
对于大规模部署 LLM 的机器学习工程师来说,这个等式既熟悉又无情:随着上下文长度的增加,注意力计算成本呈爆炸式增长。无论您是在处理检索增强生成 (RAG) 工作流、代理式 AI 工作流,还是长文本内容生成,注意力的复杂性 
本文将介绍一种名为 Skip Softmax 的技术,这是一种硬件友好型的插入式稀疏注意力方法,无需任何重新训练即可加速推理。继续阅读,了解 Skip Softmax 如何将首 token 时间(TTFT)和每输出 token 时间(TPOT)均提升 1.4 倍,以及如何在 NVIDIA TensorRT-LLM 中启用该技术。
Skip Softmax 的工作原理是什么?
“Skip Softmax 的核心在于提供一种动态方式来修剪注意力块。这之所以可行,是因为它利用了 Softmax 函数的基本属性: 
在标准 FlashAttention 中,GPU 会计算查询块 ( 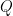

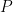
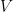
但是,注意力本质上是稀疏的。对于许多块而言,其注意力得分相较于主导的 tokens 明显偏低,因此在统计上它们对最终输出的贡献可以忽略不计。Skip Softmax 会修改 FlashAttention 循环,以便尽早识别出这些块,并直接跳过它们。
Skip Softmax 算法
直接在 FlashAttention 内核中实现,其逻辑遵循以下启发式方法:
- 计算本地最大值:计算当前块 (
) 的最大 logit。
- 与运行 max 的比较:判断当前块的局部 max (
) 与运行的全局 max (
) 之差是否超过校准值 (
)。
- 跳过:若条件成立,核函数将跳过该块的 softmax 和 BMM2 计算,并且尤为关键的是,跳过从高带宽内存 (HBM) 加载
使用 Skip Softmax 有哪些好处?
Skip Softmax 具备插件式兼容性、硬件高效性、灵活性与通用性。
与需要修改特定架构的方法(例如线性注意力)不同,Skip Softmax 与采用 MHA、GQA 或 MLA 等标准注意力机制的现有预训练模型兼容。该方法经过优化,能够充分利用 NVIDIA Hopper 和 NVIDIA Blackwell GPU 所特有的 Tensor Core 及内存层次结构。此外,它还可与其他优化技术结合使用。例如,在解码过程中,将预填充阶段的 XAttention 与 Skip Softmax 相结合,可在不牺牲准确性的前提下显著提升推理速度。
Skip Softmax 用途广泛,因为它有效缓解了预填充和解码阶段的瓶颈问题。根据 Hopper 和 Blackwell 架构的性能数据,Skip Softmax 在带宽受限的解码过程以及计算受限的预填充过程中均表现出显著优势,尤其适用于长上下文场景。
带宽受限的解码
在生成(解码)阶段,大语言模型的推理过程通常受限于内存带宽。GPU 在移动 KV 缓存数据上所花费的时间往往超过其用于计算的时间。
- 优势:通过尽早识别不重要的块,Skip Softmax 可完全避免加载关联的
- 数据:在 Llama 3.3 70B(NVIDIA GB200 NVL72)上,Skip Softmax 在解码期间可实现约 1.36 倍的端到端加速。
计算受限的预填充
在预填充阶段(处理输入提示),系统受限于计算能力。
- 优势: 跳过 softmax 和二次矩阵乘法(BMM2)可节省大量 FLOPS。
- 数据: 对于相同的 Llama 3.3 70B 模型(NVIDIA GB200 NVL72),预填充阶段在 128K 上下文长度下预计可实现 1.4 倍的端到端加速。
长上下文场景
Skip Softmax 的效果随着序列长度的增加而提升。被跳过的值在数学上与上下文长度( 

准确性与稀疏性之间的权衡
对于任何近似技术,一个显而易见的问题是:“这种方法会对准确性产生怎样的影响?”
