
随着 AI 模型日益复杂,往往超出可用硬件的承载能力,量化技术已成为应对这一挑战的关键手段,使资源密集型模型得以在受限的硬件上运行。NVIDIA TensorRT 和 Model Optimizer 工具能够简化量化流程,在提升模型运行效率的同时,有效保持其准确性。
本博客系列面向初次接触 AI 研究的开发者,旨在阐明量化的基本原理,并聚焦于实际应用。通过本文,您将理解量化的工作机制以及适用场景。
量化的优势
模型量化使得在资源受限的环境中部署日益复杂的深度学习模型成为可能,同时能够在很大程度上保持模型的准确性。随着人工智能模型(尤其是生成式AI模型)规模和计算需求的不断增长,量化技术通过降低模型参数(如权重和激活值)的精度(例如从FP32降至FP8),有效应对了内存占用、推理速度和能耗等方面的挑战。相比原始模型,这种精度调整能够显著减小模型体积并降低计算开销,从而加快推理速度并减少功耗。然而,量化也可能带来一定程度的精度损失。因此,如何在模型准确性与运行效率之间取得合理平衡,往往取决于具体的应用场景。
量化数据类型
数据类型(例如 FP32、FP16、BF16 和 FP8)直接影响模型所需的计算资源,进而决定其运行速度与效率。模型参数可用多种浮点格式表示,常见的包括 FP32、FP16、BF16 和 FP8。通常,浮点数采用 n 位来存储数值,并将这些位划分为三个组成部分:
- 符号: 该位表示数值的符号,0 代表正数,1 代表负数。
- 指数: 该部分对指数进行编码,表示以底数(在二进制系统中通常为 2)为基数的幂次,决定了数值的表示范围。
- 尾数(或有效数): 该部分表示数值的有效数字,其长度在很大程度上决定了数据的精度。
用于此表示的公式为:

由于指数和尾数所占用的位数可能不同,数据类型有时会进一步细分。例如,FP8 中的 E4M3 表示使用 4 位表示指数,3 位表示尾数。图 1 展示了多种数据类型(包括 FP16、BF16、FP8 和 FP4)的格式及其对应的数值表示范围。
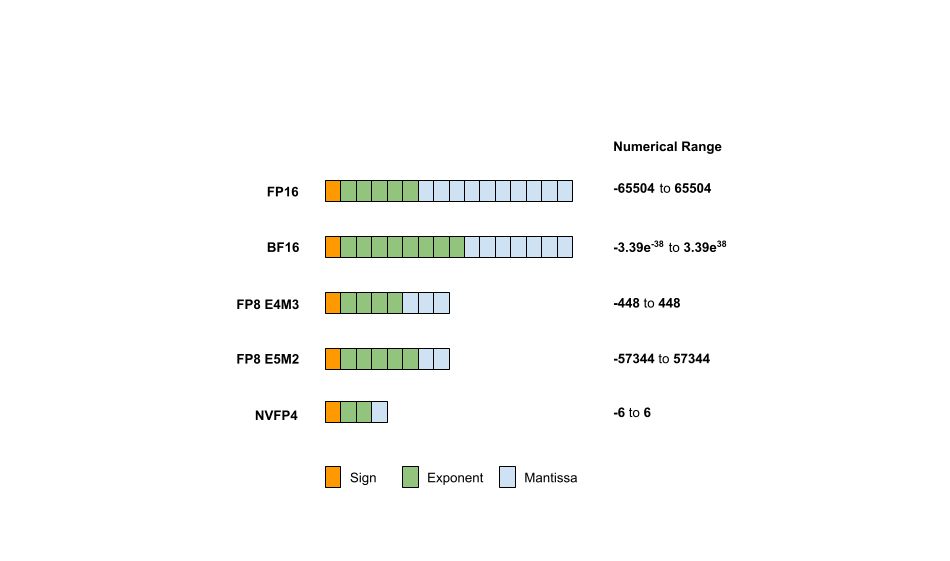
您可以量化的三个关键要素
