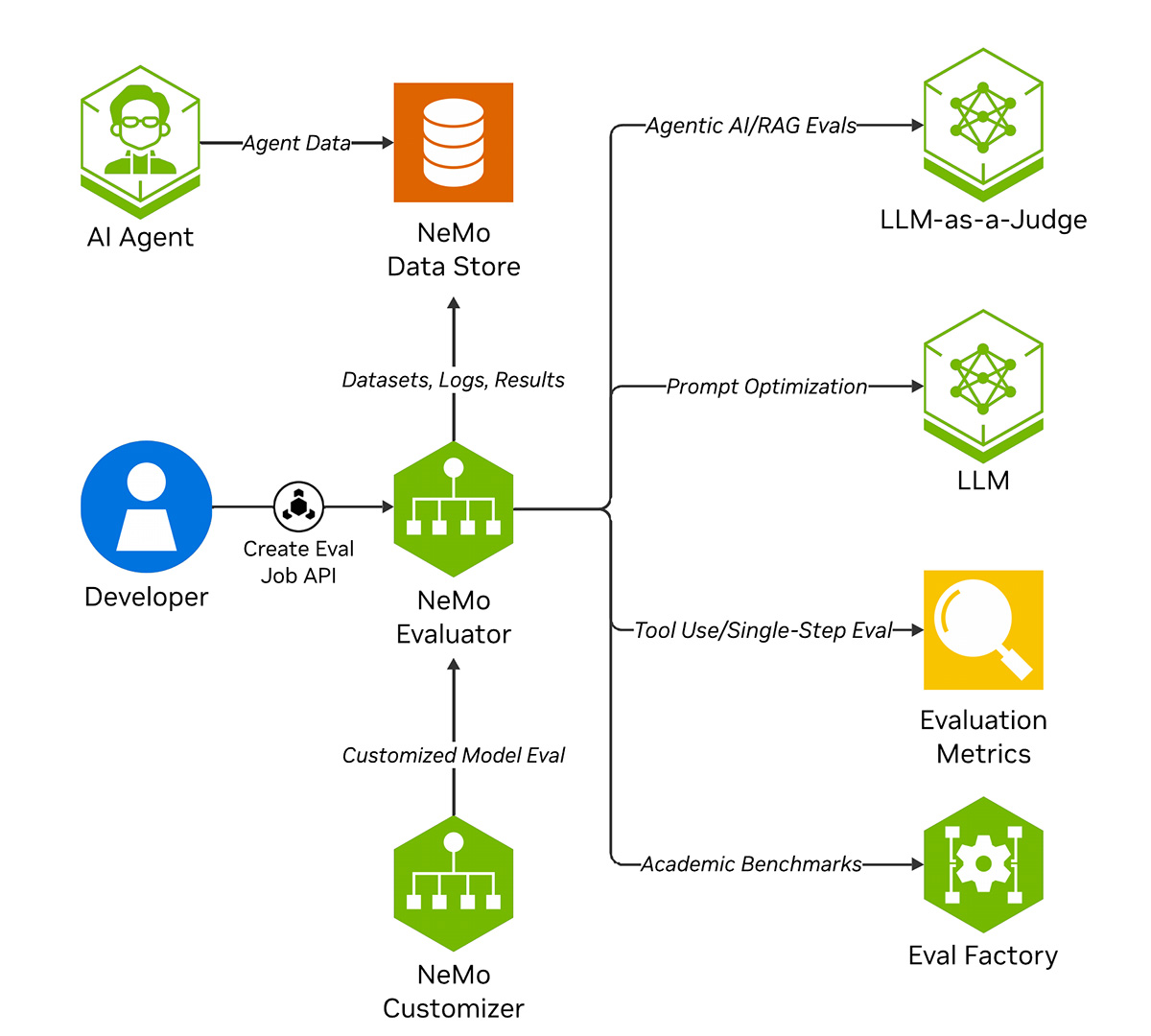
NVIDIA NeMo 微服务评估器的工作原理
NeMo Evaluator 微服务允许用户通过 REST API 运行代理式 AI 应用的各种评估作业。启用的评估流程包括:学术基准测试、代理和 RAG 指标,以及 LLM 即评判。用户还可以通过提示优化功能调整其判断模型。
入门资源
如何开始使用 NVIDIA NeMo Evaluator
使用合适的工具和技术,在任何平台上跨学术和自定义 LLM 基准评估生成式 AI 模型和流程。

查看 NVIDIA NeMo Evaluator 微服务的实际应用
观看这些演示,了解 NeMo Evaluator 微服务如何简化 AI 智能体、RAG 和 LLM 的评估和优化。
入门套件
相似性指标
使用 F1、ROUGE 或其他指标衡量 LLM 或检索模型处理特定领域查询的效果。
NVIDIA NeMo Evaluator 学习资源库
更多资源


AI 伦理
NVIDIA 认为可信 AI 是一项共同责任,我们已制定相关政策和实践,以支持开发各种 AI 应用。根据我们的服务条款下载或使用时,开发者应与其内部模型团队合作,确保此模型满足相关行业和用例的要求,并解决不可预见的产品滥用问题。请单击此处报告安全漏洞或 NVIDIA AI 问题。
立即开始使用 NeMo Evaluator。