
大语言模型(LLM)通过精密分析大量非结构化数据,生成切实可行的交易见解,正在重塑金融交易格局。这些先进的 AI 系统能够处理金融新闻、社交媒体情绪、收益报告和市场数据,以更高的准确性预测股价波动,并实现投资策略的自动化。
15 年多来,战略技术分析中心 (STAC) 一直致力于为金融行业的关键工作负载制定基准。如今,该机构已开发出 检索增强生成 (RAG) 与 大语言模型推理 工作流的 STAC-AI 基准测试,旨在帮助企业评估端到端的检索增强生成 (RAG) 与大语言模型推理工作流。
本文介绍了多个 NVIDIA 平台在 STAC-AI LANG6 基准测试中取得的成果,并分享一些建议,帮助用户根据其数据集的规格对 NVIDIA TensorRT LLM 进行基准测试。
STAC-AI LANG6 (仅推理) 基准测试
在更广泛的 RAG 工作流背景下,STAC-AI LANG6 作为基准测试的一部分,专注于评估 LLM 的推理性能。该基准测试结合以下自定义数据集,对 Llama 3.1 8B Instruct 和 Llama 3.1 70B Instruct 模型的硬件与软件堆栈进行测试:
- EDGAR4:提示总结了公司与各类物理及金融概念(如商品、货币、利率和房地产行业)其中之一的关系。其基于单一证券在一年内的 EDGAR 10+ K 段落,输入/输出序列长度旨在对中等长度请求进行建模。
- EDGAR5:涵盖完整 10+ K 提交中的多个不同方面问题。文档类型为单份 EDGAR 10+ K 提交的完整文本,输入/输出序列长度旨在对长上下文请求进行建模。
这些数据集基于 EDGAR 提交的文件,对金融交易和投资建议场景中的中长上下文信息进行了归纳。这些提示要求模型对过去五年中数千家上市公司的年度报告(10-K 提交文件)进行分析与总结。
该基准测试还涵盖了两种不同的推理场景,即批量模式与交互模式:
- 分批(离线)模式:所有请求一次性提交,所有响应一次性收集,仅测量吞吐量。
- 交互式(在线)模式:请求在伪随机时间点到达,可设置平均到达率(系统每秒接收请求的平均数量),以模拟不同的使用场景。该基准测试会收集多项指标,例如响应时间(RT)、每位用户的每秒字数(WPS/用户)和每秒总字数(WPS),但不对这些指标设定任何限制。在其他基准测试中,RT 类似于首字生成时间(TTFT),WPS 则类似于 tokens/second/user 的指标。
