
自2023年首次发布以来,NVIDIA Grace CPU 在数据中心领域实现了快速普及,为多种工作负载的性能与能效树立了新的标杆。Grace 将 Arm Neoverse 核心与 NVIDIA 可扩展一致性架构(SCF)、高带宽 LPDDR5X 内存以及 NVIDIA NVLink-C2C 互联技术相集成,实现了突破性的带宽性能、低延迟扩展能力和卓越的能效表现。
在本博文中,我们将探讨 Grace 非统一内存访问(NUMA)整体架构的优势,深入分析各核心的显存带宽、可扩展性与运行效率,并将其设计思路与传统的基于 x86 架构的 CPU 进行对比。
单一 NUMA 设计
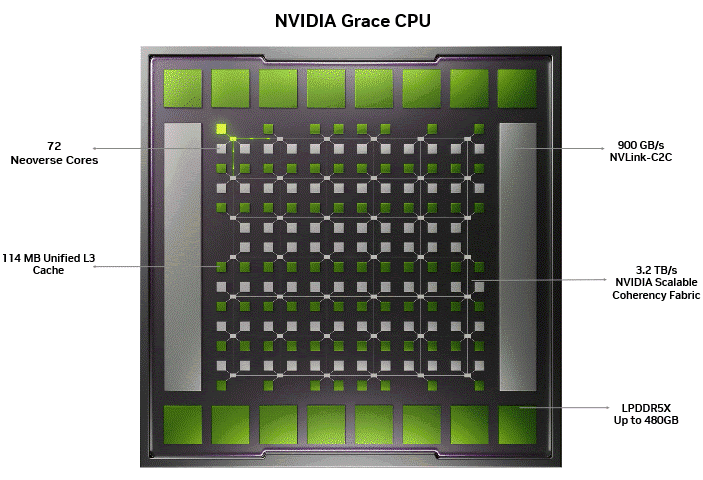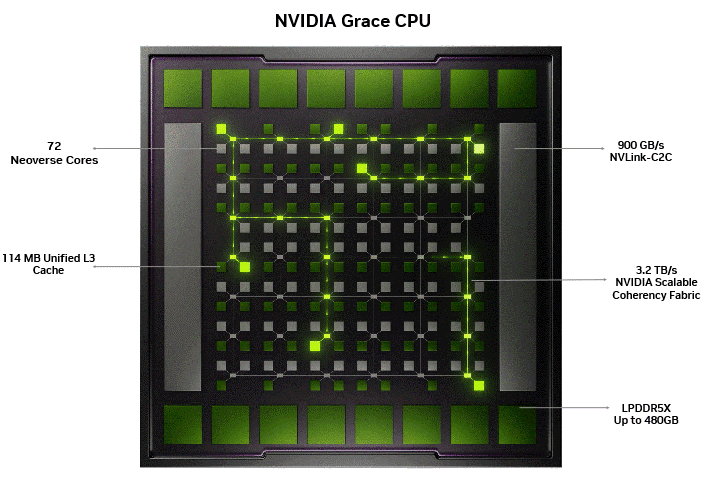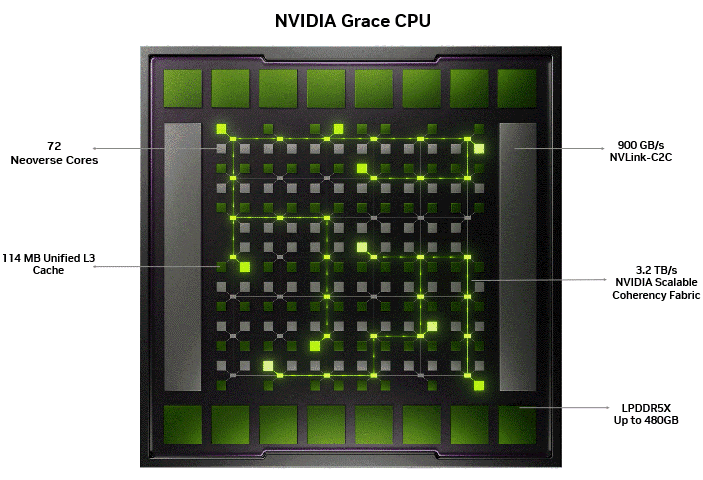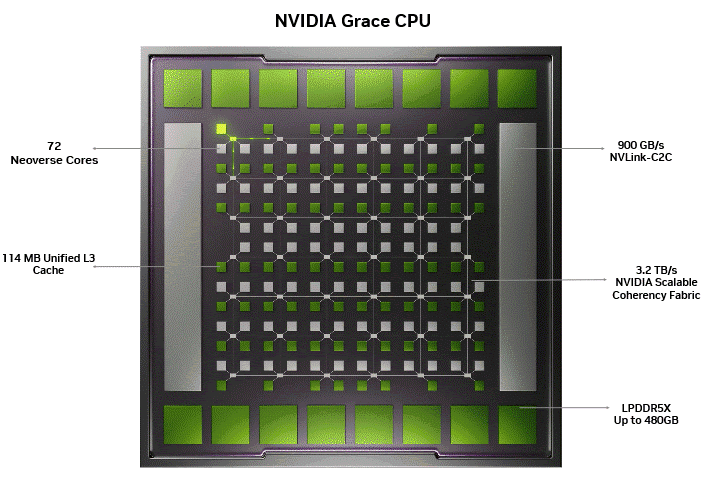
Grace CPU 采用一致性网格互连架构,将全部 72 个 Arm Neoverse 核心整合为一个高性能计算域。所有核心均可平等访问内存,摆脱了 NUMA 架构带来的限制,从而简化了软件开发与应用扩展,并保障线程间及不同工作负载下的性能一致性。该统一的网格结构使各核心的内存访问延迟趋于均衡,有效避免了跨 NUMA 数据传输及其引发的性能损耗。