
在本文中,我们将深入探讨现代 AI 中至关重要的工作负载之一:Flash Attention,您将了解:
- 如何使用 NVIDIA cuTile 实现 Flash AttentioncuTile。浏览完整代码,以构建生产就绪型应用。
- “捕获并拯救”优化之旅。本案例研究展示了原生优化(如增大图块大小)可能适得其反的原因,并探讨了相应的解决方案。
- 先进技术如 FMA 模式、快速数学计算、循环分割和自适应平铺,实现卓越性能。
环境要求:
- CUDA 13.1 或更新版本
- GPU 架构:NVIDIA Blackwell(例如,NVIDIA B200、GeForce RTX 50 系列)
- Python:3.10 或更新版本
有关安装 cuTile Python 的更多信息,请参阅快速入门文档。
什么是注意力?
注意力机制是 Transformer 模型的计算核心。给定 token 序列,注意力机制使每个 token 能够“查看”其他 token,并动态调整它们对当前 token 的贡献程度。从数学角度看,对于输入矩阵 Query (\(Q\))、Key (\(K\)) 和 Value (\(V\)),输出可表示如下:
\(O = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V\)
其中:
- \(Q \text{ has shape } (N,d),\ N \text{ query tokens, each with dimension } d.\)
- \(K \text{ has shape } (N,d),\ N \text{ key tokens.}\)
- \(V \text{ has shape } (N,d),\ N \text{ value tokens.}\)
- \(\text{The intermediate } QK^{T} \text{ matrix has shape } (N,N), \text{ is a problem.}\)
内存带宽问题
对于长度为 \(N = 16,384\)(在现代 LLM 中很常见)的序列,注意力矩阵 \(QK^{T}\) 包含约 \(N^2 = 268\) 亿个元素。在 FP16 精度下,每个注意力头、每个批量样本需要 512 MB 的中间存储空间。
标准注意力实现:
- 计算完整的 \(N \times N\) 注意力矩阵并将其写入全局内存(速度较慢)
- 逐行应用 softmax 函数
- 读回该矩阵并与 \(V\) 相乘
这种方法受内存限制,因为 GPU 大部分时间都在等待数据在 HBM 与计算单元之间传输,而非等待计算完成。
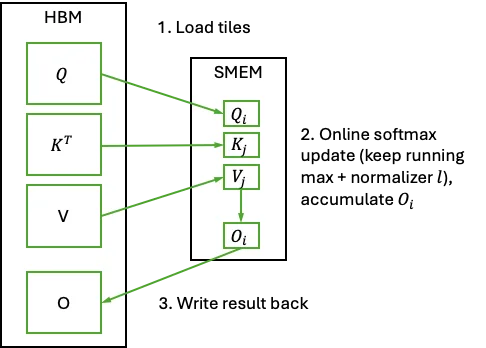
Flash Attention 如何解决内存带宽瓶颈问题
Flash Attention(由 Dao 等人于 2022 年提出)是一种 IO 感知算法,不会显式构造完整的 \(N \times N\) 矩阵。相反,它:
- 将计算划分为小块: 将进程 \(Q, K, V\) 载入快速片内 SMEM 中
- 采用在线 softmax: 无需整行数据,可逐步计算 softmax
- 融合运算: 将矩阵乘法与 softmax 融合至单个内核中
其结果是速度提升了2-4倍,同时节省了大量内存,从而支持更长的上下文长度。
了解在线 Softmax
Flash Attention 的关键算法见解是在线 Softmax 技巧。数值稳定的 safe softmax 要求在计算前掌握整行的最大值:
\(\text{softmax}(x_i) = \frac{e^{x_i – \max(x)}}{\sum_j e^{x_j – \max(x)}}\)
但如果我们要处理图块,则无法访问完整的行。Online Softmax 通过维护可逐步更新的运行统计量来解决这一问题。
在线 softmax 算法
我们为每行维护两个运行值:
- \(m_i\): 截至目前观测到的最大值(用于数值稳定性)
- \(l_i\): 截至目前观测到的指数之和(softmax 分母)
当我们处理具有值 \(x_{new}\) 的新图块时:
- 更新最大值:\(m_{new} = \max(m_i, \max(x_{new}))\)
- 计算校正系数:\(\alpha = e^{m_i – m_{new}}\) (对先前的数值进行重新缩放)
- 更新总和:\(l_i = l_i \cdot \alpha + \sum e^{x_{new} – m_{new}}\)
- 更新累加器:\(acc = acc \cdot \alpha + P_{new} \cdot V_{tile}\)
\(P_{new}\) 是注意力权重矩阵,\(V_{tile}\) 是与当前迭代的键图块对应的值矩阵图块。最后,我们进行归一化处理:\(O = acc / l_i\)。
这使我们能够在不存储整行的情况下,计算出精确的 softmax。
因果注意力和分组查询注意力
在深入探讨实现细节之前,我们先来了解现代大语言模型中采用的两种重要注意力变体:
因果注意力
在 GPT、LLaMA 和克劳德等自回归语言模型中,每个 token 只能基于序列中前面的 tokens 进行处理,而无法访问未来的信息。这种机制可防止模型在训练过程中提前获知后续内容,从而避免“作弊”现象的发生。