一种较为简便的方法是量化模型的权重,以降低内存占用。然而,还有其他组件也可以进行量化。其中,模型激活是另一个关键部分,它指的是模型在推理过程中各层操作所产生的中间输出。尽管这些激活值具有动态性,并不显式地存储在模型中,但在量化过程中仍起着至关重要的作用。
将 Llama2 7B 模型以 FP16 或 BF16 格式存储时,每个参数占用 2 个字节,总共约需 14 GB 显存(7B 参数 × 2 字节/参数)。若将模型量化至 FP8,模型权重所需的显存可降至约 7 GB,显存占用减少一半。此外,量化后的模型在计算过程中,其中间激活值可利用专用的 Tensor Core 硬件进行处理,在降低位宽的同时提升计算吞吐量,从而进一步加快推理速度。
对于基于 Transformer 的解码器模型,推理阶段需考虑的另一个关键组件是 KV 缓存。这是解码器模型特有的机制,通过在自回归生成输出 token 时缓存键(Key)和值(Value)状态,从而加快生成速度。KV 缓存的大小与序列长度、网络层数以及注意力头的数量密切相关。以支持较长上下文窗口(例如 4096 个 token)的 Llama2 7B 模型为例,KV 缓存在总显存占用中可能额外增加数 GB 的内存开销。
总之,在当前基于 Transformer 的模型中,可以对三个关键要素进行量化:模型权重、模型激活以及 KV 缓存(仅限于解码器模型)。
量化算法
现在,您已经对量化有了基本了解,接下来将介绍量化算法,展示如何将高精度数值转换为低精度表示。该过程涉及确定零点和缩放系数的不同方法,由此衍生出两种主要的量化类型:仿射(非对称)量化和对称量化。
仿射量化与对称量化的对比分析
量化将浮点值映射到低精度格式,例如将 FP16 浮点值 ![{\LARGE x \in [\alpha, \beta]}](https://s0.wp.com/latex.php?latex=%7B%5CLARGE+x+%5Cin+%5B%5Calpha%2C+%5Cbeta%5D%7D&bg=transparent&fg=000&s=0&c=20201002)

