
推理模型的规模正在迅速增长,并且越来越多地集成到与其他模型和外部工具交互的代理式 AI 工作流中。在生产环境中部署这些模型和工作流需要将它们分布到多个 GPU 节点上,这需要在 GPU 之间进行仔细的编排和协调。
NVIDIA Dynamo 1.0 现已推出,通过加速大规模分布式环境中的生成式 AI 和推理模型来解决这些问题。该 AI 框架可为生产级多节点 AI 部署提供低延迟、高吞吐量、分布式推理。
Dynamo 支持领先的开源推理引擎,包括 SGLang、NVIDIA TensorRT LLM 和 vLLM。它还在值得信赖的第三方基准测试 (如 MLPerf 和 SemiAnalysis InferenceX) 中取得了优异的成绩,巩固了其作为生产级推理平台的地位。Dynamo 可以将 NVIDIA Blackwell 上处理的请求数量提高高达 7 倍,如最近的 SemiAnalysis InferenceX 基准测试所示。
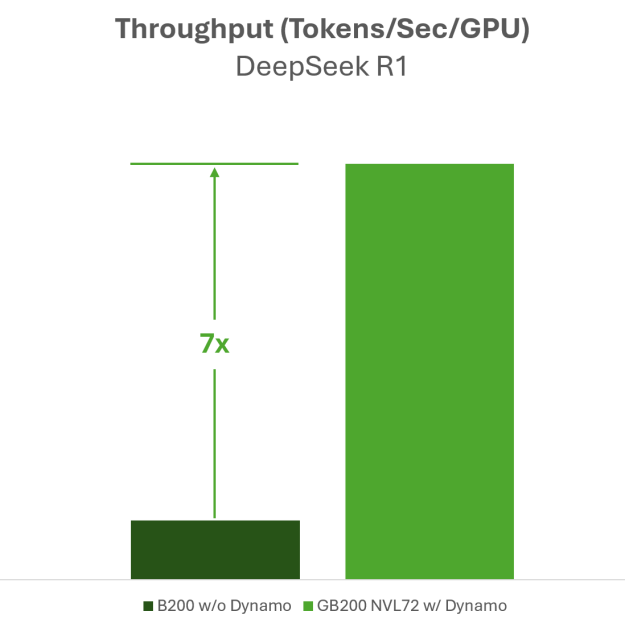
SemiAnalysis InferenceX,2026 年 3 月 3 日更新。DeepSeek R1-0528、FP4、1k/ 1k、交互性:< 50 tok/sec/user 的结果。
本博客详细介绍了早期采用者如何将 Dynamo 集成到现实世界的推理工作流中、实现的系统级性能提升,以及为框架添加的新功能和优化。
早期采用者和实际影响
在去年的 GTC 大会上,NVIDIA 推出了 NVIDIA Dynamo,这是一个专为多节点 AI 部署而构建的低延迟、高吞吐量、分布式推理框架。自那时起,NVIDIA 一直与开源生态系统合作,强化 Dynamo 的生产级性能和大规模工作负载。在此期间,Dynamo 取得了重要的里程碑:
- 已在生产工作流中成功部署: AstraZeneca、Baseten、ByteDance、CoreWeave、Crusoe、DigitalOcean、Gcore、GMI Cloud、Nebius、Meituan、Pinterest、Prime Intellect、Rednote、SoftBank Corp.、腾讯云、Together AI、Vultr 等公司已在生产环境中部署 Dynamo,以扩展多节点推理、优化吞吐量并降低延迟。观看 Dynamo Day 录像,直接聆听部署 Dynamo 的组织的讲话。
- 集成到托管 Kubernetes 环境:阿里云, Amazon Web Services (AWS), Google Cloud, Microsoft Azure, 和 Oracle Cloud Infrastructure (OCI) 已构建集成,展示如何将 Dynamo 无缝部署到其托管 Kubernetes 环境中,通过扩展推理来满足日益增长的 AI 需求。
- 为主要开源框架所采用:模块化 Dynamo 组件如 NIXL 已被推理引擎广泛采用,包括 llm-d、NVIDIA TensorRT LLM、SGLang 和 vLLM,以加速 GPU 之间的 KV 缓存传输。 LMCache 已将其 KV 缓存直接集成到 Dynamo 的存储解决方案中,SGLang 已将其 HiCache 解决方案集成到 Dynamo 的路由器中,LangChain 已构建集成,为 Dynamo 的路由器注入代理式提示,验证其可组合架构。
- 来自整个 AI 生态系统的启发性贡献:整个 AI 社区的开发者为 Dynamo 做出了贡献,并拓宽了 Dynamo 的功能。Mooncake 和阿里巴巴扩展了支持 SGLang 的 Dynamo AIConfigurator;Microsoft 对 Dynamo on Azure Kubernetes Service (AKS) 进行了测试和强化,并提供了修复、部署指南、公开演示和规划器/ AIConfigurator 增强功能;Prime Intellect 共同设计并集成了 LoRA 适配器支持;和 Baseten 在生产等环境中验证了早期的 Dynamo 功能,然后在上游修复问题并强化补丁。
