
人工智能由 token 驱动。每个提示、推理步骤和智能体交互都会生成 tokens。在过去一年中,token 的消耗量增长了数倍,现在每年已超过 10 万亿 tokens。虽然 tokens 的大部分由人类与 AI 交互生成,但在新时代,大多数 tokens 将由 AI 与 AI 交互生成。
现代代理式系统可规划任务、调用工具、执行代码、检索数据,并跨多个连续多步骤工作流进行协调 AI 智能体。这些交互会生成大量推理 tokens,扩展 KV 缓存,并且需要基于 CPU 的沙盒环境来测试和验证加速计算系统生成的结果。这对低延迟、高吞吐量提出了跨 GPU、CPU、纵向扩展域、横向扩展网络和存储的要求。
为这些现代代理式系统提供有用的智能,需要一组专门构建的机架级系统,这些系统作为一个连贯的 AI 超级计算机一起运行。本文将介绍 NVIDIA Vera Rubin POD,由五个专用的机架级系统组成,基于第三代 NVIDIA MGX 适用于代理式 AI 时代的机架架构。
隆重推出 NVIDIA Vera Rubin POD
NVIDIA Vera Rubin 通过对涵盖计算、网络和存储的七款芯片进行极致协同设计而构建,引入了极其复杂的 POD 级 AI 平台。该平台拥有 40 个机架、1.2 万亿个晶体管、近 20000 个 NVIDIA 裸片、1152 个 NVIDIA Rubin GPU、60 exaflops 和 10 PB/s 的纵向扩展总带宽。
Vera Rubin POD 引入了五个全新的专用机架级扩展系统,适用于需要高吞吐量、超低延迟推理、密集型 CPU 沙盒和大规模上下文内存存储的代理式 AI 工作负载。这些机架共同构成了一个紧密的系统,将为全球最节能、最具成本效益的数据中心提供动力支持。

POD 中的每个芯片都通过第三代 NVIDIA MGX 机架进行扩展,由 80 多家合作伙伴组成的生态系统提供支持,他们拥有在将大规模 AI 系统推向市场方面经验丰富的全球供应链。这可实现快速部署和无缝过渡,每个 NVIDIA MGX 机架共享相同的功率、冷却和机械包围。
有两种类型的 MGX 机架采用铜质脊线,专为实现性能、弹性和能效而设计。MGX NVL 机架通过 NVIDIA NVLink 连接,而新的 NVIDIA MGX ETL 机架则通过以下两种类型的脊线之一连接: NVIDIA Spectrum-X 以太网 或 NVIDIA Groq 3 LPU 直接芯片到芯片链路。
NVIDIA Vera Rubin NVL72:四大扩展定律平台
