
AI 原生服务暴露了 AI 基础设施的新瓶颈:随着数百万用户、智能体和设备需要访问智能,挑战正在从峰值训练吞吐量转向大规模提供确定性推理 — — 可预测的延迟、抖动和可持续的 token 经济效益。
NVIDIA 宣布在 GTC 2026 上,电信公司和分布式云提供商正在将其网络转变为 AI 网格,在区域 POP、中心办公室、地铁中心和边缘位置的网格中嵌入加速计算,以满足 AI 原生服务的需求。
本文将介绍 AI 网格如何通过在分布式、工作负载、资源和 KPI 感知型 AI 基础设施中运行推理,实现大规模的实时、多模态和超个性化 AI 体验。
跨分布式站点的智能工作负载放置
NVIDIA AI Grid 参考设计提供了一个统一的框架,用于构建地理上分布式、互联且经过编排的 AI 基础设施。图 1 显示了现有网络资源如何组合成 AI 网格:
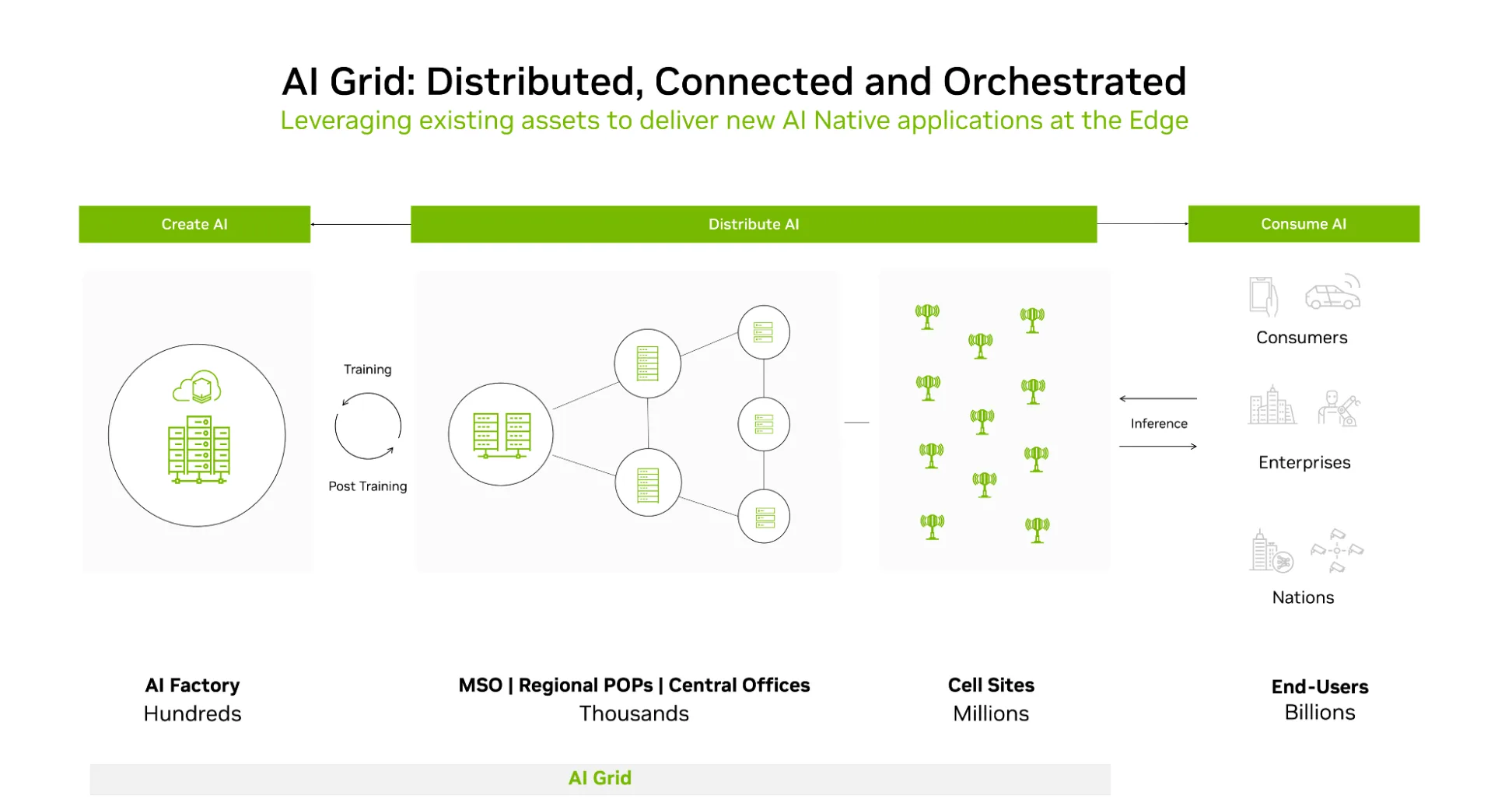
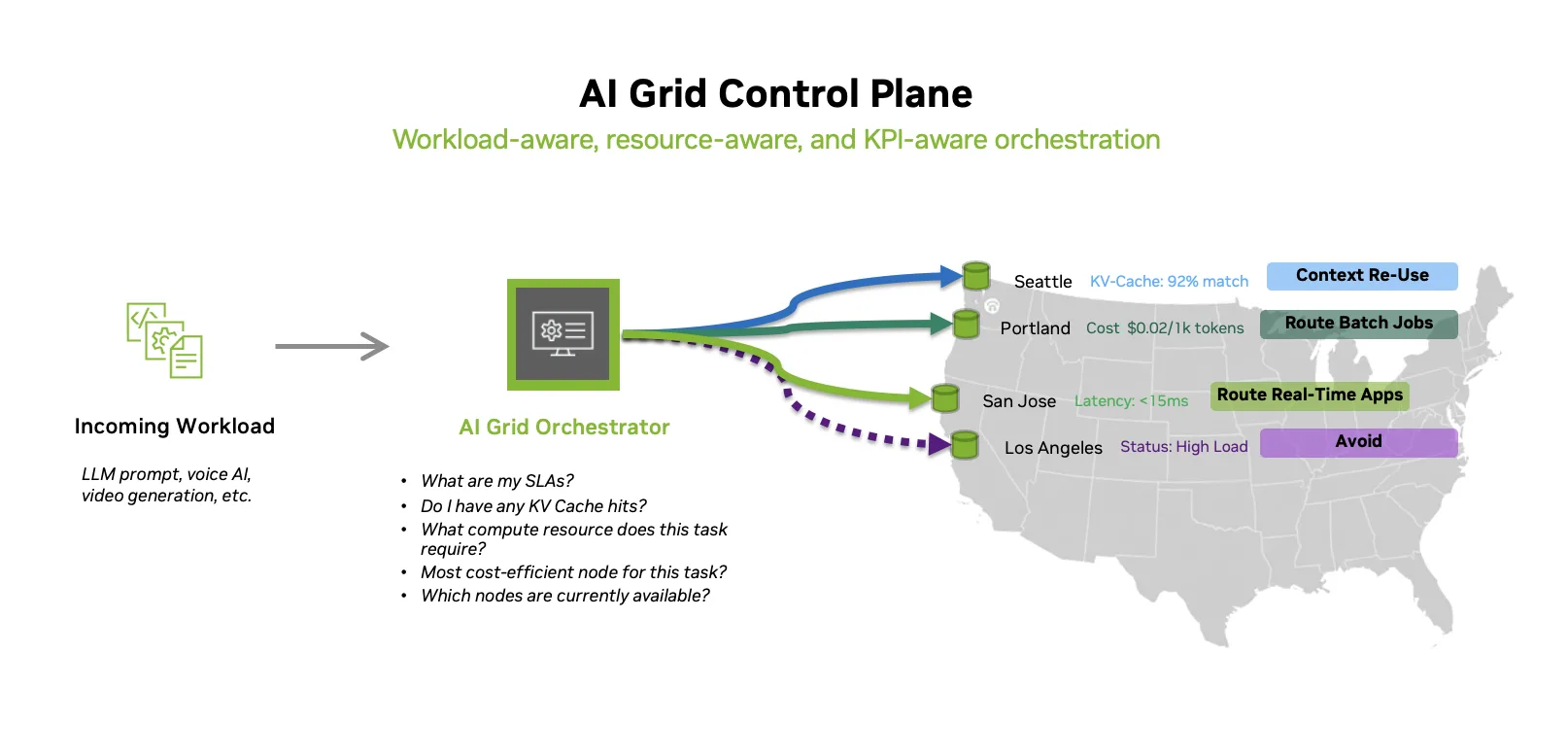
这种设计的一个关键方面是 AI 网格控制平面,它将孤立的集群和区域转变为单个可编程平台。其主要关注点是智能地确定每个工作负载应在何处运行,以满足其 KPI:
- KPI 感知路由,根据延迟要求、主权限制和成本放置工作负载。