- 支持与存储解决方案集成: Cloudian, DDN, Dell, Everpure (以前称为 Pure Storage), HPE, IBM, NetApp, VAST, 和 WEKA 已将 Dynamo 集成到其 AI 解决方案中。这使得推理工作负载的扩展超出了 GPU 显存的限制,从而支持非常大的上下文长度和存储。
Dynamo 1.0 以这些里程碑为基础,同时标志着框架的成熟度和生产就绪性。请继续阅读,了解有关更新的更多亮点。
借助 Dynamo 和 NVIDIA NeMo Agent Toolkit,将代理式推理速度提高 4 倍
如今的推理运行时对每个请求和 KV 缓存块都有相同的处理方式 – 在许多回合中重复使用的系统提示具有与一次性思维链相同的驱逐优先级。然而,多轮代理会重复使用前缀并遵循可预测的模式。需要重新计算被逐出的多圈 KV 块,这会导致计算浪费和推理成本增加。Dynamo 通过新的代理式推理优化弥补了这一差距:
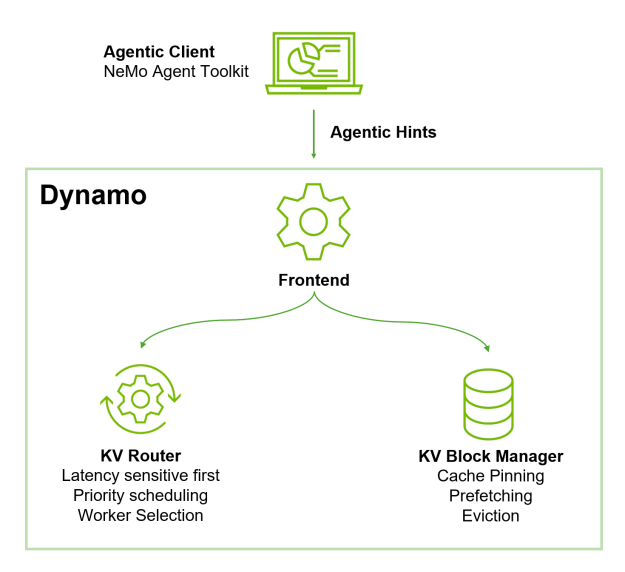
- Dynamo 前端 API: 接受智能体提示 (每个请求的元数据,如延迟敏感度、预期输出长度和缓存控制) ,并将其传递给路由器和 KV 缓存管理器。
- Dynamo KV 感知路由器:使用优先级和延迟代理式提示来控制队列排序,以便在后台工作之前进行面向用户的轮询。它可以采用预期的输出序列长度 (OSL) ,以提高负载平衡准确性。
- Dynamo KV 缓存管理器:支持实验性缓存固定。固定节点在指定的持续时间内不会被逐出,并会移动到主机内存,而不会被删除。
该社区基于这些优化来创建自定义路由,并将智能体提示集成到热门框架中,例如 LangChain 的 ChatNVIDIADynamo 和 NVIDIA NeMo Agent Toolkit。
在 NVIDIA Hopper 上运行 Llama 3.1 模型时,运行 Dynamo 和 NeMo Agent Toolkit 可将 TTFT 和吞吐量分别降低 4 倍和 1.5 倍。