![{\large x \in [-65504,\, 65504]}](https://s0.wp.com/latex.php?latex=%7B%5Clarge+x+%5Cin+%5B-65504%2C%5C%2C+65504%5D%7D&bg=transparent&fg=000&s=0&c=20201002)
![{\large x_q \in [-448,\, 448]}](https://s0.wp.com/latex.php?latex=%7B%5Clarge+x_q+%5Cin+%5B-448%2C%5C%2C+448%5D%7D&bg=transparent&fg=000&s=0&c=20201002)
仿射量化
仿射或非对称量化由两个关键参数定义:比例系数 

确定这些参数后,便可启动量化过程。

其中:
-
是原值
-
是量化值
-
-
-
,
定义量化表示的范围
-
将缩放值转换为最近的量化表示
-
确保值保持在量化表示的范围内
要从量化值中恢复近似的全精度值,请按以下步骤操作:

其中, 
在量化与去量化过程中,不可避免地会产生四舍五入误差和截断误差,这些误差是量化过程本身固有的特性。
对称量化
对称量化是对一般非对称量化情况的简化形式。当将零点固定为 0 时,该量化方式可有效减少计算开销,因为它消除了大量加法运算。其量化与去量化公式如下:


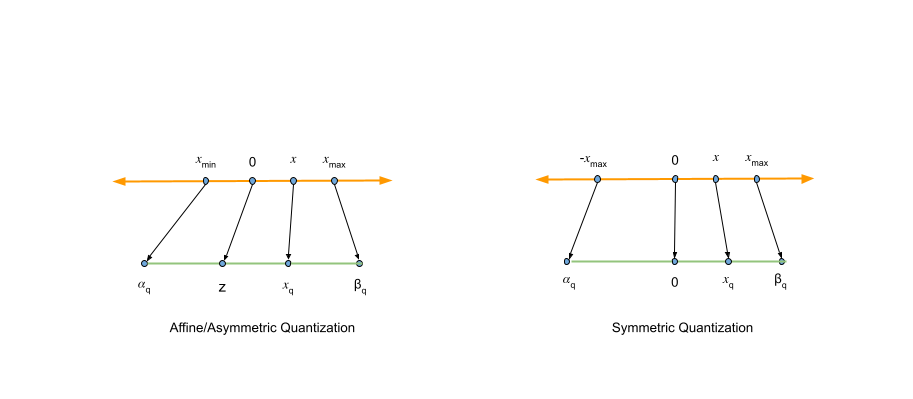
图2 对称量化与仿射量化的对比
由于非对称量化相较于对称量化并未带来明显的精度提升,因此后续将重点支持对称量化方案,因其结构更简单、实现更高效。此外,NVIDIA TensorRT 和 Model Optimizer 等主流工具均采用对称量化,这也符合当前行业的普遍实践。
AbsMax 算法
比例系数在其中起着关键作用,但其具体数值究竟是如何确定的呢?本节将介绍一种常用的量化方法——AbsMax量化,该方法因具有简单性和良好的实用性而被广泛应用于这些数值的计算。
比例系数

该值取决于实际输入数据的范围以及目标量化表示的范围。
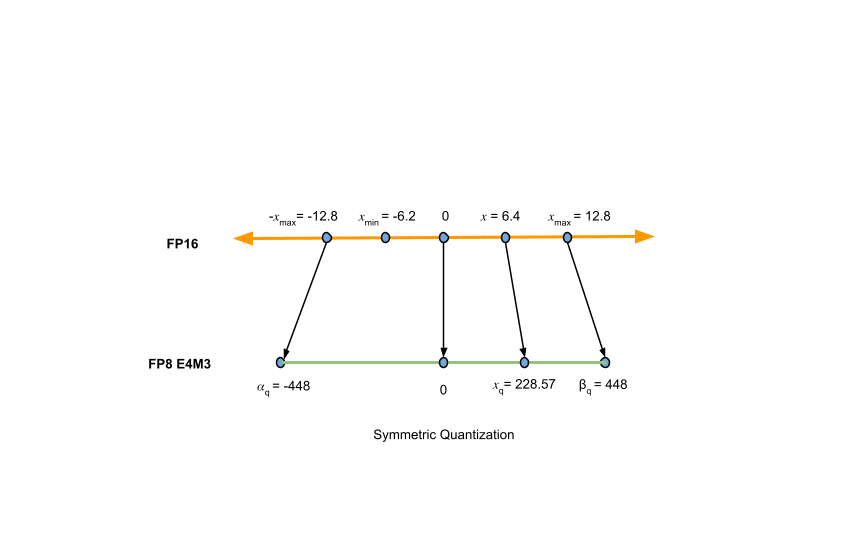
图3展示了采用AbsMax算法将FP16量化为FP8的对称量化过程,其量化尺度如下所示:

给定 

量化粒度
到目前为止,我们已经定义了量化参数,了解了如何执行量化操作,并掌握了基于基本 AbsMax 方法的量化计算。接下来,我们将探讨量化粒度,即量化参数在张量元素之间共享的方式。更具体地说,这指的是在 AbsMax 量化中计算原始数据的 

- 逐张量(或逐层)量化:张量中的所有数值均采用同一组量化参数进行量化。这种方法实现简单,内存效率较高,但可能带来较大的量化误差,尤其是在数据分布沿不同维度变化较大的情况下。
- 逐通道量化:各个通道分别使用独立的量化参数,通常应用于卷积操作中的通道维度。该方法能够将异常值的影响限制在其所属的通道内,避免波及整个张量,从而有效降低量化误差。
- 分块(或分组)量化:将张量划分为多个较小的块或组,每个块使用各自的量化参数。这种方法提供了更细粒度的控制,特别适用于张量内部不同区域数值分布差异较大的场景。

