
从 25.10 版本开始,现在可以直接从 PyPI 下载用于 pip 安装的 cuML wheels。无需执行复杂的安装步骤或管理 Conda 环境,只需像安装其他 Python 包一样,直接使用 pip 安装即可。
NVIDIA 团队始终致力于全面提升 cuML 的易用性和效率。其中一大挑战是管理 CUDA C++ 库的二进制大小,这会影响用户体验以及通过 PyPI 进行 pip 安装的能力。在 pypi.org 上分发 wheel 文件可覆盖更广泛的用户群体,并使企业环境中的用户能够在内部的 pypi.org 镜像上获取 wheel 文件。
PyPI 对二进制文件的大小进行了限制,以控制 Python 软件基金会(PSF)的运营成本,并防止用户意外下载过大的文件。过去,cuML 库由于复杂性较高,其二进制文件体积超出了 PyPI 的托管限制,但我们与 PSF 紧密合作,通过优化显著减小了文件大小,成功解决了这一问题。
本文将为您介绍 cuML 的新 pip 安装方式,并提供一份教程,说明团队如何缩减 CUDA C++ 库的二进制体积,从而在 PyPI 上发布 cuML 的 wheel 包。
从 PyPI 安装 cuML
要从 PyPI 安装 cuML,请根据您系统的 CUDA 版本使用以下命令。这些软件包已针对兼容性与性能进行了优化。
CUDA 13
车轮大小:250 MB
pip install cuml-cu13
CUDA 12
车轮大小:~470 MB
pip install cuml-cu12
cuML 团队如何将二进制文件的大小减少约 30%
通过应用精细的优化技术,NVIDIA 团队成功将 CUDA 12 libcuml 动态共享对象 (DSO) 的大小从约 690 MB 减少至 490 MB,缩减了近 200 MB,降幅约为 30%。
较小的二进制文件提供:
- 加快 PyPI 下载速度
- 减少用户存储需求
- 加速容器构建以支持部署
- 降低带宽分发成本
减少二进制大小需要采用系统化方法,以识别并消除 CUDA C++ 代码库中的膨胀。在博文后文,我们将分享实现这一目标的技术,这些技术将使所有使用 CUDA C++ 库的团队受益。我们期望这些方法能够帮助库开发者更好地管理其二进制文件的大小,并推动 CUDA C++ 库生态系统朝着更易于维护的二进制规模发展。
CUDA 二进制文件为何如此庞大?
如果您曾提供过编译后的 CUDA C++ 代码二进制文件,可能已经注意到,这些库的体积通常比实现类似功能的普通 C++ 库大得多。CUDA C++ 库中包含大量内核(即 GPU 函数),这些内核构成了二进制文件大小的主要部分。每个内核实例化本质上是以下各项的交叉乘积:
- 代码中使用的所有模板参数
- 库所支持的真实 GPU 架构,以 Real-ISA 机器代码形式进行编译,该代码是用于执行 CUDA 代码的最终二进制格式
当您添加更多功能并支持更新的架构时,二进制大小可能会迅速变得难以管理。即使只支持单个架构,其二进制文件也远比具备相同功能集的 CPU 库要大。
请注意,此处分享的技术并非解决所有二进制大小问题的通用方案,也未涵盖所有可能的优化方法。我们将重点介绍在 cuML 及其他 RAPIDS 库(例如 RAFT 和 cuVS)中行之有效的部分优化实践。需要说明的是,示例较为宽泛,开发者需根据实际情况,在二进制大小与运行时性能之间进行权衡。
了解 CUDA 整体编译模式
在深入探讨解决方案之前,必须清楚了解 CUDA 编译在默认情况下的工作原理。
CUDA C++ 库通常在“Whole Compilation”(全编译)模式下进行编译。这意味着,每个包含使用三重尖括号语法(kernel<<<...>>>)启动核函数的翻译单元(TU)(即每个.cu 源文件),都会包含该核函数的一个副本。标准 C++ 链接过程会从最终的可执行文件中去除重复的符号,而 CUDA C++ 的链接过程则会将所有副本中的核函数分别编译到各个翻译单元中。

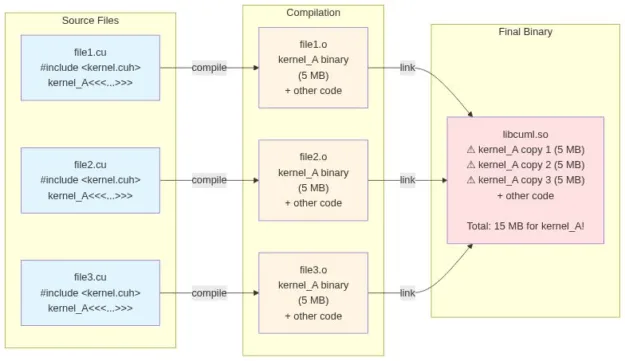
要检查 DSO 中是否存在重复的内核实例,可执行以下命令:
cuobjdump -symbols libcuml.so | grep STO_ENTRY | sort -b | uniq -c | sort -gb
注意:虽然启用 CUDA 可分离编译能够过滤掉重复的内核,但这并非一个完整的解决方案。实际上,在某些情况下,默认启用该功能反而可能增加二进制文件的大小和链接时间。有关更多详细信息,请参阅以光速构建 CUDA 软件。
以编程方式移除重复的内核实例
解决此问题的关键在于将核函数的定义与声明分离,确保每个核函数仅在一个 TU 中编译。结构如下:
函数声明 (kernel.hpp):
namespace library {
void kernel_launcher();
}
仅在单个 TU 中编译函数和核函数 (kernel.cu):
#include <library/kernel.hpp>
__global__ void kernel() {
/// code body
}
void kernel_launcher() {
kernel<<<...>>>();
}
请求核函数执行 (example.cu) :
#include <library/kernel.hpp>
namespace library {
kernel_launcher();
}
通过将核函数的定义与声明分离,核函数将在一个翻译单元(TU)中编译,并通过启动器结构从其他翻译单元中调用。这种主机端包装器是必要的,因为在某个翻译单元中不能添加核函数的函数体,也无法在另一个翻译单元中通过包含核函数定义的头文件来启动该核函数。
优化头文件中共享的内核函数模板
如果您要使用函数模板来提供仅有标头的 CUDA C++ 库,或包含共享实用工具内核的编译二进制文件,可能会遇到一个挑战:函数模板在调用点处被实例化。
反模式:隐式模板实例化
设想一个同时支持行主序和列主序两种二维数组布局的内核:
namespace library {
namespace {
template <typename T>