NVIDIA Vera Rubin NVL72 是最新的 AI 工厂 的核心机架级计算引擎。它集成了 72 个 NVIDIA Rubin GPU 和 36 个 NVIDIA Vera CPU,通过大规模 NVLink 铜质主干相连,可作为一个巨大的 GPU。NVIDIA Vera Rubin NVL72 专为 AI 的四种扩展定律而设计:预训练、后训练、测试时扩展和代理式扩展。它可以针对复杂的多专家模型 (MoE) 路由和 AI 推理的繁重计算受限的上下文阶段进行优化。它提供高达 4 倍的训练性能和高达 10 倍的每瓦推理性能,并且 token 的成本是 NVIDIA Blackwell 的十分之一。
NVIDIA Groq 3 LPX:推理加速器机架
NVIDIA Groq 3 LPX 与 NVIDIA Vera Rubin 平台共同设计,可满足代理式 AI 的大规模上下文和低延迟需求,每个机架配备 256 个语言处理单元 (LPU) 。它与 Vera Rubin NVL72 搭配使用,无需在高速交互性和吞吐量之间权衡取舍。通过将仅使用高带宽 SRAM 的 LPU 与具有大 HBM 容量的 Rubin GPU 融合,该系统可在长上下文长度下实现低延迟和高吞吐量,从而在不牺牲系统吞吐量的情况下为万亿参数模型的用户交互性提供强效助力。相较于 Blackwell,Vera Rubin NVL72 plus LPX 可提供高达 35 倍的 tokens 和 10 倍的万亿参数模型创收机会。如需了解详情,请参阅 深入了解 NVIDIA Groq 3 LPX。
NVIDIA Vera CPU 机架:大规模代理式 AI 和强化学习
这个 NVIDIA Vera CPU 机架在密集的液冷机架中集成了多达 256 个 NVIDIA Vera CPU,可提供可扩展的高能效容量。单个机架可支持超过 22500 个并发 强化学习 (RL) 或智能体沙盒环境,更大限度地利用环境来测试、执行和验证 Vera Rubin NVL72 和 LPX 机架的结果。 Vera CPU 机架 为大规模代理式 AI 和强化学习奠定了基础,提供的结果效率是传统机架级 CPU 的两倍,速度快 50%。详细了解 Vera CPU 可为 AI 工厂提供高性能带宽和效率。
NVIDIA BlueField-4 STX:AI 原生存储
这个 NVIDIA BlueField-4 STX 机架采用 NVIDIA BlueField-4 处理器,该处理器结合了 Vera CPU 和 ConnectX-9 SuperNIC,并通过 Spectrum-X 以太网网络进行横向扩展。
