NVIDIA cuDF:GPU 加速的结构化数据处理
NVIDIA cuDF 是适用于结构化数据的开源 NVIDIA CUDA-X™ 数据处理工具包,可大幅提升数据引擎和库的速度并节省成本。cuDF 基于高度优化的 NVIDIA® CUDA® 基元构建,可利用 GPU 并行性和内存带宽来加速数据处理和分析工作流。
cuDF 的工作原理
cuDF 为 GPU 加速查询引擎提供组件,包括 I/ O 和 SQL 操作,例如连接、聚合、排序和 shuffle。cuDF 库基于 Apache Arrow 的列式内存格式构建,可同时在数千个 GPU 核心之间分发高度并行的内核。内存管理工具可优化 CPU 和 GPU 之间昂贵的内存传输。
了解目前哪些数据引擎使用 cuDF。
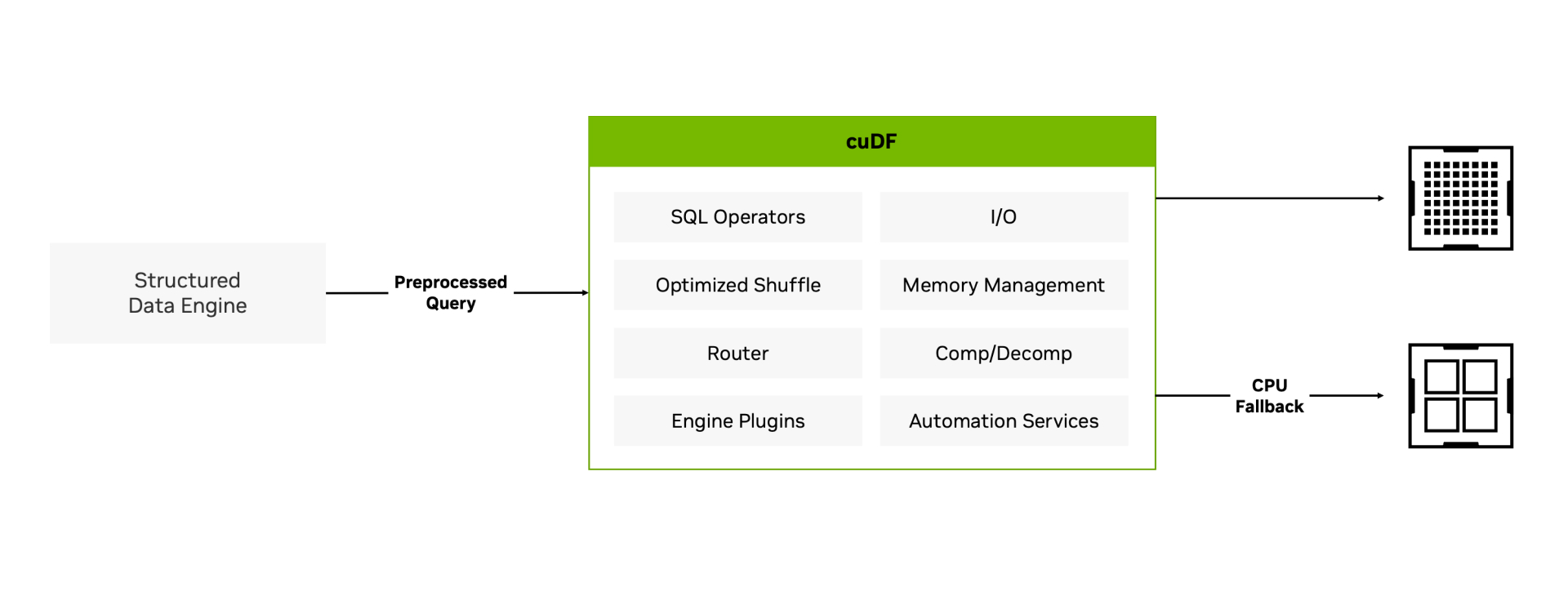
使用 cuDF 的用户体验
当使用 cuDF 加速数据引擎时,用户可以通过数据引擎体验 GPU 执行,而数据引擎可以帮助将不支持 GPU 的操作路由到 CPU,以确保用户的工作流程不会中断。
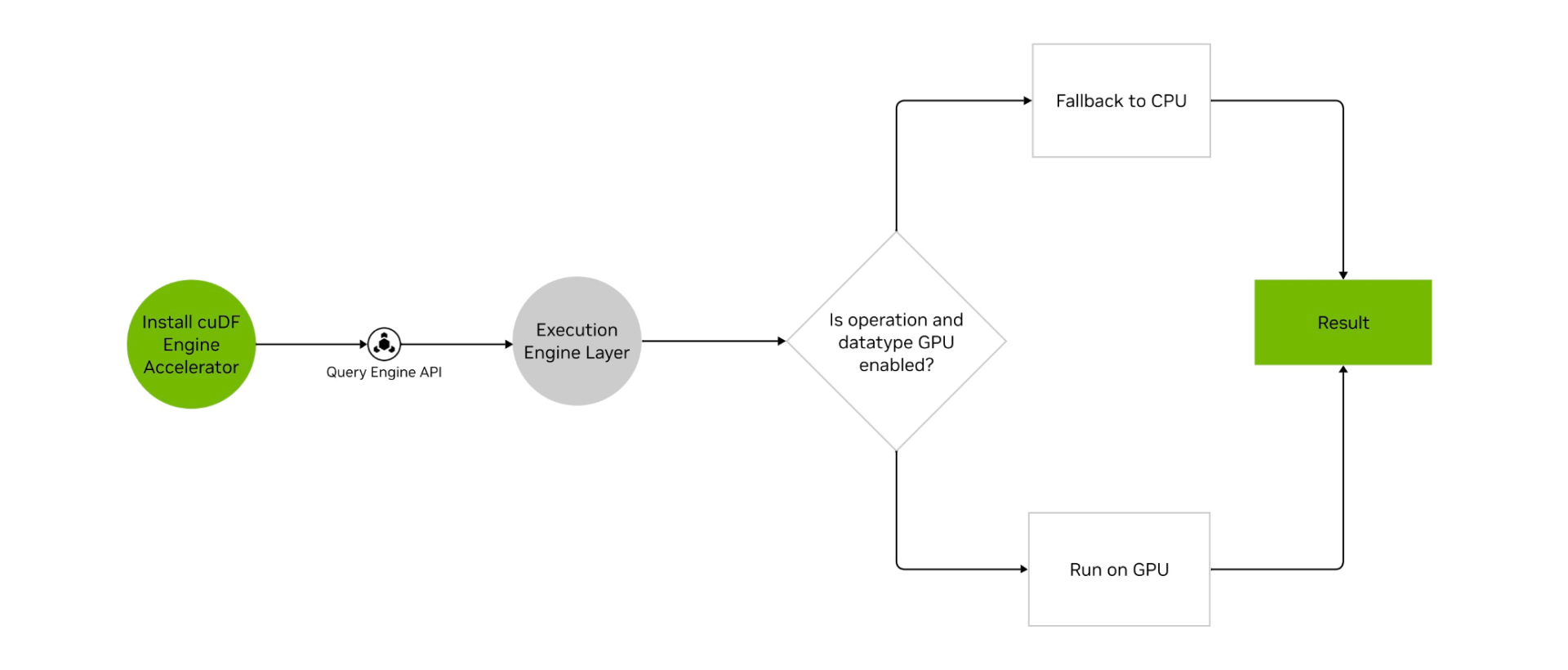
关键特性
借助 NVIDIA GPU 更大限度地提高性能
cuDF 使用低级 CUDA 基元优化核心 SQL 和 DataFrame 操作,充分利用 NVIDIA GPU 的并行性和内存带宽,从而更大限度地提高 GB 到 PB 级工作负载的性能。
专为延迟敏感型工作负载打造
cuDF 可更快地生成结果,从而解锁交互式分析和代理式 AI 查询等延迟敏感型工作负载,从而实现新一代数据分析。
降低基础设施成本
通过缩短数据操作的运行时间,工作负载可以在更少的节点上处理相同的数据量,从而降低基础设施成本并减少数据中心占用空间。
更大限度地减少数据移动
cuDF 基于 Apache Arrow 格式构建,利用高效的列式数据结构和零复制接口与其他加速库,最大限度地减少了数据移动开销。
核外可扩展性
借助 NVIDIA 的内存工具和基元,cuDF 可帮助加速引擎处理数据集和内存密集型操作,例如超出 GPU 显存的连接和分组。
在您的环境中安装和部署
要了解 cuDF 的附带功能,请使用您首选的安装方法下载软件包。