- 持续考虑节点运行状况、利用率和配额的资源感知放置可在用户看到尾部延迟峰值之前避免站点过载或降级。兼容流量还被引导到具有高 KV 缓存命中概率的节点,从而降低每个请求的 token 延迟和 GPU 周期。
从 AI 网格中获益匪浅的工作负载
对于延迟、带宽、个性化或主权成为一阶设计限制的应用,智能工作负载布局至关重要。
下表将这些工作负载类别映射到示例应用程序及其必须优化的 KPI,以提供一致的用户体验和可持续的经济效益。
| 工作负载等级 | 示例应用 | 目标 KPI |
| 实时、延迟、敏感的控制循环 | 物理 AI (机器人、传感器) 、对话智能体、AR/ VR、可穿戴设备 | SLA 中的端到端延迟和抖动 |
| token 和带宽密集型多模态 | 视觉和媒体 AI 工作负载,与文本相比,可生成多达 100% 的原始数据 | 网络带宽和出口经济学 |
| 大规模的超个性化体验 | 按用户推荐,在 app copilot 中,动态媒体插入 | 在延迟和成本预算内实现高并发 |
| 自主和受监管的数据工作负载 | 政府 AI、医疗健康、金融服务、受监管的企业数据 | 所在司法管辖区保存的数据、模型和日志 |
AI 网格不仅能够加速经典边缘应用,还解锁了一套围绕实时生成和个性化构建的全新 AI 原生服务。以下各节将介绍 AI 网格如何大规模支持三种此类工作负载:语音、视觉和媒体。
语音 AI 网格
为什么延迟对语音 AI 至关重要