高级算法
除了基本的 AbsMax 算法外,还有一些先进的量化方法可在提升效率的同时,尽可能减少精度损失。本节将简要介绍其中应用较为广泛的三种方法。
- 激活感知型权重量化 (AWQ):AWQ 是一种纯权重量化方法,通过分析校准阶段收集的激活统计数据,识别并保护一小部分“显著”权重通道——即对模型性能起关键作用的通道。该方法对这些重要权重施加逐通道的扩展,从而有效降低量化误差,实现高效的低位宽量化。
- 生成式预训练 Transformer 量化 (GPTQ):GPTQ 通过逐行量化权重矩阵来压缩模型,利用近似的二阶信息(特别是 Hessian 矩阵)指导量化过程。这种方法能够显著减少因量化带来的输出误差,实现高精度的模型压缩,同时将性能下降控制在较低水平。
- SmoothQuant:SmoothQuant 采用数学上等效的逐通道缩放变换,对激活中的异常值进行平滑处理,将量化难度从激活转移至权重,在保持模型精度和硬件效率的同时,实现权重与激活的 8 位量化。
量化方法
量化模型权重相对简单,因为权重是静态的,不依赖于数据,在大多数情况下无需额外数据。与之不同,激活函数的值动态依赖于输入数据的分布,而不同输入之间的数据分布可能存在显著差异,从而影响理想的缩放系数。在预训练模型上进行此类校准的过程称为训练后量化(PTQ)。
在 PTQ 过程中,我们会在每一层的激活输出中插入观察者,利用代表性数据对模型进行量化和推理。观察者负责收集激活值,并采用预设算法确定相应的扩展系数。对于 AbsMax 量化方法,扩展系数基于激活输出中的最大绝对值计算得出,该值表示为 


训练后量化
PTQ 有两种主要方法:一种是仅对权重进行量化,另一种是对权重和激活函数同时进行量化。
在仅权重量化中,我们可以获取已训练模型的权重,并直接对这些权重进行量化。由于权重是已知且固定的,因此无需额外数据。该过程通过计算比例因子,将权重映射到较低精度的数值,可选择是否使用零点参数。
为了量化权重和激活值,需要使用具有代表性的输入数据,因为激活值只能通过在实际输入上运行模型才能获取。收集激活值的统计信息,并据此确定相应的缩放因子和零点值的过程称为校准。在校准过程中,模型的权重保持不变,利用输入数据计算量化的参数,即缩放因子和零点。根据校准发生的时间不同,权重与激活值的量化可分为两种主要方法:静态量化与动态量化。
- 静态量化:该方法通过校准数据集预先计算量化参数,参数确定后即保持固定,并可重复应用于后续的所有推理过程。
- 动态量化:该方法在推理过程中实时计算量化参数,因此不同输入可能产生不同的量化参数,且无需依赖校准数据集。
量化感知训练
量化感知训练(QAT)是一种旨在缓解模型量化过程中常见性能下降问题的技术。与在训练完成后进行量化的后训练量化(PTQ)不同,QAT 将量化效应直接融入训练过程。具体而言,在前向和反向传播中模拟低精度计算,使模型参数能够学习并适应由量化引入的误差,例如舍入和截断误差。
在QAT期间,模型通过引入“假量化”模块来模拟低精度运算行为,同时保持实际数据类型不变。这些模块对模型的权重和激活值进行量化后再进行去量化,使模型能够感知量化带来的影响,同时维持梯度更新过程中的高精度计算。通常情况下,在QAT过程中,“假量化”模块会被冻结,并对模型权重进行微调。
为了解决量化函数不可微的问题(例如训练过程中的四舍五入操作),量化感知训练(QAT)采用了直通估计器(STE)。STE 在反向传播过程中将这些不可微函数的梯度近似为 1,从而在存在非可微运算的情况下,仍能实现有效的模型训练。
总结
本文介绍了量化的理论基础,涵盖了不同浮点格式的技术背景、主流量化方法(如PTQ和QAT),以及需要量化的对象,包括模型权重、激活值和大语言模型中的KV缓存。
我们还推荐您阅读以下几篇优质的博客文章,以加深对量化的理解,并获得更深入的见解。