从数学角度来看,我们对注意力分数应用了三角形掩码:
\(\text{mask}_{ij} = \begin{cases} 0 & \text{if } i \geq j \text{ (query position ≥ key position)} \ -\infty & \text{if } i < j \text{ (future tokens)} \end{cases}\)
被屏蔽的注意力变成:
\(O = \text{softmax}\left(\frac{QK^T}{\sqrt{d}} + \text{mask}\right)V\)
将 \(-\infty\) 添加到未来位置,可确保其在 softmax 之后变为零,从而有效阻断未来 token 的信息流动。
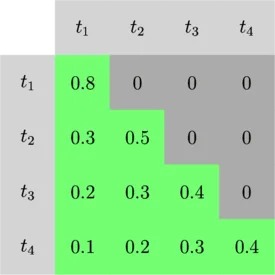
使用因果遮罩时,约有一半的注意力矩阵会被遮罩(上三角部分)。我们可以跳过这些被遮罩区域的计算,提供两倍的算法加速。这对 K 循环分块优化至关重要。
分组查询注意力
标准的多头注意力机制为每个注意力头都配备独立的 \(K,V\) 矩阵,导致内存占用较高:
- 多头注意力 (MHA):32 个查询头 + 32 个 K/V 头(1:1 比率)
- 分组查询注意力 (GQA):32 个查询头 + 4 个 K/V 头(8:1 比率)
- 多查询注意力 (MQA):32 个查询头 + 1 个 K/V 头(32:1 比率)
在 GQA 中,多个查询头共享相同的 K/V 头。例如,当使用 32 个查询头和 4 个 K/V 头时:
- 查询头 0-7 使用 K/V 头 0
- 查询头 8-15 使用 K/V 头 1
- 查询头 16-23 使用 K/V 头 2
- 查询头 24-31 使用 K/V 头 3
这在推理期间将 K/V 缓存大小减少了 8 倍,对提供长上下文模型具有重要意义。LlamA 2、Llama 3、Mistral 和 Qwen 等现代 LLM 广泛采用 GQA。
在 Flash Attention 的实现中,每个 CUDA 块负责计算一个查询头的注意力,同时会加载对应的共享 K/V 头:
head_idx = bid_y % num_heads # Which query head (0-31)
kv_head_idx = head_idx // query_group_size # Which K/V head (0-3)
查询组大小为 8 时,查询头 0-7 均映射至 kv_head_idx = 0,在内存中共享相同的 K/V 图块。
第 1 部分:CUDA Tile 中的 Flash 注意力内核
我们来逐步实现 Flash Attention。基准版本采用较小的 64 × 64 图块和简洁的代码——虽然正确,但尚未优化。
1. 定义内核接口
在 cuTile 中,@ct.kernel 装饰器用于将 Python 函数标记为 GPU 内核。我们通过 ct.Constant[T] 类型标注来传递编译时常量:
import math
import cuda.tile as ct
# Type aliases for compile-time constants
ConstInt = ct.Constant[int]
ConstBool = ct.Constant[bool]
# Conversion factor: we use exp2 instead of exp for efficiency
INV_LOG_2 = 1.0 / math.log(2)
@ct.kernel()
def fmha_kernel(
Q, K, V, Out, # Input/output tensors
qk_scale: float, # Scale factor (1/sqrt(d))
input_pos: int, # Position offset for causal masking
TILE_D: ConstInt, # Head dimension (for example, 128)
H: ConstInt, # Number of attention heads
TILE_M: ConstInt, # Tile size for Q dimension (for example, 64)
TILE_N: ConstInt, # Tile size for K/V dimension (for example, 64)
QUERY_GROUP_SIZE: ConstInt,# For Grouped Query Attention (GQA)
CAUSAL: ConstBool, # Whether to apply causal mask
EVEN_K: ConstBool, # Whether K length is divisible by TILE_N
):
2. 块 ID 映射
每个 CUDA 块计算一个输出图块。通过使用 ct.bid ,我们将二维网格映射到批量/头索引:
# Get block indices
bid_x = ct.bid(0) # Which tile along the sequence dimension