它承载NVIDIA CMX 上下文内存存储平台,这是一种新型 AI 原生存储基础设施,可在整个 POD 中无缝扩展 GPU 上下文容量,并通过将 KV 缓存卸载到专用的高带宽存储层来加速推理。CMX 经过优化,可存储和服务大量上下文内存 (KV 缓存),将临时推理上下文视为 AI 原生、共享的数据类型,可在轮次、会话和智能体中重复使用。与传统存储方法相比,这可提供高达每秒 5 倍的 tokens 性能,以及高达 5 倍的能效。
NVIDIA Spectrum-6 SPX:网络机架
将整个 POD 连接到一台超级计算机的是 NVIDIA Spectrum-6 SPX 网络机架。Spectrum-6 SPX 网络机架旨在加速 AI 工厂的东西向和南北向流量。可通过 Spectrum-X 以太网或 NVIDIA Quantum-X800 InfiniBand 交换机 进行配置,它能够大规模提供低延迟、高吞吐量的机架到机架连接。
Spectrum-6 SPX 机架现在包括 102.4 Tb/s Spectrum-6 交换机,在单芯片和多芯片交换机产品中具有 512 通道和 200 Gb/s 光电一体封装 (CPO) 。这种硅光技术集成可取代可插拔收发器,提供更高的能效和弹性、低延迟和抖动,以及近乎完美的有效带宽,使计算和存储环境中的 AI 工作负载保持完美同步。
通过共同设计这些一体式运行的专用机架,Vera Rubin POD 能够加速代理式 AI 工作负载的各个组件。这始于精简的 NVIDIA MGX 机架设计,该设计构成了 POD 中每个机架的基础。
第三代 NVIDIA MGX 机架级架构
生产级 AI 机架必须在以下几个关键领域表现出色:快速实现批量、经过验证的大规模性能、深度硬件 – 软件联合设计、弹性和能效、无缝数据中心部署和物流、为未来架构做好准备等。
第三代 NVIDIA MGX 机架级架构为所有类别设定了标准,其机械、电源和冷却设计中集成了工程突破。
实现弹性和可扩展性
NVIDIA MGX 机架采用单宽设计,优先考虑基于 PCB 的连接。它解锁了完全模块化、无线缆、无软管和无风扇的计算和 NVLink 交换机托盘,可实现更高的可靠性、可扩展性和可维护性。单个 19 英寸宽的机架还简化了运输和物流,加速了 AI 工厂的部署。

机架采用高度模块化的主干作为背板,由多达四个预集成和预认证的铜缆盒组成,将每个托盘连接成一个整体。Spine 可容纳数千条线缆,且机械外形规格与 MGX NVL 和 MGX ETL 机架相同。
确保从芯片到电网的峰值能效
在组件层面,NVIDIA MGX 机架具有动态动力转向功能,可让系统为最需要的组件提供动力。此功能可以在 CPU、GPU 和 NVLink 交换机托盘之间移动功率,确保机架中的组件以峰值能效运行,从而提高性能功耗比。
