
部署和优化大语言模型 (LLM) 以实现高性能、经济高效的服务可能是一项艰巨的工程难题。任何给定工作负载 (例如硬件、并行和预填充/ 解码拆分) 的理想配置都存在于一个庞大的多维搜索空间中,而手动或通过详尽测试无法探索该空间。AIConfigurator 是一款开源工具,可简化 NVIDIA Dynamo AI 服务堆栈,旨在降低复杂性,并在几分钟内优化部署。
AIConfigurator 的核心优势在于,您无需在真实硬件上运行所有可能的配置,即可预测哪种配置的性能最佳。相反,它将 LLM 推理分解为其构成运算,并在目标 GPU 上单独测量每个运算。然后,AIConfigurator 可以重新组合这些测量结果,以估算任何配置的端到端性能,而无需在搜索时占用一个 GPU 小时。
本博客将简要概述 AIConfigurator 的工作原理;如何将其与 Dynamo 结合使用;以及阿里巴巴和 Mooncake 等生态系统贡献者如何帮助将此开源项目的功能扩展到所有框架。
使用 AIConfigurator 配置解服务
借助 AIConfigurator,每个操作 (包括通用矩阵乘法 (GEMM) 、注意力、通信和混合专家模型 (MoE) 调度) 的延迟估算均由在目标硬件上收集的真实内核测量结果提供支持。收集器工具链针对所支持的量化模式、批量大小、序列长度和 GPU 数量对每个基元进行基准测试,并将结果记录到硅校准性能数据库中。当收集的数据无法用于新模型或 GPU 时,AIConfigurator 会使用经验校正系数回退到光速顶线估计值,甚至在对模型进行经验性分析之前就能提供可用的建议。
在此估计层之上,AIConfigurator 对用于聚合服务的连续批处理、速率匹配预填充和解码工作池进行建模,以进行分解服务,并处理 MoE 特定的问题,如专家并行和 token 路由偏差。它不会返回单个答案,而是在所有评估的配置中计算 Pareto 前沿,同时显示聚合和解模式的吞吐量与延迟权衡。完整搜索通常涵盖数万个候选配置,只需几秒钟即可完成,而无需花费数天时间在 GPU 上进行搜索。
