
ChatGPT 给人留下了深刻印象。用户很乐意使用人工智能聊天机器人提问、写诗、塑造互动角色、充当个人助理等等。大语言模型( LLM )为 ChatGPT 供电,这些模型就是本文的主题
在更仔细地考虑 LLM 之前,我们首先想确定语言模型的作用。语言模型给出了一个单词在单词序列中有效的概率分布。从本质上讲,语言模型的工作是预测哪个词最适合一个句子。图 1 提供了一个示例。
![Screenshot of the words, "Hey I need to chop this onion, can you pass me the [?] -- Model's prediction[?]: Knife."](https://lh4.googleusercontent.com/YMDSzp4md5FuOGakw_5ukMk8By37UAsReaqoGrzhbohrsyioVFx0bUIZkRdyxH0OyXVBQFL42mQU8OBaggzPgGvMhOVlxupKNq6DclAXzg8ij7wCXkrXnclKWb1fOxKmHNvSYJHOqFPsTK-REZo8XWA)
虽然像 BERT 这样的语言模型已经被有效地用于处理文本分类等许多下游任务,但已经观察到,随着这些模型规模的增加,某些额外的能力也会出现
这种规模的增加通常伴随着以下三个维度的相应增加:参数的数量、训练数据和训练模型所需的计算资源。有关详细信息,请参阅Emergent Abilities of Large Language Models.
LLM 是一种深度学习模型,可以使用大型数据集识别、总结、翻译、预测和生成内容。 LLM 没有一个集合的界限,但为了本讨论的目的,我们使用这个术语来指代任何 GPT 规模的模型或具有 1B 或更多参数的模
这篇文章解释了在使用较小语言模型构建的一组模型管道上使用 LLM 的好处。它还涵盖了以下基本内容:
- LLM 提示
- 快速工程
- P- 调谐
为什么要使用大型语言模型?
聊天机器人通常是由一组 BERT 模型和一个对话框管理器构建的。这种方法具有一些优点,例如更小的模型,这可以降低延迟和计算需求。这反过来又更具成本效益。那么,为什么不使用合奏而不是 LLM 呢?
- 就其设计而言,合奏团不如 LLM 灵活。这种灵活性来自生成能力,以及所述模型是在需要各种任务的大型数据语料库上训练的。
- 在许多情况下,获得足够的数据来应对挑战是不可行的。
- 每个集合都有自己的 MLOps 管道。维护和更新大量复杂的合奏是困难的,因为每个合奏中的每个模型都必须定期进行微调。

LLM 在多个系综中的价值
可以说,一组模型可以比 LLM 便宜。然而,仅考虑推理成本,这一假设忽略了以下考虑因素:
- 节省工程时间和成本:构建、维护和扩展集成是一项复杂的挑战。每个组件模型都必须进行微调。用于模型推理和缩放以适应流量的人工智能基础设施需要相当多的时间来构建。这是针对一项技能。为了模仿 LLM ,必须建立多种技能。
- 更短的功能发布时间:为一项新技能建立一个新管道所需的时间通常比对 LLM 进行 p 调谐所需要的时间更长(稍后将对此进行详细介绍)。这意味着 TTM 要长得多。
- 数据采集和质量维护:任何专门构建的集合都需要大量的特定病例数据,而这些数据并不总是可用的。必须在每个模型的基础上收集这些数据。换句话说,除了来自集成的 I / O 之外,还需要用于集成中使用的每个单独模型的数据集。此外,所有模型都会随着时间的推移而漂移,在使用多个模型时,用于微调的维护成本会迅速增加。
这些考虑因素显示了在多个系综上使用 LLM 的价值。
提示 LLM
提示被用作与 LLM 交互以完成任务的一种手段。提示是用户提供的输入,模型要对其做出响应。提示可以包括说明、问题或任何其他类型的输入,具体取决于模型的预期用途。例如,在稳定扩散模型的情况下,提示是要生成的图像的描述