推进多模态推理优化
Dynamo 1.0 引入了三项新功能,旨在加速图像密集型工作负载 (其中图像编码可能会成为瓶颈) 中的多模态推理:
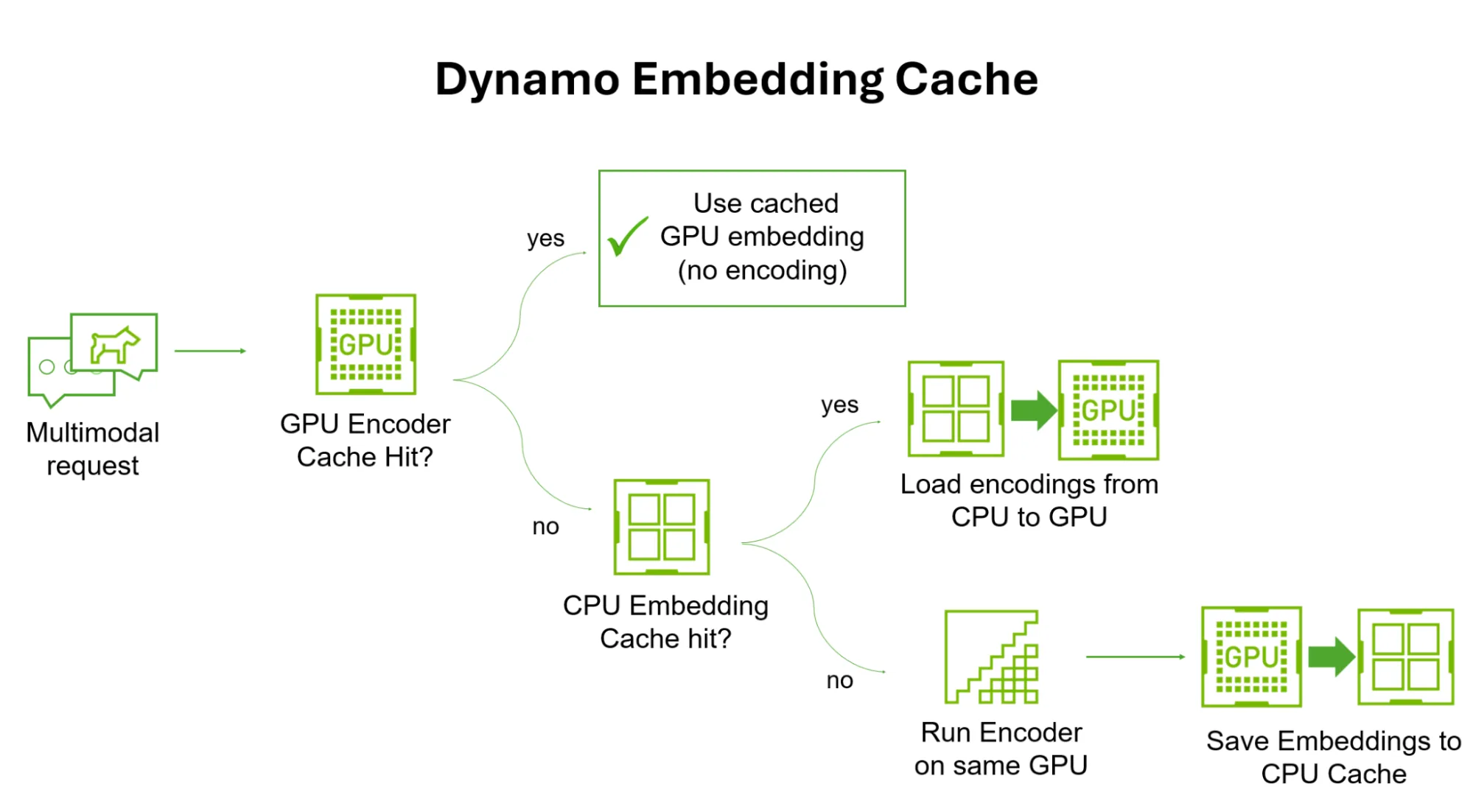
- 分解编码/ 预填充/ 解码 (E/ P/ D): Dynamo 不在同一 GPU 上运行 E/ P/ D,而是通过独立扩展将它们分成不同的阶段。在专用工作者上运行编码阶段可实现独立扩展,从而提高批处理、内存效率和整体吞吐量。
- 多模态嵌入缓存:由 CPU 支持的最近使用最少 (LRU) 缓存可将计算出的图像嵌入存储在 GPU 之外,因此重复图像可完全跳过编码。这适用于解和聚合设置。
- 多模态 KV 路由:多模态 KV 路由扩展了 Dynamo 的 KV 感知路由器,以考虑图像内容。专用多模态路由器可下载图像,然后选择具有最高缓存重叠 (包括包含图像的块上的重叠) 的后端工作进程。
在 NVIDIA GB200 上运行 Qwen3-VL-30B-A3B-Instruct-FP8 多模态模型时,Dynamo 的嵌入缓存可将生成首个 token (TTFT) 的时间缩短高达 30%,并将处理图像请求的吞吐量提高高达 25%。
添加对视频生成的原生支持
新的视频生成模型为电影级画质和动态逼真度树立了新标杆。但高效服务并非易事:其推理工作负载需要大量计算和内存,尤其是在高分辨率下。
Dynamo 1.0 增加了对视频生成模型的原生支持,并集成了 FastVideo、SGLang Diffusion、TensorRT LLM Diffusion 和 vLLM-Omni 等领先的开源推理框架。这将 Dynamo 的模块化堆栈 (包括低用度前端、流式传输功能和高效调度引擎) 引入到现代视频工作负载中。
此集成表明,可以在 Dynamo 上高效地生成先进的视频。如需逐步了解如何使用 Dynamo 部署视频生成模型,请查看此方法指南。