要了解此工具如何为开发者提供帮助,请考虑一个具体示例:在 64 个 NVIDIA B200 GPU 上部署具有 NVFP4 量化的 Qwen3-32B,目标 SLA 为 time-to-first-token (TTFT) 和 time-per-output-token (TPOT) 之间的时长分别为 1000 毫秒和 15 毫秒。您可以使用单个命令搜索数千个候选配置:
pip install aiconfigurator # or install from source for latest aiconfigurator cli default \ --model-path nvidia/Qwen3-32B-NVFP4 \ --total-gpus 64 \ --system b200_sxm \ --isl 15000 --osl 500 \ --ttft 1000 --tpot 15 \ --save-dir ./results |
AIConfigurator 会在几秒钟内返回推荐内容。在本示例中,解服务可实现 550 tokens/s/ GPU,比最佳聚合配置提高 38%。输出包括一个 Pareto 边界,用于可视化完整的权衡空间、等级配置 (best_config_topn.csv) 、每个工作者类型的引擎配置,以及两种服务模式的即用型部署构件。
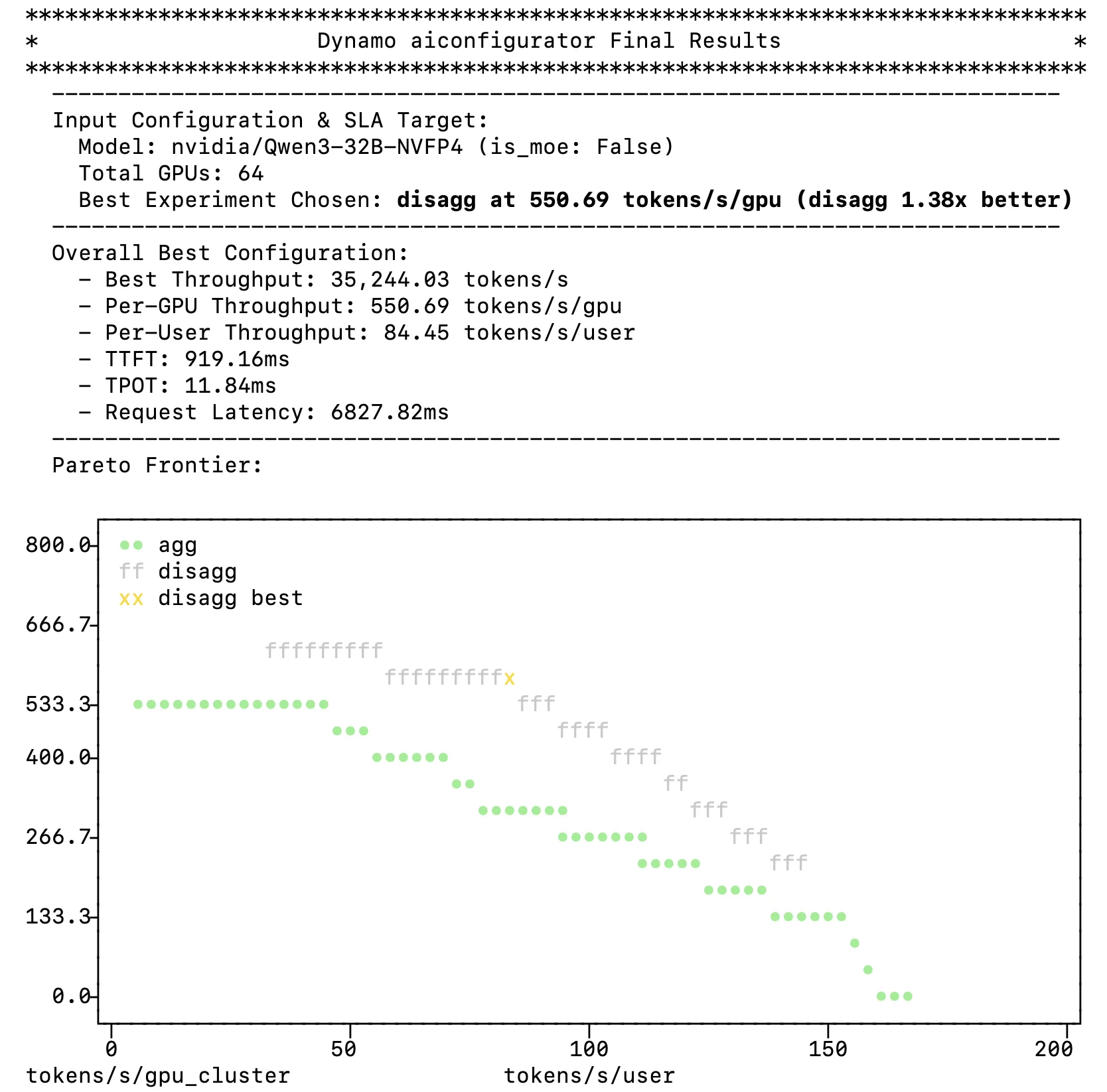
要在 Dynamo 中进行解服务,部署推荐的配置需要一个命令:
kubectl apply -f results/disagg/top1/k8s_deploy.yaml |
此工作流可跨模型和硬件进行推广。无论是在 8 个 NVIDIA H200 GPU 上部署 Qwen3-32B,还是在多节点 B200 集群上部署 DeepSeek-V3,接口都相同;AIConfigurator 可根据指定的模型、硬件和 SLA 限制调整其搜索空间和建议。
扩展对多个框架的支持
AIConfigurator 最初仅支持 NVIDIA TensorRT LLM,但随着 SGLang 等框架越来越受欢迎,尤其是对于 DeepSeek 等 MoE 模型,单后端支持已不再足够。我们设计了一个与框架无关的抽象层,该层具有统一的参数映射,可在单个接口后规范化每个后端的配置模式和术语。当 Mooncake 和阿里巴巴等社区合作伙伴将 SGLang 支持变为现实时,这项投资得到了回报,并在以下章节中介绍了收集、验证和集成工作。
