
在算法交易中,缩短对市场事件的响应时间至关重要。为了与高速电子市场保持同步,对延迟敏感的公司通常使用 FPGA 和 ASIC 等专用硬件。然而,随着市场效率不断提高,交易员越来越依赖深度神经网络等先进模型来提高盈利能力。由于在低级硬件上实现这些复杂的模型需要大量投资,因此通用型 GPU 是一种经济高效的实用替代方案。
Supermicro ARS-111GL-NHR 服务器中的 NVIDIA GH200 Grace Hopper 超级芯片 在 STAC-ML 市场 (推理) 基准测试、 Tacana 套件 (由 STAC 审计) 中实现了单位数微秒的延迟,提供与专用硬件系统相当或更出色的性能。
本文详细介绍了这些创纪录的结果,并深入探讨了低延迟 GPU 推理所需的定制解决方案。它还会引导您完成开源参考实现和入门教程。
金融服务中的 STAC-ML 基准测试
具有长短期记忆 (LSTM) 的深度神经网络广泛应用于资本市场的时间序列预测。STAC-ML (市场) 推理基准测试用于测量 LSTM 模型延迟,即从接收新输入到生成输出之间的时间。它包含三个日益复杂的模型 ( LSTM_A、LSTM_B 和 LSTM_C) ,其中 LSTM_B 大约比 LSTM_A 大六倍,LSTM_C 大约比 LSTM_A 大 200 倍。该基准测试包含两个套件:Tacana 和 Sumaco,前者用于测试每个时间步更新的滑动窗口上的推理,后者用于测试每个运算的全新数据的推理。
STAC-ML Markets (推理) Tacana 基准测试处理滑动窗口输入,生成单个回归输出,zt,在每次迭代中。
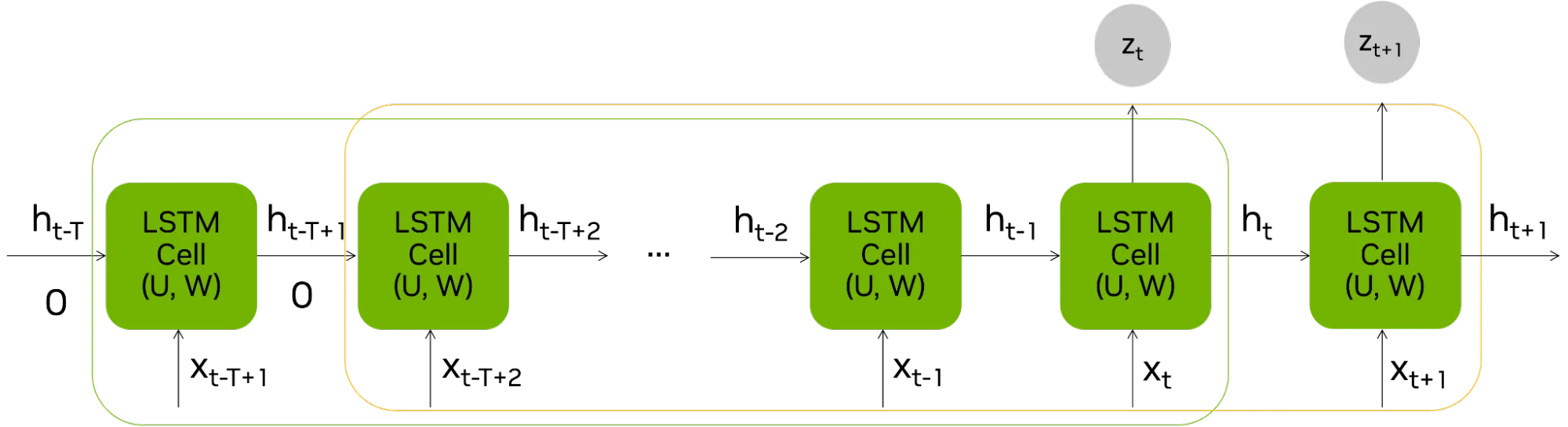
STAC-ML 已成为金融机构在交易中利用机器学习 (ML) 的关键基准。它严格衡量技术堆栈的速度和可靠性,可在逼真的生产环境下基于实时市场数据运行模型。通过标准化关键指标 (例如 LSTM 和其他时间序列模型的延迟、吞吐量和效率) ,STAC-ML 使银行、对冲基金和做市商能够在部署前对竞争硬件和软件解决方案进行客观的、苹果到苹果的比较。
对于位于同一地点数据中心的交易台而言,可以在几微秒内决定是否赢得订单,STAC-ML 结果至关重要。它们证实,对于高频做市、短期价格预测和自动对冲等要求严苛的用例,平台可以满足严格的延迟预算。
此外,由于该基准由领先金融公司的从业者设计和管理,因此其分数在技术选择过程中具有重要的权重,帮助公司管理推出 ML 驱动的新交易策略的风险,并证明重大投资决策的合理性。
NVIDIA 关键 STAC-ML 结果
NVIDIA 在 Supermicro ARS-111GL-NHR 上使用单个 NVIDIA GH200 Grace Hopper 超级芯片 ( FP16 精度) 展示了以下延迟 (第 99 个百分位) ,用于 STAC-ML Tacana。
LSTM_A 和 p99 延迟:
- 4.70 微秒,使用一个模型实例
