
随着 AI 模型和数据集规模的不断扩大,仅依赖更高精度的 BF16 训练已难以满足需求。训练吞吐量预期、内存限制以及成本上升等关键挑战,正逐渐成为扩展 Transformer 模型的主要障碍。
使用低精度训练有助于应对这些挑战。通过降低计算过程中所使用的数值精度,GPU 能够在每个周期内处理更多运算,从而提升训练效率并降低计算成本。
本文直接比较了以下三种低精度训练格式与在数千亿 token 的预训练运行及下游基准测试中建立的 BF16 精度训练的效果:
我们提供了大规模的实用结果,展示了低精度训练如何通过当前即可投入生产的成熟方法,将吞吐量提升约 1.6 倍,显著节省内存,同时实现接近相同的模型质量。
什么是低精度训练?
在模型训练过程中,低精度训练采用位宽更少的数值格式来表示权重和激活值。这种方式降低了内存带宽与计算需求,使 GPU 每个周期能够处理更多运算,从而显著提升训练吞吐量。
低精度格式
FP8-CS 采用从当前训练步骤中每个张量的统计属性推导出的缩放系数,将 FP8 应用于线性层。 MXFP8 在 FP8 方法的基础上进行扩展,针对 NVIDIA Blackwell 架构 优化了块级缩放机制,每个块覆盖 32 个张量元素。 NVFP4 进一步提升了显存效率与吞吐量,通过使用 4 位格式表示张量数值,并结合分层的二级缩放策略。
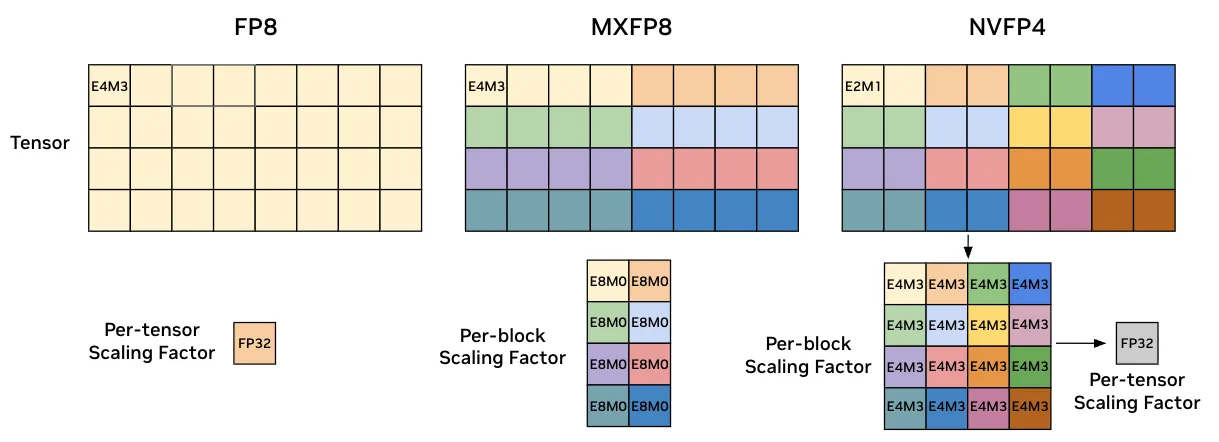
低精度训练能否大规模媲美 BF16 精度?
为了验证低精度训练对现实世界大型模型预训练的实际影响,该团队评估了两个广泛使用的密集 Transformer 架构在训练收敛性及下游任务性能方面的表现:Llama 3 8B 和 NVIDIA 内部研究 8B 模型(采用密集分组查询注意力(GQA)架构的 Research-8B,结构与 Llama 3 8B 相似)。这两个模型均在 1 万亿 tokens 的数据上完成了训练。
实验设置:消除精度带来的影响
开展了以下大规模预训练实验:
- 四种数值精度:BF16(基准)、FP8-CS、MXFP8 和 NVFP4
- 两种模型架构:Llama 3 8B 和 Research-8B
- 训练软硬件环境:基于 NVIDIA B200 GPU 的 NeMo Megatron Bridge
- 两个数据集:Lingua DCLM 数据集 和内部数据集。其中,Llama 3 8B 使用这两个数据集进行训练,Research-8B 则使用 NVIDIA 内部研究数据集进行训练
收行为:跨精度训练的稳定性
图 2、3 和 4 展示了模型在不同数据集上的训练与验证损失曲线。低精度训练的损失曲线与 BF16 基准高度接近,表明在不同精度下模型具有稳定且一致的收敛表现。在所有情况下,NVFP4 的损失略高,但下游任务的精度未受影响。具体数据详见表 1.