从用户的角度来看,比较后端是一种单标志变化:
# TensorRT LLMaiconfigurator cli default \ --model-path nvidia/Qwen3-32B-NVFP4 \ --total-gpus 64 --system b200_sxm \ --backend trtllm# SGLangaiconfigurator cli default \ --model-path nvidia/Qwen3-32B-NVFP4 \ --total-gpus 64 --system b200_sxm \ --backend sglang# vLLMaiconfigurator cli default \ --model-path nvidia/Qwen3-32B-NVFP4 \ --total-gpus 64 --system b200_sxm \ --backend vllm |
更简单地说,--backend auto在一个命令中比较三个框架:
aiconfigurator cli default \ --model-path nvidia/Qwen3-32B-NVFP4 \ --total-gpus 64 --system b200_sxm \ --backend auto |
各后端的搜索过程相同;只有生成的部署构件不同,每个后端都以预期格式接收原生配置文件、CLI 参数和 K8s 清单。AIConfigurator 目前随附适用于 NVIDIA H100、H200 和 B200 系统的 TensorRT LLM 和 SGLang 的芯片验证性能数据,并在选定平台上提供 vLLM 支持。
用于 SGLang 的 WideEP 推理
SGLang 在运行“Wide Expert Parallelism” (WideEP) 时特别受欢迎,它通过将专家分布到大量 GPU 上,显著提高了 DeepSeek V3/ R1 等 MoE 模型的解码吞吐量。为了准确模拟 SGLang 的 WideEP 路径,AIConfigurator 模拟了 DeepEP 多对多通信、MTP、MLA 注意力、注意力 DP、工作负载感知 MoE 和专家并行负载均衡 (EPLB) 等关键元素。MoE 和 EPLB 建模面临着巨大的挑战。