- 4.67 微秒,使用两个模型实例
- 4.61 微秒,使用四个模型实例
- 4.67 微秒,8 个模型实例
LSTM_B 和 p99 延迟:
- 7.10 微秒 (使用一个模型实例)
- 6.88 微秒,使用两个模型实例
- 7.10 微秒,四个模型实例
LSTM_C 和 p99 延迟:
- 15.80 微秒 (使用一个模型实例)
请注意,在将 LSTM_A 和 LSTM_B 的模型实例数 (NMI) 从 1 个扩展到 4 – 8 个时,观察到的延迟保持高度一致。这种稳定性凸显了绿色环境在保持延迟敏感型应用的可预测性能方面的重要性。有关更多详细信息,请参阅采用 NVIDIA GH200 Grace Hopper 超级芯片的 Supermicro ARS-111GL-NHR 上的 STAC-ML 市场 (推理)。
无缝集成 NVIDIA GH200 Grace Hopper 超级芯片
NVIDIA GH200 Grace Hopper 超级芯片通过支持各种容器、应用程序二进制文件和操作系统,扩展了强大的 64 位 Arm 处理器生态系统。它与完整的 NVIDIA 软件堆栈无缝集成,包括 NVIDIA HPC 和 AI 平台。
与之前提交作品的比较
NVIDIA 之前提交了吞吐量和延迟的优化结果 ( Sumaco 和 Tacana 基准测试) ,详情请参阅NVIDIA A100 Aces 吞吐量,金融服务业关键推理基准测试中的延迟结果。在之前的 Tacana 工作中,滑动窗口方法通过预计算实现了更高效的递归处理。我们重构了该问题,使用固定数量的矩阵乘法 (GEMM) 和初始预计算对所有时间步长执行计算,从而实现有竞争力的性能。
最近提交的 Tacana FPGA 基准测试结果通过将延迟测量集中在最终时间步上并利用关键部分之外的预计算,报告了两种 LSTM 大小的单位数微秒延迟。
在 GPU 上实现如此低的延迟需要定制的解决方案,从而突破 GPU 内核启动延迟的界限。
NVIDIA 实施由两个连续步骤组成。第一步是预计算,它会为滑动窗口 LSTM 的最后时间步生成所需的输入。例如,如果需要将滑动窗口的初始隐藏/ 单元输入重置为 0,则每层需要执行两次 GEMM 运算。此预计算阶段排除在定时测量之外。
第二步是推理,即在滑动窗口转向新输入后计算最后一个 LSTM 时间步。推理完成后,下一个预处理阶段会预先计算下一次推理迭代的相关数据。
GPU 上的低延迟 LSTM 推理
本节介绍在 NVIDIA 硬件上高效实现 LSTM 网络低延迟推理的技术,包括开源参考实现。
NVIDIA 开源 LSTM CUDA 内核
dl-lowlat-infer 是一个开源资源库,其中提供了用于实现低延迟时间序列推理的 CUDA 内核示例。此处介绍的内核中使用的技术也应用于 STAC-ML 基准测试中。虽然开源库包含用于实现代码执行的最低限度基准测试功能,但它并不像 STAC-ML 那样是一个成熟的基准测试套件。
