CUDA-X Data Science
CUDA-X™ Data Science 是一套开源库集合,可加速流行的数据科学库与平台。它属于 CUDA-X 系列高度优化、基于 CUDA® 的特定领域库。
CUDA-X Data Science 提供无需更改代码的 API,可直接加速 pandas、scikit-learn 等流行 PyData 工具,以及 Apache Spark 等分布式计算框架。通过超过 100 种与数据科学和数据处理生态系统中开源库和工具的集成,CUDA-X Data Science 致力于让更多人轻松体验加速数据科学的能力。
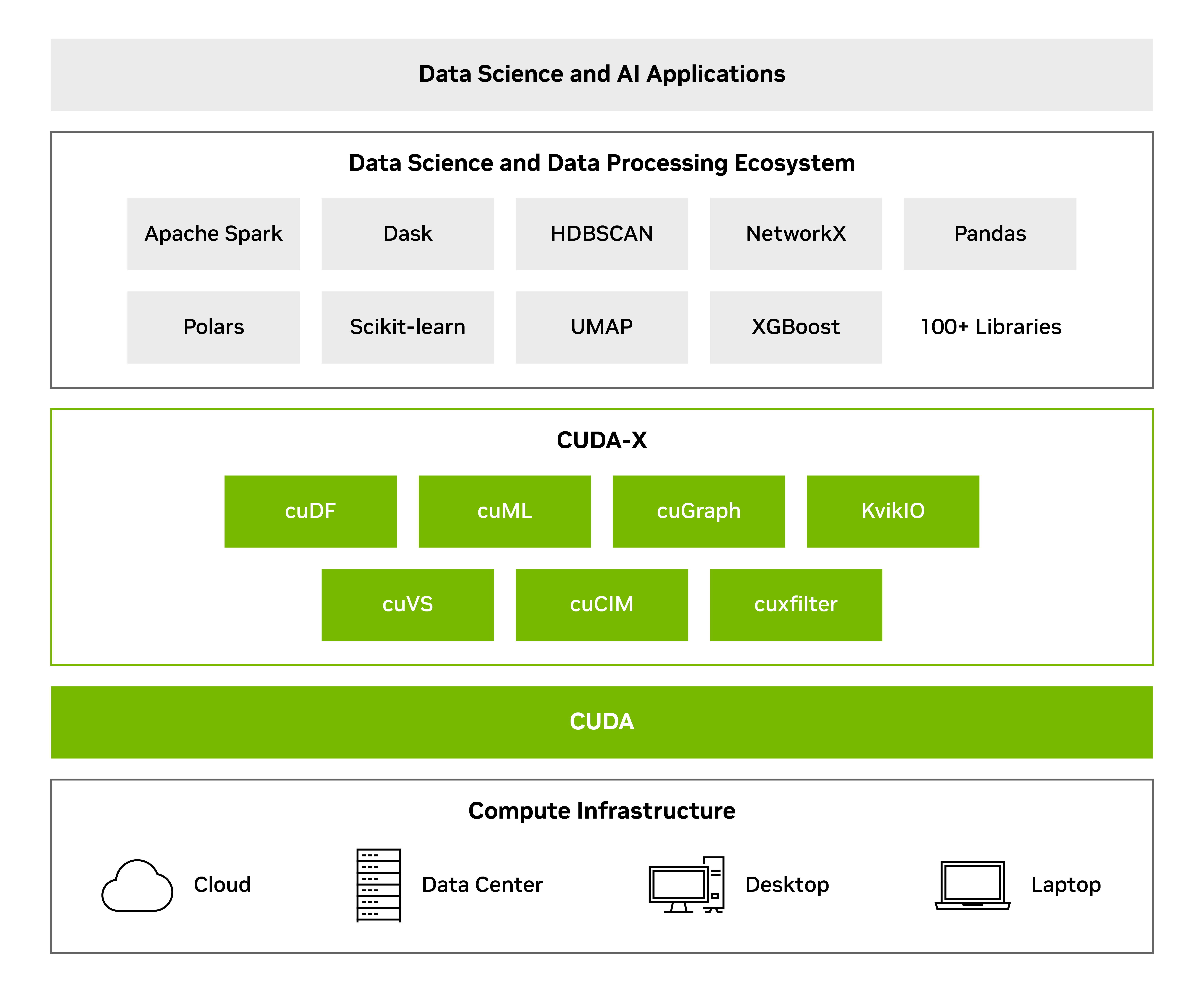
CUDA-X 数据科学库
CUDA-X 数据科学库可加速数据分析、机器学习、图分析及数据密集型应用(如向量检索),让单颗 GPU 达到优异性能,也能通过简单、无需更改代码的接口,扩展至分布式系统。
使用 cuDF 加速 Apache Spark
详细了解适用于 Apache Spark 工作流的加速器插件。
标签:机器学习,数据处理,分布式计算,Scala,Python
KvikIO
通过与 cuFile 的强大绑定,充分利用 NVIDIA® GPUDirect® Storage (GDS) 。
标签:FILEIO、GPUDirectStorage、Python、C++
开始使用
入门套件:使用 pandas Code 加速数据分析
此套件演示了如何使用 pandas 代码和 PyViz 库针对大规模数据创建响应式控制面板,同时利用 cuDF 加速探索性数据分析,且无需更改代码。
视频:借助 NVIDIA GPU 上的 pandas 加速探索性数据分析( 16:06)
Notebook:构建交互式控制面板 Notebook
入门套件:基于 XGBoost 的加速机器学习
XGBoost 是用于梯度提升决策树的热门 Python 库。它为机器学习模型的分类、回归和排名工作流程提供强力支持。
视频:
基于 NVIDIA GPU 的 XGBoost 加速机器学习( 20:10)
Notebook:开始在 GPU 上加速 XGBoost 工作流
入门套件:使用 cuML 代码加速机器学习
cuML 可加速流行的机器学习算法,包括随机森林、UMAP 和 HDBSCAN
视频:cuML 可将机器学习加速 50 倍,无需更改代码( 00:55)
Notebook:开始使用加速热门机器学习库
入门套件:使用 Apache Spark 加速数据分析
适用于 Apache Spark 的 NVIDIA RAPIDS™ 加速器可加速企业级数据工作负载,从而节约成本。
视频:使用适用于 Apache Spark 的 RAPIDS 加速器在 GPU 上加速数据分析( 1:27:34)
入门套件:使用 Polars Code 加速数据分析
Polars 以高性能和内存优化而闻名。调用由 cuDF 提供支持的 GPU 引擎,体验更快的执行速度。
视频:使用 Polar 在 2 秒内处理 1 亿行数据( 00:28)
Notebook:加速 Polars 数据处理工作流 Notebook
入门套件:使用 NetworkX Code 加速图形分析
NetworkX 可加速热门图形算法,包括 Louvain、Betweeness Centrality 和 PageRank。
