大型语言模型 (LLM) 对人类语言和编程语言的深刻理解正在改变 AI 格局。对于新一代企业生产力应用程序而言,它们至关重要,可提高用户在编程、文案编辑、头脑风暴和回答各种主题的问题等任务中的效率。
然而,这些模型通常难以处理实时事件和特定知识领域,从而导致不准确之处。微调这些模型可以增强其知识,但成本高昂,并且需要定期更新。
检索增强生成(RAG)通过将信息检索与 LLM 结合,为开放领域的问答应用提供解决方案。RAG 为 LLM 提供大量可更新的知识,有效解决了这些限制(图 1)。NVIDIA NeMo 框架中的 NVIDIA NeMo Retriever 优化了 RAG 的嵌入和检索部分,以提供更高的准确性和更高效的响应。
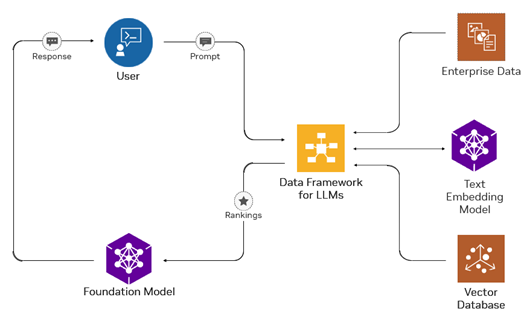
本文概述了 RAG 工作流组件的工作原理,以及与创建支持 RAG 的 AI 应用相关的企业挑战(例如商业可行性)。您将了解 NeMo Retriever (包括适用于企业 RAG 工作流的生产就绪型组件)以及我们今天分享的模型。
规范的 RAG 工作流
RAG 应用通常具有从嵌入到检索和响应的多个阶段。我们来看看典型的 RAG 工作流,了解 NeMo Retriever 如何提供帮助。
对知识库进行编码(离线)
在此阶段,知识库(通常由文本、PDF、HTML 或其他格式的文档组成)被分割成多个块。然后,这些块被输入到嵌入深度学习模型中,该模型会为每个块生成密集的向量表示。
生成的嵌入及其相应的文档和其他元数据存储在向量数据库中(图 2)。分块策略取决于文档的类型和内容、元数据(例如文档详细信息)的使用以及生成合成数据的方法(如果适用)。在开发检索系统时,必须仔细考虑这一策略。

通过计算用户查询中的嵌入与存储在数据库中的文档之间的相似性(例如点积),这些嵌入可以用于语义搜索。向量数据库专门用于存储大量向量化数据,并能够快速执行 近似最近邻搜索。
部署(在线)
此阶段的重点是在向量数据库连接到 LLM 应用程序时进行部署,以便实时回答问题。该阶段分为两个阶段:从向量数据库检索和生成响应。
第 1 阶段:根据用户的查询从向量数据库中检索*
用户的查询首先嵌入为密集向量。通常,会在查询中添加一个特殊的前缀,以便检索者使用的嵌入模型能够理解它是一个问题。这使得非对称语义搜索其中,简短查询可用于查找更长的段落来回答查询。
接下来,查询嵌入用于搜索向量数据库,该数据库可检索与用户查询最相关的少量文档块(图 3)。

向量数据库通过使用近似搜索算法来实现这一点,例如余弦相似度。这保证了可扩展性和低延迟。
第 2 阶段:使用 LLM 利用上下文生成响应
在此阶段,我们将最相关的数据块组合成一个上下文,然后将其与用户的查询结合起来,作为 LLM 的最终输入。提示通常包含额外的指令,用于指导 LLM 仅根据上下文生成响应。图 4 说明了此响应生成过程。

为企业应用构建 RAG 工作流面临的挑战
虽然 RAG 本身相比于 LLM 具有显著的优势,但必须注意的是,这些优势伴随着一些必须解决的挑战。一个主要问题是找到商业上可行的检索策略,这通常会受到训练数据集许可限制的影响,例如 MSMARCO。现实世界中的查询因其模糊性而更加复杂;用户往往会输入不完整或模糊的查询,这使得检索变得更加困难。
在多回合对话中,这种复杂性会随着用户查询经常引用对话的早期部分而增加,因此需要对上下文进行理解才能进行有效检索。此外,一些查询需要合成来自多个来源的信息,因此需要高级集成功能。
对于 LLM 而言,处理长上下文输入是一项挑战。这些模型尽管不断改进,但通常难以忘记长上下文输入中的细节,并且需要大量计算资源,这在多回合场景中变得更加明显。
这些系统的部署涉及复杂的 RAG 流程,其中包括嵌入、向量数据库和 LLM 等各种微服务。以安全、高效的方式设置和管理这些服务是一项重要任务。
我们来看看 NeMo Retriever 如何简化复杂场景中的检索流程,它带来了一套经过优化的商用工具。
用于检索增强代的 NVIDIA NeMo Retriever
我们宣布了最新加入 NVIDIA NeMo 框架 的 NVIDIA NeMo Retriever,这是一种可在本地或云端部署的信息检索服务。它为企业提供了一条安全、简化的路径,将企业级 RAG 功能集成到其定制的生产级 AI 应用中。
NeMo Retriever 旨在提供先进的商用模型和微服务,并针对更低的延迟和更高的吞吐量进行优化。它还具有具有企业级支持的生产就绪型信息检索管道。构成此解决方案核心的模型已使用负责任的精选可审计数据源进行训练。有多个预训练模型作为起点,开发者还可以针对特定领域的用例快速定制这些模型,例如 IT 或人力资源帮助助理以及研发研究助理。
今天,我们将分享我们的嵌入模型,该模型针对文本问答检索进行了优化。我们正在开发重新排序和检索微服务,这些服务即将推出。