WideEP 的 MoE 路由本身存在负载不平衡问题,一些专家获得的 tokens 比其他专家多。AIConfigurator 使用 Alpha 参数对这种规工作负载分布进行建模。此 alpha 可充当性能数据库中的查找键,将分布模式与收集的延迟配置文件关联起来,类似于标准 MoE 路径。根据经验,1.01 与 DeepSeek V3.1 非常适合跨数据集的预填充和解码。
在 WideEP 部署中,AIConfigurator 通过调整两个因子来模拟 EPLB,而不是直接模拟算法。首先,工作负载分布 Alpha 从 1.01 降低到 0.6,以反映专家复制的负载平滑。其次,将有效的 token 计数乘以 0.8,对每个 GPU token 负载最大值的经验性缩减进行建模。这些更改可选择正确的延迟曲线,并相应地调整操作点。
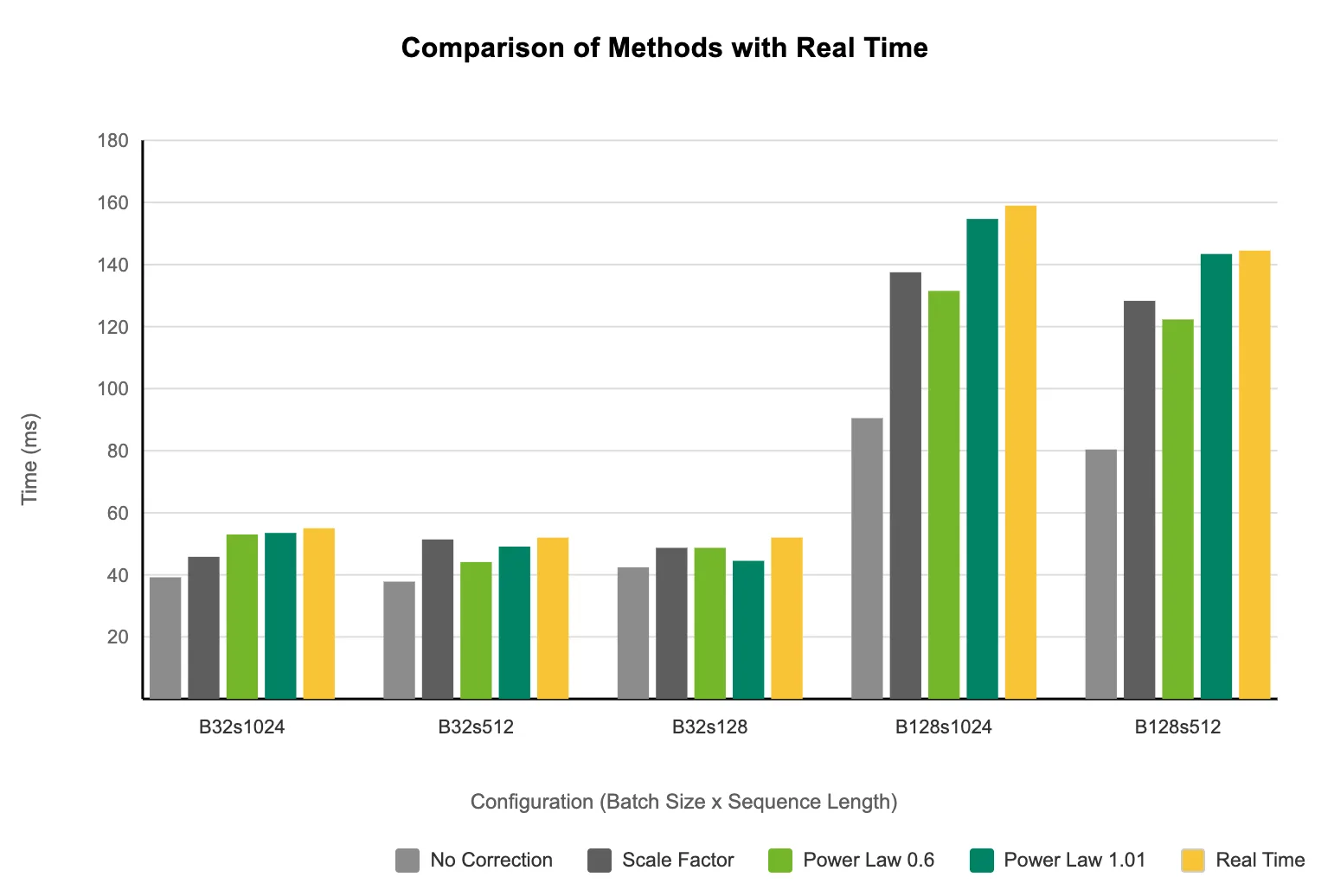
初步结果很有前景:AIConfigurator 确定的最佳配置与手动调整的生产配置保持一致。我们计划开展进一步合作,使其做好生产准备。
SGLang 社区如何做出贡献
Mooncake:AIConfigurator 中的初始 SGLang 支持
AIConfigurator 最初仅支持 TensorRT LLM,为 SGLang 和 vLLM 保留接口,而未完全实现。Mooncake ( Moonshot AI、清华大学等公司合作开发的开源项目) 的贡献者随后开发了 SGLang 后端的第一个版本。
他们首先完成了收集器层,对核心运算 ( GEMM、注意力、批量 GEMM) 进行建模和封装。这样可以快速支持 Llama、Qwen 和 DeepSeek 等模型。这项工作与随后的 SGLang WideEP 工作相结合,形成了 AIConfigurator 的第一个 SGLang 后端。
阿里巴巴:将 AIConfigurator 集成到 AI 服务堆栈中,实现自动化部署
AI 服务堆栈基于阿里 Kubernetes 容器服务 ( ACK) 构建,是一个端到端解决方案,可实现高效且可扩展的云原生 LLM 推理。它管理整个生命周期,提供部署、智能路由、自动扩展和深度可观测性。
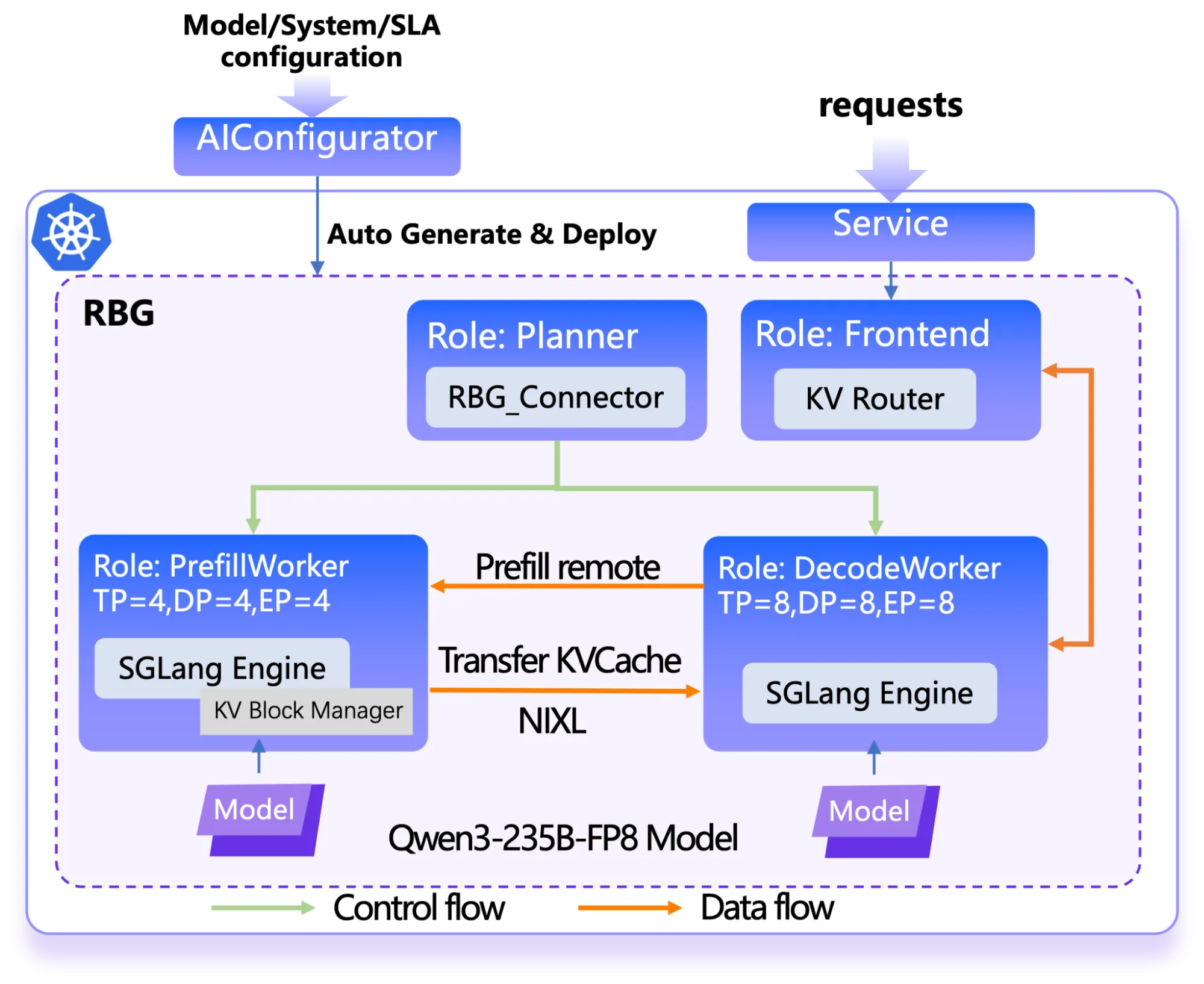