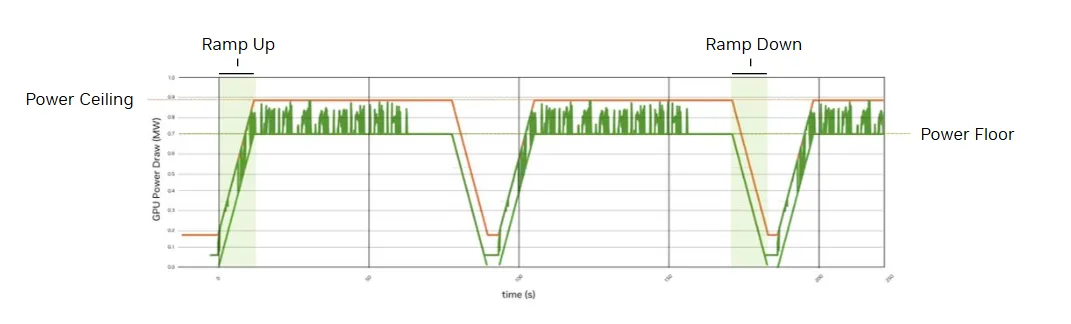
AI 训练和推理工作负载会产生较大的负载波动。如果管理不力,负载波动可能会对电网、数据中心电力基础设施和 IT 设备造成巨大压力。
为防止功率波动,MGX 机架具有机架级能量存储,可使用电容器缓冲电源瞬变。当工作负载同时需要大量电力时,电容器将提供额外的电力,而电网功耗保持不变或上升。当工作负载突然停止时,电容器将充电,而电网功率保持不变或下降。
NVIDIA Vera Rubin NVL72 现已引入智能功耗平滑。与前几代产品相比,它具有 6 倍的机架级能源存储能力 (每个 GPU 400 J) ,并引入了新的闭环系统,使 GPU 能够持续监控电容器的充电状态,从而更有效地扁平化功率曲线。这可大幅降低每分钟的交流电源波动,将峰值电流需求降低高达 25%,并且无需使用大量电池组来防止大规模电源瞬变。
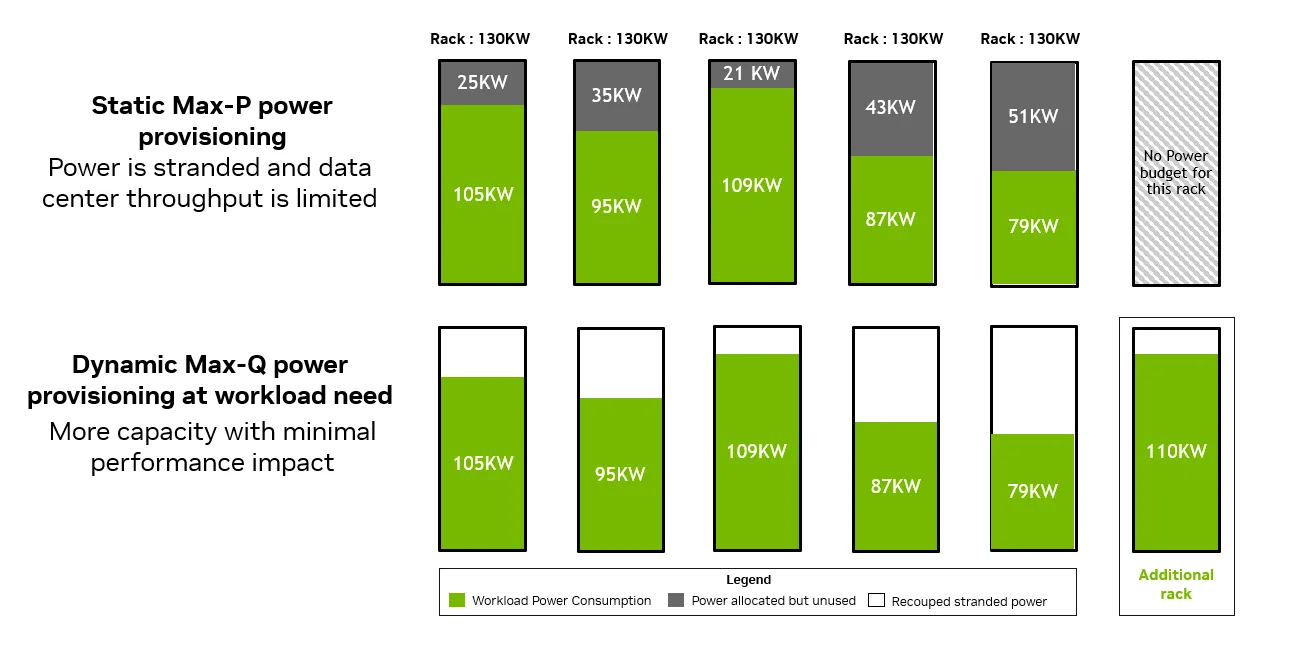
在设施层面,以静态 Max-P 配置机架会提供本可用于生成 tokens 的电力容量。它假设始终需要峰值功率的同构工作负载,而在现实中,AI 工厂会运行具有不同功率需求的多种工作负载。
通过在较低的动态 Max-Q 级别配置 MGX 机架,数据中心可以根据工作负载为每个机架动态配置正确的功率,从而更大限度地提高 AI 数据中心的吞吐量。这样可以释放剩余功率,在 45 ° C 液冷技术下,在相同的功率预算下释放多达 30% 的 GPU,并提高每瓦性能。
释放更多计算能源预算
所有 MGX 机架均经过普遍设计,可在 45 ° C ( 113 ° F) 的暖水入口温度下运行,因此,已设计用于液冷的数据中心可以保证无缝过渡,而无需重新设计冷却基础设施。图 5 展示了基础设施布局的示意图,为 CDU 提供 41 ° C (105.8 ° F) 的水,CDU 转而为 AI 机架提供 45 ° C (113 ° F) 的冷却液。
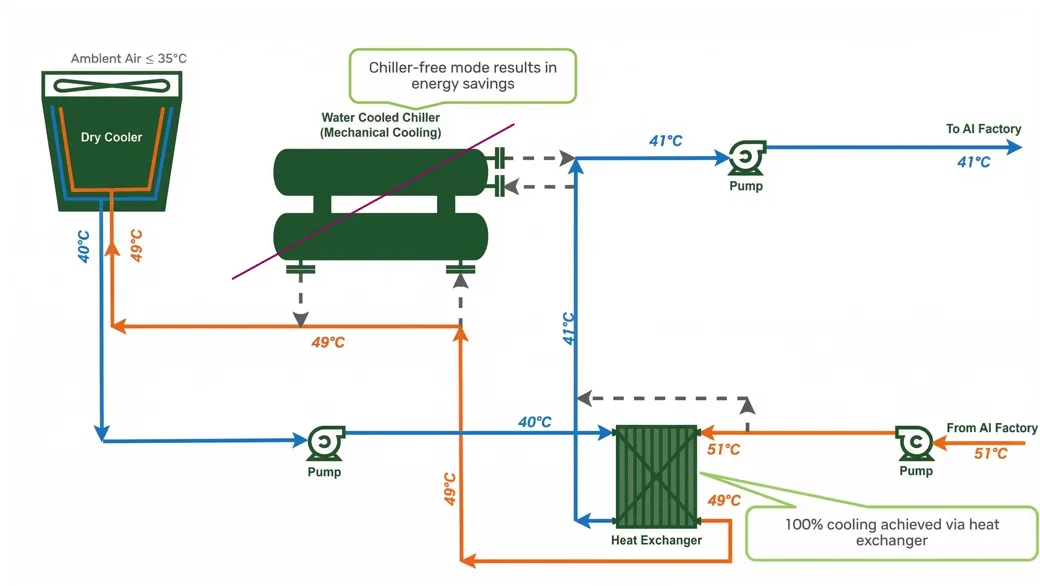
在 45 ° C 下运行,使数据中心能够在许多气候条件下使用环境空气和闭环干冷器进行冷却,从而减少对压缩机的需求,降低 PUE,并释放更多的计算能源预算。较低的入口温度 ( 35 ° C) 需要数据中心分流大量的设施电力或水用于冷却,而较高的入口温度最大限度地提高了直接转换为 tokens 的电网功率。这显著节省了数据中心的能耗,足以在相同的功耗预算下,额外分配多达 10% 的 Vera Rubin NVL72 机架,以生成更多 token 代产品。