bid_y = ct.bid(1) # Which batch-head combination
# Decode batch and head from flattened index
batch_idx = bid_y // H
head_idx = bid_y % H
# For Grouped Query Attention: multiple Q heads share one K/V head
off_kv_h = head_idx // QUERY_GROUP_SIZE
3. 初始化累加器
在主循环开始前,我们先初始化在线 softmax 状态和输出累加器:
# Convert scale for base-2 exponential (faster than natural exp)
qk_scale = qk_scale * INV_LOG_2
# Create position indices for this tile
offs_m = bid_x * TILE_M + ct.arange(TILE_M, dtype=ct.int32)
offs_m += input_pos
offs_m = offs_m[:, None] # Shape: [TILE_M, 1]
offs_n_tile = ct.arange(TILE_N, dtype=ct.int32)
offs_n_tile = offs_n_tile[None, :] # Shape: [1, TILE_N]
# Online softmax state (float32 for numerical stability)
m_i = ct.full((TILE_M, 1), -math.inf, dtype=ct.float32) # Running max
l_i = ct.full((TILE_M, 1), 0.0, dtype=ct.float32) # Running sum
acc = ct.full((TILE_M, TILE_D), 0.0, dtype=ct.float32) # Output accumulator
我们将 float32 用于累加器,即使输入为 float16,也能在迭代的 softmax 计算过程中保持数值精度。
4. 加载查询图块
查询图块加载一次,并在所有键/值迭代中重复使用:
# Load Q tile: shape [1, 1, TILE_M, TILE_D] -> [TILE_M, TILE_D]
q = ct.load(
Q,
index=(batch_idx, head_idx, bid_x, 0),
shape=(1, 1, TILE_M, TILE_D)
).reshape((TILE_M, TILE_D))
当图块延伸至张量边缘时, ct.load 函数会自动处理边界条件。
5. K/ V 图块的主循环
这是 Flash Attention 的核心:我们将迭代 K/V 图块。
# Calculate loop bounds
m_end = input_pos + (bid_x + 1) * TILE_M
k_seqlen = K.shape[2]
if CAUSAL:
# For causal attention, stop early (future tokens are masked)
Tc = ct.cdiv(min(m_end, k_seqlen), TILE_N)
else:
Tc = ct.cdiv(k_seqlen, TILE_N)
for j in range(0, Tc):
# --- Step A: Load Key tile and compute QK^T ---
k = ct.load(
K,
index=(batch_idx, off_kv_h, 0, j),
shape=(1, 1, TILE_D, TILE_N),
order=(0, 1, 3, 2), # Transpose for correct layout
latency=2 # Hint for memory prefetching
).reshape((TILE_D, TILE_N))
# Matrix multiply: Q @ K^T
qk = ct.full((TILE_M, TILE_N), 0.0, dtype=ct.float32)
qk = ct.mma(q, k, qk) # Uses Tensor Cores automatically
参数中的 order=(0,1,3,2) 告知 cuTile 加载运算时使用 K 的转置,而 latency=2 表示我们可以容忍一定程度的延迟以实现更优的流水线化。随后,我们通过 ct.mma=(q, k, k,qk) 执行 cuTile 矩阵乘积累加运算。
6. 应用因果掩码
用于自回归模型(如 GPT、Llama 等),每个 token 只能处理其之前的 tokens:
# --- Step B: Apply causal masking ---
if CAUSAL or not EVEN_K:
offs_n = j * TILE_N + offs_n_tile
mask = ct.full((TILE_M, TILE_N), True, dtype=ct.bool_)
# Boundary mask (for non-divisible sequence lengths)
if not EVEN_K:
mask = mask & (offs_n < k_seqlen)
# Causal mask: query position >= key position
if CAUSAL:
mask = mask & (offs_m >= offs_n)
# Convert to additive mask: True->0, False->-inf
mask = ct.where(mask, 0.0, -math.inf)
qk += mask
将 -inf 添加至遮罩位置,可确保其在 softmax 运算后变为零。
7. 在线 Softmax 更新
现在,我们更新正在运行的 softmax 统计数据:
# --- Step C: Online softmax ---
# Find max in current tile
qk_max = ct.max(qk, axis=-1, keepdims=True)
qk_max_scaled = qk_max * qk_scale
# Update running maximum
m_ij = max(m_i, qk_max_scaled)
# Scale QK scores
qk = qk * qk_scale
qk = qk - m_ij
# Compute attention weights (using exp2 for speed)
p = ct.exp2(qk)
# Update running sum
l_ij = ct.sum(p, axis=-1, keepdims=True)
alpha = ct.exp2(m_i - m_ij) # Correction factor
l_i = l_i * alpha
l_i = l_i + l_ij
# Rescale previous accumulator
acc = acc * alpha
8. 累积输出
最后,加载“Value” (值) 图块并累加:
# --- Step D: Load V and accumulate ---
v = ct.load(
V,
index=(batch_idx, off_kv_h, j, 0),
shape=(1, 1, TILE_N, TILE_D),
latency=4
).reshape((TILE_N, TILE_D))
# Cast attention weights back to input dtype for Tensor Core MMA
p = p.astype(Q.dtype)
# Accumulate: acc += P @ V
acc = ct.mma(p, v, acc)
# Update max for next iteration
m_i = m_ij
9. 最终规范化和存储
处理完所有图块后,我们依据总和进行归一化处理,并将结果写入。
# --- Final: Normalize and store ---
acc = ct.truediv(acc, l_i)
acc = acc.reshape((1, 1, TILE_M, TILE_D)).astype(Out.dtype)
ct.store(Out, index=(batch_idx, head_idx, bid_x, 0), tile=acc)
启动核函数:主机侧代码
现在,我们来看一下启动核函数的主机端代码:
import torch
from math import ceil
def tile_fmha(q, k, v, sm_scale=None, is_causal=True):
"""
Launch the Flash Attention kernel.
Args:
q: Query tensor, shape [batch, heads, seq_len, head_dim]
k: Key tensor, shape [batch, kv_heads, seq_len, head_dim]
v: Value tensor, shape [batch, kv_heads, seq_len, head_dim]
sm_scale: Softmax scale (default: 1/sqrt(head_dim))
is_causal: Whether to apply causal masking
Returns:
Output tensor, same shape as q
"""
if sm_scale is None:
sm_scale = 1.0 / math.sqrt(q.size(-1))
batch_size, num_heads, seq_len, head_dim = q.shape
_, num_kv_heads, _, _ = k.shape
# Calculate query group size for GQA
query_group_size = num_heads // num_kv_heads
# Ensure contiguous memory layout
q = q.contiguous()
k = k.contiguous()
v = v.contiguous()
# Allocate output
o = torch.empty_like(q)