在此堆栈中,阿里云大力助力的 SGLang 社区孵化 AI 编排引擎 RoleBasedGroup (RBG) 简化了 Kubernetes 上的 LLM 推理服务部署。RBG 使用“角色”作为其核心编排单元,将基于预填充 – 解码 – 分解的服务划分为路由器、预填充和解码角色,以协调它们的放置、缩放和更新。这可确保性能和稳定性的平衡,以及基于角色的可扩展性。
完整的 Dynamo 服务堆栈可以通过 ACK 上的 AI 服务堆栈进行部署,并利用 AIConfigurator 预测结果作为输入和 AIConfigurator 的生成器模块。ACK 团队可以为 RBG 生成可部署配置,请参阅参考这里。通过整合这一流程,阿里巴巴在 Qwen3-235B-FP8 模型上实现了 1.86 倍的吞吐量,同时将 TTFT 保持在 5000 毫秒以内,ITL 保持在 40 毫秒以内。
RBG 将继续跟踪 AIConfigurator 的进展,并为在 ACK 中快速部署新模型提供零日支持。
阿里巴巴:基于 AIConfigurator 构建 HiSim
AIConfigurator 可优化静态工作负载,但无法轻松对动态、突发生产流量、复杂调度和 KV 缓存动态进行建模。为了克服这一问题,阿里巴巴 TAIR KV 缓存团队创建了 Tair-KVCache-HiSim,这是一款轻量级、高保真的事件驱动型系统模拟器。
HiSim 通过系统级模拟来处理动态流量和队列 (预测可变速率和复杂调度 (如 SGLang) 下的 TTFT、TPOT 和吞吐量) 以及高级 KV 缓存优化 (量化多级存储和各种拆迁/ 预取策略的权衡) 。
HiSim 由工作负载生成器、全局路由器模拟器和推理引擎模拟器 (IES) 组成。IES 使用统一的全局时钟来协调调度器模拟器 (管理 LLM 请求:抢占、批处理) 、KVCache Manager Simulator ( HiCacheController,对三级 KV 缓存和驱逐进行建模) 和 BatchRunnerEstimator ( AIConfiguratorTimePredictor,根据 AIConfigurator 计算批量延迟) 。
