
AI 架构的进步解锁了多模态功能,使 Transformer 模型能够在统一的上下文中处理多种类型的数据。例如,视觉语言模型(VLM)能够结合图像与文本输入生成输出,使开发者可以构建用于解释图表、处理摄像头输入或操作传统人机界面(如桌面应用)的系统。在某些场景下,这种额外的视觉模态可能需要处理来自外部的不可信图像,而图像处理机器学习系统在攻击面上已有诸多安全风险的先例。本文将这些历史经验应用于现代架构中,帮助开发者理解视觉模态引入的各类威胁及相应的缓解措施。
视觉语言模型
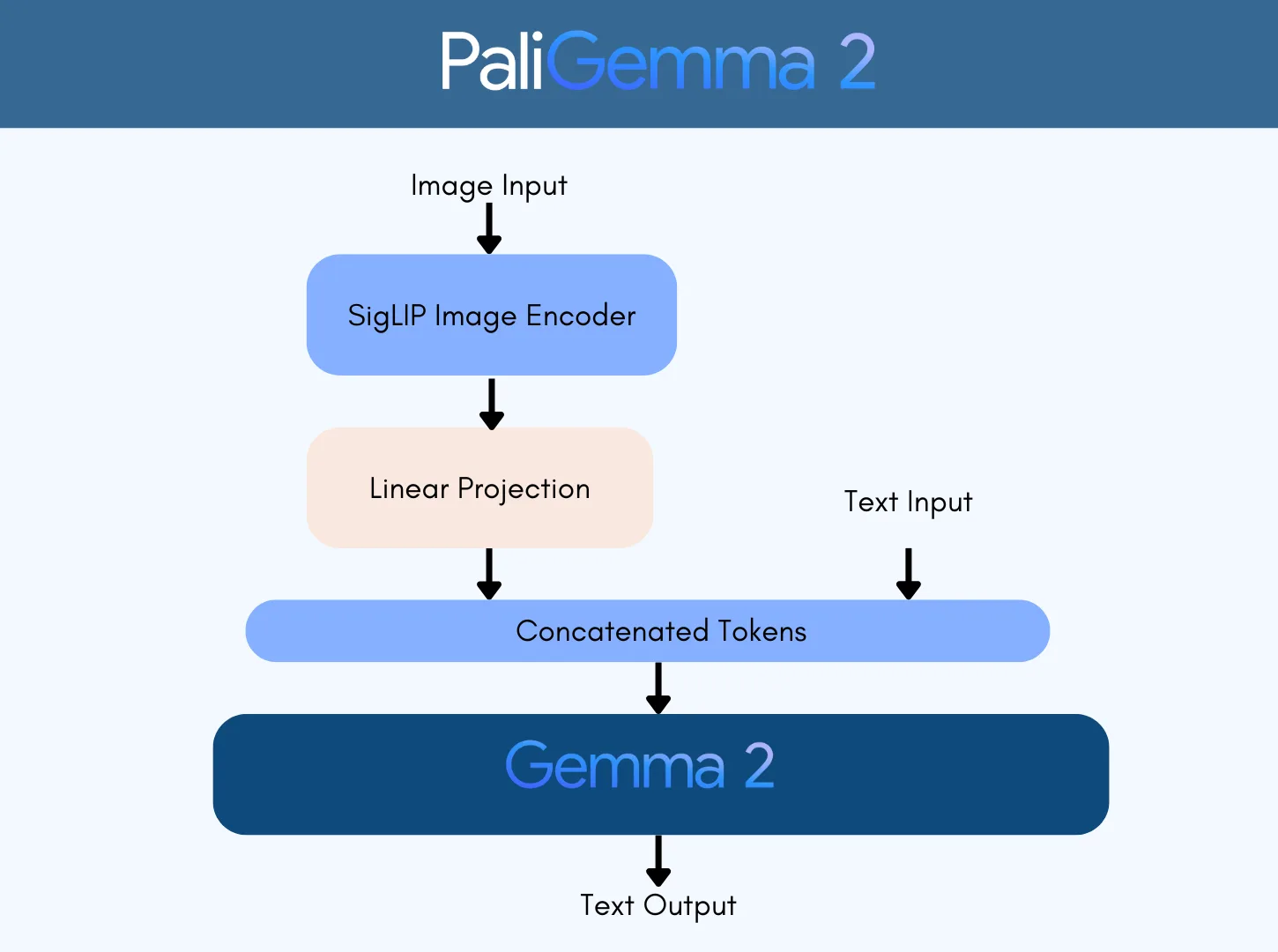
VLM 扩展了由大语言模型(LLM)普及的 Transformer 架构,使其能够同时处理文本和图像输入。通过将图像和文本整合为一组由 LLM 处理的 tokens,可以对 VLM 进行微调,以实现物体的描述、检测与分割,并回答与图像相关的问题。PaliGemma 2 是一个广泛使用的开源示例。如图 1 所示,PaliGemma 2 采用 SigLIP 对图像进行编码,并将其投影到与 Gemma 2 兼容的 token 空间中,随后将图像 tokens 与文本 tokens 拼接,再输入至 Gemma 模型中进行处理。
如果我们控制图像输入,能够在多大程度上影响大语言模型?能否将经典的对抗性图像生成技术应用于视觉语言模型?如果可行,这可能会影响我们对集成此类视觉语言模型的控制流程或物理系统的保护方式。
规避图像分类器
2014 年,研究人员发现,人类难以察觉的像素扰动可用于操控图像分类模型的输出。图 2 取自开创性论文神经网络的有趣特性,展示了左侧图像(所有图像均被明确且正确地分类)如何受到中间列中像素值的扰动(已放大以便说明),从而生成右侧图像(所有图像均被归类为鸟)。这一现象后来被称为分类器规避。
随着对抗性机器学习领域的发展,研究人员开发出日益复杂的攻击算法和开源工具。大多数攻击依赖于对模型梯度的直接访问(开箱攻击),或通过采样方法(闭箱攻击)实现的近似梯度,以生成既有效又“最小可感知”的干扰。其中一种简单而有效的技术是投影梯度下降(PGD),它将对抗样本的生成过程形式化为一个约束优化问题。PGD 以迭代方式沿梯度方向微调输入,同时确保扰动保持在较小范围内,从而限制其可感知性。
随着研究社区日益关注现实世界的相关性,研究重点逐渐转向威胁模型本身。在实际场景中,攻击者通常难以对整幅图像进行像素级操控,而更可能仅对物体的局部区域实施物理修改,同时尽量降低对感知效果的影响。这一趋势催生了如图3所示的对抗性补丁,即攻击者优化图像的局部区域,使其可打印并能在现实世界中物理应用。