提示也可以采用图像的形式。通过这种方法,生成的文本输出描述了图像提示。这通常用于图像字幕等任务。

对于 GPT-3 等模型,文本提示可以是一个简单的问题,比如“彩虹中有多少种颜色?”或者,提示可以采取复杂问题、数据或指令的形式,比如“写一首励志诗,让我快乐。”
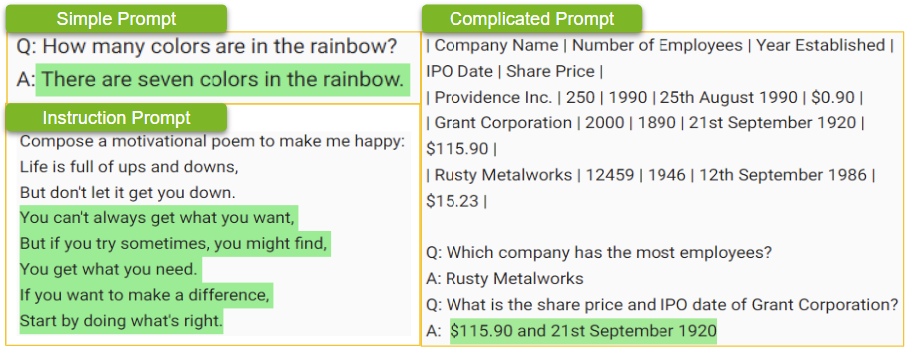
提示还可以包括特定的约束或要求,如语气、风格,甚至所需的响应长度。例如,给朋友写信的提示可以指定语气、字数限制和要包含的特定主题
LLM 生成的响应的质量和相关性在很大程度上取决于提示的质量。因此,提示在自定义 LLM 以确保模型的响应满足自定义用例的要求方面发挥着关键作用
提示工程以获得更好的提示
术语快速工程是指仔细设计提示以生成特定输出的过程。提示在从模型中获得最佳结果方面发挥着关键作用,而如何编写提示可以对生成的输出产生很大影响。以下示例讨论了三种不同的策略:
- 零样本提示
- 很少提示射击
- 思维链提示
零样本意味着提示模型,而不显示任何来自模型的预期行为示例。例如,一个零样本提示会提出一个问题。

在图 7 中,答案是错误的,因为巴黎是首都。从答案来看,模型可能不理解“资本”一词在这种情况下的使用
克服这个问题的一个简单方法是在提示中给出一些例子。这种类型的提示被称为少镜头提示。在提出实际问题之前,您提供了几个例子

几次射击提示使模型能够在没有训练的情况下进行学习。这是设计提示的一种方法
你如何让模型合乎逻辑地回答一个问题?要了解这一点,请从更复杂的零样本提示开始。

在图 9 中,答案再次出现错误。(正确答案是四个蓝色高尔夫球。)为了帮助发展推理,请使用一种名为 思维链提示。通过提供一些镜头示例来做到这一点,其中解释了推理过程。当 LLM 回答提示时,它也会显示其推理过程。

虽然图 10 中所示的示例是一个“思考链”提示,但您也可以给出一个“零样本链”提示。这种类型的提示包括诸如“让我们从逻辑上思考这个问题”之类的短语

通过这种方法, LLM 生成了一个能够准确回答问题的思想链。尝试一系列不同的提示是很有用的
P- 调整以自定义 LLM
如前所述,即时工程是定制模型响应的一种方法。然而,这种方法有缺点:
- 可以使用少量示例,从而限制控制级别。
- 示例必须预先附加,这会影响代币预算
如何绕过这些限制?
迁移学习是一个明显的候选者:从一个基本模型开始,使用特定于用例的数据来微调模型。这种方法在处理常规模型时效果很好,但微调具有 530B 参数的模型(比 BERT 模型大约 5300 倍)会消耗相当大的时间和资源
P- 调谐,或迅速调谐, 是一种参数有效的调整技术,可以解决这一挑战.P- 调谐包括在使用 LLM 之前使用一个小的可训练模型。小模型用于对文本提示进行编码,并生成特定于任务的虚拟令牌
这些虚拟令牌被预先附加到提示并传递给 LLM 。当调优过程完成时,这些虚拟令牌被存储在查找表中,并在推理过程中使用,取代较小的模型。
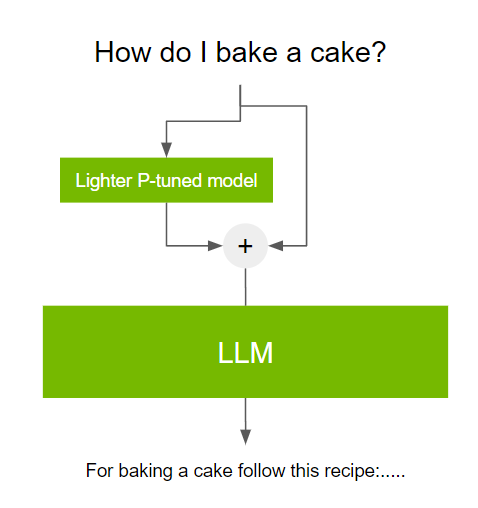
这一过程是有益的,原因如下:
- 与微调 LLM 相比,定制模型管道以获得所需结果所需的资源要少得多。
- 调整较小型号所需的时间要少得多(最快可达约 20 分钟)。
- 在不需要大量内存的情况下,可以保存对不同任务进行 p 调整的模型。
这个NVIDIA NeMo 云服务简化了这个过程。有关详细信息,请参阅p-tuning the models in the NeMo service(您必须是早期访问计划的成员)。
结论
这篇文章讨论了 LLM ,并概述了它们的使用案例。它还涵盖了定制 LLM 行为所涉及的基本概念,包括各种类型的提示、提示工程和 p 调整。
有关详细信息,请参阅more posts about LLMs.