借助 Dynamo ModelExpress 将推理启动速度提高 7 倍
现代推理集群不断根据流量上下旋转新的副本。每个新进程都必须重复相同的繁重启动工作流:
- 下载模型检查点
- 从远程或共享存储加载权重
- 应用模型优化
- 编译内核
- 构建 NVIDIA CUDA 计算图
为了解决这一挑战,Dynamo 可确保员工启动过程中成本高昂的部分只需完成一次,并通过两种新的 ModelExpress 功能重复使用多次:
检查点恢复: Dynamo 不是将每个副本视为新启动,而是一次运行完整的初始化序列,将“ready* to* serve”状态捕获到持久存储,然后通过从该检查点恢复而不是从头开始重建所有内容来使新副本联机。
模型权重流:ModelExpress 不是让每个新工作节点单独下载模型权重,将其写入本地或共享存储,然后将其加载到 GPU 显存中,而是使用 NVIDIA 推理 Xfer 库 (NIXL) 和 NVIDIA NVLink 在初始工作节点上加载一次模型,并通过高带宽互连将权重流式传输给其他工作节点,从而消除对存储的依赖
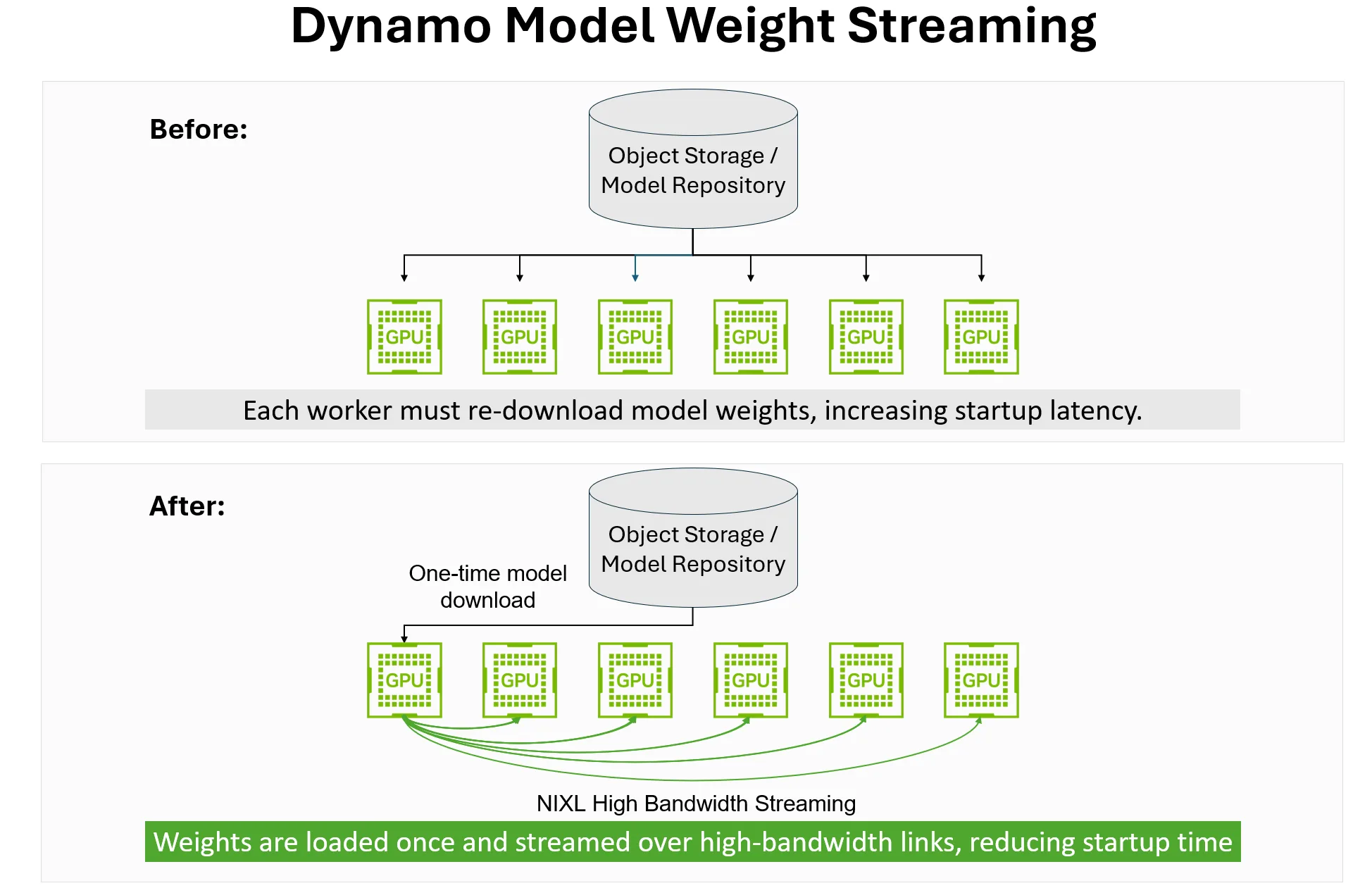
对于大型模型,尤其是在大规模扩展的车队中,模型权重流可以将基于 NVIDIA H200 的 DeepSeek v3 等大型 MoE 模型的模型加载时间缩短高达 7 倍。
在 NVIDIA GB300 NVL72 上扩展 Kubernetes
NVIDIA Grove,是 Dynamo 中的一个开源 API,可简化在 Kubernetes 上部署分层轮询、拓扑感知的 AI 工作负载。在 Dynamo 1.0 中,Grove 为机架级系统 (例如 NVIDIA GB300 NVL72) 添加了 NVIDIA NVLink 网络 设置自动化。这使用户能够在基础设施的每一层 (从云区域和可用区域到数据中心、网络模块、机架、主机,甚至是非统一内存访问 (NUMA) 节点) 定义放置策略。