# Choose tile sizes (we'll optimize this later!)
TILE_M, TILE_N = 64, 64
# Calculate grid dimensions
grid_x = ceil(seq_len / TILE_M) # Number of tiles along sequence
grid_y = batch_size * num_heads # One block per batch-head pair
grid = (grid_x, grid_y, 1)
# Check if K length is evenly divisible
EVEN_K = (k.shape[2] % TILE_N) == 0
# Launch kernel
ct.launch(
torch.cuda.current_stream(),
grid,
fmha_kernel,
(q, k, v, o, sm_scale, 0, head_dim, num_heads,
TILE_M, TILE_N, query_group_size, is_causal, EVEN_K)
)
return o
使用 64 * 64 个图块时,此基准可以正常运行。但能否进一步提升速度?让我们来探究一下。
第 2 部分:“陷阱和救援”优化之旅
我们基于以下配置进行基准测试:
- 硬件:NVIDIA B200
- 批量:4,打印头:32,打印头尺寸:128
- 注意力机制:因果型,数据类型:FP16
- 序列长度:1024、2048、4096、8192、16384
为解释每个步骤,我们使用带有极小截面集的 Nsight Compute:
LaunchStatsOccupancySpeedOfLightComputeWorkloadAnalysisMemoryWorkloadAnalysis
基准性能
| SeqLen | 吞吐量 (TFLOPS) |
|---|---|
| 1024 | 330 |
| 2,048 | 441 |
| 4,096 | 511 |
| 8,192 | 546 |
| 16,384 | 566 |
这是我们的起点,由 64 * 64 个图块组成,尚未进行优化。
NCU 见解 ( SeqLen 1024、B200):
- 寄存器/线程:128
- 理论/实际占用率:25%/19.8%
- 计算 (SM) 吞吐量:37.8%
- 显存吞吐量:19.7%
- 网格大小:2048
1. 大牌的陷阱
GPU 编程的一种常见直觉是“图块越大,性能越高。”图块越大,计算密度越高,内存访问效率也往往随之提升。
- 摊销内存访问开销,
- 提升二级缓存利用率,
- 降低每个元素的内核启动开销。
我们将图块大小从 64* 64 调整为 256* 128:
TILE_M, TILE_N = 256, 128 # Was 64, 64
预期是更高的内存带宽利用率 → 更快的性能。然而,以 TFLOPS 计算的结果却是:
| SeqLen | Baseline (64*64) | 使用更大的图块 (256*128) | 性能下降 |
|---|---|---|---|
| 1024 | 330 | 187 | -43% |
| 2048 | 441 | 268 | -39% |
| 4096 | 511 | 347 | -32% |
| 8192 | 546 | 415 | -24% |
| 16384 | 566 | 463 | -18% |
所有序列长度的性能都会降低 18-43%。这是陷阱,使用大块图块会导致性能 下降。
为什么会出现这种情况?
- 计算瓶颈: 随着每个图块中的元素不断增多,低效运算(独立的复加运算、精确的数学运算)逐渐成为性能瓶颈。
- 指令用度: 每个图块承担的任务越多,执行下一次内存操作前所需的指令也越多。
课程: 图块大小与计算效率相互关联,只有在计算效率足够高时,采用较大的图块才能发挥作用。
NCU 见解 ( SeqLen™ 1024、NVIDIA B200):
- 寄存器/ 线程跳转至 168 (~ 31%) ,理论占用率降至 18.75%
- 实际占用率降至 16.5%
- 计算吞吐量降至 17.4% (存在陷阱)
- 显存吞吐量降至 7.4%
- 网格大小缩小至 512 (图块越大,对应图块尺寸越小)
2. 借助快速数学运算进行救援
其中一个瓶颈是特殊函数:exp2(指数运算)和 truediv(真除法)。默认情况下,这些运算采用 IEEE-754 精度,精度较高,但运算速度较慢。
对于深度学习,我们可以通过微小的精度损失来实现显著的加速:
之前 (精确运算) :
p = ct.exp2(qk)
alpha = ct.exp2(m_i - m_ij)
acc = ct.truediv(acc, l_i)
After (快速数学运算) :
p = ct.exp2(qk, flush_to_zero=True)
alpha = ct.exp2(m_i - m_ij, flush_to_zero=True)
acc = ct.truediv(acc, l_i, flush_to_zero=True, rounding_mode=RMd.APPROX)
这些标志的作用:
flush_to_zero=True: Denormal numbers (extremely small values near zero) become exactly zero. This avoids slow microcode paths on the GPU.rounding_mode=RMd.APPROX: Skips iterative refinement after initial hardware approximation.
