
随着生成式 AI 的不断发展,企业组织对准确、可靠且基于自身特定业务数据的 AI 智能体的需求日益增长。NVIDIA AI-Q 研究助手与企业级 RAG 蓝图结合使用检索增强生成(RAG)技术以及 NVIDIA Nemotron 推理 AI 模型,能够自动完成文档理解、关键信息提取,并从大规模数据集中生成高价值的分析与报告。
部署这些工具需要安全且可扩展的 AI 基础设施,同时兼顾性能优化与成本效益。在本文中,我们将介绍如何在 Amazon Elastic Kubernetes Service (EKS) 上部署这些蓝图,并结合使用 Amazon OpenSearch Serverless 作为向量数据库、Amazon Simple Storage Service (S3) 用于对象存储,以及 Karpenter 实现 GPU 资源的动态扩展。
Blueprint 的核心组件
NVIDIA AI-Q 研究助手蓝图直接基于 NVIDIA 企业级 RAG 蓝图构建,该 RAG 蓝图是整个系统的核心基础组件。本文介绍的两个蓝图均依托一系列 NVIDIA NIM 微服务打造,这些推理容器经过专门优化,旨在实现 AI 模型在 GPU 上的高吞吐量与低延迟性能。
组件可根据其在解决方案中所承担的角色进行分类。
1. 基础 RAG 组件
这些模型构成了企业级 RAG 架构的核心,同时也是实现 AI-Q 助手功能的关键基础。
- 大语言模型(LLM)NVIDIA NIM:Llama-3.3-Nemotron-Super-49B-v1.5:该模型作为RAG工作流中的核心推理模型,负责查询分解、内容分析以及答案生成。
- NeMo Retriever 模型:这是一组基于 NVIDIA NIM 构建的模型,具备先进的多模态数据提取与检索能力,可从文档中提取文本、表格以及图形元素。
注意: RAG blueprint 提供了多个可选模型,这些模型未在当前解决方案中部署。您可以在 RAG blueprint GitHub 页面上获取更多详细信息。
2. AI-Q 研究助手组件
在 RAG 基础上,AI-Q 蓝图增加了以下组件,以支持其高级代理式工作流与自动化报告生成功能之上。
- LLM NIM: Llama-3.3-70B-Instruct: 这是一个规模更大的可选模型,由 AI-Q 专门用于生成全面且深入的研究报告。
- 网页搜索集成: AI-Q blueprint 采用 TAVILY API 实现网页搜索功能,通过实时获取网络信息来补充研究内容,确保报告基于最新可用的数据。
AWS 解决方案概述
这些蓝图可在 AI-on-EKS 上获取,并在 AWS 上提供完整的环境,自动配置所有必要的基础设施和安全组件。
架构
该解决方案将所有 NVIDIA NIM 微服务及其他组件以 Pod 形式部署在 Kubernetes 集群上,并根据每个工作负载的实际需求动态配置相应的 GPU 实例(如 G5、P4、P5 系列),从而实现成本与性能的优化。
AWS 上的 NVIDIA AI-Q 研究助手