dl-lowlat-infer 存储库展示了在 NVIDIA GPU 上运行深度学习工作负载的高效技术,并且完全独立。它可以生成模型权重和输入,对输入数据位置进行随机采样,并在同一 GPU 上对单个或多个模型实例运行推理。目前,它仅限于 LSTM 的滑动窗口用例。
这项工作侧重于三种 LSTM 模型大小,这些模型经过专门调整,可在 NVIDIA RTX PRO 6000 Blackwell Server Edition GPU 上高效运行。这些配置包括一个适合单个流多处理器 (SM) 的共享内存和寄存器的小型模型、一个线程块集群 (TBC) 中跨越 8 个 SM 的中型模型,以及一个几乎可以利用整个设备的大型模型 (186 个 SM 中有 184 个) 。
| 图层 | 时间步长 | 输入 | 单位 | 权重 | |
| 小 | 2 | 64 | 128 | 96 | 16 万 |
| 中级 | 3 | 96 | 192 | 160 | 63.5 万 |
| 大型 | 4 | 128 | 512 | 736 | 1670 万 |
虽然 STAC-ML Tacana 在 NVIDIA GH200 Grace Hopper 超级芯片上取得了创纪录的成果,但以下教程使用了 NVIDIA RTX PRO Blackwell 服务器版本。这一转变的推动因素是许多金融服务公司的目标部署环境。低延迟交易台通常在功耗受限的托管环境中运行,在这种环境中,传统数据中心级 GPU (例如 GH200) 的散热和功耗限制可能不是一个可行的选择。
NVIDIA RTX PRO Blackwell 服务器版 GPU 提供了强大而高效的替代方案,适合部署在这些受限环境中。至关重要的是,以下教程中介绍的低延迟推理技术和开源代码与这两种架构完全兼容。这可确保在 RTX PRO Blackwell Server Edition GPU 上提供高性能的相同优化内核也能在 GH200 上高效运行。这使用户能够轻松地在数据中心平台上进行基准测试。
如何构建和运行低延迟 LSTM 推理参考实现
要构建和运行基准测试,您需要 CUDA 13.0 或更高版本以及支持 C++ 20 的编译器。以下说明是针对最新的 NVIDIA Blackwell 架构 量身定制的,但您也可以通过为 SM90 编译在 NVIDIA Hopper GPU 上运行代码。较旧的 GPU 架构仅支持小型网络;由于技术限制,两个较大的网络无法运行。
在 Docker 中构建
该基准测试旨在在 Docker 容器内运行。您可以在代码的顶层目录中构建容器和基准测试,并准备模型的权重和输入:
make -C docker CUDA_ARCHS=120-real LOCAL_USER=1 release_run |
CUDA_ARCHS 在 cmake 中设置目标 GPU 架构。例如,100 可用于 NVIDIA Blackwell 和 NVIDIA RTX PRO 6000 Blackwell 服务器版本 GPU。
运行模型
