
随着对预训练大型语言模型( LLM )权重访问需求的增加,围绕 LLM 共享的环境正在发生变化。最近, Meta 发布了 开式预训练Transformer ,一个具有 1750 亿个参数的语言模型。 BigScience 计划在几个月内发布具有 1760 亿个参数的多语言模型。
随着越来越多的 LLM 可用,行业需要解决实际自然语言任务的技术。研究表明, 模型提示方法 可以从 LLM 中获得良好的零拍和少拍性能,并有助于在各种下游自然语言处理( NLP )任务中产生高质量的结果。白皮书提出了一种解决方案,使经过预训练的通用 LLM 在自然语言处理领域日益流行的新 预训练、提示和预测 范式中切实有用。
然而,当您将提示方法应用于工业自然语言处理应用程序时,还需要考虑其他挑战。对于任何下游 NLP 任务,必须收集标记数据,以指示语言模型如何生成预期结果。
尽管对于许多任务,有大量标记的英语数据,但很少有具有基准价值的非英语下游数据集。标记数据的稀缺性是业界在低资源语言环境中执行自然语言处理任务的首要挑战。
此外,公司通常必须动态解决多个下游非线性规划任务,这些任务可以随着时间的推移而演变。在不忘记先前学习任务的情况下对新任务进行连续学习仍然是一个热门的研究课题。一个好的、干净的解决方案意味着更低的模型维护、更低的部署成本和快速的开发。
在本文中,我们将向您展示如何将 p-tuning (一种快速学习方法)适应于低资源的语言设置。我们使用在 NVIDIA NeMo 中实现的 improved version p-tuning ,它支持虚拟提示的连续多任务学习。特别是,我们将重点放在使我们的英语 p-tuning 工作流适应瑞典语。 Learn more 关于瑞典的一个财团计划如何在北欧地区提供语言模型。
我们提出的工作流是通用的,可以很容易地为其他语言修改。
为什么选择大型语言模型?
如 OpenAI 的 语言模型比例律研究 所示,语言模型的性能随着语言模型大小的增加而提高。这导致了训练越来越大的语言模型的竞赛。
NVIDIA 最近培训了一名 Megatron 图灵 NLG 530B 该模型具有优越的零拍和少拍学习性能。为了访问 LLM ,研究人员可以使用付费模型 API ,例如 OpenAI 提供的 API ,或者在本地部署公开发布的模型。
当您有一个能够很好地理解语言的 LLM 时,您可以应用 即时学习方法 使该模型解决过多的非线性规划下游任务。
快速学习和 p- 调优的简要概述
与手动或自动选择离散文本提示不同, prompt learning 使用虚拟提示嵌入,可以使用梯度下降进行优化。这些虚拟嵌入会从文本提示自动插入到离散令牌嵌入中。

在即时学习期间,整个 GPT 模型被冻结,并且在每个训练步骤中仅更新这些虚拟令牌嵌入。提示学习过程会产生少量虚拟令牌嵌入,这些嵌入可以与文本提示相结合,以提高推理时的任务性能。
具体来说,在 p- 调谐中,使用一个小的长短时记忆( LSTM )模型作为提示编码器。提示编码器的输入是任务名称,输出是特定于任务的虚拟令牌嵌入,与文本提示嵌入一起传递到 LLM 。

多任务连续学习解决方案
图 2 显示了 p-tuning 使用提示编码器生成虚拟令牌嵌入。在 原始 p 调谐纸 中,提示编码器只能用于一个任务。我们在我们的 NeMo 实现 因此,提示编码器可以根据不同任务的名称进行调整。
训练提示编码器时,它将任务名称映射到一组虚拟令牌嵌入。这使您能够构建一个嵌入表,该表存储每个任务的任务名称和虚拟令牌嵌入之间的映射。使用此嵌入表可以不断学习新任务,避免灾难性遗忘。例如,可以使用任务 A 和 B 启动 p-tuning 。
训练后,您可以将任务 A 和 B 的虚拟令牌嵌入保存在表中,并将其冻结。您可以使用另一个新的提示编码器继续训练任务 C 。类似地,在训练后,将任务 C 的虚拟令牌嵌入保存在提示表中。在推理过程中,该模型可以查找提示表,并为不同的任务使用正确的虚拟令牌嵌入。
除了持续学习能力外, p-tuning 的 modified version 还有几个其他优点。首先,我们的实现引出了质量模型预测。今年早些时候,我们在 GTC 2022 年关于使用 P-tuning 可以显著提高大型非线性规划模型的性能 的会议上,展示了 p- 调优有助于实现下游非线性规划任务的最先进精度。