请注意,交互模式无法覆盖 Llama 3.1 70B Instruct 与 EDGAR5 的组合情况。
该基准测试会将输出结果与由大语言模型生成的响应控制集进行对比,评估输出质量和字数。
虽然其他基准测试允许所有预处理操作,但 STAC-AI 的一个重要区别在于,需在推理过程中应用聊天模板并对请求进行标记化。实际部署时,可能更倾向于在服务器端完成这些处理,以保护系统提示,但这会增加 CPU 的负载。
硬件和软件堆栈
本文对比了 HPE 提交的两台本地 NVIDIA Hopper-基于服务器与基于云的 NVIDIA Blackwell 节点。
- HPE ProLiant Compute DL384 Gen12 由 NVIDIA GH200 Grace Hopper 超级芯片 提供支持,可实现高效的单服务器解决方案。如需查看详细结果,请参阅 STAC 网站上的 Llama 3.1 8B 配套报告 和 Llama 3.1 70B 配套报告。
- 由 Nebius Cloud 提供的基于云的 VM,基于 NVIDIA GB200 NVL72 系统的单节点。该 VM 配备两个 NVIDIA Grace CPU 和四个 NVIDIA Blackwell GPU,通过 NVIDIA NVLink 和 NVSwitch 实现全互联,可最大限度提升网络吞吐量。有关 NVIDIA GH200 结果的详细信息,请参阅 Llama 3.1 8B 配套报告 和 Llama 3.1 70B 配套报告 在 STAC 网站上。
- 最新的本地部署方案采用 SuperMicro AS -5126GS-TNRT,配置两个 NVIDIA RTX PRO 6000 Blackwell 服务器版本,可在单个服务器中成对部署两个 Blackwell GPU,适用于 AI 开发与部署。每个 RTX PRO Blackwell GPU 配备 96 GB 显存,在相同系统空间内为更大模型、更大批量或更多并发任务提供充足的 GPU 显存总量。有关测试结果的详细信息,请参阅 Llama 3.1 8B 配套报告 和 Llama 3.1 70B 配套报告 在 STAC 网站上。
由于基准测试需在测试过程中进行后训练量化,因此采用 NVIDIA TensorRT Model Optimizer 对模型进行量化。为充分利用各部署平台上的高性能内核,我们在 NVIDIA Hopper 上对 FP8、在 NVFP4 上的 NVIDIA Blackwell 进行了量化。