构建镜像并启动容器后,您可以转到应用目录,/ app/ dl-lowlat-infer例如,使用持久算法对小模型的单个实例执行 10 秒:
./nvLstmInf lstm_s data/lstm_s data/lstm_s.npy 10 |
使用持久性算法,使用六个 CPU 线程 (每个模型实例一个线程加主线程加定时线程) 运行中型模型的四个实例:
./nvLstmInf --cpuset=0,1,2,3,4,5 --num-instances=4 lstm_m data/lstm_m data/lstm_m.npy 10 |
有关在容器内运行和开发的更多详细信息,请参阅基准测试文档。
结果
表 2 显示了在搭载 AMD EPYC 9124 16 核处理器和 NVIDIA RTX PRO Blackwell 服务器版 GPU 的系统上启动代码所产生的结果。
| 乒乓球 | 小 | 中级 | 大型 | |
| 平均值,s | 2.4 | 3.5 | 4.7 | 13.2 |
| P99,微秒 | 2.5 | 4.3 | 5.4 | 14.2 |
Ping Pong 测试用于测量 CPU-GPU 同步和从主机内存读取输入向量的开销,这是导致小型模型延迟的主要原因。这些测量采用与俄亥俄州立大学 MVAPICH 延迟微基准测试类似的方法。这种开销因系统而异,并且取决于硬件和软件堆栈中的多个因素。对于具有更多层的更大模型,使用集群级和网格级同步基元会增加延迟。
实现详情
有关实现的详细信息,请参阅本节。
用于推理的持久内核
批量大小为 1 的推理阶段执行矩阵向量乘法,然后在每层执行元素级运算。在最后一层之后,生成的隐藏状态将缩减为单个值,并通过推理将其报告给基准测试过程。
推理使用持久性内核方法实施,这意味着内核在应用程序的整个生命周期中一直处于活动状态。这种持久性通过将权重加载到共享显存中并在核函数初始化期间仅寄存器一次来提高性能。
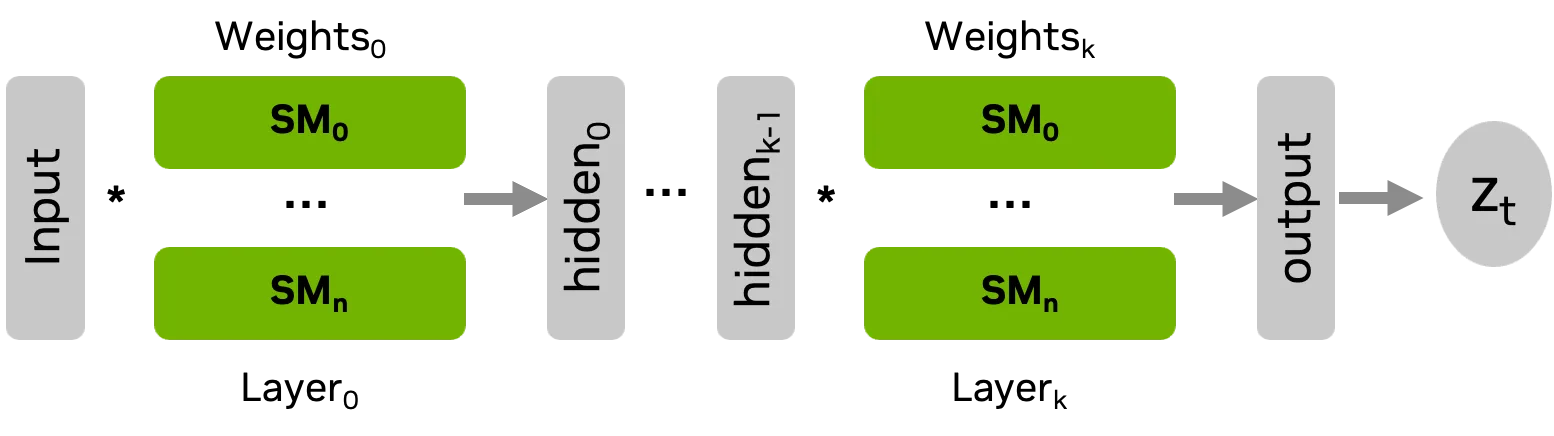
根据问题大小并确保权重适合可用 SM,请使用单个 CUDA 块、TBC 或分配整个设备。因此,实现了三个不同的内核,它们共享相同的权重内存布局,并且都遵循相似的结构和时间约定。
TBC 可在 RTX PRO Blackwell 服务器版 GPU 上跨多达 8 个 SM,足以容纳中型模型的权重。在从其他 CUDA 块收集计算隐藏状态的片段时,适用于 TBC 的分布式共享内存 API 可实现 SM 之间更高效的数据交换和同步。
计时
计时由 CPU 线程管理,需要使用 CPU 和 GPU 原子同步基元在主机和设备之间实现信令。
- 当新输入到达主机内存时,主机会向设备发送信号,并同时启动计时器。
- 内核轮询此信号,然后读取输入并启动计算。
- 计算得出的浮点输出也可充当主机停止计时器的信号。
还有其他信号来中止核函数执行或重置双缓冲区 ID。这些缓冲区包含来自预计算的数据。
为多个模型实例提供服务