该软件包包括 Python 和 C++ 接口,以及零代码更改加速器。
将 cuDF 直接集成到您的环境中。请按照以下步骤开始操作。
安装 cuDF
使用 conda 快速安装
1. 如果未安装,请下载并运行安装脚本。这将安装最新的 miniforge:
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh" bash Miniforge3-$(uname)-$(uname -m).sh
2. 然后使用以下命令进行安装:
conda create -n rapids-26.04 -c rapidsai -c conda-forge \
cudf=26.04 python=3.14 'cuda-version>=13.0,<=13.1'使用 pip 快速安装
pip install \
"cudf-cu13==26.4.*"请参阅 Docker、WSL2 和各个库的完整安装选择器。
安装选择器
试用加速数据引擎和工具
工具 |
生态系统插件 |
开始使用 |
|---|---|---|
Velox |
基于 GPU 的 Velox (实验性) |
|
Apache Spark |
适用于 Apache Spark 的 cuDF 插件 嵌入式扩展程序: spark.conf.set('spark.rapids.sql.enabled','true') |
|
Presto |
Presto-GPU |
|
Polars |
Polars GPU 引擎 嵌入式扩展程序: .collect(engine="gpu") |
|
DuckDB |
SiriusDB 嵌入式扩展程序: LOAD 'sirius.duckdb_extension'; |
|
Pandas |
Cudf.pandas 嵌入式扩展程序: %load_ext cudf.pandas import pandas as pd ... |
入门套件
入门套件:使用 cuDF 构建数据引擎
了解 cuDF 在大规模数据处理工作负载中的应用。
GTC 点播会议:GPU 数据处理的时代:从 SQL 到搜索再返回
GTC 点播会议:打破记忆墙:用于大规模分析的可组合基础模组
GitHub:GPU 查询执行 Blueprint