NVIDIA 检索 QA 嵌入模型
嵌入模型是文本检索系统的重要组件,因为它将文本信息转换为密集向量表示。它们通常是 Transformer 解码器,用于处理输入文本(例如,问题、段落)的标记以输出嵌入。
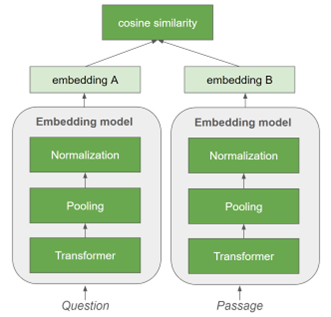
用于文本检索的嵌入模型通常使用双编码器架构进行训练,如图 5 所示。这涉及使用嵌入模型独立编码一对句子(例如,查询和分块段落)。对比学习用于最大限度地提高查询与包含答案的段落之间的相似性,同时最大限度地减少查询与无法回答问题的采样否定段落之间的相似性。
NVIDIA Retrieval QA Embedding Model 是一款 Transformer 编码器,是 E5-Large-Unsupervised 的微调版本,具有 24 层,嵌入大小为 1024,在私有和公共数据集上进行训练。它支持最多输入 512 个令牌。此外,我们致力于研究尖端的模型架构和数据集,以通过 NeMo Retriever 实现先进的 (SOTA) 检索模型。
训练数据集
大规模公共开放 QA 数据集的开发促进了功能强大的嵌入模型的巨大进步。然而,一个受欢迎的数据集,名为 MSMARCO,因其商业许可的限制,使得这些模型在商业环境中的应用受到限制。为了克服这一挑战,我们创建了自己的内部开放领域 QA 数据集,旨在训练可在商业上应用的嵌入模型。
我们在博客中搜索了与 NVIDIA 专有数据收集相关的段落,并选择了一组与客户用例相关的段落。这些段落由 NVIDIA 内部数据标注团队进行标注。
为了更大限度地减少数据收集过程中的冗余,我们选择了能够更大限度地提高相关性距离分数并增加数据多样性的样本。预训练的嵌入模型使用混合的英语语言数据集(包括我们的专有数据集)以及从商用公共数据集中选择的样本进行了微调。
我们的主要目标是优化信息检索功能,尤其是针对常见企业 LLM 用例(基于文本的问答,而非知识库)定制嵌入模型。
评估结果
NVIDIA Retrieval QA 嵌入模型专注于问答应用。这是一个非对称语义搜索问题,因为问题和段落通常有不同的分布和模式 – 问题通常比包含答案的段落更短。
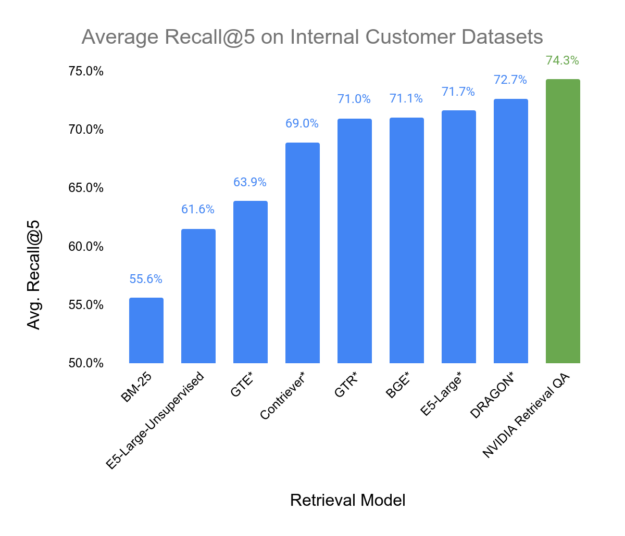
我们使用来自电信、IT、咨询和能源行业的真实内部客户数据集对嵌入模型进行了评估。该指标为 Recall#5,以模拟 RAG 场景,在该场景中,我们在 LLM 模型回答问题的提示中提供了最相关的五个段落作为上下文。我们将模型的信息检索准确性与 AI 社区提供的许多知名嵌入模型(包括使用非商用数据集训练的模型)进行了比较,这些模型用*标记。Recall#5 用于衡量相关商品在检索的前五个商品中出现的频率。
您可以在图 6 中看到基准测试的结果。请注意,在这些基准中,我们的 Retriever 模型实现了最佳性能。
如图 7 所示,我们将 NVIDIA Retrieval QA Embedding Model 与学术基准测试 NQ、HotpotQA、FiQA(来自 BeIR 基准测试)和 TechQA 数据集进行了比较。在此基准测试中,使用的指标是 标准化折扣累积增益(NDCG=10)。
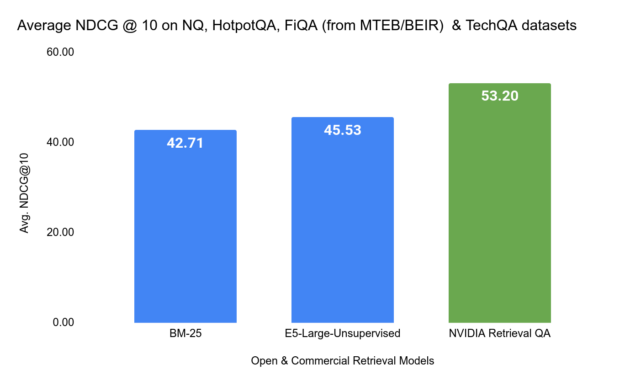
请注意,techQA 数据集由 IBM 技术论坛精选的问答以及作为知识库的 80 万个 technotes 组成,这些在之前并未用于检索基准设置。我们提供了一个notebook,用以将此数据集转换为与 BEIR 兼容的格式,以便进行基准测试。
入门指南
NVIDIA Retrieval QA Embedding Model 即将作为抢先体验版 (EA) 的微服务容器提供。欢迎申请加入EA 计划。
您还可以免费试用 NVIDIA Retrieval QA 嵌入 API,请访问 NGC 目录。
NVIDIA 检索 QA 嵌入 Playground API
NVIDIA Retriever QA 嵌入模型是基于 E5 – 大型无监督式工作站,并且采用类似的输入格式要求。发出请求时,您必须在有效负载中明确指出是“查询”还是“通道”。这一点对于非对称任务(例如,在开放式 QA 中进行通道检索)是必要的。
API 接受简单的有效载荷格式,其中“input”是用于生成嵌入的文本块。在以下示例 API 调用中,我们将两个较长的文本嵌入为“passages”(段落)和一个较小的“query”(查询)文本,然后使用点积计算段落与查询之间的相似度。
请注意,您必须登录 NGC AI Playground 并获取 API 密钥,在以下代码段中,API 密钥用作“API_KEY”。
1.嵌入两个段落。
import requests
import numpy as np