MGX 机架采用 100% 液冷技术,可利用与前几代产品相同的数据中心冷却基础设施。第三代 MGX 机架配备新的内部托盘歧管、机架式 UQD08 歧管和最高支持 5000A 的液冷汇流排。用于机架的冷却液将取决于客户和数据中心,但许多冷却液将继续使用去离子水或基于丙烯二醇的液体 (PG25) ,这些液体在闭环系统中可以使用长达 10 年,并且液体维护量最少。
开放标准
这些功能的基础是开放、标准化的 MGX 机架架构。2024 年,NVIDIA Blackwell 推出了首款量产机架级系统。 NVIDIA 将该设计贡献给了开放计算项目 (OCP),强化对开源技术的承诺,并使整个生态系统能够快速创新和加速采用。NVIDIA 已经建立了一个由 80 多个全球合作伙伴组成的生态系统,创建了一个高效、全球多元化的供应链,在将机架级 AI 系统推向市场方面经验丰富。
NVIDIA MGX NVL 机架
作为独立第三方 半分析 InferenceMax 基准测试 SemiAnalysis InferenceMax benchmarks demonstrate, NVIDIA 机架级系统可将每瓦性能提高 50 倍,将每 token 的成本降低 35 倍 ( NVIDIA GB300 NVL72 与 NVIDIA H200 相比) ,这直接转化为更高的收入和更高的运营利润。
2024 年,NVIDIA 交付了首批 NVIDIA GB200 NVL72 机架级系统。2025 年,NVIDIA GB300 NVL72 出货。现在,NVIDIA Vera Rubin NVL72 已全面投产,预计将于 2026 年下半年发货。
NVIDIA Vera Rubin NVL72 的简化设计
NVIDIA Vera Rubin NVL72 是一项工程奇迹,旨在无缝融入现有的数据中心空间。其晶体管数量将比 NVIDIA GB200 NVL72 高出近 2 倍,同时通过极端协同设计将每瓦性能提升 10 倍。该机架在 18 个计算托盘上集成了 72 个 NVIDIA Rubin GPU、36 个 NVIDIA Vera CPU、ConnectX-9 SuperNIC 和 BlueField-4 DPU,以及 9 个 NVLink 交换机托盘。该机架总共容纳了 130 万个独立组件和近 1300 个芯片,这些芯片全部封装在一个较宽的第三代 NVIDIA MGX 机架中,重量约为 4000 磅,大约相当于一辆小卡车的重量。

计算和 NVLink 交换机托盘
第六代 NVLink 使这 72 个 GPU 成为一个统一的引擎。它为每个 GPU 提供 3.6 TB/s 的带宽,为每个机架提供 260 TB/s 的纵向扩展带宽 — — 数据量超过了整个全球互联网的带宽。这种高速数据传输是在机架背面的 NVLink Spine 中进行的,它配备四个模块化预集成线缆盒,其中包含 5000 根铜缆,长度超过 2 英里。