Grace 的统一缓存与内存子系统进一步优化了核心间的通信延迟,提升了缓存命中率,同时无需依赖多芯片设计中的芯片间跳转,实现了更高效的内部数据交互。
在云环境中,小型虚拟机(VM)在最终用户中更为普遍。Grace 的统一架构使每个虚拟机都能访问完整的内存子系统,相较于将内存分布在多个裸片上的传统芯片设计,这一特性具有明显优势。传统的多芯片架构通常需要精细的核心绑定以维持性能一致性,而在工作负载分配过程中,若利用率不足,激活多个小芯片可能导致额外的功耗。
下图1展示了作为主干的 NVIDIA SCF 架构,该架构在单个单片芯片上集成了 72 个 Arm Neoverse 核心、114 MB 统一 L3 缓存、480 GB LPDDR5X 内存以及 900 GB/s 的 NVLink-C2C 互连带宽,构成一个完整的相干系统。图中示意了数据在网格结构中的流动情况,避免了传统小芯片设计中常见的通信瓶颈。
通过核心数量实现最佳显存带宽扩展
NVIDIA Grace CPU 采用覆盖整个系统的大型统一网格互连架构,在核心数量与内存带宽之间实现了良好平衡。许多数据分析、提取、转换、加载(ETL)以及高性能计算(HPC)工作负载需要在核心、缓存和内存之间频繁传输大量数据,因此对内存带宽提出了较高要求,需与核心总数相匹配。