例如,在 RTX PRO Blackwell 服务器版 GPU 上运行单个 CUDA 块推理,既不节能,也不划算。使用 CUDA 绿色上下文 (GC) 功能在同一 GPU 上提供多个推理实例。请注意,有一些替代方法可以独立为多个实例提供服务。例如,使用 NVIDIA 多实例 GPU (MIG) 功能,或为持久 CUDA 内核本身添加另一层复杂的信令传输。
GC 功能可在应用程序内将 GPU 划分为 GC,而不会使内核变得复杂。每个 GC 绑定到特定数量的 SM。提交到在此类环境中创建的 CUDA 流的任何 CUDA 工作都将在相应的 SM 集上执行。
与传统的 GC 相比,GC 对编程人员来说更轻巧、更透明。GPU 被分割成大小相同的分区,以服务多个持久内核。其余 SM 用于预计算阶段。由于预计算对延迟并不重要,因此来自不同模型实例的预计算将提交给具有剩余 SM 的同一分区,但它们位于不同的 CUDA 流中。
与主机中的持久内核实例进行协调涉及多个旋转循环。因此,为多个模型实例提供服务需要为每个 GC 额外生成一个 CPU 线程。
最小 GC 大小为两个 SM。中小型模型每个 GC 分别分配 2 个和 8 个 SM。大型模型几乎需要整个设备在共享显存和寄存器中保存权重,并且在单个 RTX PRO Blackwell 服务器版本 GPU 上无法同时为多个模型提供服务。
GDRCopy
在位于固定主机缓冲区中的标志上轮询设备的成本可能相当高昂。 GDRCopy 通过使用 GPUDirect RDMA 创建 GPU 显存的 CPU 映射来提供低延迟替代方案。这使得 CPU 驱动的内存复制能够以最小的开销实现,这在小型数据传输较小且频繁的低延迟场景中尤为有用。在我们的实验中,使用 GDRCopy 在基于 PCIe 的系统上实现了高达 0.5 µs 的加速。
Ping Pong 基准测试
要获得乒乓球模型,请从最小的模型实现开始,并移除所有与 LSTM 相关的计算。此设置仅用于测量 CPU 信号和单个时间步长的输入读取的用度。因为它不涉及权重,所以使用单个 CUDA 块来实现它,就像在最小的模型中一样。这使得我们能够通过我们的实现来估计在给定系统上可实现的最小延迟。
开始使用低延迟推理
在之前“针对 NVIDIA GPU 上的低延迟交易和快速回测对深度神经网络进行基准测试”中报告的工作基础上,我们现在集成了针对延迟+ 关键路径专门优化的自定义 CUDA 内核。这些增强功能在两种 LSTM 模型大小上实现了创纪录的延迟,同时还保留了灵活的开发者体验。NVIDIA 平台继续为研究、优化和部署提供一致且以生产力为导向的环境。
这些功能可通过开源时间序列建模流程获得,该流程展示了如何高效使用 NVIDIA 技术 进行低延迟推理和回测。您还可以观看 GTC 2026 会议 构建高性能金融 AI:实现微秒延迟和按需可扩展的 LLM 推理。
STAC 和所有 STAC 名称均为 Strategic Technology Analysis Center,LLC 的商标或注册商标。