Vera Rubin NVL72 内部的计算托盘完全重新设计自 NVIDIA Blackwell。它采用坚固耐用的 PCB 中板,可安装在单宽机架中,解锁无线缆、无软管和无风扇的设计。这种简化将计算托盘组装时间从近 2 小时缩短到仅 5 分钟,组装速度和可维护性提高了 20 倍。
每个计算托盘配备两个 NVIDIA Vera Rubin 超级芯片,每个包含 17,000 个组件,约为现代智能手机组件数量的五倍。这些超级芯片通过 PCB 中板连接至前部模块化插槽中的八个 ConnectX-9 SuperNIC 和一个 BlueField-4 DPU。

Vera Rubin NVL72 引入了新的机架级弹性功能,旨在更大限度地延长大型 AI 集群的正常运行时间并提高其性能。NVLink 交换机托盘支持操作弹性功能,允许管理员将交换机置于维护模式,并在机架继续运行时进行更换。即使多个交换机托盘不可用,该架构也支持持续运行,从而最大限度地减少维护期间的中断。
在芯片层面,NVIDIA Rubin GPU 持续运行无中断运行状况检查,NVIDIA Vera CPU 具有系统内测试和 SOCAMM 内存功能,可提高可维护性。这些从芯片到机架的创新技术共同减少了运营开销,并建立在 Blackwell 集群实现的弹性提升之上。
NVIDIA Vera Rubin Ultra NVL576
NVIDIA Vera Rubin Ultra 引入了新的两层 all-to-all NVLink 拓扑,使开发者能够扩展到 576 个 GPU。Vera Rubin Ultra NVL576 将 8 个独立的 MGX NVL 机架 (每个机架配有 72 个 Rubin Ultra GPU) 组合在一起,并通过铜缆和直接光纤连接在一个 576-GPU NVLink 域中。它将使用相同的 MGX 机架级生态系统构建,以缩短投产时间。
作为多机架 NVL576 纵向扩展架构的原型,Polyphe 是基于 GB200 的 NVIDIA 内部全功能产品,展示了这种大规模的多机架 NVLink 拓扑结构。

NVIDIA Kyber NVL1152:新一代
为了扩展到 NVL576 之外,我们将推出全新 MGX 机架 NVIDIA Kyber。NVIDIA Kyber 是新一代 MGX NVL 机架设计,将每个机架的 NVLink 域数翻倍,可容纳 144 个 GPU。