此结构可快速适应各种推理引擎 ( vLLM、SGLang、TensorRT LLM) ,准确模拟现实世界的配置、运行时参数和执行语义 (并行、批处理、设备优化) ,无需修改引擎,从而确保高保真。
HiSim 通过配置调整来量化调度权衡 ( TTFT/ 吞吐量、队列/ 内存、缓存命中/ TTFT、重叠效率) ,从而指导 SGLang 研发,而无需更改代码。它通过估算性能上限和使用理论规格识别瓶颈,为新硬件提供“Oracle”评估。HiSim 还通过三级 KV 缓存设计 (例如,L2 大小、预取/ 驱逐策略、L3 带宽需求、写入与写入) 来帮助 HiCache 架构探索和成本/ 性能优化,以找到最佳性价比点。
利用 AIConfigurator,HiSim 将静态分析扩展到动态流量的主动、成本感知部署建议。端到端仿真与实际性能相比,误差在 5% 以内。未来的工作将加强这种合作,以构建一个高保真、生产就绪的系统模拟器。
AIConfigurator 的下一步发展
未来的路线图将 AIConfigurator 从独立的命令行工具扩展到 Dynamo 平台的核心组件:
- 更快的模型支持。 “混合”模式已通过光速估算提供首发日推荐;我们还将自动执行芯片数据采集流程,以加速经过全面验证的支持。
- 助力 Dynamo 部署。AIConfigurator 正在通过 DynamoGraphDeploymentRequest (DGDR) CRD 成为 Dynamo Kubernetes 流背后的配置引擎,通过单个 YAML 文件生成优化的部署。
- 动态工作负载建模。 从静态输入序列长度/ 输出序列长度/ 并发目标转向直接捕获生产工作负载分布的模型。
NVIDIA 计划继续与第三方合作,将 AIConfigurator 引入更多系统和工具。AIConfigurator 非常欢迎大家做出贡献,包括新硬件的性能数据、其他后端支持、新功能以及 HiSim 等扩展程序。
要开始使用,请查看 AIConfigurator 资源库,并查看 Dynamo 项目,了解设置解服务的最快方法。
有关完整的技术处理 (包括形式定义和验证结果) ,请阅读我们的论文:AIConfigurator:Lightning-Fast Configuration Optimization for Multi-Framework LLM Service.




