
加速结构在空间上组织几何体以加速光线跟踪遍历性能。创建加速结构时,会分配保守的内存大小。
- 在初始构建时,图形运行时不知道几何体如何最佳地适应超大的加速结构内存分配。
- 在 GPU 上执行构建之后,图形运行时报告加速结构可以容纳的最小内存分配。
这个过程称为压缩加速结构,它对于减少加速结构的内存开销非常重要。
减少记忆的另一个关键因素是对加速结构的子分配。子分配通过使用比图形 API 所要求的内存对齐方式更小的内存对齐方式,使加速结构能够在内存中紧密地打包在一起。
通常,缓冲区分配对齐最小为 64 KB ,而加速结构内存对齐要求仅为 256 B 。使用许多小加速结构的游戏从子分配中受益匪浅,使许多小分配能够紧密打包。
NVIDIA RTX 内存实用程序( RTX MU ) SDK 旨在降低与加速结构优化内存管理相关的编码复杂性。 RTX MU 为 DXR 和 Vulkan 光线跟踪提供压缩和子分配解决方案,同时客户端管理加速结构构建的同步和执行。 SDK 为这两个 API 提供了子分配器和压缩管理器的示例实现,同时为客户机实现自己的版本提供了灵活性。
有关压缩和子分配在减少加速结构内存开销方面为何如此重要的更多信息,请参见 提示:加速结构压实 。
为什么使用 RTX MU ?
RTX MU 允许您将加速结构内存缩减技术快速集成到他们的游戏引擎中。下面是这些技术的总结,以及使用 RTX MU 的一些关键好处
- 减少加速结构的内存占用,包括压缩和子分配代码,实现起来并不简单。 RTX MU 可以完成繁重的工作。
- 抽象了底层加速结构( blase )的内存管理,但也足够灵活,允许用户根据引擎的需要提供自己的实现。
- 管理压缩大小回读和压缩副本所需的所有屏障。
- 将句柄传递回引用复杂 BLAS 数据结构的客户端。这可以防止对 CPU 内存的任何管理不当,包括访问已经释放或不存在的 BLAS 。
- 有助于将 BLAS 内存减少 50% 。
- 通过将更多的 BLASE 打包到 64 KB 或 4 MB 页中,可以减少翻译查找缓冲区( TLB )未命中。
RTX MU 设计
RTX MU 有一种设计理念,可以降低大多数开发人员的集成复杂性。该设计理念的主要原则如下:
- 所有函数都是线程安全的。如果同时访问发生,它们将被阻塞。
- 客户机传入客户机拥有的命令列表, RTX MU 填充它们。
- 客户机负责同步命令列表执行。
API 函数调用
RTX MU 抽象了与压缩和子分配相关的编码复杂性。本节中详细介绍的函数描述了 RTX MU 的接口入口点。
Initialize– 指定子分配程序块大小。PopulateBuildCommandList– 接收D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS数组并返回加速结构句柄向量,以便客户端稍后在顶级加速结构( TLAS )构造期间获取加速结构 GPU VAs ,依此类推。- PopulateUAVBarriersCommandList –接收加速度结构输入并为其放置 UAV 屏障
- PopulateCompactionSizeCopiesCommandList –执行拷贝以传递任何压缩大小数据
PopulateUpdateCommandList– 接收D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS数组和有效的加速结构句柄,以便记录更新。PopulateCompactionCommandList– 接收有效的加速结构句柄数组,并记录压缩命令和屏障。RemoveAccelerationStructures– 接收一个加速结构句柄数组,该数组指定可以完全释放哪个加速结构。GarbageCollection– 接收一个加速结构句柄数组,该数组指定可以释放生成资源(暂存和结果缓冲区内存)。GetAccelStructGPUVA– 接收加速结构句柄并根据状态返回结果或压缩缓冲区的 GPU VA 。Reset– 释放与当前加速结构句柄关联的所有内存。