__global__ void kernel_row_major(T* ptr) {
// code body
}
template <typename T>
__global__ void kernel_col_major(T* ptr) {
// code body
}
}
template <typename T>
void kernel_launcher(T* ptr, bool is_row_major) {
if (is_row_major) {
kernel_row_major<<<...>>>(ptr);
}
else {
kernel_col_major<<<...>>>(ptr);
}
}
}
这种方法为每个调用 kernel_launcher 的 TU 提供两个内核实例,无论用户是否需要这两个实例。
模式:显式模板参数
解决方案是将编译时信息以模板参数的形式公开:
namespace library {
namespace {
template <typename T>
__global__ void kernel_row_major(T* ptr) {
// code body
}
template <typename T>
__global__ void kernel_col_major(T* ptr) {
// code body
}
}
template <typename T, bool is_row_major>
void kernel_launcher(T* ptr) {
if constexpr (is_row_major) {
kernel_row_major<<<...>>>(ptr);
}
else {
kernel_col_major<<<...>>>(ptr);
}
}
}
这种方法引入了意图。若用户需要这两个内核实例,可显式地进行实例化;而多数下游库通常仅需一个,从而显著减小了二进制文件的大小。
注意:通过采用一组受限的模板参数,将内核函数模板编译为尽可能小的形式,该方法不仅能加快编译速度,还可提升运行时性能。同时,它还支持您基于模板实例化进行编译时优化的预计算。
优化源文件中的内核函数模板
即使消除了重复的内核实例,针对具有多种模板类型的大型内核,仍需进行更多优化工作。
反模式:将运行时参数用作模板参数
编译二进制文件时,引入模板参数可能导致不必要的多个内核实例生成。与在头文件中编写函数模板相比,这种方式需要更多的模板实例化。
示例 (detail/kernel.cuh) :
namespace {
template <typename T, typename Lambda>
__global__ void kernel(T* ptr, Lambda lambda) {
lambda(ptr);
}
}
用法 (example.cu) :
namespace library {
template <typename T>
void kernel_launcher(T* ptr) {
if (some_conditional) {
kernel<<<...>>>(ptr, lambda_type_1{});
}
else {
kernel<<<...>>>(ptr, lambda_type_2{});
}
}
}
这种方法不可避免地会在预编译的二进制文件中生成两个核函数实例。
模式:将模板转换为运行时参数
编写核函数模板时,应始终自问:“该模板参数能否转换为运行时参数?”一旦答案为“是”,请按以下步骤进行重构:
定义 (detail/kernel.cuh) :
enum class LambdaSelector {
lambda_type_1,
lambda_type_2
};
template <typename T>
struct lambda_type_1 {
void operator()(T* val) {
// do some op
}
};
template <typename T>
struct lambda_type_2 {
void operator()(T* val) {
// do some other op
}
};
namespace {
template <typename T>
__global__ void kernel(T* ptr, LambdaSelector lambda_selector) {
if (lambda_selector == LambdaSelector::lambda_type_1) {
lambda_type_1<T>{}(ptr);
}
else if (lambda_selector == LambdaSelector::lambda_type_2){
lambda_type_2<T>{}(ptr);
}
}
}
用法 (example.cu) :
namespace library {
template <typename T>
void kernel_launcher(T* ptr) {
if (some_conditional) {
kernel<<<...>>>(ptr, LambdaSelector::lambda_type_1);
}
else {
kernel<<<...>>>(ptr, LambdaSelector::lambda_type_2);
}
}
}
现在仅交付一个内核实例,使二进制文件大小缩减至原始规模的近一半。将模板参数转换为运行时参数的影响随系数递增而放大:缩减幅度为 1 /(已删除的模板实例化交叉乘积)。
注意:此方法可加快编译速度,但因增加了内核复杂性并限制了编译时优化,可能导致运行时性能有所下降。
开始在 PyPI 上使用 cuML
我们很高兴将 cuML 引入 PyPI。我们希望此处分享的技术能为使用 CUDA C++ 的其他团队提供参考,帮助他们实现类似成果,并鼓励大家在构建 Python 接口时分享各自在 PyPI 上的实践经验。
如需了解更多关于基于 CUDA C++ 构建库的技巧,可查阅更新版的 CUDA 编程指南。若要开始使用 CUDA,建议参考 CUDA 的入门介绍。