为了在 Hopper 和 Blackwell 上实现优异性能,我们采用 NVIDIA TensorRT LLM 推理框架以实现高效的模型执行。这些量化模型通过 TensorRT LLM PyTorch 运行时 运行,在提供熟悉且原生的 PyTorch 开发体验的同时,保持峰值性能。
在 STAC-AI LANG6 上对结果进行基准测试
本节将详细阐述批处理模式与交互模式的基准测试结果。
批量模式
对于批处理模式,NVIDIA Blackwell 在所有场景中均能实现显著加速。表 1 展示了达到的 WPS 以及每秒请求数(RPS)。
请注意,NVIDIA GB200 NVL72 的测试结果未经 STAC 审核。
| 模型 | 数据集 | 2x GH200 144 GB TensorRT LLM FP8 |
4x GB200 NVL72 TensorRT LLM NVFP4 |
2x RTX PRO 6000 NVFP4 |
|||
| WPS | RPS | WPS | RPS | WPS | RPS | ||
| Llama 3.1 8B | EDGAR4 | 8237 | 51.5 | 37480 | 224 | 5500 | 32.9 |
| EDGAR5 | 304 | 0.784 | 1112 | 2.85 | 138 | 0.345 | |
| Llama 3.1 70B | EDGAR4 | 1071 | 6.77 | 5618 | 35.9 | 831 | 5.26 |
| EDGAR5 | 41.4 | 0.119 | 150 | 0.477 | 13 | 0.04 | |
有关交互式与批量模式的更多详细信息,请参阅 STAC 发布的完整报告。
我们还评估了单 GPU 性能,以考虑各系统上 GPU 数量的差异。尽管 STAC-AI 不对每块 GPU 的性能进行单独衡量,但图 1 所示的结果反映了各系统中单个 GPU 之间的吞吐量差异。
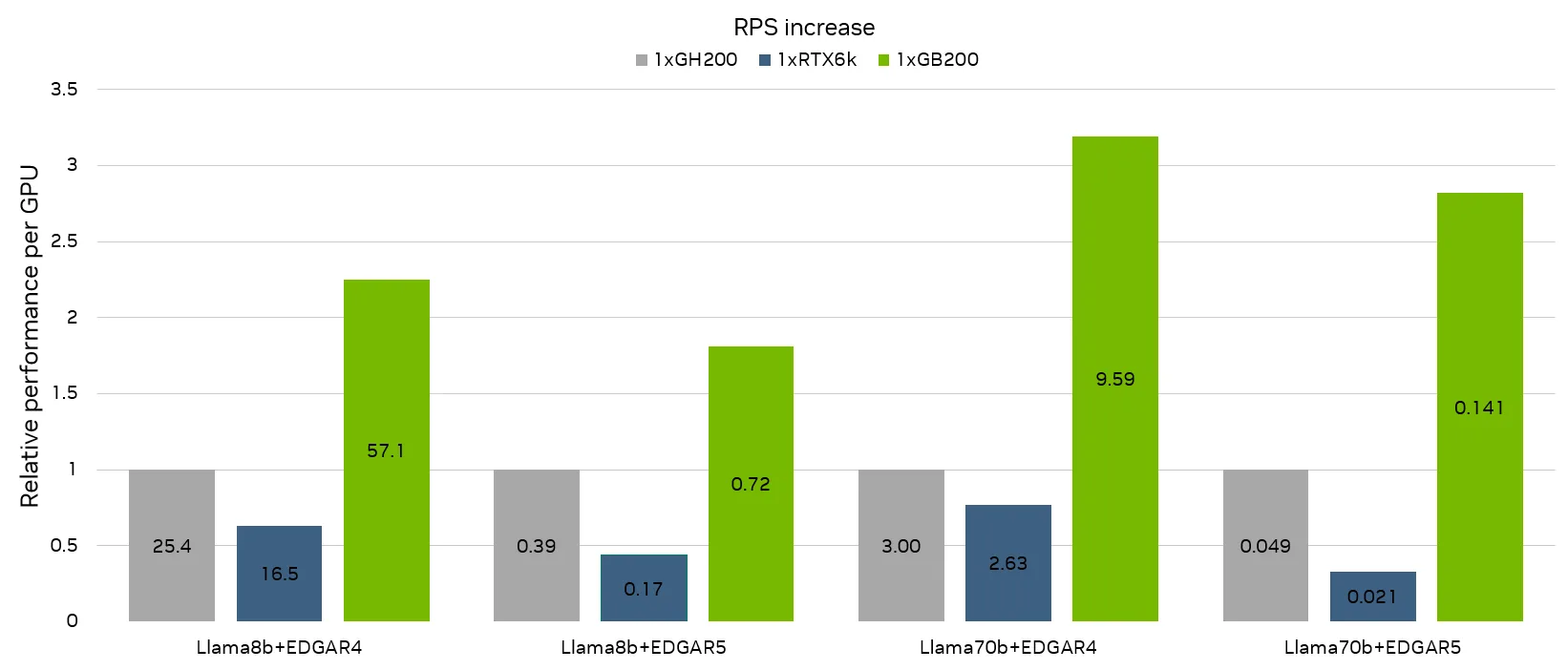
交互模式
Token 经济性(取决于吞吐量)与用户体验(取决于响应时间 RT 和每秒词数 WPS 等交互性指标)之间的平衡,是现代 LLM 推理的关键因素。
