cuBLAS
NVIDIA GPU 上的基本线性代数
NVIDIA cuBLAS 是一个基于 GPU 加速的库,用于加速人工智能和高性能计算应用。它包含若干 API 扩展,提供业界标准的 BLAS API 和 GEMM API,支持高度优化的融合操作,专为 NVIDIA GPU 设计。cuBLAS 库还包括针对批量操作、多 GPU 运行以及混合和低精度执行的扩展,并进行了额外调优以实现最佳性能。
cuBLAS 库包含在 NVIDIA HPC SDK 以及 CUDA 工具包中。
了解最新版本的新特性。
cuBLAS API 扩展程序
cuBLAS 主机 API
用于 CUDA 加速的 cuBLAS 主机 APIBLAS为1 级(向量 - 向量) ,2 级(矩阵向量) 和3 级(矩阵 - 矩阵) 运算。cuBLAS 还包括自定义 GEMM 扩展 API,这些 API 易于用于嵌入式硬件加速。
cuBLAS API 可在 cuBLAS 库中使用。
cuBLASLt 主机 API
cuBLASLt 主机 API多阶段 GEMM API这些模型极具表现力,允许应用利用最新的 NVIDIA 架构功能实现最佳性能融合和性能调优选项。
cuBLAS 库中提供了 cuBLASLt API。
cuBLASXt 单进程多 GPU 主机 API
cuBLASXt 主机 API 提供支持多 GPU 的接口,可在一个或多个 GPU 之间高效调度 3 级工作负载单节点。
cuBLAS 库中提供了 cuBLASXt API。
cuBLASMp 多节点多 GPU 主机 API (预览版)
cuBLASMp (预览版) 是一个高性能,多进程,GPU 加速库分布式基本密集线性代数。cuBLASMp 可供独立下载 HPC SDK。
下载 cuBLASMp
cuBLASDx 设备 API (预览版)
cuBLASDx (预览版) 是设备端cuBLAS 的 API 扩展,用于在 CUDA 内核中执行 BLAS 计算。融合数值运算可降低延迟并提高应用程序的性能。
下载 cuBLASDx
cuBLAS 的主要特性
- 全面支持所有 152 个标准 BLAS 例程
- 支持半精度和整数矩阵乘法
- 针对 Tensor Core 优化融合的 GEMM 和 GEMM 扩展程序
- 针对各种深度学习模型中使用的大小调整 GEMM 性能
- 支持用于并发操作的 CUDA 流
cuBLAS 性能
cuBLAS 库针对 NVIDIA GPU 上的性能进行了高度优化,并利用 Tensor Core 加速低精度和混合精度矩阵乘法。



cuBLAS 矩阵针对各种精度在数据中心 GPU 上实现性能倍增
cuBLASMp 主要特性
- 多节点多 GPU 基本线性代数功能
- 2D 块循环数据布局
- 通过 nv Fortran 提供 Fortran 包装器
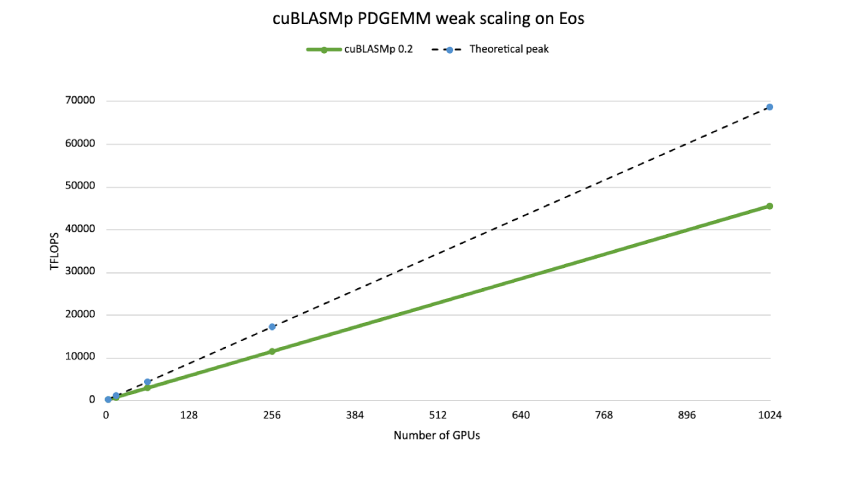
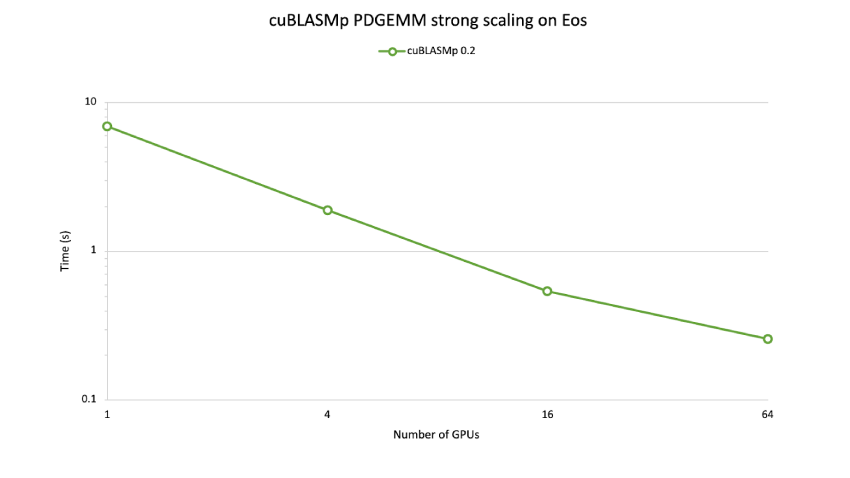
cuBLASMp 性能
cuBLASMp 利用 Tensor Core 加速,同时在 GPU 之间高效通信并同步其进程。
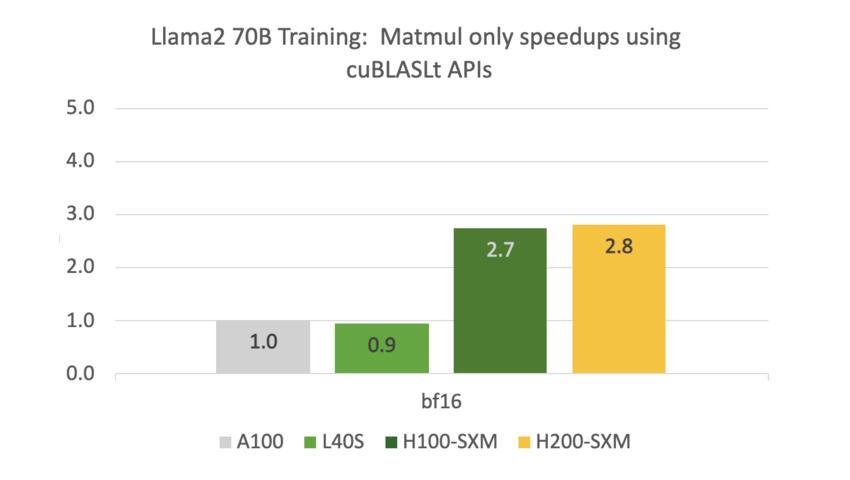
cuBLASLt 性能
cuBLASMp 分布式双精度 GEMM 的弱扩展。M,N,K = 55k 每 GPU