对 RULER(合成长上下文)和 LongBench(真实长上下文)基准的广泛测试表明,稀疏性存在一个明确的“安全区”。
- 安全区域: 观察到 50% 的稀疏比(跳过一半的块)属于安全范围。在使用 Llama 3.1 8B 和 Qwen3-8B 进行的测试中,当稀疏性约为 50% 时,大多数任务可实现接近无损的准确性。
- 危险区域: 当稀疏度超过 60% 时,通常会导致精度显著下降,尤其在复杂的“大海捞针”多关键任务中表现更为明显。
- 长代: 对于需要长输出生成的任务(例如 MATH-500),与部分静态 KV 缓存压缩方法不同,Skip Softmax 能在稀疏注意力下保持与密集注意力相当的准确性。
| 模型 | 数据集 | 稀疏度 | 精度增量与基准 |
| Llama 3.1 8B | RULER-16K | = 50% 在预填充阶段 | – 0.19 |
| Qwen-3 -8B | MATH500 | = 50% 在解码阶段 | – 0.36 |
| 场景 | 阈值 | 加速 (BF16) | 基准精度 | 稀疏精度 | 精度增量 |
| 仅上下文 | 0.2 | 130.63% | 37.21% | 36.74% | -0.47% |
| 上下文加生成 | 0.6 | 138.37% | 35.81% | 34.42% | -1.39% |
部署时的其他优化措施包括以下内容:
- 自动校准程序,用于确定目标稀疏水平的最优值。
- 稀疏感知训练使模型更适应稀疏注意力模式。
开始在 NVIDIA TensorRT-LLM 中启用 Skip Softmax
Skip Softmax Attention 直接集成至 NVIDIA TensorRT-LLM,支持 NVIDIA Hopper 与 NVIDIA Blackwell 数据中心 GPU。依托 TensorRT-LLM 所提供的高效 LLM 推理性能,可进一步加速注意力计算。
可以通过配置 LLM API 的稀疏注意力机制来启用 Skip Softmax Attention:
from tensorrt_llm import LLM
from tensorrt_llm.llmapi import SkipSoftmaxAttentionConfig
sparse_attention_config = SkipSoftmaxAttentionConfig(threshold_scale_factor=1000.0)
# Additionally, the threshold_scale_factor for prefill and decode could be separately configured.
sparse_attention_config = SkipSoftmaxAttentionConfig(threshold_scale_factor={"prefill": 1000.0, "decode": 500.0})
llm = LLM(
model="Qwen/Qwen3-30B-A3B-Instruct-2507",
sparse_attention_config=sparse_attention_config,
# Other LLM arguments...
)
实际值等于 threshold_scale_factor 除以上下文长度。
您还可以通过额外的 LLM API 选项 YAML 文件来指定配置。以下为启动兼容 OpenAI 的端点的示例:
cat >extra_llm_api_options.yaml <<EOF
sparse_attention_config:
algorithm: skip_softmax
threshold_scale_factor: 1000.0
EOF
# Additionally, the threshold_scale_factor for prefill and decode could be separately configured.
cat >extra_llm_api_options.yaml <<EOF
sparse_attention_config:
algorithm: skip_softmax
threshold_scale_factor:
prefill: 1000.0
decode: 500.0
EOF
trtllm-serve Qwen/Qwen3-30B-A3B-Instruct-2507 --extra_llm_api_options extra_llm_api_options.yaml
了解详情
如需了解更多信息,请参阅 BLASST:通过 Softmax 值实现动态阻塞注意力稀疏,以及关于 LLM API 和 CLI 的 TensorRT-LLM 文档。校正将由 NVIDIA Model Optimizer 提供支持,帮助用户设定目标稀疏性并获取相应的值比例系数。
Skip Softmax 稀疏注意力内核也将通过 FlashInfer Python API 提供。请关注即将发布的 TensorRT-LLM、Model Optimizer 和 FlashInfer 版本更新的官方公告。




