面向开发者的 NVIDIA NIM
NVIDIA NIM™ 提供容器,支持在云、数据中心以及 RTX™ AI PC 和工作站上自托管 GPU 加速的推理微服务,适用于预训练和自定义的 AI 模型。NIM 微服务公开行业标准 API,便于简单集成到 AI 应用、开发框架和工作流中,并针对每种基础模型与 GPU 的组合优化响应延迟和吞吐量
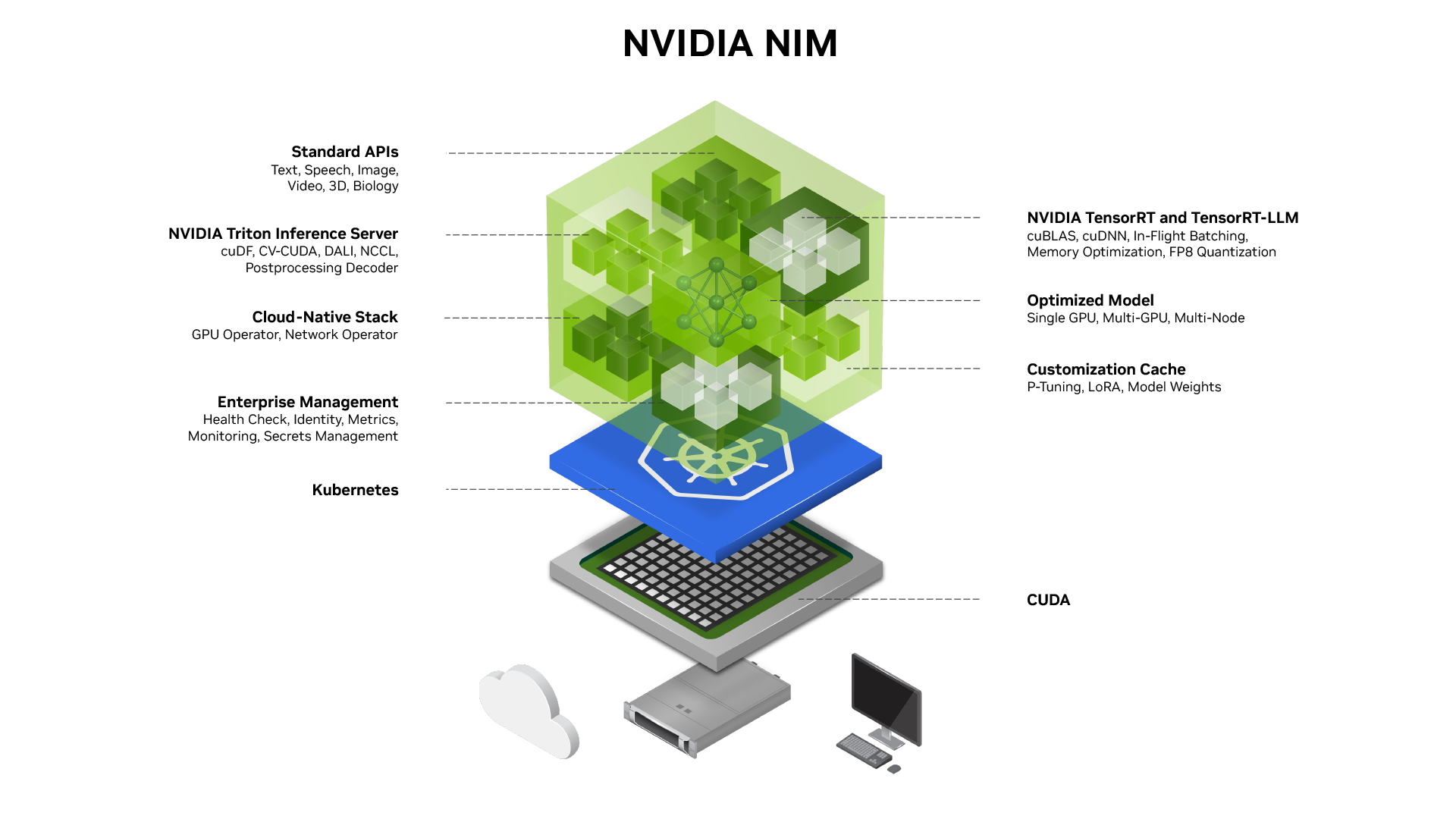
工作原理
NVIDIA NIM 有助于克服构建 AI 应用程序的挑战,为开发者提供行业标准 API,用于构建功能强大的 Copilot、聊天机器人和 AI 助手,同时使 IT 和 DevOps 团队能够轻松地在自己的托管环境中自行托管 AI 模型。NIM 基于可靠的基础构建,包括 TensorRT、TensorRT-LLM、PyTorch、vLLM, SGLang 等推理引擎,旨在促进大规模无缝 AI 推理。
博客
了解 NIM 的架构、主要特性和组件。
文档
访问在基础设施上运行 NIM 的指南、参考信息和版本说明。
网络会议
获取在任何 NVIDIA 加速基础设施上自行托管 NIM 的分步说明。
部署指南
获取在任何 NVIDIA 加速基础架构上自行托管 NIM 的分步说明。
使用 NVIDIA NIM 构建
获得出色的模型性能
借助 NVIDIA 和社区的加速引擎 (包括 TensorRT、TensorRT-LLM、vLLM、SGLang 等) 提高 AI 应用程序的性能和效率,这些引擎针对特定 NVIDIA GPU 系统上的低延迟、高吞吐量推理进行了预构建和优化。
随时随地运行 AI 模型
借助可部署在任何位置 (工作站、数据中心或云) 的 NVIDIA GPU 上的预构建微服务,保持应用程序和数据的安全性和控制力。下载用于自托管部署的 NIM 推理微服务,或利用 Hugging Face 上的专用端点在您首选的云中启动实例。