人类级语音 AI 服务对端到端延迟极其敏感。当响应超过 500 毫秒时,对话明显滞后于用户。因此,在客户端满足这种“Time-to-first-token” ( TTFT) 要求就变成了硬 SLO (服务水平目标) 。
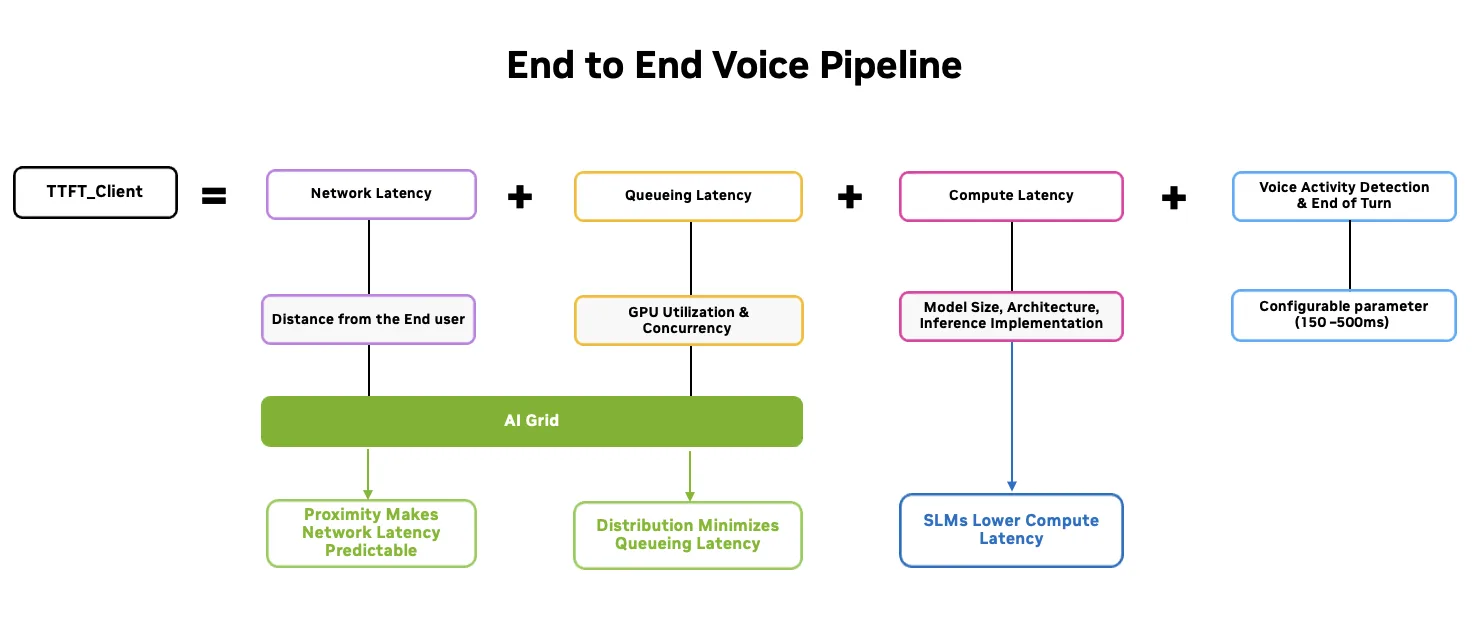
客户端的 TTFT (TTFT_Client) 是五个组件的总和:
- 网络往返时间 (RTT) :音频和 tokens 在用户和推理端点之间通过网络传输的时间
- 排队延迟:请求在 GPU 或服务上排队等待,然后开始执行。
- 计算延迟:
- Tokenization: 将传入音频转换为语音模型可处理的 tokens 的时间。其中包括自动语音识别 (ASR) 和文本转语音 (TTS) 。
- 预填充和解码:模型在处理提示 (预填充) 和生成第一个 token (解码) 时所花费的时间
- 语音活动检测 (VAD) :检测用户开始和停止说话的时间,以准确地确定每个回合的情况。
- RTT 和排队延迟在很大程度上取决于其中推理运行,使 AI 网格能够提供有意义的延迟改进。
端到端延迟
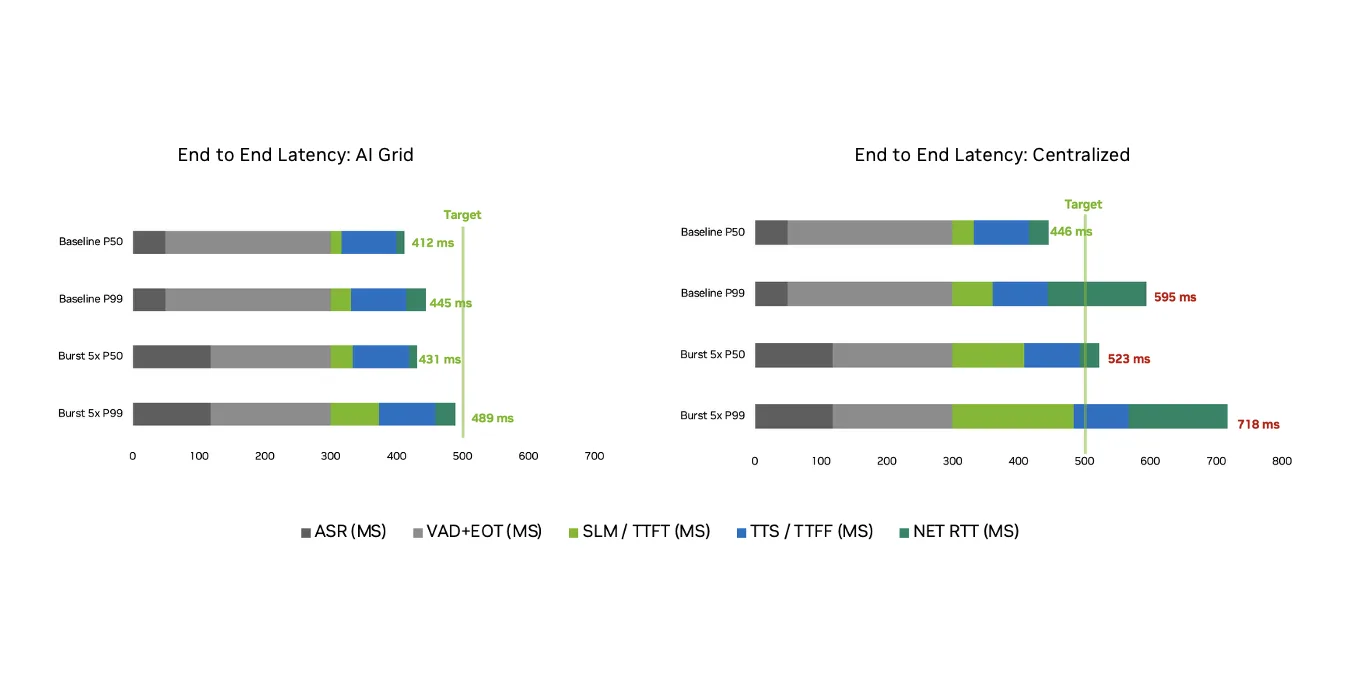
上述来自 Comcast 的基准测试比较了相同的语音小语言模型 (SLM) ,该模型由运行在 4 个 NVIDIA RTX PRO 6000 GPU 上的个人 AI 构建而成,采用两种架构:一个集中式集群和一个分布在 4 个站点的 AI 网格,这两种架构都会出现大量高度相关和并发会话,其中语音 AI 服务压力最大。