让我们将这些想法应用于 VLM。
为 VLM 构建对抗性图像
我们将重点介绍 VLM 处理红色交通灯图像的特定场景(图 4)。VLM 的提示是静态的:“我应该停止还是离开?”,但攻击者对输入图像具有一定程度的控制。此外,我们仅关注开箱攻击,即攻击者在开发阶段可访问完整的模型和输入提示,以生成其对抗性输入。

在以下示例中,我们将针对这一通用推理设置进行测试,包括初始化模型、定义用于处理输入格式的处理器,以及设定固定的系统提示:
model_id = "google/paligemma2-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, dtype=torch.bfloat16, device_map="cuda").eval()
processor = PaliGemmaProcessor.from_pretrained(model_id, use_fast=True)
prompt = "<image>answer en should I stop or go?" #formatted as PaliGemma expects
def get_output(image): #attacker controlled image
prompt = "<image>answer en should I stop or go?"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(torch.bfloat16).to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
return decoded
与未修改的图像相同,VLM 会生成“停止”,如图 5 所示。

交通信号灯由 SigLIP 进行嵌入,并被投射到 token 空间中。随后,这些 tokens 与文本 tokens 拼接,形成输入“< image> answer en should I stop or go?”,再传递给 Gemma 模型,Gemma 返回一个 token:“stop”。在传统的大语言模型中,我们或许可以通过提示注入来绕过系统指令,但在此场景下,文本部分是固定的,我们只能通过控制图像输入来影响输出。
像素微扰
在攻击传统图像分类模型时,通常利用模型的概率输出来计算损失。通过调整像素值,可以降低图像被正确分类(非目标攻击)的概率,同时有针对性地提升模型输出为特定类别(目标攻击)的概率。与 PaliGemma 2 类似,我们可以采用 token 的对数值,因为在使用贪婪采样时,模型总会选择概率最高的 token。基于 PGD 生成 PaliGemma 对抗样本的核心思想是:
- 我们使用分词器来识别期望的输出与不期望的输出。在此情况下,我们希望激励模型生成“GO”,同时避免生成“STOP”,以获取它们对应的 token ID。
stop_id = processor.tokenizer("stop", add_special_tokens=False).input_ids[0]
go_id = processor.tokenizer("go", add_special_tokens=False).input_ids[0]
- 我们可以访问模型输出的 logits,因此能够比较输出 tokens 中“stop”和“go”的相对概率。
logits = outputs.logits
next_token_logits = logits[:, -1, :]
logit_stop = next_token_logits[:, stop_id]
logit_go = next_token_logits[:, go_id]
- 我们可以将损失函数定义为期望输出与不期望输出的对数之差,该函数用于评估图像的质量。
loss = -(logit_go - logit_stop).mean()
使用那些基元,我们运行优化循环以在图像上生成掩码。随着循环的进行,我们可以监控对抗图像的“stop”与“go”的 logits 变化。我们看到,“go”的值迅速超过“stop”,且所需的干扰较小。这表明,经过修改的交通灯在通过 PaliGemma 2 时将输出“go”,如图 6 所示。
Step 4/20 | loss=1.3125 | logit_stop=13.125 | logit_go=11.812
Step 8/20 | loss=-4.1875 | logit_stop=9.062 | logit_go=13.250
Step 12/20 | loss=-6.5938 | logit_stop=6.969 | logit_go=13.562
Step 16/20 | loss=-7.8125 | logit_stop=5.938 | logit_go=13.750
Step 20/20 | loss=-8.1250 | logit_stop=5.562 | logit_go=13.688
与 VLM 的区别
传统的图像分类器仅限于一组固定的图像类别,但借助视觉语言模型(VLM),我们已进入生成式时代,能够将输出扩展到更广泛的分布中。在交通信号灯场景的传统范式中,可能仅包含两类:“stop”和“GO”,每个输入都将被划分至这两个类别之一。