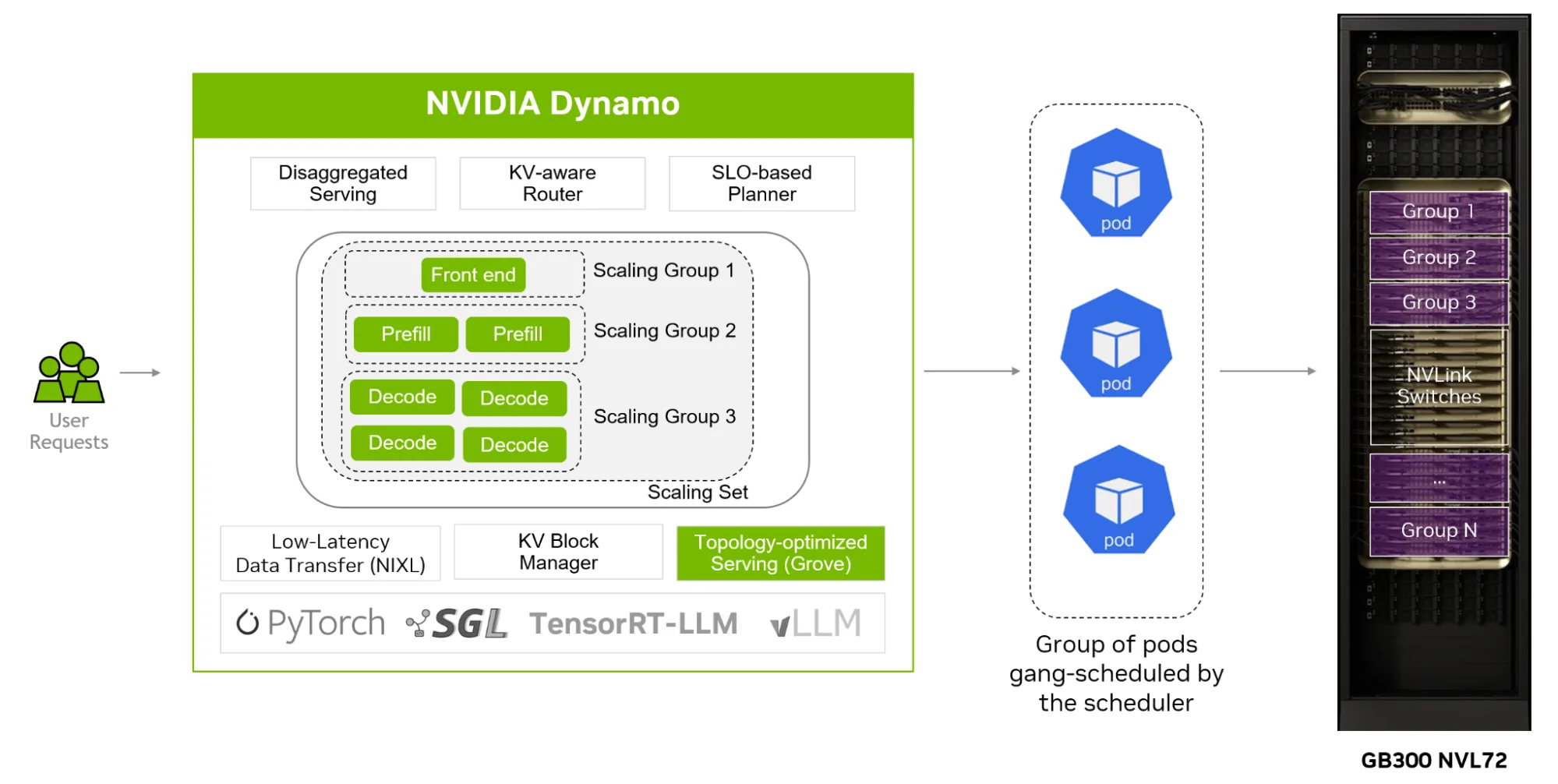
过去,使用 NVIDIA GB300 NVL72 NVLink 结构时,用户需要手动定义和管理计算域。此版本引入了统一的拓扑 API,使开发者能够在同一 NVIDIA NVL72 机架上无缝托管预填充和解码,以优化 KV 缓存传输,将推理堆栈限制在单个数据中心以满足延迟需求,并将前端服务放置在附近的 CPU+ 节点上,以实现高效的请求处理。Grove 与 KAI 调度程序等先进的 AI 调度程序集成,以确保这些限制得到执行。
与 Kubernetes 推理网关集成
上一个 Dynamo 版本引入了一个插件,允许用户结合 Kubernetes 原生推理网关扩展路由和 Dynamo 的 KV 感知路由器。
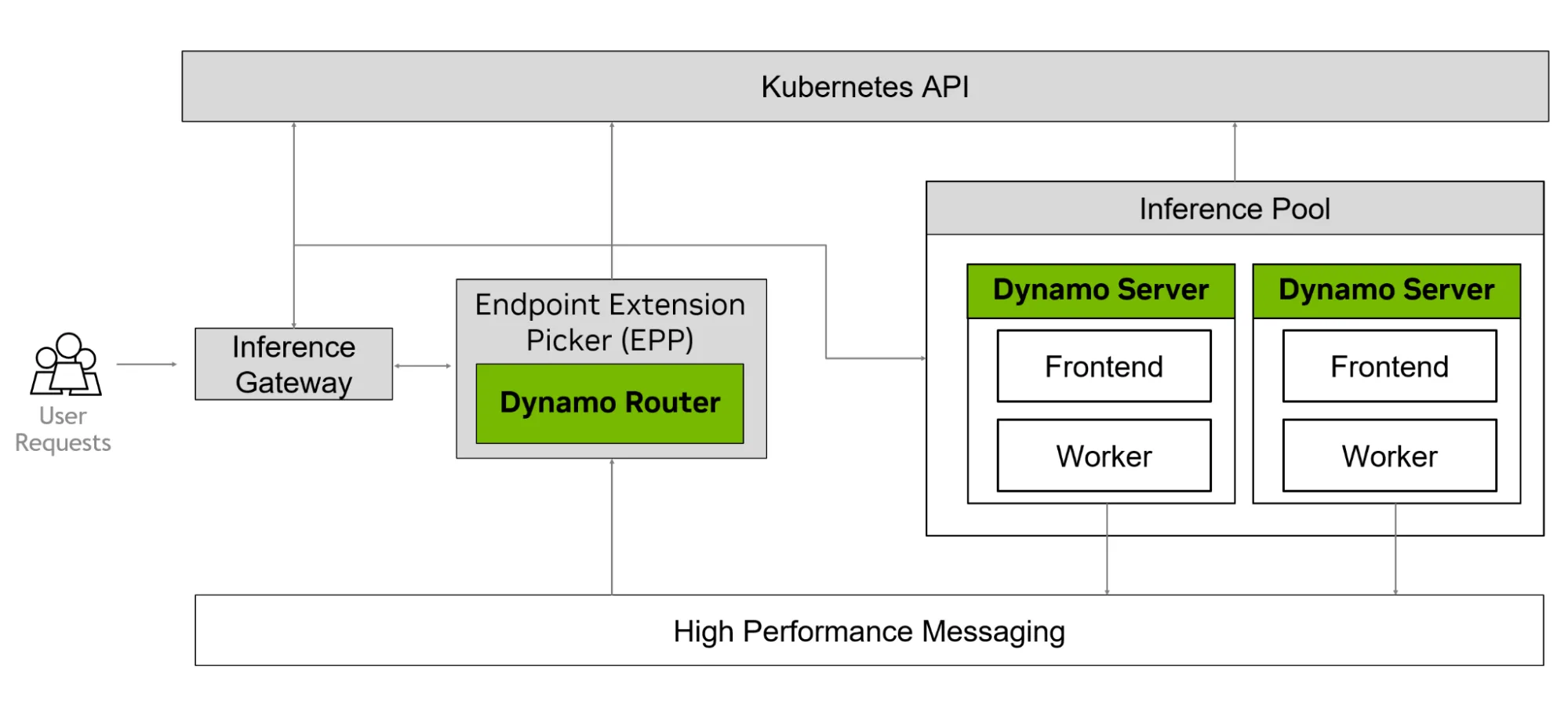
在典型的 Dynamo 设置中,路由由 Dynamo 的 KV 感知路由器 处理。路由器会评估每个工作者的队列深度和相关 KV 缓存信息,然后使用这些因素的加权组合做出概率决策。
Dynamo 的 KV 感知路由器可以在推理网关内运行,以便在基于 Kubernetes 的环境中集成路由插件、过滤器和其他网关功能。
部署零配置的快速延迟感知型推理
部署大型模型需要深厚的专业知识,通过复杂的扩展和配置步骤来平衡延迟、吞吐量和成本目标。Dynamo 的全新 Dynamo Graph Deployment Request (DGDR) 可提供从服务水平目标 (SLO) 到优化推理部署的简单一步式路径,从而消除上述障碍。
DGDR 将规划器和 AIConfigurator 的智能整合到统一的 Kubernetes™ 本地部署流中。开发者现在可以通过直观的 Web UI 在 YAML 中指定模型、目标硬件和流量目标,而 Dynamo 可以处理其余工作,而无需在多个工具、脚本和猜测之间来回切换。