交互式模式通过选择不同的到达率范围,展示了交互性、吞吐量与帕累托前沿之间的权衡关系。交互性通过响应时间(RT)和每用户每秒写入词数(WPS/user)来衡量。为了便于可视化,我们采用 WPS/user 的倒数,即词间延迟(IWL),表示为 1𝑊𝑃𝑆/𝑢𝑠𝑒𝑟。在图表中,这两个指标均使用其第 95 百分位数值。
如图 2 所示,GB200 NVL72 在吞吐量与响应时间(RT)和交互窗口长度(IWL)之间实现了更优的整体平衡。在各类模型/数据集场景中,绘制了 IWL(实线,数值越低越好)和 RT(虚线,数值越低越好)随交互式模式吞吐量变化的对比图。
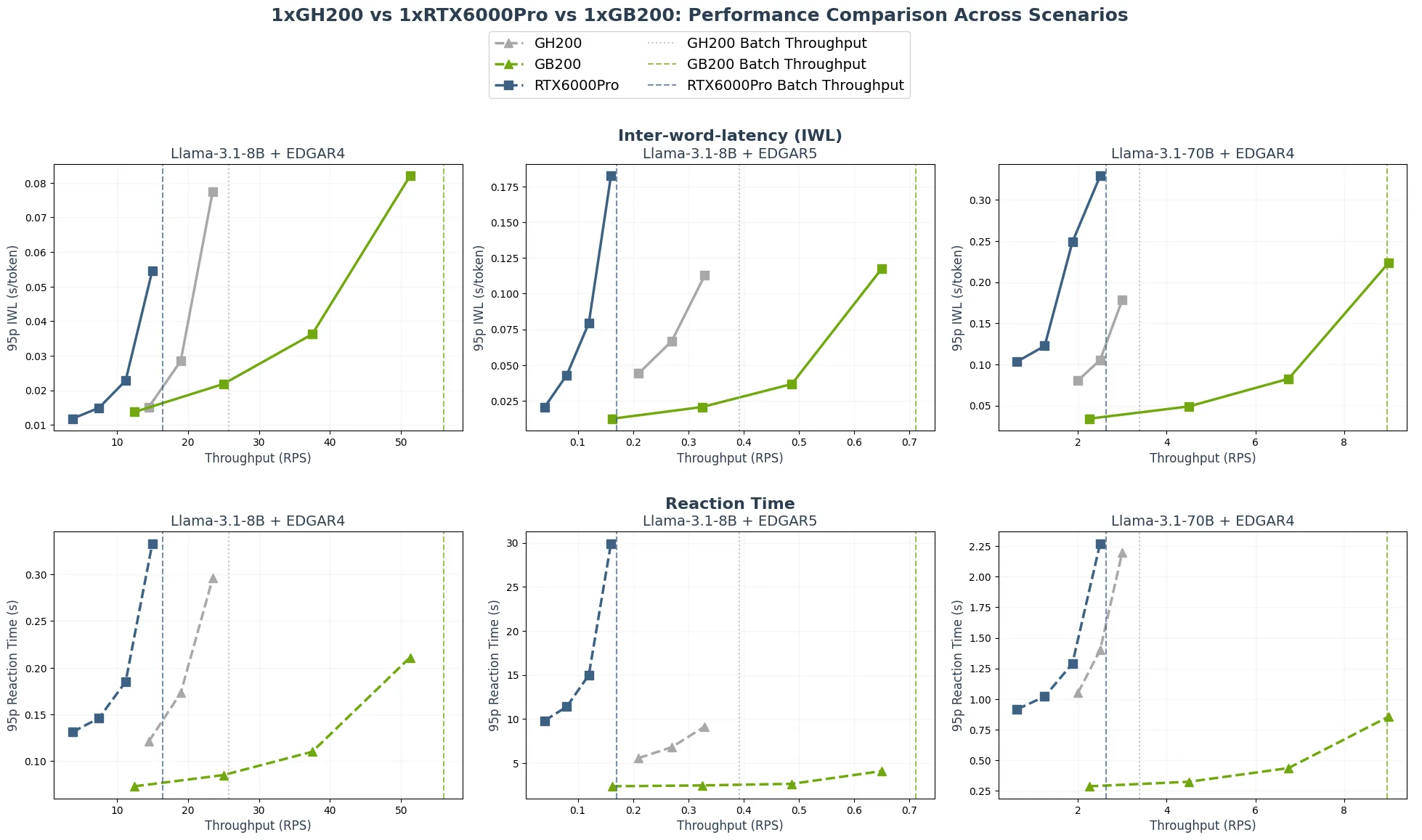
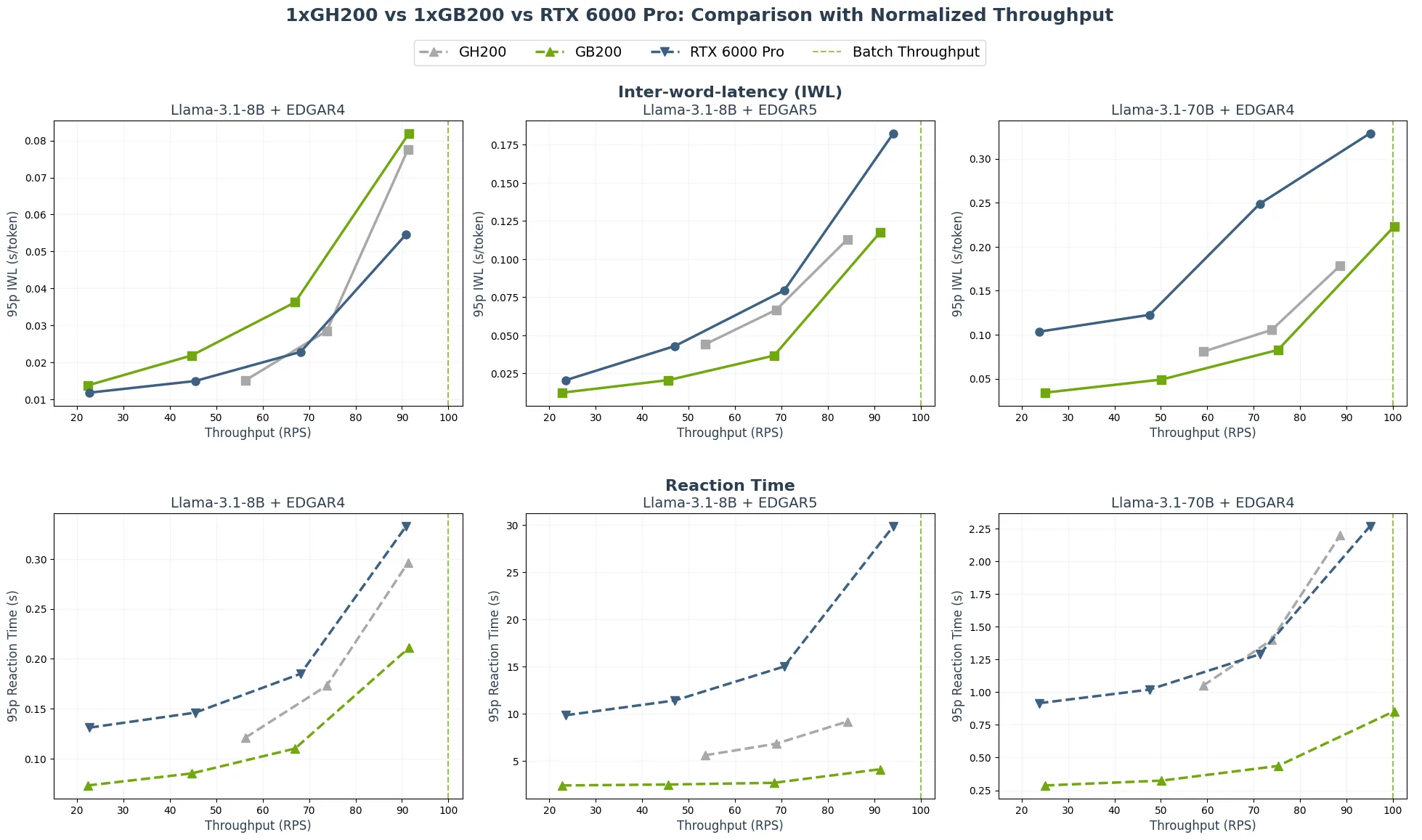
图 3 显示,即使在最大吞吐量百分比相近的情况下运行,NVIDIA GB200 NVL72 在多数场景中仍能实现更优的 RT 和 IWL。对 x 轴进行归一化处理可消除原始吞吐量带来的优势,从而凸显相同负载下的交互性表现。
如何使用自定义数据对 TensorRT LLM 进行性能基准测试
虽然 STAC 基准测试采用专有数据和指标,但您可以针对特定数据集特征定制的模型对 TensorRT LLM 进行基准测试。本教程将指导您完成模型量化、数据集准备以及性能基准测试的执行,所有步骤均根据您的具体用例进行定制。
预备知识:
- 包含 TensorRT LLM(例如 TensorRT LLM 版本)的 Docker 镜像。
- 具备足够显存的 NVIDIA GPU,能够在目标量化级别为您的模型提供服务。您可在 TensorRT LLM 文档中查阅量化功能的支持矩阵。
- 拥有 Hugging Face 账户及访问令牌,并具备对 Llama 3.1 8B Instruct 或 Llama 3.1 70B Instruct 门控模型的访问权限。您可将
HF_TOKEN环境变量设置为该令牌,后续所有命令将自动使用此令牌。
第 1 步:启动容器
由 NVIDIA 维护的容器已预装所有必需的依赖项。请切换至一个空目录,为模型及其量化过程预留充足空间。您可以使用以下命令在配备 NVIDIA GPU 的计算机上启动容器,请务必指定您的 Hugging Face token。
docker run --rm -it --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
--gpus=all \