视频:借助 NVIDIA cuGraph,实现高达 500 倍的网络加速,且无需更改代码( 00:42)
Notebook:加速图形分析 Notebook
在您的环境中安装和部署
使用 conda 快速安装
1. 如果未安装,请下载并运行安装脚本。这将安装最新的 miniforge:
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh" bash Miniforge3-$(uname)-$(uname -m).sh
2. 然后使用以下命令进行安装:
conda create -n rapids-26.04 -c rapidsai -c conda-forge rapids=26.04 python=3.13 'cuda-version>=13.0,<=13.1'
使用 pip 快速安装
Install via the NVIDIA PyPI index: pip install \ --extra-index-url=https://pypi.nvidia.com \ cudf-cu13==26.4.* \ dask-cudf-cu13==26.4* \ cuml-cu13==26.4.* \ cugraph-cu13==26.4.*
加速数据科学生态系统
开源库、商业软件和行业的数据从业者正在利用 CUDA-X 数据科学推动创新。
AT&T 在其数据到 AI 工作流中的 GPU 集群上应用了适用于 Apache Spark 的 RAPIDS 加速器。
Bunq 使用 NVIDIA CUDA-X 库将模型训练速度提高了 100 倍,数据处理速度提高了 5 倍,从而提高了欺诈检测的准确性。
阅读博客Capital One 加速了其金融和信用分析流程,将模型训练速度提高了 100 倍。
借助 NVIDIA cuDF,Checkout.com 将数据分析工作流的速度从几分钟缩短到几秒钟。
IRS 团队在 Cloudera 数据平台上使用适用于 Apache Spark 的 RAPIDS 加速器发现了欺诈行为。
LinkedIn 开发了 DARWIN,以便在 NVIDIA cuDF 上实现更快的数据分析。
PayPal 借助适用于 Apache Spark 的 RAPIDS 加速器将云成本降低了 70%。
广告平台 Taboola 使用适用于 Apache Spark 的 RAPIDS 加速器处理 TB 级的小时数据。
观看点播会议借助基于 CUDA-X 数据科学的 RAPIDS 单细胞,TGen 将 400 万个单元数据集的分析时间从 10 小时缩短到 3 分钟。
TCS Optumera 利用适用于 Apache Spark 的 RAPIDS 加速器加速其需求预测管道。
Uber 开发了支持 Spark 3.x 和 GPU 调度的 Horovod。
观看点播会议沃尔玛使用其产品替代算法解决了可扩展性问题。
加入社区
伦理 AI
NVIDIA 认为,可信赖的人工智能(Trustworthy AI)是各方共同的责任,为广泛的 AI 应用开发建立了相关政策和实践。用户在遵守服务条款下载或使用产品时,需与支持团队协作,确保其应用满足相关行业和场景的要求,并妥善应对产品被误用的风险。
如需报告安全漏洞或 NVIDIA AI 相关问题,请点击提交。