在后台,AIC 配置器运行基于仿真的快速建议以进行快速迭代,而规划器则更深入地分析集群,以实现精确的生产级优化。这两种路径都提供了可自动部署的动态图形部署 (DGD) ,可满足用户所需的成本、性能和可扩展性平衡,而无需手动配置部署配置。
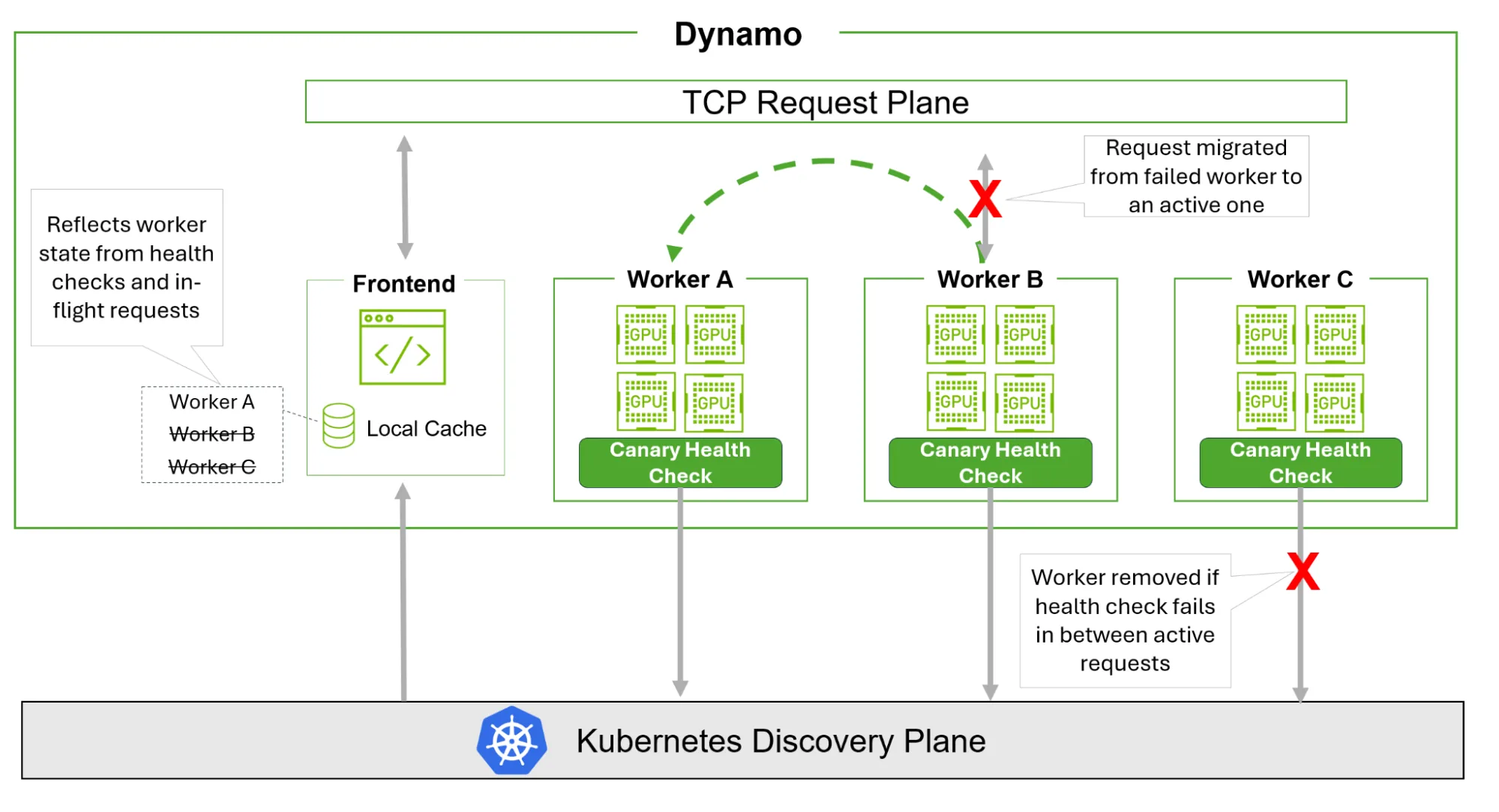
通过故障检测和请求迁移提高弹性
Dynamo 的一个关键设计原则是在默认情况下具有弹性,因此即使单个工作进程发生故障或挂起,应用也能保持运行。更新后的 Dynamo 容错包括两个支柱:
早期故障检测: Dynamo 增加了一个独立于框架的“金丝雀健康检查”,按照可配置的计划对工人进行检测。如果这些检查未收到有效的响应,则系统会标记工作节点不健康,并将其从路由中移除。此外,Dynamo 前端还使用网络级信号执行主动检测。如果为工作进程建立新流失败,或者现有流在请求中意外结束,系统会立即将该工作进程从活动工作进程集中删除 (大约 5 秒钟) ,因此不会向其发送新请求。
请求取消和迁移: 请求取消支持开箱即用,允许在不再需要继续工作时终止飞行中的工作。当 worker 变得不可用时,Dynamo 可以将受影响的请求迁移到另一个 worker,并恢复处理,保留请求本身,而不是强迫客户端从头开始重新提交。这可确保故障不会自动转化为用户可见的错误。
通过将 Dynamo 的新分层运行状况检测与取消和迁移相结合,Dynamo 旨在保持 LLM 应用的响应速度,即使在单个工作者出现故障时也是如此。
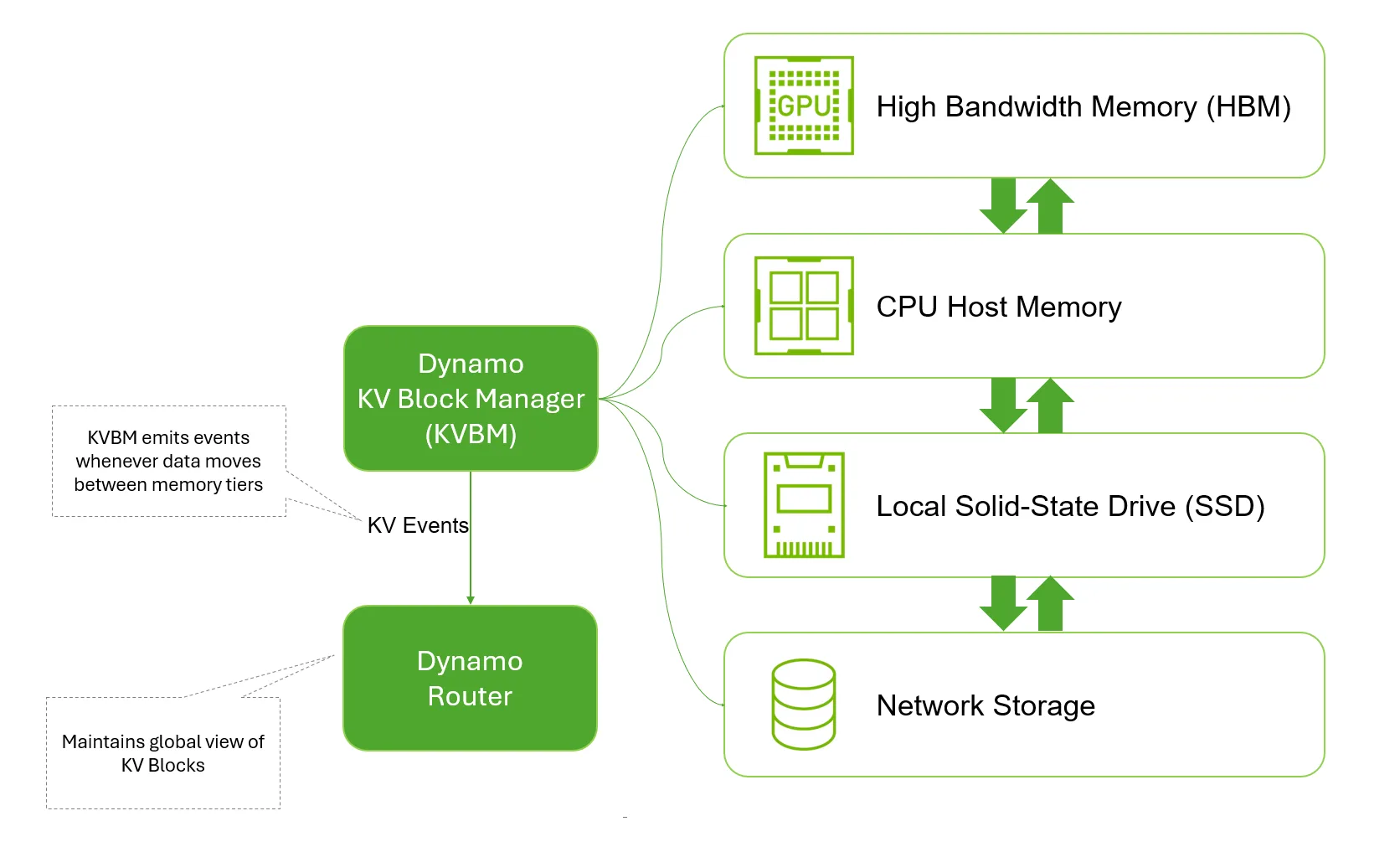
将 KV 缓存推进到存储
在 Dynamo 1.0 中,KV Block Manager (KVBM) 引入了多项功能,可增强灵活性、可见性和部署选项:
- 对象存储支持: KVBM 现在可与主要存储供应商和云提供商使用的 Amazon Simple Storage Service (S3) 和 Azure 式 Blob API 配合使用。这允许模型运算符将 KVBM 与现有文件系统、S3 或其他云对象存储集成,而无需为每个后端构建单独的 KV 卸载管道。