如图2所示,STREAM基准测试结果充分体现了Grace在内存带宽方面所具备的显著优势。该基准测试经过专门设计,旨在使CPU缓存超负荷运行,从而迫使系统直接从内存执行大规模、连续的数据传输操作。
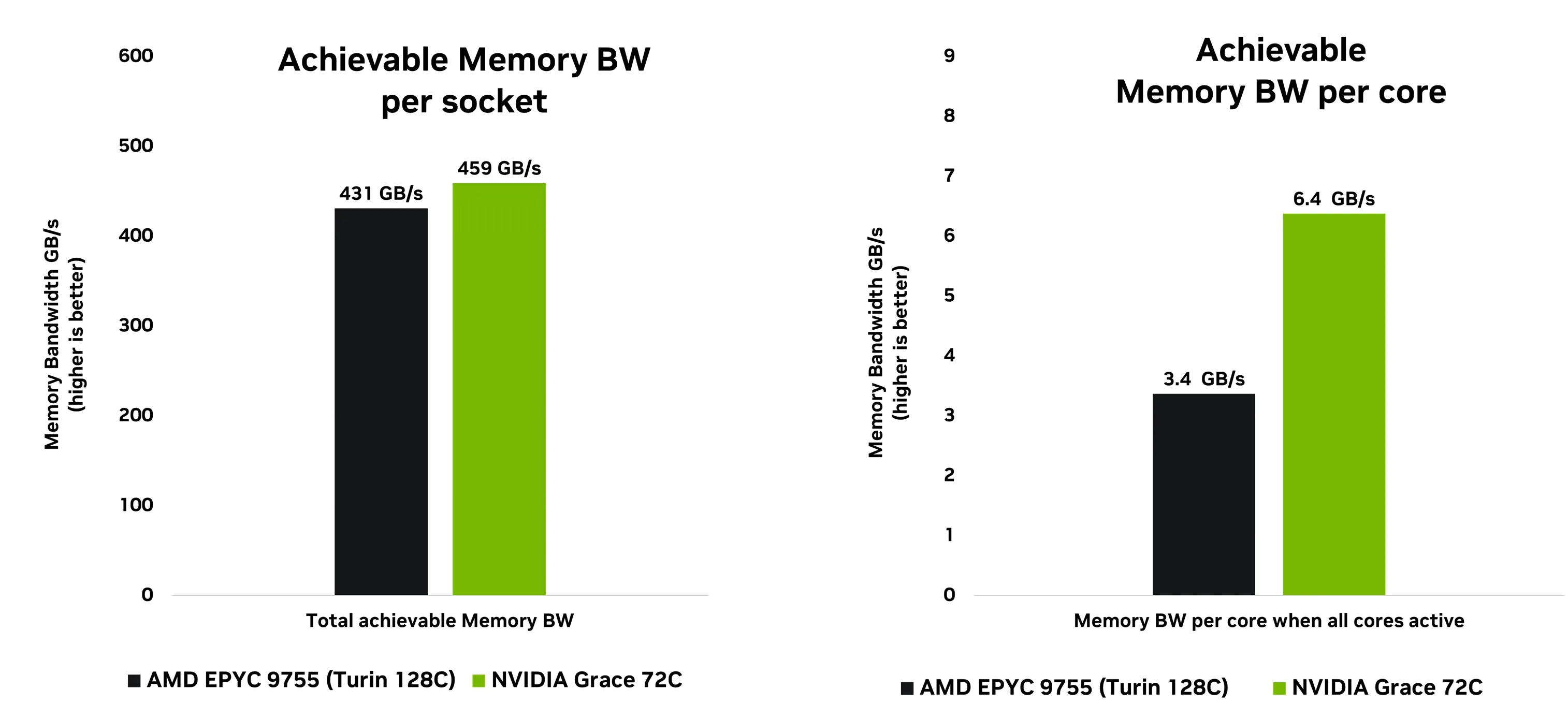
Grace 的总显存带宽超过 AMD Turin,但其真正的优势在于带宽效率。当系统在高负载下所有核心均处于活动状态时,Grace 能为每个核心提供更高的可用带宽,这一特性对于新一代数据驱动计算至关重要。相比同类 SoC,Grace 可提供高达 1.8 倍的每核心显存带宽,使每个核心都能更高效地同时处理来自网格结构和内存子系统的海量数据流。
Grace 适用于大数据工作负载
Grace 架构凭借统一的网络设计以及更高的每核显存带宽,在现实世界的数据分析工作负载中展现出显著优势。以图算法平台基准套件(GAPBS)中的 PageRank 算法为例,该算法是评估图分析与大数据系统性能的关键测试之一。PageRank 通过迭代方式计算大规模图中各节点的重要性得分,可模拟网站排名、社交网络分析等实际应用场景。这一基准测试不仅对核心间的通信能力提出较高要求,同时也考验系统高效处理大规模、随机且分散的内存访问模式的能力。