NVIDIA Kyber 将使用类似的直接光学互连技术实现机架到机架的纵向扩展,从而扩展为大规模的多对多 NVL1152 超级计算机。Kyber 使用 NVIDIA Feynman 为下一个超大规模 AI 计算时代奠定了基础。Kyber 将首先与 Vera Rubin Ultra 一起推出,作为独立的 NVL144 系统,为客户提供 Vera Rubin Ultra NVLink 扩展域的三种选择:NVL72、NVL144 和旗舰 NVL576。
NVIDIA MGX ETL 机架
虽然 NVIDIA MGX NVL 机架提供大规模纵向扩展的计算域,但代理式 AI 工作流需要高度专业化的节点来实现超低延迟推理、CPU 沙盒和用于 KV 缓存的加速上下文内存。为满足这些不同需求,Vera Rubin 推出了 MGX ETL 机架架构,这是一种完全可配置的全新 MGX 机架,其设计采用 Spectrum-X 以太网主干或直接芯片到芯片主干,利用与 MGX NVL 机架相同的机架级生态系统。
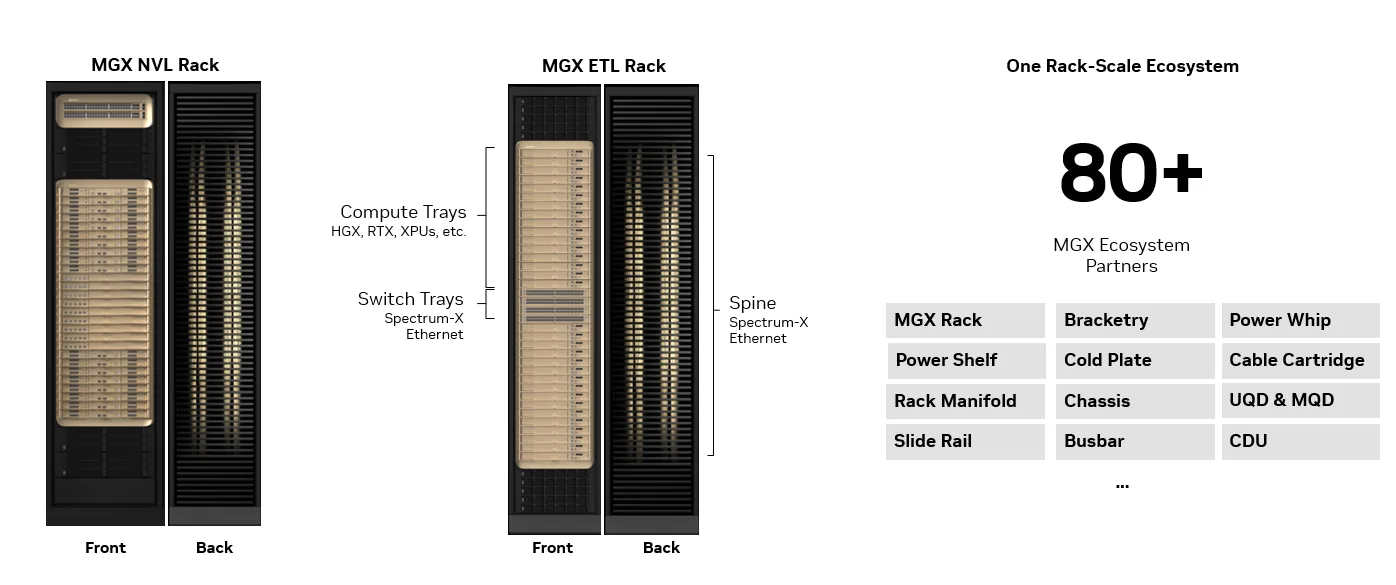
MGX ETL 与 MGX NVL 机架具有相同的外形规格和物理基础设施,并设计为在相同的机械、功率和冷却范围内运行。两个机架将共享由经验丰富的 MGX 生态系统构建的相同关键机架组件:机架、机箱、托盘、线缆盒、液冷歧管、快速断开、汇流排 (标准和液冷) 、支架、侧栏、电源层、防漏托盘、托盘手柄等。
MGX ETL 将使用经过预集成和预先验证的铜缆卡式线缆,以及 Spectrum-X 以太网主干或直接的芯片到芯片主干。MGX ETL 将利用成熟的 MGX 生态系统和供应链,多年来在大规模构建机架架构方面积累了丰富的经验。
NVIDIA Spectrum-X 以太网脊
配备 Spectrum-X 以太网脊节点的 MGX ETL 将成为 Vera Rubin POD 中 Vera CPU 机架和 BlueField-4 STX 存储机架的基础。机架高度可配置,还可容纳多达 256 个 Rubin GPU ( HGX Rubin NVL8 系统) 、XPU 或更多。

在这种设计中,1U MGX ETL 交换机托盘 (基于 Spectrum-6) 位于机架中间。后置端口连接到铜质 Spine,而 32 个前置 OSFP 保持架可将光学收发器连接到 POD 的其余部分。
MGX ETL 利用 Spectrum-X 多平面拓扑,通过多个交换机将 200 Gb/s 通道风扇化,在机架内节点之间提供完整的多对多连接,同时保持单个网络层。预集成的铜脊可提供弹性、高能效的连接 (实现 ETL 机架之间的单层光学连接) ,并在整个 256 个芯片机架中扩展专用 Spectrum-X 以太网,实现零抖动、噪音隔离和负载平衡。