-u $(id -u):$(id -g) \
-e USER=$(id -un) \
-e HOME=/tmp \
-e TRITON_CACHE_DIR=/tmp/.triton \
-e TORCHINDUCTOR_CACHE_DIR=/tmp/.inductor_cache \
-e HF_HOME=/workspace/model_cache \
-e HF_TOKEN=<your_huggingface_token> \
--volume "$(pwd)":/workspace \
--workdir /workspace \
nvcr.io/nvidia/tensorrt-llm/release:1.3.0rc2
第 2 步:克隆资源库
模型量化可减小模型体积并提升推理速度。使用 NVIDIA Model Optimizer 将 Llama 3.1 8B Instruct 量化为 NVFP4 格式。首先,克隆 Model Optimizer 仓库以获取量化示例:
git clone https://github.com/NVIDIA/TensorRT-Model-Optimizer.git -b 0.37.0
第 3 步:量化模型
接下来,使用选定的模型和量化格式运行 Hugging Face 示例脚本,本例中采用 NVFP4 量化方式执行 Llama 3.1 8B Instruct。
bash TensorRT-Model-Optimizer/examples/llm_ptq/scripts/huggingface_example.sh \
--model meta-llama/Llama-3.1-8B-Instruct \
--quant nvfp4
第 4 步:生成合成数据
使用基准测试工具生成包含任务所需 token 分布的合成数据集。本示例创建了 3 万个请求,输入序列长度固定为 2048,输出序列长度为 128。若可获取非零标准差信息,则数据分布将更接近真实流量。
python /app/tensorrt_llm/benchmarks/cpp/prepare_dataset.py \
--stdout \
--tokenizer meta-llama/Llama-3.1-8B-Instruct \
token-norm-dist \
--input-mean 2048 \
--output-mean 128 \