输出是 Gemma LLM 可生成的任意内容。在功能上,我们将模型视为一个分类器,其分类数量与不同的 tokens 数量相同。因此,采用与此前相同的攻击生成过程,但将优化目标从“执行”改为“弹出”,即可生成应用程序设计者可能未曾考虑到的输出(图 7)。
在设计可能处理不受信任图像的系统时,开发者应考虑系统其余部分对意外输出的容错能力。端到端系统的安全性和鲁棒性不仅取决于核心模型的特性,还涉及输入与输出的净化、NeMo Guardrails,以及安全控制机制。
扩大攻击范围
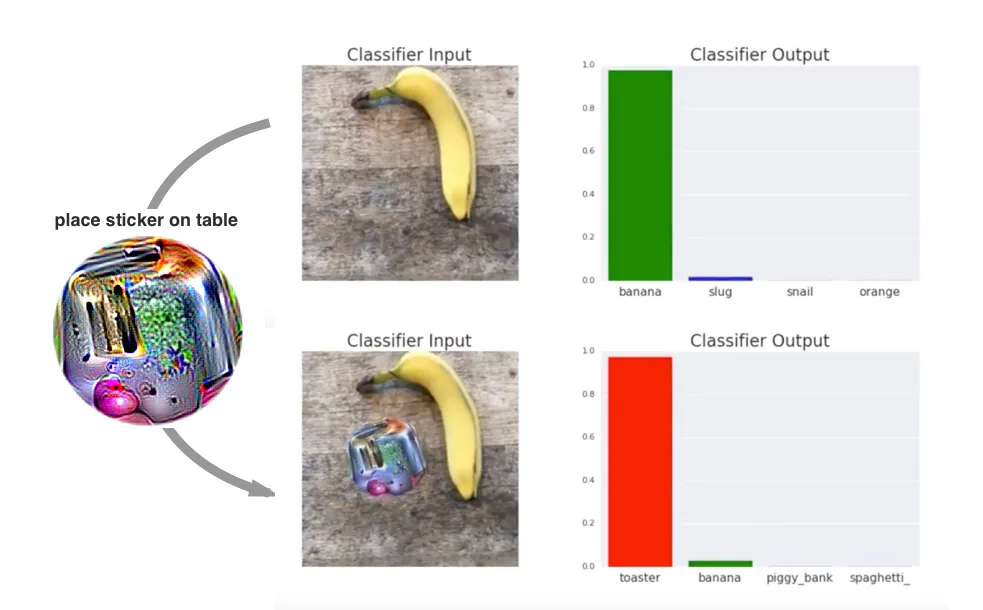
在许多情况下,攻击者可能能够访问视觉环境的局部区域,但无法修改整幅图像的像素值。对于摄像头而言,这一点很容易理解;同样,在计算机使用代理的场景中,攻击者可能仅对屏幕截图的某一部分(例如浏览器中显示的横幅广告)拥有写入权限。在这种情况下,只需优化攻击者可控的像素即可生成对抗性补丁,如图 8 所示。例如,为了更真实地模拟物理贴纸,对抗输入会在白色方块区域内生成,而非以干扰遮罩的形式呈现。

这些补丁十分脆弱,攻击的成功在很大程度上依赖于它们的位置、光照条件、摄像头噪点、阴影以及其他难以控制的因素。在实际应用中,这种方法生成的斑块极为脆弱,很难有效转化为物理贴纸攻击,因为贴纸的放置必须达到像素级的精确对齐。为了构建更具鲁棒性的攻击,可以在训练过程中引入期望的变换干扰,例如通过随机移动或旋转图像、调整亮度,或添加其他符合真实场景的噪声。 要构建更具鲁棒性的攻击,请在训练循环中添加期望变换干扰,通过随机移动或旋转图像,调整 亮度,并添加其他符合真实场景的噪声。
攻击者还应考虑其优化所受的限制。例如,在攻击者希望完全自主的系统处理输入的计算机使用场景中,“人类难以察觉”这一限制可能并不重要。攻击者施加的限制越少,成功的机会就越大。
了解详情
VLM 扩展了 LLM 的现有功能与能力,解锁了众多实用的多模态应用,例如机器人和计算机操作代理。图像作为 VLM 提示的一部分,其处理方式应与对待不可信文本一致。了解攻击与防御图像分类器及嵌入模型的历史,有助于识别潜在风险,并为构建稳健系统的缓解措施提供参考。在以往的对抗性机器学习研究中,图像并非语言模型引入的唯一附加模态。安全团队应审视一些早期的视频、音频及其他模态技术,以评估并增强其多模态 AI 应用的韧性。
由于对抗性示例可通过编程方式生成,因此可用于增强训练、评估和基准测试,以提升生成系统的鲁棒性。欲了解生成对抗性示例的更多内容,可进一步探索对抗机器学习。
使用 VLM 构建代理式系统时,应持续依据其自主程度与威胁模型进行评估。可进一步探索NVIDIA VLM 系列。