图 3 展示了 PageRank 算法在 Grace 和 AMD Epyc Turin 处理器上,从核心 0 到核心 15 顺序运行时的性能表现。在 Grace CPU上,关键的 PageRank 指标——每秒遍历边的次数(TEPS)——随着核心数量的增加持续提升。这得益于统一的 SCF 架构,它实现了核心、缓存与内存子系统之间数据的无缝移动。
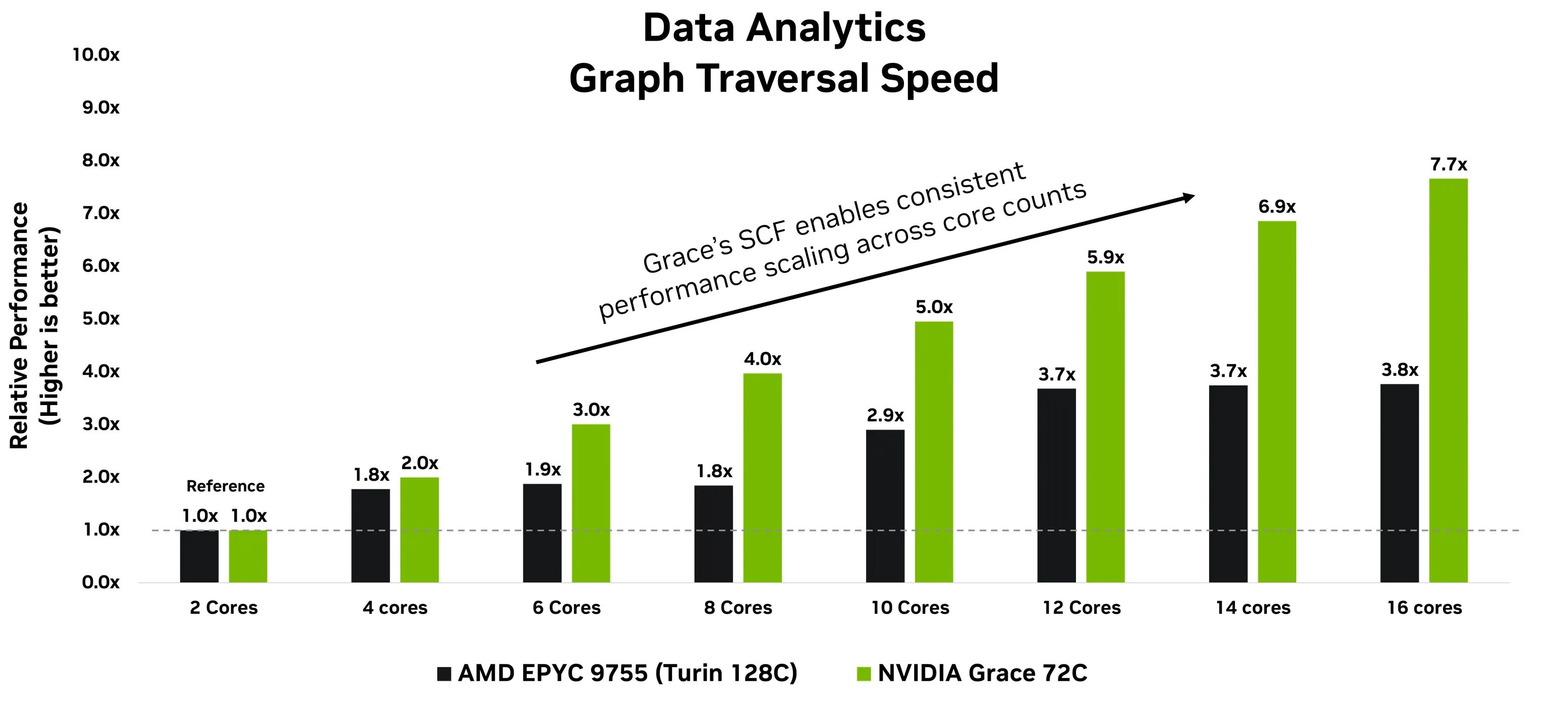
相比之下,由于网格碎片化和裸片间延迟,基于小芯片的 x86 架构在扩展性方面表现出不均衡且受限的特点。尽管细粒度的核心绑定在小芯片架构上可能带来一定性能提升,但对于典型的数据分析类工作负载,这种做法往往适得其反,并在实际部署中增加额外的工程复杂性。在采用小型虚拟机的云计算环境中,这一问题尤为突出,因为此类场景下可能无法灵活分配核心资源。
Grace 在数据分析和高性能计算(HPC)工作负载方面的性能优于 x86 架构的 CPU
Grace 是首款配备高性能 LPDDR5X 显存和全一致性 CPU-GPU 互连(NVLink-C2C)的服务器 CPU,数据传输速率高达 900 GB/s,可为新一代 AI 工厂和大数据工作负载提供强大支持。
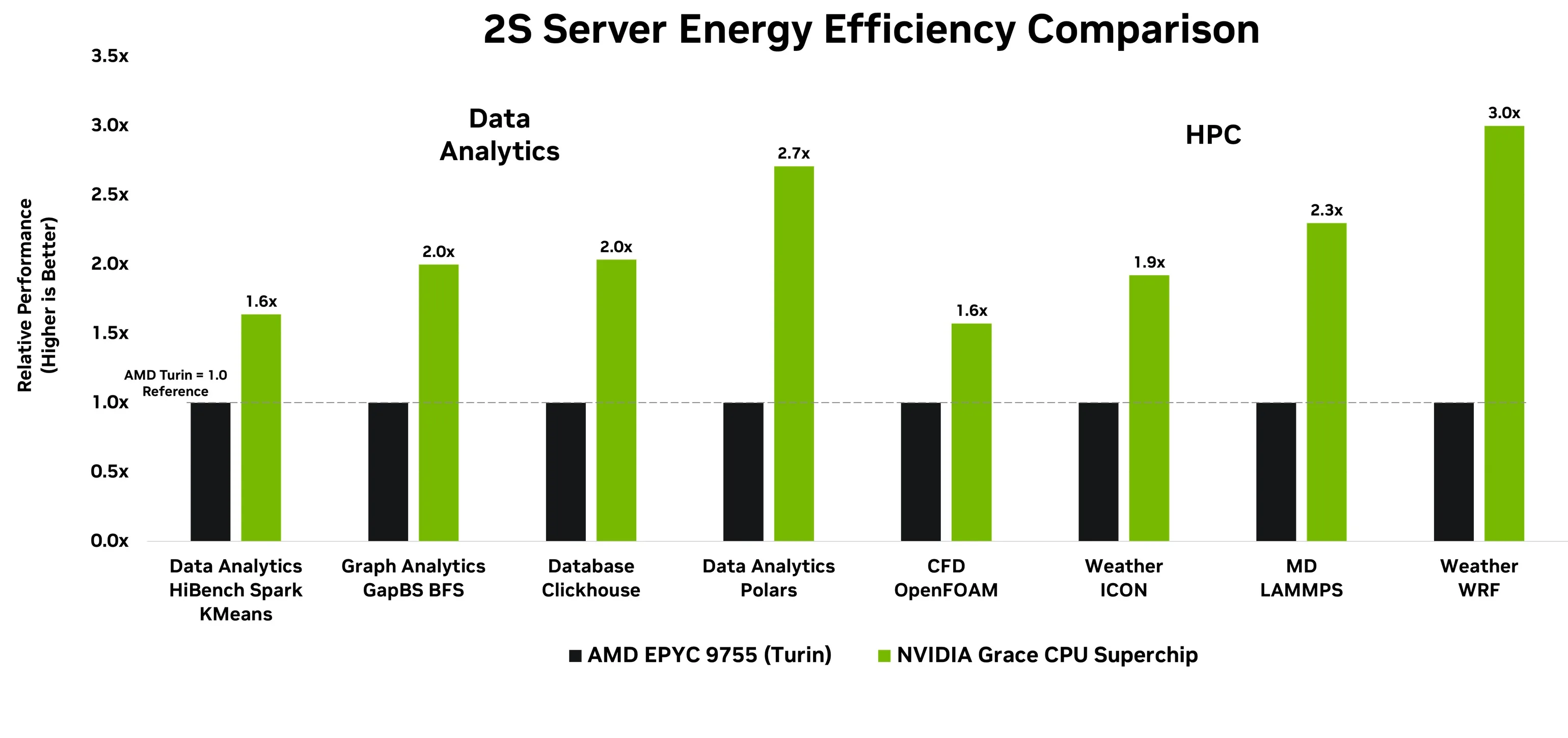
图 4 展示了 Grace 与 AMD Epyc Turin 在双插槽系统中每瓦性能的对比。NVIDIA Grace 在关键数据分析任务(包括 OLAP、图计算和 ETL)以及 CFD、天气模拟和分子动力学等 HPC 工作负载中,可将每瓦性能提升高达 3 倍,显著提高数据中心的吞吐量并降低总体拥有成本。