借助快速数学运算,我们成功优化了大型图块,TFLOPS 结果如下:
| SeqLen | Larger tile (trap) | Fast math (rescue) | Improvement |
|---|---|---|---|
| 1024 | 187 | 322 | +72% |
| 2048 | 268 | 436 | +63% |
| 4096 | 347 | 524 | +51% |
| 8192 | 415 | 585 | +41% |
| 16384 | 463 | 620 | +34% |
现在我们已达到或超越小图块基准,序列更长时可获得 10-20% 的提升。
NCU 见解 ( SeqLen™ 1024、NVIDIA B200):
- 寄存器/线程:168 个(保持不变)
- 理论/实际占用率:18.75% / 16.6%(保持不变)
- 计算吞吐量回升至 24.0%
- 显存吞吐量提升至 12.9%
3. K 环拆分
为引起因果注意,我们采用了一个三角形掩码:每个查询仅能处理此前位置的键。在基准测试中,我们会在每次循环迭代时检查 if CAUSAL: mask…。
但想一想:对于位置为 1000 的查询图块,多数关键图块 (0-900) 根本不需要任何掩码。只有靠近对角线的图块需要遮罩。查询位置以外的图块被完全遮罩(我们可以完全跳过它们)。 无需任何掩码。只有靠近对角线的图块需要遮罩。查询位置以外的图块被 完全遮罩(我们可以完全跳过它们)。
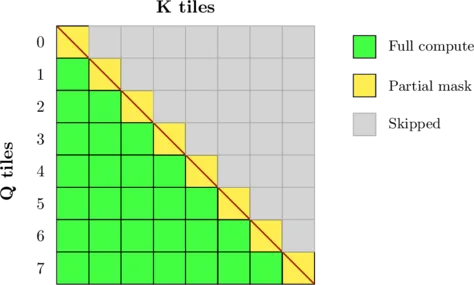
该优化将循环分为几个阶段:
# Calculate where masking starts being necessary
mask_start = (input_pos + bid_x * TILE_M) // TILE_N
mask_start = min(mask_start, k_seqlen // TILE_N)
# Calculate where to stop (for causal, we exit early)
if CAUSAL:
Tc = ct.cdiv(min(m_end, k_seqlen), TILE_N)
else:
Tc = ct.cdiv(k_seqlen, TILE_N)
for j in range(0, Tc):
# Load K and compute QK...
# ONLY apply masking when necessary
if (CAUSAL or not EVEN_K) and j >= mask_start:
offs_n = j * TILE_N + offs_n_tile
mask = ct.full((TILE_M, TILE_N), True, dtype=ct.bool_)
if not EVEN_K:
mask = mask & (offs_n < k_seqlen)
if CAUSAL:
mask = mask & (offs_m >= offs_n)
mask = ct.where(mask, 0.0, -math.inf)