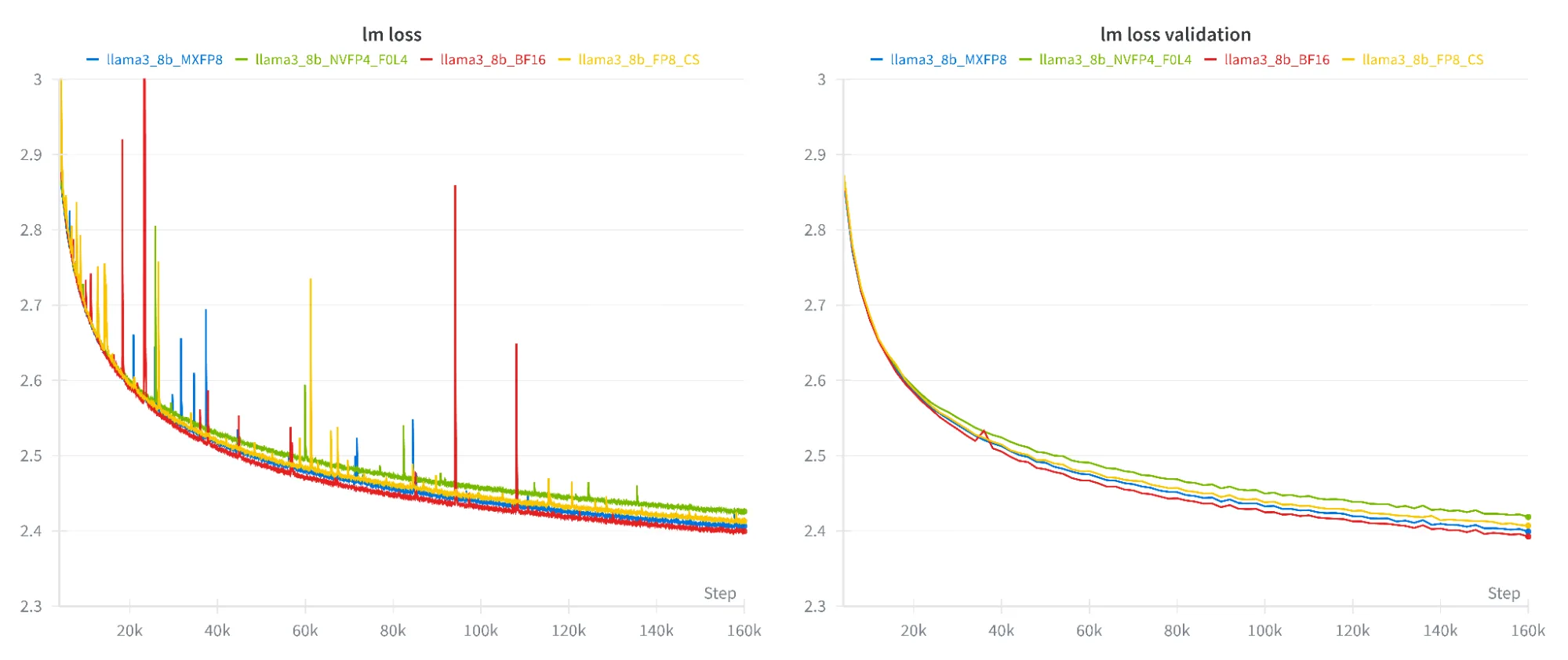
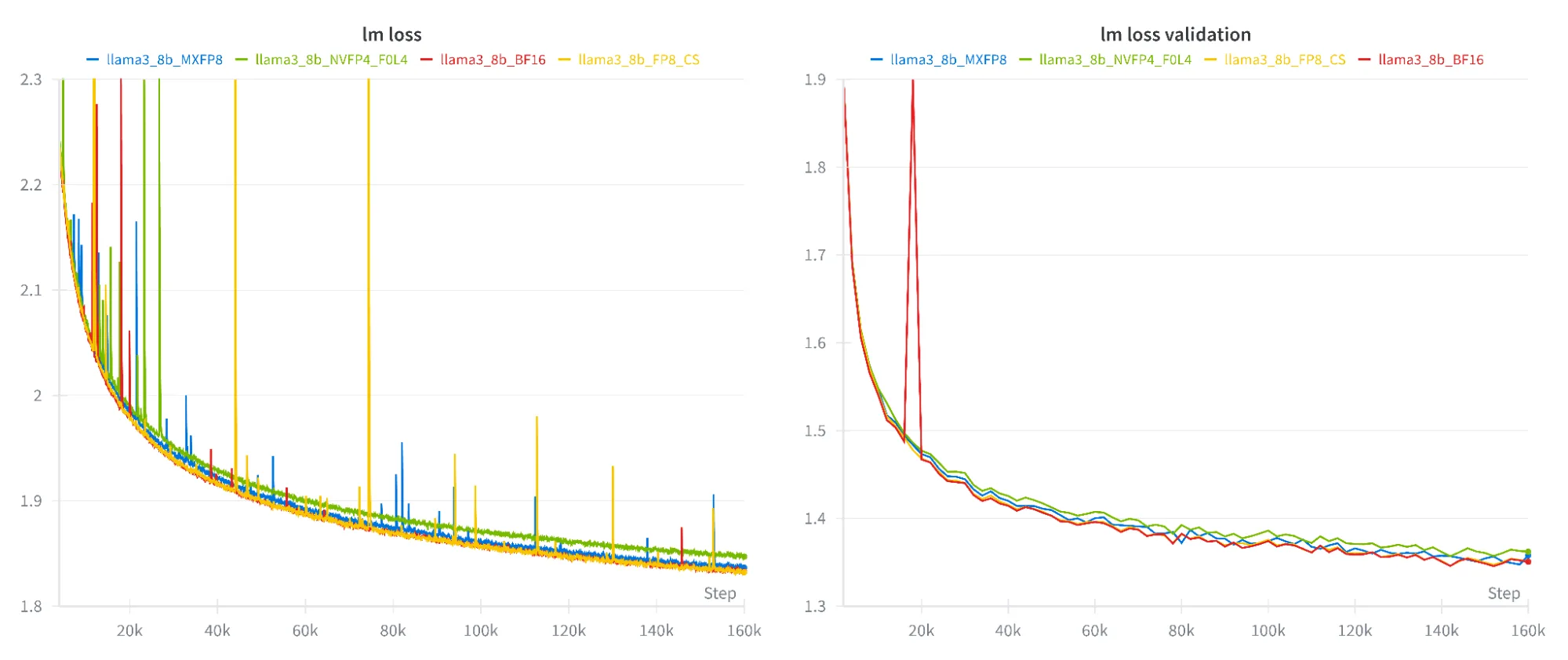
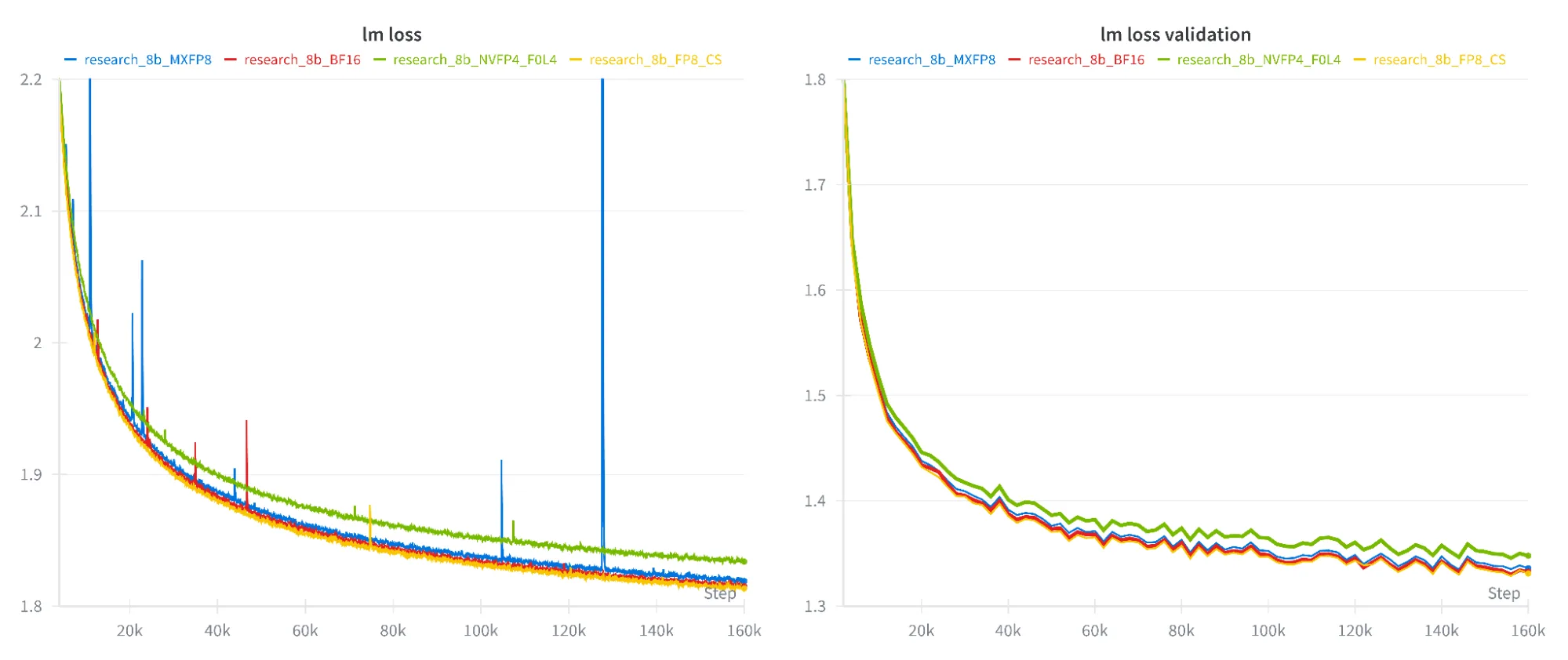
下游评估:保持准确性
为了评估低精度训练是否会影响实际性能,我们基于标准下游基准对所有预训练模型进行了评估。所有评估均以 BF16 精度执行,以隔离训练精度带来的影响。
结果如表 1 所示。尽管训练和验证损失之间存在细微差别,但所有低精度格式均可实现与 BF16 相当的下游任务精度。
| Model | Dataset | Precision | MMLU (↑) | HellaSwag (↑) | WinoGrande (↑) | ARC-C (↑) |
| Llama 3 8B | DCLM | BF16 | 45.98 | 76.44 | 70.17 | 51.28 |
| FP8-CS | 46 | 75.25 | 70.24 | 49.91 | ||
| MXFP8 | 46.56 | 75.46 | 71.27 | 51.11 | ||
| NVFP4 | 45.64 | 75.59 | 69.38 | 51.28 | ||
| Llama 3 8B | 内部数据集 | BF16 | 52.73 | 75.71 | 67.88 | 51.37 |
| FP8-CS | 52.46 | 75.65 | 70.17 | 54.52 | ||
| MXFP8 | 53.7 | 75.54 | 69.69 | 51.62 | ||
| NVFP4 | 52.83 | 75.04 | 71.98 | 53.58 | ||
| Research-8B | 内部数据集 | BF16 | 53 | 76.98 | 70.4 | 55.89 |
| FP8-CS | 52.62 | 75.81 | 70.8 | 54.44 | ||
| MXFP8 | 52.38 | 76.55 | 69.77 | 53.58 | ||