Grace 以低功耗提供高性能
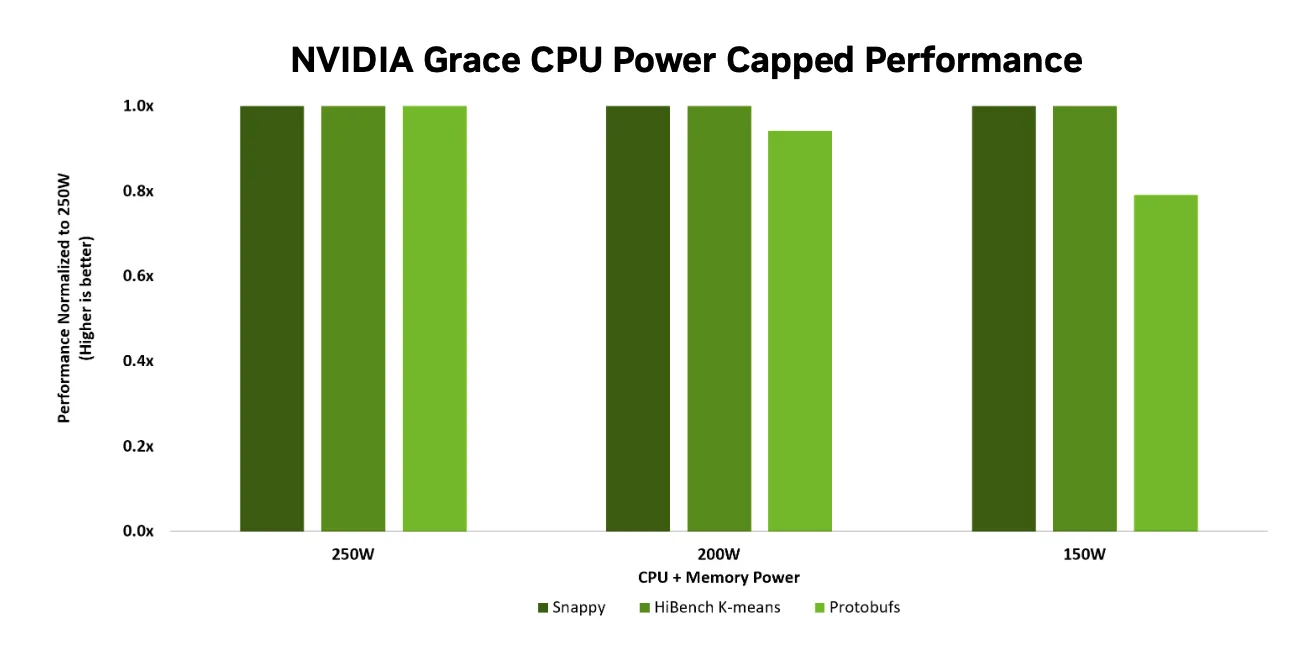
Grace CPU 的节能架构具备一项关键优势:即使在较低的功率限制下运行,仍能保持出色的性能。这种设计通过限制 CPU 模块的功耗,有效降低了机架的整体能耗与冷却需求。随着数据中心不断追求更高的计算密度和更严格的能效控制,能效表现愈发重要。图 5 展示了 Grace 在不同功率上限下的相对性能表现,以相同工作负载下 250W 的基准性能作为参考。结果显示,Grace 在 200W 功耗下仍可维持超过 90% 的性能,在 150W 时仍可达到约 80% 的性能水平,从而在显著节约能源的同时,最大程度地减少了性能损失。
该功能使操作员能够在不牺牲有效计算性能的前提下调节效率,从而在功率受限的环境中提升机架级密度并降低冷却成本。
Grace 通过将节能高效的 LPDDR5X 显存与高性能计算能力相结合,并将节能高效的 Arm Neoverse 核心集成于单个 SoC 芯片中,有效减少了片外通信需求。这些技术协同作用,降低了数据传输开销,显著提升了每瓦性能。由此实现的 CPU 不仅运行速度更快,而且功耗更低。即便在功率受限的环境下,仍能保持良好的性能弹性,非常适合应用于超大规模部署、高性能边缘计算、存储系统、CDN、高性能计算(HPC)以及其他对功耗敏感的现代场景。