在所有测试场景中 (从第 50 百分位 (P50) 基准流量到第 99 百分位 (P90) 突发流量) ,AI 网格部署可在 500 毫秒的目标内保持语音交互的端到端延迟,即使并发会话高峰也是如此。这是通过在区域边缘节点上进行推理、缩短网络往返时间和减少排队延迟来实现的。
每个 token 的吞吐量和成本
此基准测试的另一个关键发现是相关突发流量的吞吐量性能。吞吐量不会在更高的负载下降低,而是随着四个边缘节点并行吸收需求而增加,在突发时达到 42362 tokenss (比基准增益 80.9%) ,而集中部署在相同条件下损失吞吐量。
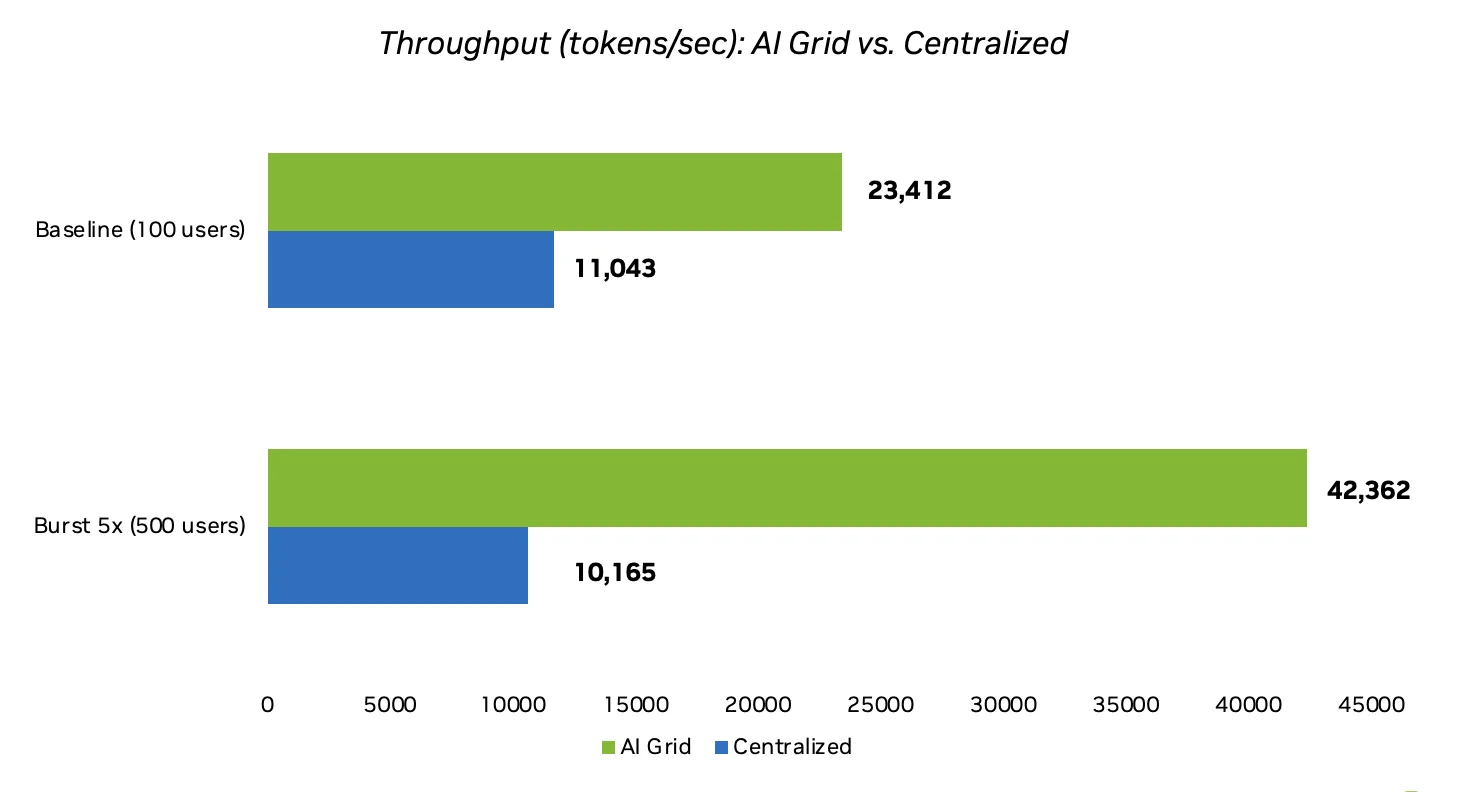
因此,在 AI 网格上运行推理的成本 – token 比在基准上进行集中式部署的成本低 52.8%,并且随着分布式 GPU 利用率随着负载的增加而提高,这种差距扩大到在突发时将 – token 成本降低 76.5%。集中式集群在 RTT 上消耗大量延迟预算,因此它们必须以更低的利用率运行,以避免违反延迟规定,而 AI 网格部署可保持较低的 RTT,并可以安全地在相同的延迟目标下提高 GPU 的性能。
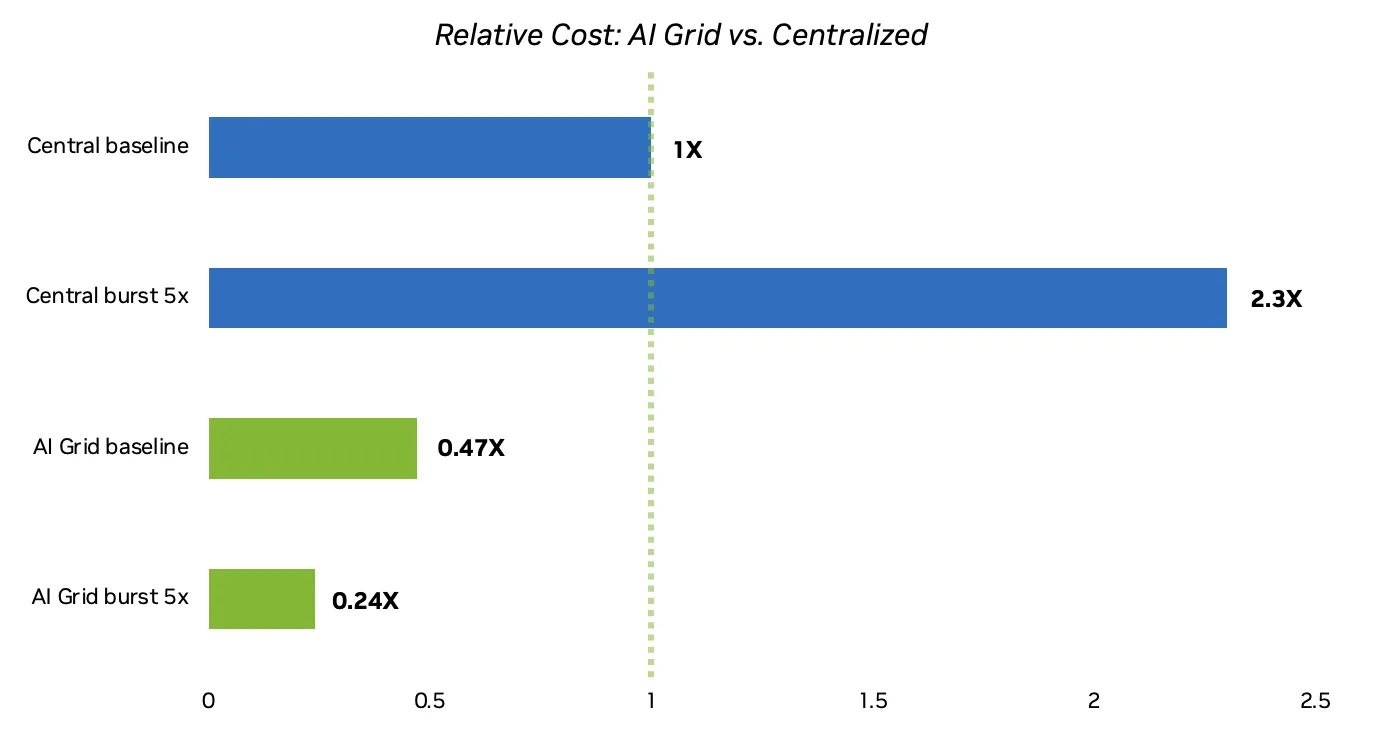