入门套件:在 GPU 上使用 Velox 构建数据引擎的速度最高可提升 6 倍
了解 C++ 执行引擎 Velox 如何在 GPU 上加速数据引擎执行 TB 级工作负载。
GitHub:GPU 后端的 Velox (实验性)
入门套件:运行 Apache Spark 工作负载的速度提高 5 倍,成本降低 10 倍
了解 GPU 如何加速企业级 Apache Spark 工作流,从而推动成本节约。
GTC 点播研讨会:自动执行并简化从 CPU 到 GPU 的 Apache Spark 工作负载迁移
GTC 点播会议:借助适用于 Apache Spark 的 NVIDIA RAPIDS™ 加速器,在 GPU 上加速大数据分析( 01:27:34)
入门套件:在 GPU 上运行 Presto 的速度最高可提升至原来的 6 倍,同时可节省 5 倍的成本
该套件介绍了交互式分析引擎 Presto 如何在 cuDF 上利用 Velox 执行来加速分析执行。
GTC 点播会议:在大型湖屋上实现快速、经济高效的交互式分析
GitHub:Velox 测试中的 Presto 基准测试
入门套件:运行 Polars GPU 引擎,获得高达 10 倍的速度提升
此套件演示了 Polars GPU 引擎如何在两秒内处理 1 亿行数据。
视频:使用 Polars GPU 引擎在 2 秒内处理 1 亿行数据( 00:28)
Notebook:Polars GPU 引擎简介
入门套件:使用 SiriusDB 将 DuckDB 的速度提升高达 8 倍
了解 ClickBench 上排名第一的 SiriusDB 如何经济高效地加速 DuckDB 工作负载。
GTC 点播会议:利用 GPU 加速的 DuckDB 将分析成本降低 8 倍
GitHub:SiriusDB
学术论文:重新思考 GPU 时代的分析处理
加入社区
符合伦理的 AI
NVIDIA 认为值得信赖的 AI 是一项共同的责任,我们制定了相关政策和实践来支持各种 AI 应用的开发。根据我们的服务条款下载或使用时,开发者应与其支持团队合作,确保其应用符合相关行业和用例的要求,并解决不可预见的产品滥用问题。
请单击此处报告安全漏洞或 NVIDIA AI 问题。