其次, p- 调优只需要几个标记的数据点就可以给出合理的结果。例如,对于 FIQA 情绪分析任务 ,它使用了 1000 个数据示例来实现 92% 的准确性。
第三,原始文件中描述的 p- 调优,在我们的具体实现中更是如此,是极其高效的参数。在 p- 调整期间,参数等于原始 GPT 模型参数的一小部分的 LSTM 被调整,而 GPT 模型权重保持不变。在训练结束时,可以丢弃 LSTM 网络,只需要保存虚拟提示本身。这意味着在推理过程中必须存储和使用总计小于 GPT 模型大小约 0.01% 的参数,以实现与零次和少次推理相比显著提高的任务性能。
第四, p-tuning 在训练期间也更节省资源。冻结 GPT 模型意味着我们不必为这些模型参数存储优化器状态,也不必花时间更新 GPT 模型权重。这节省了大量 GPU 内存。
最后,虚拟提示令牌参数与 GPT 模型解耦。这使得能够分发小型虚拟令牌参数文件,这些文件可以插入共享访问 GPT 模型,而不需要共享更新的 GPT 模型权重,这是微调 GPT 模型时所需要的。
创建瑞典下游任务数据集
为了将 p-tuning 应用于非英语下游任务,我们在目标语言中标记了数据。由于有大量的英文标签下游任务数据,我们使用机器翻译模型将这些英文标签数据翻译成目标低资源语言。在这篇文章中,我们将英文数据翻译成瑞典语。由于 p-tuning 的低标记数据要求,我们不需要翻译很多标记数据点。
为了完全控制翻译模型,我们选择使用从头开始训练的内部翻译模型。该模型采用英语到瑞典语/挪威语(一对多)的方向,使用 NeMo NMT 工具包。 训练数据(平行语料库)来自 Opus 。英语到瑞典语的翻译质量由母语为英语和瑞典语的人手动评估。
我们还使用了其他翻译模型来帮助检查我们的翻译模型的质量。我们翻译了一些来自原始英语基准数据的随机样本,并手动检查了其他模型翻译与我们自己的模型翻译的质量。我们使用了 deepL 、 谷歌翻译 API 和 DeepTranslator 。
除了一些时钟和时间系统错误外,整体翻译质量足够好,我们可以继续将英语标记的数据转换为瑞典语。随着我们的 NeMo 非负矩阵变换英语 – 瑞典语翻译模型的训练和验证完成,我们使用该模型翻译了两个英语基准数据集:
- 财务情绪分析 ( FIQA )
- Assistant Benchmarking (助手)
为了方便起见,我们使用 svFIQA 和 svAssistant 来区分原始英语和翻译后的瑞典基准数据集。
以下是分别从 FIQA 和 svFIQA 中随机选取的培训记录示例:
英语:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC Are The 2 Banks I'd Buy Today. Sentiment for Lloyds ", "label": "positive"}
瑞典的:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
翻译后的数据集应保留实际英语源数据的正确语法结构。因为情绪指的是两家银行,所以是复数。翻译成瑞典语的地面实况标签也应反映正确的瑞典语语法,即“ positiva ”。
为了完整性起见,我们还从 Assistant 和 svAssistant 中随机选择了一个示例:
英语:
{"taskname": "intent_and_slot", "utterance": "will you please get the coffee machine to make some coffee", "label": "\nIntent: iot_coffee\nSlots: device_type(coffee machine)"}
瑞典的:
{"taskname": "intent_and_slot", "utterance": "kommer du snälla få kaffemaskinen för att göra lite kaffe", "label": "Intent: iot _ kaffe Slots: enhet _ typ (kaffemaskin)"}