在生产环境中,吞吐量和每 token 成本的提升可能会因模型选择、工作负载特性和实时网络条件而异。
视觉 AI 网格
边缘 Metropolis:从感知到行动
与基于文本的服务相比,视觉 AI 工作负载传输的数据量要多得多,在城市规模下,并发视频流量通常会产生 Tbs 的吞吐量。为了实现这一目标,AI 基础设施必须保持足够低的延迟,以便实时做出反应,将原始视频保留在正确的管辖范围内,并避免将网络回传变成系统的主要成本。
为了满足这些需求,NVIDIA Metropolis 视觉 AI 应用平台可以在边缘的 AI 网格节点、运营商管辖范围内以及隔离的网络切片上运行。摄像头会串流到附近的节点,在这些节点中,模型会对个人身份信息进行匿名化处理,理解多个源中的场景,并触发重新规划流量或派遣接线员等操作。
网络切片、高分辨率和带宽
在仅集中式云部署中,视频数据会遍历多个网络跃点进行处理并返回给运营商。每次网络跳跃时增加的物理距离增加了固有的延迟,并增加了遇到故障或拥塞的几率。
在更高效的设计中,运营商可以通过将边缘分析与按需上采样分辨率相结合来减少回传。例如,摄像头可能以 360p (约 2 Mbps) 的速度进行流式传输,而超分辨率模型仅在操作员需要检查场景时才会重建 4K 视图,因此全分辨率视频仅在需要时通过区域或主干链路传输。