子分配程序 DXR 设计
BLAS 子分配程序通过将小的 BLAS 分配放在较大的内存堆中,来满足 64kb 和 4mb 的缓冲区对齐要求。 BLAS 子分配程序仍然必须满足 BLAS 分配所需的 256B 对齐。
- 如果应用程序请求 4mb 或更大的子分配块,那么 RTX MU 使用具有堆的已放置资源,这些堆可以提供 4mb 对齐。
- 如果应用程序请求的子分配块少于 4MB ,那么 RTX MU 将使用提交的资源,它只提供 64KB 的对齐。
BLAS 子分配程序通过维护空闲列表重用块中的空闲子分配。如果内存请求大于子分配程序块大小,则会创建一个无法子分配的分配。
压实 DXR 设计
如果构建请求压缩,那么 RTX MU 请求将压缩大小写入视频内存块。压缩大小从视频内存复制到系统内存后, RTX MU 分配一个子分配的压缩缓冲区,用作压缩复制的目的地。
压缩拷贝获取包含未使用的内存段的原始构建,并将其截短到可以容纳的最小内存占用。压缩完成后,原始的非压缩构建和暂存内存将释放回子分配程序。唯一需要担心的是传入 allow compression 标志并用 BLAS 句柄调用 GetGPUVA 。 GPU VA 可以是原始版本,也可以是压缩版本,这取决于 BLAS 处于什么状态。
如何使用 RTX MU
在本节中,我将详细介绍 RTX MU 序列循环和同步。
RTX MU 序列环路
图 1 显示了 RTX MU 的正常使用模式。客户机管理命令列表的执行,而其他一切都是对 RTX MU 的调用
首先,通过传入子分配程序块大小和负责分配子分配块的设备来初始化 RTX MU 。在每一帧中,引擎构建新的加速结构,同时也压缩先前帧中构建的加速结构。
在 RTX MU 填充客户机的命令列表之后,客户机就可以自由地执行和管理初始构建到最终压缩拷贝构建的同步。在调用 PopulateCompactionCommandList 之前,确保每个加速结构构建都已完全执行,这一点很重要。这是留给客户妥善管理。
当加速结构最终达到压缩状态时,客户机可以选择调用 GarbageCollection ,它通知 RTX MU 可以释放暂存和原始加速结构缓冲区。如果引擎执行大量的资产流,那么客户端可以通过使用有效的加速结构句柄调用 RemoveAS 来释放所有加速结构资源。
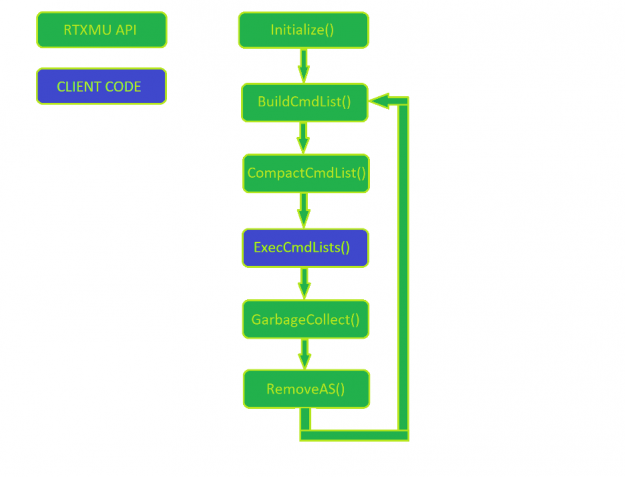
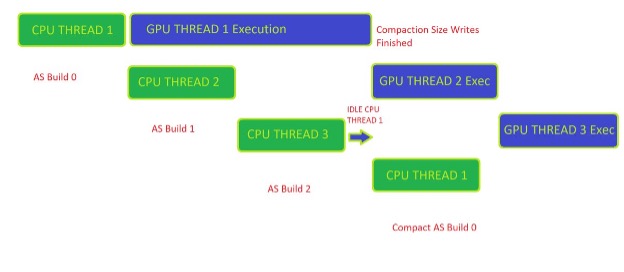
客户端加速结构生成同步
图 2 显示了客户端正确管理压缩就绪工作负载所需的同步。这里的示例是一个三帧缓冲循环,其中客户端最多可以有三个异步帧构建在 CPU 上并在 GPU 上执行。
若要获取 CPU 侧可用的压缩大小,生成 0 必须已在 GPU 上执行完毕。在客户端接收到来自 GPU 的 fence 信号后,客户端可以调用 RTX MU 来开始压缩命令列表记录。
管理加速结构的压缩同步的一种有用方法是使用某种类型的键/值对数据结构,它跟踪 RTX MU 给定的每个加速结构句柄的状态。加速度结构的四种基本状态可描述如下:
- Prebuilt – 生成命令记录在命令列表中,但尚未在 GPU 上完成执行。
- Built – 初始构建已在 GPU 上执行,并准备好执行压缩命令。
- Compacted – 压缩拷贝已经在 GPU 上完成,并且准备好让
GarbageCollection释放暂存和初始构建缓冲区。 - Released – 客户端从内存中释放加速结构,因为它不再在场景中。此时,与加速结构句柄相关的所有内存都被释放回操作系统。
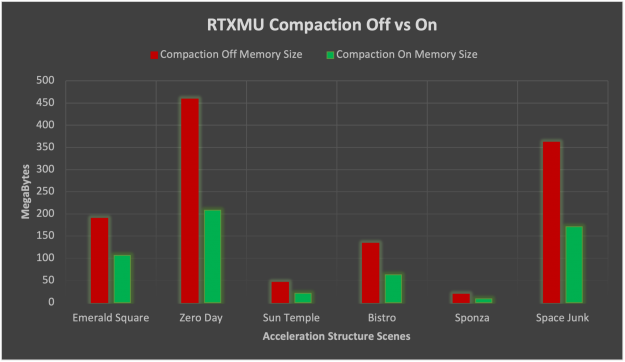
RTX MU 测试场景
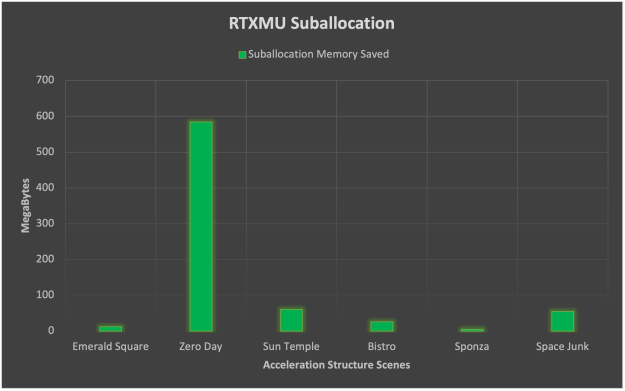