GPT 模型
以下实验中使用的瑞典 GPT-SW3 检查点是瑞典 AI 和 NVIDIA 合作的结果。更具体地说, AI 瑞典的 GPT-SW3 检查点具有 36 亿个参数,使用威震天 LM 进行预训练。该模型用于进行本文所述的瑞典多任务 p- 调整实验。
多任务 p- 调谐实验
为了模拟典型的企业客户用例,我们设想了一个场景,其中用户首先需要高精度地解决情感分析非线性规划任务。随后,随着业务的发展,用户需要继续使用相同的模型解决虚拟助理任务,以降低成本。
我们在瑞典语的连续学习设置中运行了两次 p-tuning 。我们将 svFIQA 数据集用于第一个自然语言处理任务。然后,我们将 svAssistant 数据集用于第二个 NLP 任务。
我们可以同时对这两个任务进行 p-tuned 。然而,我们选择连续进行两轮 p 调整,以展示 NeMo 中的连续快速学习能力。
我们首先使用该 p-tuning 教程笔记本 的稍微修改版本,对 svFIQA 和 svAssistant 进行了一系列短期超参数调优实验。在这些实验中,我们确定了每个任务的最佳虚拟令牌数量和最佳虚拟令牌放置。
为了在文本提示中操作虚拟令牌的总数及其位置,我们在 p-tuning 模型的训练配置文件中修改了以下sentiment任务模板。有关 p-tuning 配置文件的更多信息,请参阅 NeMo 文档中的 提示学习配置部分 。
"taskname": "sentiment", "prompt_template": "<|VIRTUAL_PROMPT_0|> {sentence} <|VIRTUAL_PROMPT_1|>sentiment:{label}", "total_virtual_tokens": 16, "virtual_token_splits": [10,6], "truncate_field": None, "answer_only_loss": True, "answer_field": "label",
此提示模板是特定于语言的。除了虚拟令牌的位置和使用的虚拟令牌的数量外,将每个提示模板中的单词翻译成目标语言也很重要。在这里,术语“情绪”(添加在最终虚拟提示令牌和标签之间)应翻译成瑞典语。
在我们的实验中,我们使用了 10 倍交叉验证来计算性能指标。在我们的超参数搜索过程中,我们对瑞典 GPT-SW3 模型进行了第一次 p- 调优,直到验证损失在 10-20 个阶段后趋于稳定。
在以这种方式进行了几轮实验后,我们决定对 svFIQA 数据集的所有 10 倍使用以下模板:
"taskname": "sentiment-task", "prompt_template": "<|VIRTUAL_PROMPT_0|> {sentence}:{label}", "total_virtual_tokens": 10, "virtual_token_splits": [10], "truncate_field": None, "answer_only_loss": True, "answer_field": "label",
术语“情绪”从提示模板中删除,而是直接包含在提示的{sentence}部分。这使我们能够轻松地将“感悟”与英语句子的其余部分一起翻译成瑞典语:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
在找到最佳训练配置后,我们在 10 个 svFIQA 折叠中的每个折叠上对瑞典 GPT-SW3 模型进行了 p- 调优。我们评估了对应测试分割上每个折叠的 p- 调整检查点。通过对 svAssistant 数据集重复相同的步骤,我们向 GPT-SW3 模型中添加了意向和时隙预测功能,这次恢复了在 svFIQA 上训练的检查点,并添加了意向和时隙任务。
后果
为了建立一个基线,并且由于在这种情况下没有瑞典现有的基准,我们使用原始 AI 瑞典 GPT-SW3 模型的零、一和少数镜头学习性能作为基线(图 3 )。

可以看出,除了零炮外, svFIQA 上的少数炮学习性能为 42-52% 。可以理解,由于 GPT 模型接收到零标记示例,零炮的性能明显较差。该模型生成的令牌很可能与给定任务无关。