| NVFP4 | 52.21 | 76.19 | 70.32 | 54.95 |
关键见解
下文详细阐述了从这些实验中获得的关键见解。
- 低精度训练与 BF16 收敛表现匹配:FP8、MXFP8、NVFP4 在预训练和验证损失上均与 BF16 非常接近,仅表现出轻微的性能下降。
- 保持下游任务准确性:在各类模型和基准测试中,低精度训练所获得的下游任务表现可与 BF16 相媲美,表明降低精度的同时仍能有效维持模型性能。
- MXFP8 表现略优于标准 FP8:这可能得益于其细粒度缩放机制,能够更有效地捕捉张量内部的局部动态范围。
- 经过适当校准的 NVFP4 即使在高度压缩的情况下仍能取得有竞争力的结果:经验表明,以下配置为较优选择:AdamW = 1e-8、LR = 6e-4 至 6e-6、GBS = 768。
- 选择性使用 BF16 层对 NVFP4 至关重要:消融实验显示,完全采用 NVFP4 的模型存在训练不稳定性。为保障训练稳定,需在 BF16 中保留部分网络层,尤其在网络后段,以缓解 NVFP4 量化带来的误差累积。在本组实验中,将最后四个 Transformer 层保留在 BF16 精度已足以实现稳定训练。
FP8、MXFP8 和 NVFP4 训练的优势
低精度格式可显著提升训练吞吐量与内存效率,从而在 NVIDIA Blackwell GPU 上实现更快速的端到端训练及更优的可扩展性。
| 精度 | 微批量大小 | 吞吐量 (TFLOP/s/GPU) | 与 BF16 的对比 |
| BF16 | 2 | 1165 | – |
| FP8-CS (F1L1) | 2 | 1547 | 1.33x |
| MXFP8 | 2 | 1540 | 1.32x |
| NVFP4 (F0L4) | 4 | 1850 | 1.59x |
GBS = 128,Seq。长度 = 8192。请注意,FxLy 表示前`x`层,后`y`个 transformer 块层保持在 BF16 精度中。
更快的端到端训练