RTX MU 使用六个文本场景进行了测试,以提供有关压缩和子分配的好处的真实用例数据。下面的图只显示了一些场景。

10740 BLAS ,未压缩加速结构内存大小 458 . 9 MB ,压缩加速结构内存大小 208 . 3 MB ,内存减少 55% ,子分配内存节省 71 . 3 MB

281 BLAS ,未压缩加速结构内存大小 189 . 7 MB ,压缩加速结构内存大小 106 . 1 MB ,内存减少 44% ,子分配内存节省 8 . 3 MB

1056 BLAS ,未压缩加速结构内存大小 45 . 8 MB ,压缩加速结构内存大小 20 . 7 MB ,内存减少 55% ,子分配内存节省 56 . 8 MB
RTX MU 积分结果
在测试场景中, NVIDIA RTX 卡上的压缩平均减少了 52% 的加速度结构。压缩记忆降低的标准差为 2 . 8% ,比较稳定。
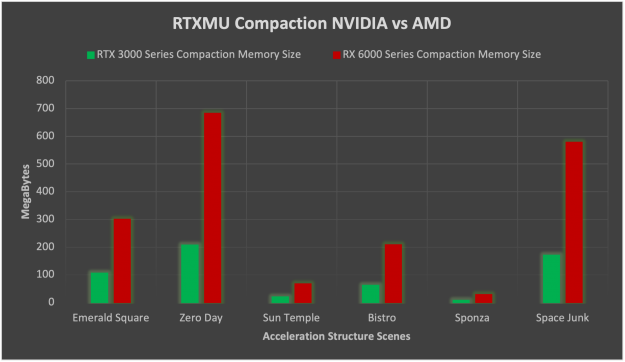
在 NVIDIA 和 AMD-HW 上启用压缩时, NVIDIA HW 上的内存节省比 AMD 上的内存节省大得多。在启用压缩时, NVIDIA 的加速结构内存平均比 AMD 小 3 . 26 倍。在 NVIDIA 上如此巨大的内存占用减少的原因是没有压缩的 AMD 使用的内存是 NVIDIA 的两倍。压缩还将 NVIDIA 内存平均再减少 50% ,而 AMD 倾向于只减少 75% 的内存。
子分配在这里讲述了一个稍有不同的故事,其中有许多小加速结构的场景(如零日)受益匪浅。子分配带来的平均内存节省最终为 123MB ,但标准差在 153MB 时相当大。从这些数据中,我们可以断言子分配高度依赖于场景几何体,并受益于数千个小三角形计数的 BLAS 几何体。
源代码
NVIDIA 是一个开源的 RTX MU SDK ,以及一个集成 RTX MU 的示例应用程序。在 GitHub 上将 RTX MU 作为一个开源项目进行维护可以帮助开发人员理解逻辑流程并提供修改底层实现的访问。 RT Bindless 示例应用程序提供了一个 RTX MU 集成的示例 Vulkan 光线跟踪和 DXR 后端。
下面是如何构建和运行集成 RTX MU 的示例应用程序。您必须拥有以下资源:
- Windows 、 Linux 或支持 DXR 或 Vulkan 光线跟踪的操作系统
- 克马克 3 . 12
- C ++ 17
- Git
首先,使用以下命令克隆存储库:
git clone --recursive https://github.com/NVIDIAGameWorks/donut_examples.git
接下来,打开 CMake 。对于 源代码在哪里 ,输入 /donut_examples 文件夹。在 /donut_examples 文件夹中创建生成文件夹。对于 在哪里构建二进制文件 ,输入 new build 文件夹。选择 cmake 变量 NVRHI \ u ,并将“ RTX MU ”设置为“开”,选择“配置”,等待其完成,然后单击“生成”。
如果要使用 Visual Studio 进行构建,请选择 2019 和 x64 version 。在 visualstudio 中打开 donut_examples.sln 文件并生成整个项目。
在 /Examples/Bindless Ray 跟踪下找到 rt_bindless 应用程序文件夹,选择项目上下文(右键单击)菜单,然后选择 启动项目 。
默认情况下,无绑定光线跟踪在 DXR 上运行。要运行 Vulkan 版本,请在项目中添加 -vk 作为命令行参数。
Summary
RTX MU 结合了压缩和子分配技术来优化和减少任何 DXR 或 Vulkan 光线跟踪应用程序的加速结构的内存消耗。数据表明,使用 RTX MU 可以显著减少加速结构的内存。这使您可以向光线跟踪场景添加更多几何体,或将额外内存用于其他资源。
立即开始使用 RTX MU SDK :