芯片间直接脊柱连接
LPX 机架专为超低延迟推理而设计,将 256 个 LPU 作为一个整体连接在一起。它配备 32 个计算托盘,每个托盘有 8 个 LPU,由一个芯片到芯片的直接主干连接,主干由两个铜质线缆盒组成,通过数千个配对的铜缆连接形成复杂的点对点拓扑结构。这些线缆构成机架背面芯片到芯片的直接主干,包含与其他 MGX 机架相同的线缆盒机械外形规格。这种庞大的互联结构使整个 256-LPU 机架能够作为单个快速推理引擎,使用 Vera Rubin NVL72 进行部署。
在数据中心部署中扩展到多个 LPX 机架时,可在各机架之间保持芯片之间的直接链路,从而使多个 LPX 机架能够作为一个速度超快的单一推理引擎运行。
NVIDIA Vera Rubin DSX AI 工厂平台
NVIDIA Vera Rubin DSX 是一个 AI 工厂平台,可为共同设计的 AI 基础设施 (从芯片到电网) 提供蓝图和参考设计。它可将电网功率更大限度地提升到 token 的效率和良好的输出,并加快首次生产的时间。
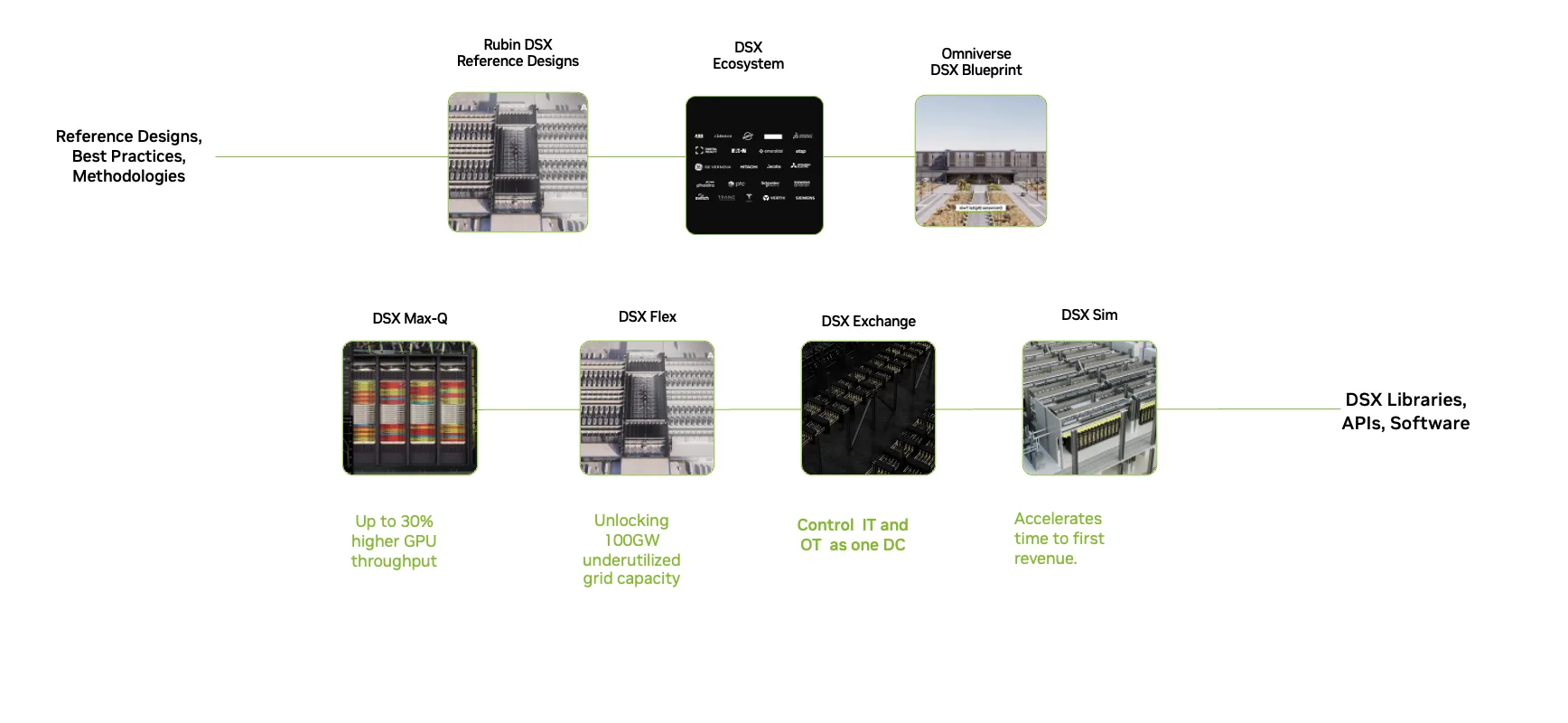
NVIDIA Vera Rubin DSX 将芯片、系统、软件库、API 和全球合作伙伴生态系统整合到一个架构中,在整个 AI 工厂中紧密集成计算、网络、存储、电源、冷却和设施控制。这使生态系统合作伙伴能够快速设计、部署和扩展吉瓦级 AI 工厂,实现每瓦 token 的最大吞吐量,并通过端到端内置在 DSX 平台中的弹性和能效缩短正常运行时间。
详细了解 NVIDIA Vera Rubin POD
AI 基础设施正在迅速发展,从独立芯片、独立服务器和机架级系统发展为共同设计的 POD 级超级计算机和 AI 工厂。现代代理式 AI 工作负载正在推动向专用 AI 基础设施的转变,该基础设施将计算、网络和存储集成到单个紧密结合的超级计算机中。NVIDIA Vera Rubin POD 将五个机架级系统与第三代 NVIDIA MGX 机架的关键机械、功率和冷却创新相结合,提供可扩展性、弹性和能效。
在 AI 工厂规模,NVIDIA Vera Rubin DSX 参考设计和NVIDIA Omniverse DSX Blueprint适用于 AI 工厂数字孪生,为构建和运营 AI 工厂提供了统一的框架。这些创新成果共同带来了性能、成本效益和节能方面的巨大提升,为代理式应用时代提供动力支持。
加入我们 NVIDIA GTC 2026 观看 GTC 主题演讲 NVIDIA 创始人兼首席执行官黄仁勋的演讲。