--input-stdev 0 \
--output-stdev 0 \
--num-requests 30000 \
> dataset_2048_128.json
第 5 步:运行基准测试
trt-llm bench 命令可离线运行生成的请求,将所有请求一次性发送至 TensorRT LLM 运行时(与 STAC-AI 批处理模式非常相似)。
虽然 CLI API 提供了一些选项,但完整的 LLM API 可通过包含 extra_llm_api_options 参数的 YAML 文件 进行访问。本示例中启用了 CUDA 图形填充。如需了解更多信息,请参阅 TensorRT LLM API 参考。
cat > llm_options.yml << 'EOF'
cuda_graph_config:
enable_padding: True
EOF
随后,运行基准测试,指定模型、数据集和选项:
trtllm-bench \
--model meta-llama/Llama-3.1-8B-Instruct \
--model_path /workspace/TensorRT-Model-Optimizer/examples/llm_ptq/saved_models_Llama-3_1-8B-Instruct_nvfp4 \
throughput \
--dataset dataset_2048_128.json \
--backend pytorch \
--extra_llm_api_options llm_options.yml
这将输出各类指标,例如请求吞吐量、每 GPU 每秒处理的 tokens 等。
开始使用 TensorRT LLM 基准测试
NVIDIA GB200 NVL72 在 STAC-AI LANG6 基准测试中显著提升了性能,创下金融领域 LLM 推理的新纪录。NVIDIA Blackwell 的性能达到前代架构的 3.2 倍,不仅实现了更高的吞吐量,还始终保持出色的交互性。
除创下新纪录外,NVIDIA Hopper 在大语言模型推理工作负载方面持续展现出卓越且富有价值的表现。自首次发布三年多以来,Hopper 在批量与交互式推理场景中均表现出色,即便在高吞吐量条件下仍能维持良好的性能指标,充分体现了其对金融机构的长期适用性与重要价值。
要深入了解如何设置和运行您自己的性能评估,请参阅 TensorRT LLM 基准测试指南。