在 AI 网格上部署时,推理会在本地边缘节点的 RTX PRO GPU 上运行,并且只有轻量级警报和元数据会通过网络发送到集中式系统,以实现全车队监控、跨站点关联和长期分析。最终,端到端响应时间将持续缩短,且更加可预测。
此外,网络切片可以为 Metropolis 工作流提供用于安全关键型事件和分析的专用隔离带宽,确保始终优先处理安全关键型视觉工作负载,并获得确定的吞吐量和延迟,而不会对整个网络进行过度配置。
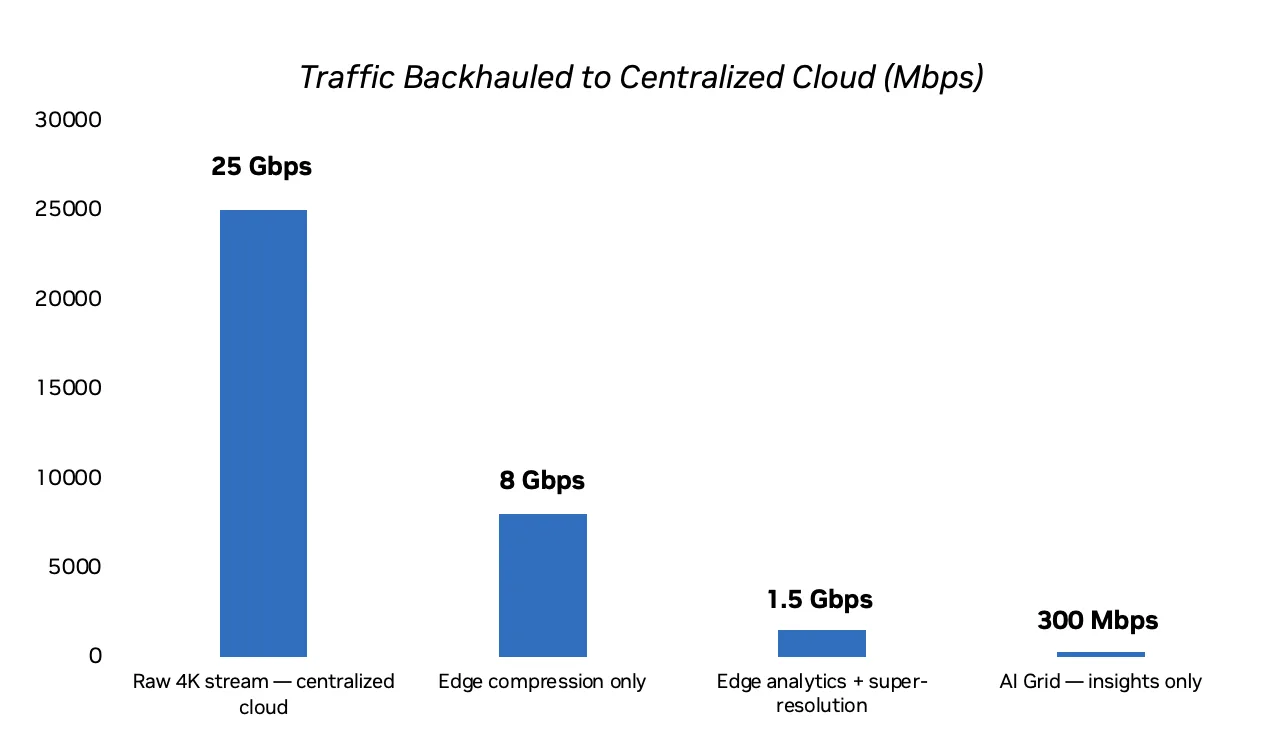
对于拥有 1000 个 4K 摄像头的代表性部署,从集中处理到边缘压缩,然后再到边缘分析和超高分辨率,可以将持续的主干负载从数十 Gbps 减少到低单位数 Gbps 范围。图 7 中显示的数字具有说明性,会因摄像头设置、压缩配置文件、模型选择和实时网络条件而异,但不同部署模型之间的相对节省预计也将遵循相同的模式。
适用于媒体的 AI Grid
超个性化是一项基础架构挑战
超个性化是指媒体 AI 在每个会话中都是连续的,内容、叠加、语言和建议可以实时适应每个观众。这些工作负载的独特之处在于,结果的价值很快就会过期:广告填充过晚会导致抖动,错过直播窗口的体育叠加功能无关紧要,提供的推荐内容过慢会损失购买时间。下表 2 重点介绍了具有代表性的媒体 AI 用例、它们的运行截止日期,以及 AI 网格如何执行每个用例以确保严格遵循