- 全局 KV 事件发射:每当 KV 块在存储层 ( GPU 内存、CPU 内存、本地 SSD 和远程存储) 之间移动或被逐出时,KVBM 就会发出事件。KV 路由器的索引器会使用这些事件,以在整个集群范围内保持一致的 KV 块位置视图,从而实现更智能的路由,并改进跨多个模型副本和推理引擎的缓存重用。
- Pip-installable 模块:KVBM 现在可以直接安装到 vLLM 或 TensorRT LLM 等推理引擎中,而无需完整的 Dynamo 堆栈。使用不同推理框架的团队可以共享通用的 KV 卸载工具,而无需重新实现拆迁策略和存储集成。
展望未来
展望未来,Dynamo 产品路线图将侧重于扩展多模态功能,以支持更丰富、更情境感知的交互,推进基于扩散的模型以解锁实时更高质量的视频生成功能,并扩展代理式工作负载和增强学习。Dynamo 是与社区一起以开放的方式构建的。要参与其中,请在 NVIDIA GitHub 资源库中探索代码和问题,进入每两周一次的 Dynamo 办公时间,并在现有的技术博客深入了解。
致谢
Akshatha Kamath、Anish Maddipoti、Anna Tchernych、Ben Hamm、Biswa Ranjan Panda、Dhruv Nandakumar、Ekin Karabulut、Ganesh Kudleppanavar、Hannah Simmons、Hannah Zhang、Harry Kim、Hongkuan Zhou、Hyunjae Woo、Ishan Dhanani、Itay Neeman、Jacky Hui、Jakub Kosek、John Kim、Kavin Krishnan、Kyle Kranen、Maksim Khadkevich、Michael Demoret、Moein Khazraee、Neal Vaidya、Neelay Shah、Qi Wang、Ryan McCormick、S