qk += mask
# Continue with softmax and accumulation...
为何如此重要: 对于长度为 16K 的序列,若每个图块包含 256 个 token:
- ・50% 的图块完全取消掩码(无分支,无掩码计算)
- 每行有 1 个图块被部分掩码(完整逻辑)
- 其余图块则被完全跳过(提前退出)
结果为 TFLOPS:
| SeqLen | 快速数学运算 | 循环分割 | 优化 |
|---|---|---|---|
| 1024 | 322 | 373 | +16% |
| 2048 | 436 | 552 | +27% |
| 4096 | 524 | 684 | +31% |
| 8192 | 585 | 770 | +32% |
| 16384 | 620 | 813 | +31% |
这是单次优化中幅度最大的一次,所有序列长度的速度提升高达 32%。
NCU 见解 ( SeqLen 1024、B200):
- 寄存器/线程:168 个(保持不变)
- 理论/实际占用率:18.75% / 16.6%(保持不变)
- 显存吞吐量提升至 14.5%(减少了工作浪费)
- 计算吞吐量仍为 24.0%(任务效率提高,但每个周期的执行速度未必更快)
4. ProgramId 重映射
其中一个细微的优化是反转因果注意力的分块顺序。当从右下角向左上角反向处理图块时,由于因果掩码的作用,后启动的方块所需计算量较小,从而改善了负载均衡,减轻了尾部效应。
之前 (标准顺序):
bid_x = ct.bid(0) # Process tiles 0, 1, 2, ...
之后 (因果反向) :
if CAUSAL:
bid_x = NUM_M_BLOCKS - 1 - ct.bid(0) # Process tiles N, N-1, N-2, ...
else:
bid_x = ct.bid(0)
这一微小的调整优化了波形调度,使 GPU 上的线程块完成进度更加一致。
结果为 TFLOPS:
| SeqLen | Loop split | Remapping | Improvement |
|---|---|---|---|
| 1024 | 373 | 377 | 1 |
| 2048 | 552 | 560 | 1.5 |
| 4096 | 684 | 696 | 1.8 |
| 8192 | 770 | 781 | 1.5 |
| 16384 | 813 | 835 | 2.6 |
适度但一致的 1-3% 的增益,在尾部效果尤为明显的更长序列中表现突出。
5. 自动调整
我们优化了大图块,但存在一个问题:短序列仍然倾向于使用小图块。
为什么?当使用 1024-token 序列和 256-token 图块时,我们仅有 4 个图块,这不足以在 B200 上充分占用所有 SM。而较小的图块(64 × 64)可生成 16 个图块,从而更有效地利用 GPU 资源。
我们可以让 cuTile 的自动调整器 对多个配置进行基准测试,并为每个输入形状缓存较优配置,而不是手动选择值。
自动调整器方法:
def _fmha_autotune_configs():
"""Search space for autotuning.
The autotuner will benchmark these configurations and cache the best one
per input shape (sequence length, batch size, etc.).
"""
gpu_capability = torch.cuda.get_device_capability()
if gpu_capability in [(12, 0), (12, 1)]:
# RTX 50 series (sm120, sm121)
yield SimpleNamespace(TILE_M=64, TILE_N=64, num_ctas=1, occupancy=2)
else:
# B200/GB200 (sm100) - Try multiple tile sizes
# Autotuner will discover:
# - 64x64 is best for short sequences (1024-2048)
# - 128x128 may be best for medium sequences (4096)
# - 256x128 is best for long sequences (8192+)
yield SimpleNamespace(TILE_M=64, TILE_N=64, num_ctas=1, occupancy=2)
yield SimpleNamespace(TILE_M=128, TILE_N=128, num_ctas=1, occupancy=2)
yield SimpleNamespace(TILE_M=256, TILE_N=128, num_ctas=1, occupancy=1)
如何通过自动调整启动:
使用 ct_experimental.autotune_launch 而不是直接调用 ct.launch:
import cuda.tile_experimental as ct_experimental
def autotune_launch_fmha(