为新一代数据工厂提供动力支持
Grace 为 NVIDIA 的 CPU 路线图奠定了基础,在单个 NUMA 架构中实现了卓越的性能与能效,具备一致的核心扩展能力、优化的网格结构以及出色的内存带宽,适用于多样化的服务器部署场景。展望未来,我们对即将推出的新一代服务器 CPU Vera 充满期待。Vera 采用 88 个支持多线程的自定义 Arm 核心,配备更大的网格结构、高达 1.2 TB/s 的内存带宽,以及 1.8 TB/s 的 NVLink-C2C 互联带宽,致力于推动新一代数据密集型计算的发展。
深入了解 NVIDIA Grace CPU 性能与能效表现,优化策略,和 软件生态系统。
NVIDIA Grace 超级芯片(480GB LPDDR5X),AMD EPYC 9755(768GB DDR5)
操作系统:Ubuntu 24.04 LTS 编译器:默认使用 GCC 12.3,特殊情况下另行说明 能效功耗测量范围涵盖 CPU 及显存
**数据分析**:HiBench K-means Spark(HiBench 7.1.1、Hadoop 3.3.3、Spark 3.3.0)
**图形分析**:采用 GAP 基准测试套件中的 BFS 与 PR 算法(arXiv:1508.03619 [cs.DC], 2015),数据集为 Kronecker
**数据库性能测试**:基于 ClickHouse,使用 Phoronix 测试套件(gcc11)、Polars-CPU,PDS SF100 场景(热缓存拼接模式)
**高性能计算(HPC)**:
– 流体动力学:OpenFOAM v2406
– 天气模拟:ICON v2024.8_RC(AMD 平台)、WRF v4.6.0(AMD 平台,使用 ICC 2024.01 编译器)
– 分子动力学:LAMMPS,通过 Phoronix Test Suite 测试(gcc11)
**压缩性能**:Snappy(提交版本 af720f9a3b2c831f173b6074961737516f2d3a46),运行 N 个并行实例
**微服务性能**:Google Protobufs(提交版本 7cd0b6fbf1643943560d8a9fe553fd206190b27f),运行 N 个并行实例
**综合数据分析**:HiBench K-means Spark(HiBench 7.1.1、Hadoop 3.3.3、Spark 3.3.0)与 STREAM Triad 测试
**测试平台配置**:
– NVIDIA Grace CPU C1:运行 Ubuntu 22.04,编译器为 GCC 12.3
– AMD EPYC 9755(Turin 架构)
高性能计算调优参考指南