考虑到情绪分析任务的二元性,在计算任务准确性之前,我们将单词“ positive ”和“ negative ”的所有瑞典语法变体映射到相同的格式。
positiv, positivt, positiva → positiv negativ, negativt, negativa → negativ
| fold_id | accuracy |
| 0 | 87.18% |
| 1 | 79.49% |
| 2 | 85.47% |
| 3 | 79.49% |
| 4 | 78.63% |
| 5 | 86.32% |
| 6 | 78.63% |
| 7 | 82.91% |
| 8 | 77.78% |
| 9 | 90.60% |
| average across 10 folds | 82.65% |
通过这种重映射机制,我们取得了相当好的结果: 82.65% 。 svFIQA 测试中的 p- 调谐性能在所有 10 倍中取平均值。
表 2 显示了 svAssistant 数据集(意向和时隙分类)上第二轮 p 调整的结果。所有 10 倍的分数也取平均值。
| Precision | Recall | F1 -Score | |
| average | 88.00% | 65.00% | 73.00% |
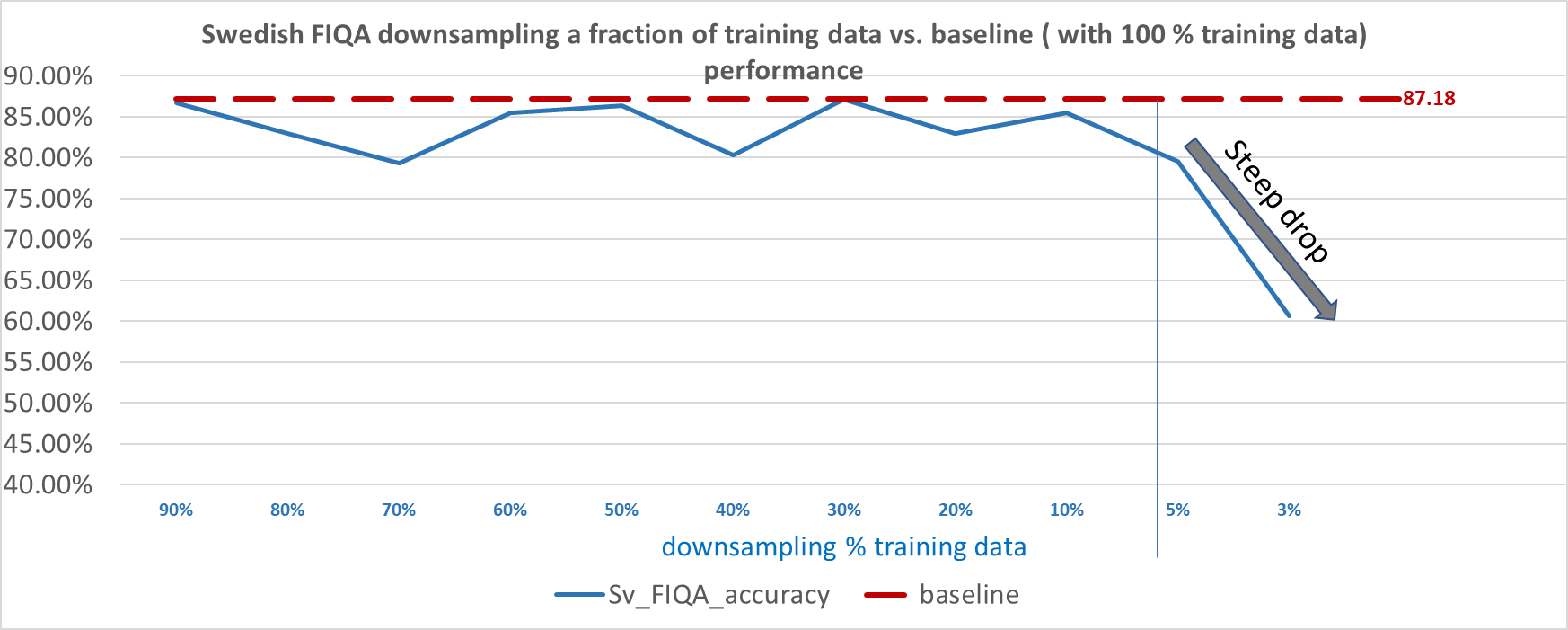
接下来,我们进一步探讨了这个问题, “ 在不降低性能的情况下,我们可以减少多少训练数据总量? ”
对于 svFIQA 数据集,我们发现我们可以在每次训练运行中只获得十分之一的训练数据,并且仍然保持可接受的性能。然而,从 5% 的训练数据开始(只有 47 个训练数据点),我们开始看到性能急剧下降,性能在 1% 左右变得不稳定(只有 9 个训练数据点,平均 6 次训练,每个训练有 9 个随机采样的数据点)。
今后的工作
我们注意到,可以改进意向和时隙分类的结果。它们在很大程度上依赖于翻译模型将非自然文本从英语翻译为瑞典语的能力。在下面的示例中,英语意图和时隙提示格式对于翻译模型来说很难准确翻译,从而影响了瑞典语翻译的质量。
- 英文标签为“意图: alarm \ u set Slots : date ( sunday ), 时间(上午八点)” 。
- 当它被翻译成瑞典语时,它变成了 “时间(上午八点)” 。
翻译模型完全跳过了“意图”和“槽:”这两个词。它还删除了 intent 中alarm_set和插槽中date(sunday)的翻译。
未来,我们将把源语言数据表述为自然语言,然后再将其翻译成目标语言。我们还尝试了一种预训练的 mT5 模型,该模型可以完全跳过翻译步骤。早期的结果是有希望的,所以请关注完整的结果。
最后,我们还计划将快速学习方法与基本 GPT 模型的完全微调进行比较。这将使我们能够比较两种任务适应方法之间的权衡。
结论
在这篇文章中,我们展示了一种参数高效的解决方案,可以在低资源语言环境中解决多个自然语言处理任务。针对瑞典语,我们将英语情感分类和意图/时隙分类数据集翻译成瑞典语。然后,我们在这些数据集上对瑞典 GPT-SW3 模型进行了 p- 调优,与我们的几个快照学习基线相比,取得了良好的性能。
我们表明,我们的方法可以帮助您训练提示编码器,只需将原始训练数据的十分之一调整到模型原始参数的 0.1% 以下,同时仍能保持性能。
由于 LLM 在训练过程中被冻结, p-tuning 需要更少的资源,整个训练过程可以高效快速地完成,这使得任何人都可以访问 LLM 。您可以带上自己的数据,并根据自己的用例调整模型。
在我们的 NeMo p- 调谐实现中,我们还简化了轻量级的连续学习。您可以使用我们的方法不断学习和部署新任务,而不会降低以前添加的任务的性能。
致谢
我们非常感谢阿玛鲁·古巴·吉伦斯坦 ( amaru.cuba.gyllensten@ri.se) , 阿里尔·埃克格伦 ( ariel.ekgren@ai.se) , 和 Magnus Sahlgren( magnus.sahlgren@ai.se) 感谢您与我们分享他们的 GPT-SW3 模型检查点,以及他们对本文的见解和建议。