stream, q, k, v, o, sm_scale, input_pos,
hidden_size, num_heads, query_group_size, is_causal
):
batch_size, _, q_len, _ = q.shape
def _grid_fn(cfg):
return (math.ceil(q_len / cfg.TILE_M), batch_size * num_heads, 1)
def _args_fn(cfg):
num_m_blocks = math.ceil(q_len / cfg.TILE_M)
even_k = (k.shape[2] % cfg.TILE_N) == 0
return (
q, k, v, o, sm_scale, input_pos,
hidden_size, num_heads, cfg.TILE_M, cfg.TILE_N,
query_group_size, is_causal, even_k, num_m_blocks,
)
ct_experimental.autotune_launch(
stream,
grid_fn=_grid_fn,
kernel=fmha_kernel,
args_fn=_args_fn,
hints_fn=lambda cfg: {"num_ctas": cfg.num_ctas, "occupancy": cfg.occupancy},
search_space=_fmha_autotune_configs,
)
注意:autotuner API 可能会发生变化。
自动调整器以智能方式工作:
- 使用 seq_len = 1024 进行首次调用:对全部 3 个配置执行基准测试,缓存表现较优的配置之一
- 首次调用 seq_len = 2048:对全部 3 个配置执行基准测试,缓存表现较优的配置之一
- 后续调用:直接采用缓存配置(零开销)
缓存键包含张量形状,因此不同序列长度会自动匹配不同的优化配置。
结果为 TFLOPS:
| SeqLen | Baseline | Remapping | Autotune | Speedup 与基准 |
|---|---|---|---|---|
| 1024 | 330 | 377 | 548 | 1.66 x |
| 2048 | 441 | 560 | 708 | 1.61 x |
| 4096 | 511 | 696 | 817 | 1.60 x |
| 8192 | 546 | 781 | 887 | 1.62 x |
| 16384 | 566 | 835 | 918 | 1.62 x |
自动调优器会发现 64* 64 图块适合序列 2048,随后切换到更大的图块以处理更长的序列。相比固定的大型图块,这种方法可将短序列的性能提升 45%,同时在长序列情况下保持峰值性能。
自动调整器的选择 (在 B200 上):
- SeqLen 1024:64 × 64 图块(高并行度)
- SeqLen 2048:64 × 64 或 128 × 128 图块(兼顾性能与效率)
- SeqLen 4096 及以上:128 × 128 或 256 × 128 图块(显存效率优先)
现在,我们无需手动调整,便可在所有序列长度上实现优异性能。
摘要:优化堆栈
| 优化 | 关键见解 | 影响 |
|---|---|---|
| 基准 (64* 64) | 正确但未优化 | 基准 |
| 大型图块 (256* 128) | 捕获点:速度较慢的 18–43%! | -18% 到 -43% |
| + 快速数学运算 (FTZ,APPROX) | 提供显著改善:大型图块现可从陷阱 | +34% 到 +72% 从陷阱 |
| + K 循环拆分 | 单次优化幅度最大 | +16% 到 +32% |
| + 程序 ID 重新映射 | 实现更佳负载均衡 | +1% 到 +3% |
| + 自动调整 | 每序列最优图块配置 | +10% 到 +45% |
最终加速:在所有序列长度上提升至 1.60 x-1.66 倍。
开始使用
编写高性能内核时,通常难以找到单一的“魔术”设置。正如我们在“陷阱和救援”中所见:
- 优化是相互依赖的:在我们修复数学运算之前,大型图块的速度较慢。图块大小无法被孤立地评估。
- 数学至关重要:
flush_to_zero和APPROX等标志对于释放 Tensor Core 吞吐量具有关键作用。在深度学习中,精确的数学运算往往过于简单。 - 算法优势可叠加:K 循环拆分通过消除冗余计算,带来了显著的单次性能提升(最高达 32%)。
- 自动调整优于手动启发式策略:cuTile 的自动调整器能针对不同序列长度动态选择最优图块配置(短序列采用 64×64,长序列采用 256×128),相比固定配置可获得 10% 至 45% 的性能增益。
- 累积效应呈倍数增长:完整的优化组合在所有序列长度上实现了 1.60 倍至 1.66 倍的加速,远超单一优化所能达到的效果。
cuTile 使开发者能够在简洁、可读的 Python 代码中表达这些优化(平铺、快速数学控制、循环分割、自动调整),同时为 NVIDIA GPU 生成高度优化的 PTX。
您可以在 TileGym 资源库 中找到经过全面优化的内核。祝使用愉快。