使用 8 位或 4 位数字格式可使 GPU 在每个时钟周期内处理更多运算,显著降低计算开销。与 BF16 基准相比,吞吐量最高提升达 1.59 倍(表 2)。这些优势直接转化为大规模模型训练速度的明显加快。
节省 GPU 显存并提高可扩展性
使用较低的位宽格式可减少权重和激活值的内存占用,从而在同一硬件上支持更大的模型或批量大小。NVFP4 效率使预训练期间的微批量大小翻倍(从 2 增加到 4),直接提升了吞吐量与可扩展性。
表 3 提供了跨训练组件的内存使用情况明细。采用较低精度格式可显著减少参数和激活值的存储需求,同时保留 FP32 优化器状态,从而在不损害训练稳定性的情况下提升吞吐量并支持更大的批量大小。
| 优化器 | ||||||
| 精度 | 参数 | 梯度 | 动量 | 方差 | 主参数 | 其他 |
| FP16 | FP16 | FP32 | FP32 | FP32 | FP32 | |
| BF16 | BF16 | BF16 | ||||
| FP8(张量缩放) | FP8x2 | BF16 | 每个权重张量的缩放系数 | |||
| MXFP8 | FP8x2 | BF16 | (每 32 个元件的缩放系数) × 2 | |||
| NVFP4 | FP4 | BF16 | 16×16 2D 块缩放复制每个 1×16 块 | |||
使用 NeMo Megatron Bridge 进行低精度训练
NeMo Megatron Bridge是 NVIDIA NeMo 框架内的开放式 PyTorch 原生库。它可实现 Hugging Face 与 Megatron Core 模型检查点之间的双向转换,支持高效的训练及多节点并行机制,适用于生成式 AI 模型的预训练、SFT 和 LoRA 调优,确保高吞吐量的性能表现。
使用 NeMo Megatron 桥接器库进行低精度训练非常简便。您可以通过更改单个配置标志,灵活尝试不同的精度格式,并为多种模型应用现成的低精度方法。以 Llama 3 8B 为例,操作如下所示:
from megatron.bridge.recipes.llama import llama3_8b_low_precision_pretrain_config as low_precision_pretrain_config