表 2 以下重点介绍了具有代表性的媒体 AI 用例、它们的运行截止日期,以及 AI 网格如何执行每个用例以保持严格的时间预算内:
| 用例 | 截止日期 | 限制 | AI 网格执行模型 |
| 实时广告插入 | 16 毫秒 | 60 fps 帧预算 | 每隔几秒钟对上下文进行采样;轻量级每帧着色器可渲染具有确定性的填充 |
| 体育分析叠加 | < 1 秒 | 节拍直播源 | 遥测技术可在广播时刻结束之前转换为叠加层 |
| 电子商务推荐 | 小于 200 毫秒 | 反弹值 | 在边缘节点上进行向量重新排序,明确优先考虑速度而非深度推理 |
| 实时视频翻译 | 小于 10 毫秒 | 音频+ 字幕同步 | ASR、翻译和 TTS 在 net 上运行;边缘放置同步保存音频、字幕和视频 |
Comcast 和 Decart 的基准测试验证了 AI 网格通过减少网络跳跃和每次跳跃的争议减少抖动,从而使计算更接近内容交付地点,从而持续满足此类截止日期的要求。这样可以在区域范围内吸收相关的需求峰值,并避免通过集中式设施路由推理流量所带来的回传。
与突发语音流量一样,通过在多个边缘站点分配并发视频生成需求,运营商可以提高 GPU 的利用率,从而提高吞吐量,并降低交付每个流的有效成本。
媒体工作流如何在 AI 网格上运行
在 AI 网格中,媒体工作负载在分布式边缘节点上作为低延迟流式传输管道运行,而不是在远程云中作为集中式作业运行。