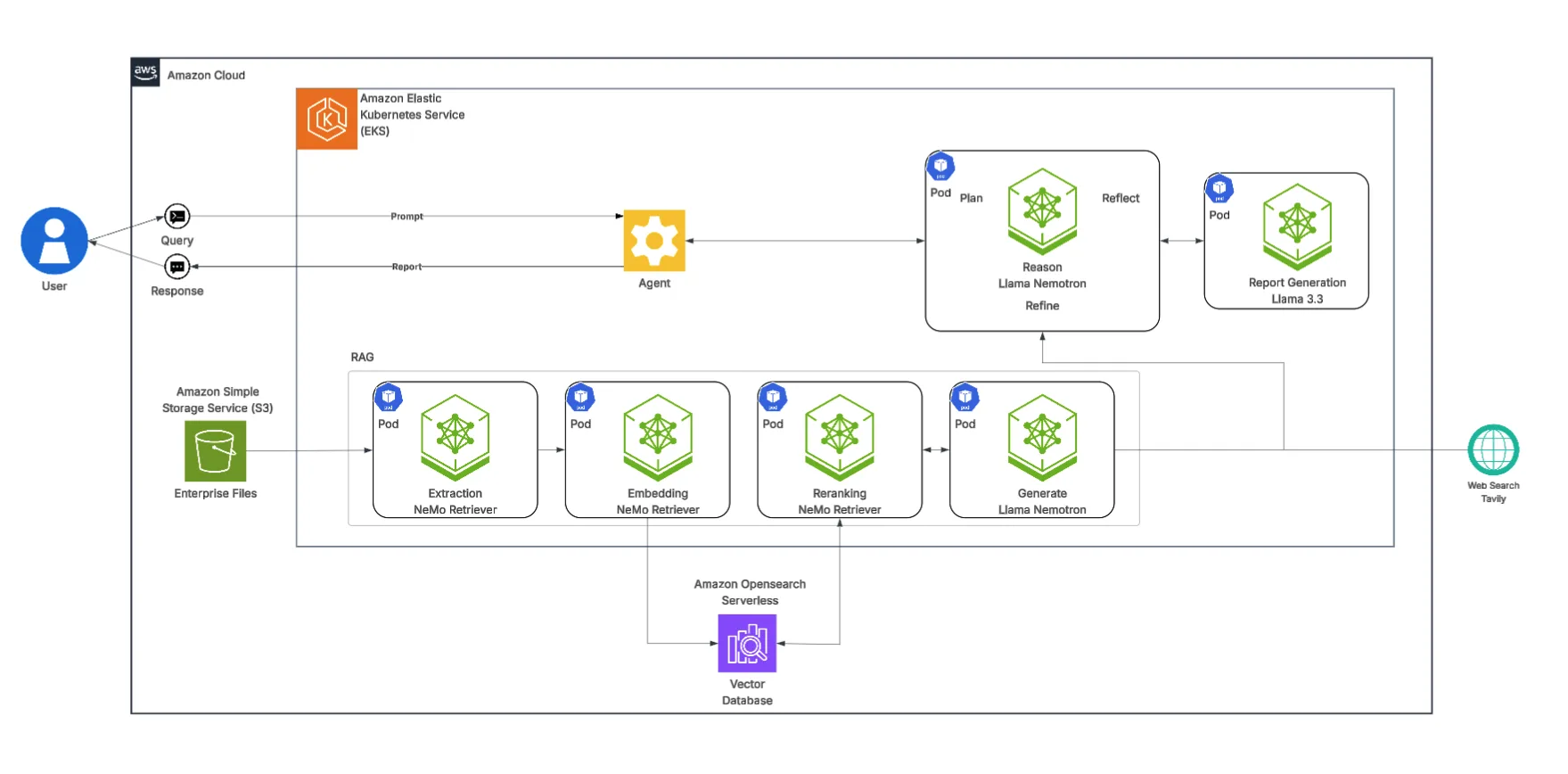
主图所示的 AI-Q 蓝图在 RAG 基础上引入了“Agent”层,用于编排更复杂的工作流程。
- 计划: Llama Nemotron 推理智能体对复杂的研究提示进行任务分解,判断应通过 RAG 管道检索内部知识,还是调用 Davinci API 执行实时网络搜索。
- 优化: 智能体从上述来源获取信息,并利用 Llama Nemotron 模型对数据进行整合与优化。
- 反思: 将所有经过处理的信息传递至“报告生成”模型(Llama 3.3 70B Instruct),由其生成结构清晰、附带引用的综合性报告。
NVIDIA Enterprise RAG Blueprint 架构
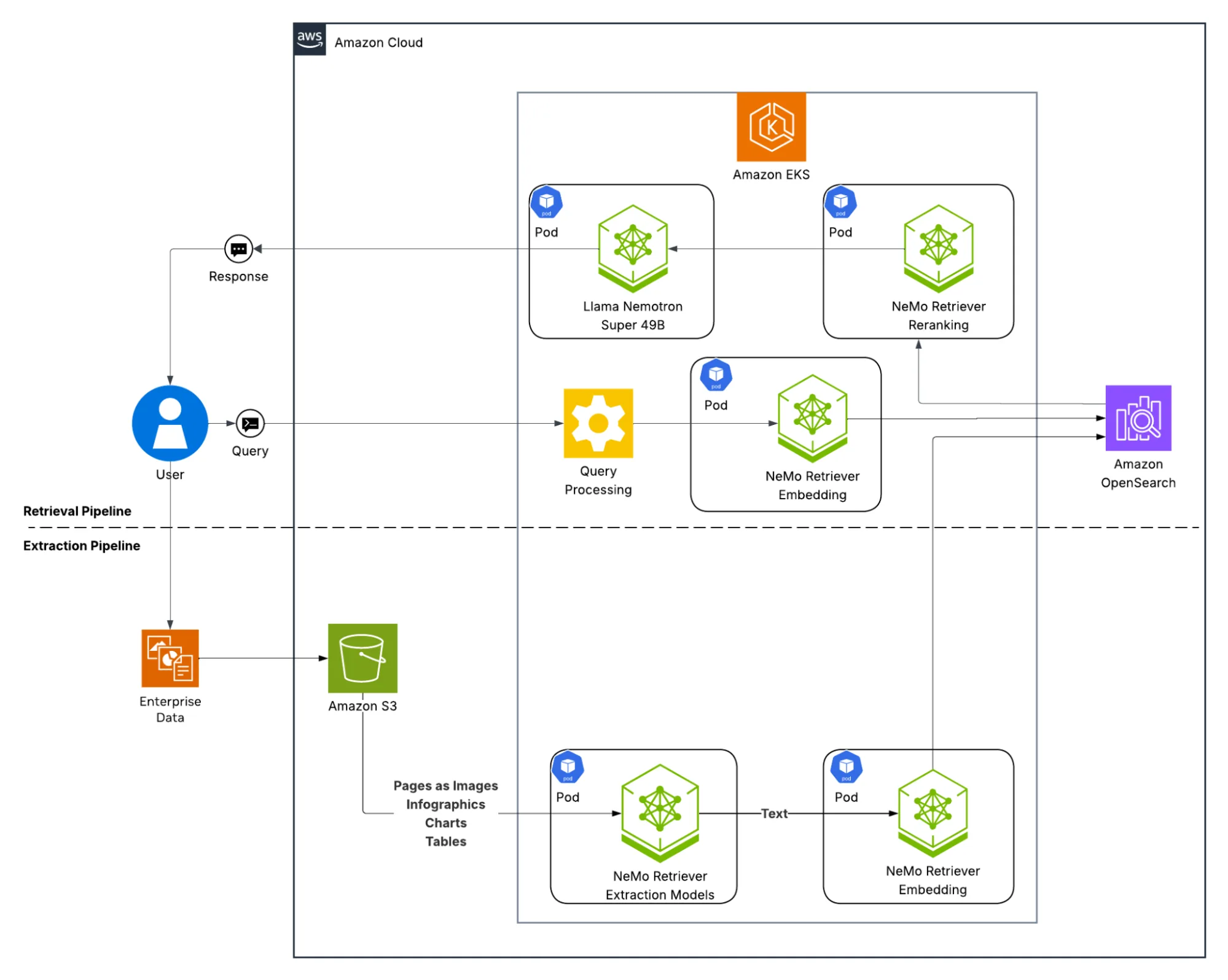
如图 2 所示,该解决方案由两个并行的工作流组成:
- 提取流程:企业文件存储在 Amazon S3 中,由 NeMo Retriever 的提取与嵌入模型进行处理,从中抽取文本、表格及其他数据,转换为向量嵌入,并存入 Amazon OpenSearch Serverless 向量数据库。
- 检索流程:当用户提交查询请求时,系统会对其内容进行处理,结合 NeMo Retriever 的嵌入与重排序模型,利用 OpenSearch 实现上下文检索。随后,检索到的上下文信息将输入至 NVIDIA Llama Nemotron Super 49B 模型,由该模型生成具备上下文理解能力的最终回答。
用于部署的 AWS 组件
该解决方案利用以下关键服务,在 AWS 上构建了一个完整且安全的运行环境。
- Amazon EKS: 作为一项托管式 Kubernetes 服务,Amazon EKS 负责运行、扩展和管理以 Pod 形式部署的全部容器化 NVIDIA NIM 微服务。
- Amazon Simple Storage Service (S3): S3 作为核心数据湖,用于存储企业文件(如 PDF、报告及其他文档),这些文件将由 RAG 工作流提取、处理并转化为可搜索的内容。
- Amazon OpenSearch Serverless: 这一完全托管的无服务器向量数据库,用于在文档被转换为数字表示(即嵌入)后进行存储。
- Karpenter: 作为在集群上运行的 Kubernetes 节点自动扩缩容组件,Karpenter 可监控 AI Pod 的资源需求,并动态配置适合的 GPU 节点(例如 G5、P4、P5 系列)以满足工作负载。
- EKS Pod 身份标识: 该功能使在 EKS 上运行的 Pod 能够安全地访问其他 AWS 服务(如 Amazon OpenSearch Serverless 集群),而无需管理静态凭证。
部署步骤
该解决方案通过一组自动化脚本,实现从 AWS 基础架构到蓝图的完整堆栈部署。
预备知识
该部署需要使用 GPU 实例(例如 G5、P4 或 P5 系列),可能导致较高的成本。请确认您的 AWS 帐户已具备所需实例的服务配额,并仔细阅读相关成本说明。在开始之前,请确保已安装以下工具:
您还需要来自以下来源的 API 密钥:
- NVIDIA NGC: 需提取 NIM 容器与模型,您可通过 NVIDIA 开发者计划或 NVIDIA AI Enterprise进行注册。
- Tavily API: 非强制要求,但若需启用网络搜索功能以实现完整的 AI-Q 研究助手能力,则必须配置。
对 AWS CLI 进行身份验证
在继续之前,请确认您的环境(AWS CloudShell终端)已使用 AWS 账户完成身份验证。本次部署将使用默认的 AWS CLI 凭据,您可通过执行以下命令进行配置:
aws configure第 1 步:部署基础架构
克隆代码仓库后,进入基础架构目录,然后运行安装脚本。
# Clone the repository
git clone https://github.com/awslabs/ai-on-eks.git
cd ai-on-eks/infra/nvidia-deep-research
# Run the install script
./install.sh该脚本使用 Terraform 来配置完整的环境,包括 VPC、EKS 集群、OpenSearch Serverless 集合,以及适用于 GPU 实例(如 G5、P4、P5 等)的 Karpenter NodePools。整个过程通常需要 15 至 20 分钟。
第 2 步:设置环境
基础设施准备就绪后,运行设置脚本。该脚本将配置 kubect l 以访问您的新集群,并提示您输入 NVIDIA NGC 和 Davily API 密钥。
./deploy.sh setup第 3 步:构建 OpenSearch 图像
该步骤用于构建自定义的 Docker 镜像,实现 RAG blueprint 与 OpenSearch Serverless 向量数据库的集成。
./deploy.sh build第 4 步:部署应用程序
您现在有两个部署选项。
选项 1:仅针对文档问答、知识库检索及自定义 RAG 应用部署企业级 RAG:
./deploy.sh rag这将部署 RAG 服务器、多模态数据摄入管道以及 Llama Nemotron Super 49B v1.5 推理 NIM。
选项 2:部署完整的 AI-Q 研究助手,包含选项 1 的全部内容以及 AI-Q 组件,其中包括用于生成报告的 Llama 3.3 70B Instruct NIM 模型和 Web 搜索后端。
./deploy.sh all此过程需要 25 至 30 分钟,因为涉及 Karpenter 调配 GPU 节点(例如 g5.48xlarge)以托管 NIM 微服务,以及启动这些微服务。
访问 blueprint
服务已通过 kubectl port-forward 实现安全公开,相关资源库中包含用于管理该操作的辅助脚本。
- 前往 blueprints 目录:
cd ../../blueprints/inference/nvidia-deep-research- 要访问企业 RAG UI:
./app.sh port start rag- 您现在可以通过 http://localhost:3001 访问 RAG 前端,上传文档并进行提问。
- 如已部署,您也可通过该地址访问 AI-Q 研究助手的用户界面:
./app.sh port start aira- 访问 http://localhost:3000 以打开 AI-Q 前端,生成完整的研究报告。
访问监控
该解决方案包含一个预构建的可观察性堆栈,集成了多个关键组件:用于监控 RAG 指标的 Prometheus和 Grafana,支持 RAG 工作流分布式追踪的Zipkin,用于追踪 AI-Q 助手复杂智能体工作流的Phoenix,以及实现全面 GPU 监控的 NVIDIA DCGM。
您可以使用相同的端口转发脚本访问控制面板。
- 启动可观察性端口转发:
./app.sh port start observability - 在浏览器中访问以下监控界面:
- Grafana: http://localhost:8080 (查看指标及 GPU 监控面板)
- Zipkin: http://localhost:9411 (用于 RAG 的分布式追踪)
- Phoenix: http://localhost:6006 (用于 AI-Q 的智能体工作流追踪)
清理
GPU 实例可能带来高昂的成本,因此及时清理资源至关重要。
1. 卸载应用程序
删除 RAG 和 AI-Q 应用程序(此举将触发 Karpenter 终止高成本的 GPU 节点),但保留 EKS 集群及其他基础设施。
# From blueprints/inference/nvidia-deep-research
./app.sh cleanup该脚本用于停止端口转发,并卸载为 RAG 和 AI-Q 部署的 Helm 版本。
2. 清理基础设施
要永久删除整个 EKS 集群、OpenSearch 集合、VPC 以及所有相关联的 AWS 资源,请执行以下操作:
# From infra/nvidia-deep-research
./cleanup.sh此操作将执行 terraform destroy,以清除由 install.sh 脚本创建的所有资源。
总结
NVIDIA AI-Q 深度研究助手和企业 RAG blueprint 是基于安全且可扩展的 AWS AI 基础设施构建的可定制参考示例。该方案集成了多项核心 AWS 服务,包括用于工作流编排的 Amazon EKS、支持成本优化的 GPU 自动扩缩容的 Karpenter、用于托管安全向量数据库的 Amazon OpenSearch Serverless,以及用于对象存储的 Amazon S3。
借助这些集成式解决方案,您可以部署可扩展的研究助手和生成式 AI 应用,高效处理并整合海量企业数据,提炼关键洞察,同时显著提升性能与成本效益。
立即部署 NVIDIA 企业级 RAG 或 AI-Q 深度研究蓝图,开启将企业数据转化为安全、可操作智能的进程。