from megatron.bridge.training.gpt_step import forward_step
precision = "bf16_with_fp8_current_scaling_mixed" # should be one of ["bf16_with_mxfp8_mixed", "bf16_with_fp8_current_scaling_mixed", "bf16_with_nvfp4_mixed"]
cfg = low_precision_pretrain_config(
mixed_precision_recipe = precision,
train_iters = 100,
lr_warmup_iters = 10,
lr_decay_iters = 90,
mock = True, # use mock dataset
)
pretrain(config=cfg, forward_step_func=forward_step)
您可以轻松切换精度格式,以评估性能、节省内存并观察收敛行为,而无需修改模型代码或优化器逻辑。
加快训练速度并高效扩展
与广泛采用的 BF16 相比,具备当前缩放功能的 FP8、MXFP8 和 NVFP4 等低精度训练格式,为实现更快、更高效的深度学习训练提供了令人振奋的新路径。这些格式在速度和内存占用方面的优势,有助于推动更大、更复杂模型的训练。来自 Llama 3 8B 及内部研究模型的实证结果表明,低精度训练在预训练指标和下游任务中的表现可与 BF16 相媲美。
开始低精度训练
随着模型规模的持续扩展,低精度训练将成为构建新一代模型的基础。借助原生 生产就绪的低精度配方 在 NeMo Megatron Bridge 中,您现在即可率先体验这些先进技术。
要快速入门,建议试用 Megatron Bridge 训练教程 notebook。该教程详细介绍了这些低精度 recipe 的端到端使用方法,并展示了其如何显著加速训练工作负载。