NVIDIA Holoscan 可协调这些网格节点上的帧和音频片段流 (从提取到理解和渲染) ,以便在不影响帧或响应预算的情况下,实时执行广告插入、叠加和个性化阶段。
基于 NVIDIA Maxine™ 的服务可在相同的边缘节点上处理实时视频增强,而 NVIDIA Riva 和 LipSync 等语音和翻译服务可保持多语种音频和视频同步,而无需额外的网络跳跃。
视频生成模型和出口经济学
视频生成模型产生的数据量远超纯文本 LLM。例如,Decart 的 Lucy 2 视频生成模型的生成速度约为 5.5 Mbps/ 秒。与基于文本的 LLM 相比,10 分钟的视频生成会话生成的数据量增加了 825000 倍,显著增加了出口带宽。
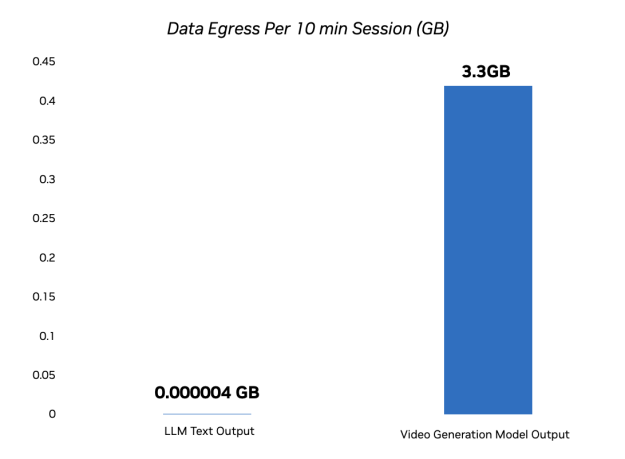
通过使视频生成更接近最终用户,AI 网格即使在个性化和并发性增长的情况下,也能使 AI 赋能的媒体体验具有经济效益和沉浸感。
AI+ 原生服务需要 AI 网格
电信公司和内容交付提供商正成为大规模交付 AI+ 原生服务推理的核心,将网络转变为模型执行路径的一部分,而非被动管道。借助跨 AI 工厂和分布式边缘站点的工作负载感知路由,运营商可以将语音、视觉和媒体等 AI 服务引导到正确的位置,从而使每个工作负载满足其延迟、并发、成本和主权要求。
开始使用
探索 AI 网格参考设计,深入探讨本文中讨论的架构和部署模式。