在数千种 AI 模型与定制方案中自由选择
部署 vLLM、SGLang 或 TensorRT-LLM 支持的各种 LLM,包括社区微调模型和基于数据微调的模型。
更大限度地提高可操作性和规模
获取用于控制面板的详细可观察性指标,并访问 Helm 图表和在 Kubernetes 上扩展 NIM 的指南。
NVIDIA NIM 示例
构建加速的生成式 AI 应用,包括 RAG、代理式 AI 等
开始使用 NVIDIA 托管的 NIM API 端点和 GitHub 中的生成式 AI 示例构建由 NIM 提供支持的 AI 应用。了解如何轻松部署检索增强生成 (RAG) 工作流、代理式 AI 工作流等。
借助蓝图加速开发起步
NVIDIA AI Blueprint 是一种可定制的预定义 AI 工作流,用于创建和部署 AI 智能体和其他生成式 AI 应用。使用蓝图以及 NVIDIA AI 和 Omniverse™ 库、SDK 和微服务,构建和运行自定义 AI 应用,创建数据驱动的 AI 飞轮。探索与领先的代理式 AI 平台提供商 (包括 CrewAI、LangChain 等) 共同开发的蓝图。
开始使用 NVIDIA NIM
我们为您提供不同的选项,借助 NVIDIA NIM 使用最新的 AI 模型构建和部署优化的 AI 应用。
尝试
使用 NVIDIA 托管的 NIM API 开始构建您的 AI 应用。
NVIDIA NIM 学习资源库
更多资源
伦理 AI
NVIDIA 的平台和应用程序框架使开发者能够构建各种 AI 应用程序。在选择或创建部署的模型时,请考虑算法偏差的潜在影响。与模型的开发者合作,确保模型符合相关行业和用例的要求;提供必要的指令和文档,以便了解错误率、置信区间和结果;并确保模型按照预期的条件和方式使用。
了解最新的 NVIDIA NIM 模型、应用程序和工具。