# Make sure to fill this. You will need to obtain the API_KEY from NGC playground
API_KEY="<YOUR_NGC_PLAYGROUND_API_KEY>"
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/091a03bb-7364-4087-8090-bd71e9277520"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
# To re-use connections
session = requests.Session()
# Note the "model": "passage" field in the payload.
passage_payload = {
"input": ["Pablo Ruiz Picasso was a Spanish painter, sculptor, printmaker, ceramicist and theater designer who spent most of his adult life in France.",
"Albert Einstein was a German-born theoretical physicist who is widely held to be one of the greatest and most influential scientists of all time."],
"model" : "passage",
"encoding_format": "float"
}
passage_response = session.post(invoke_url, headers=headers, json=passage_payload)
while passage_response.status_code == 202:
request_id = passage_response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
passage_response = session.get(fetch_url, headers=headers)
passage_response.raise_for_status()
passage_embeddings = np.asarray([item['embedding'] for item in passage_response.json()['data']])
2.嵌入查询
# Note the "model": "query" field in the payload
query_payload = {
"input": "Who is a great particle physicist?",
"model" : "query",
"encoding_format": "float"
}
query_response = session.post(invoke_url, headers=headers, json=query_payload)
while query_response.status_code == 202:
request_id = query_response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
query_response = session.get(fetch_url, headers=headers)
query_response.raise_for_status()
query_embedding = np.asarray(query_response.json()['data'][0]['embedding'])
3.计算段落与查询嵌入之间的相似性
# A simple dot product
np.dot(passage_embeddings, query_embedding)
输出:
array([0.33193235, 0.52141018])
在本示例中,查询与第二段有更多相似之处,两者都与物理域有关。
结束语
NVIDIA NeMo Retriever 提供专为问答应用量身打造的嵌入服务。嵌入模型和服务根据商业用途许可证提供。虽然此模型在多个公共和内部基准测试中显示出了有希望的结果,但我们正在不断提高模型的质量。
请务必申请抢先体验 NeMo Retriever 微服务,并期待在未来版本中推出更多内容。
要获得 600 多个 SDK 和 AI 模型的独家访问权限、免费培训,以及与我们的技术专家社区交流,请免费加入 NVIDIA 开发者计划。在限定时间内,新会员将获得 NVIDIA DLSS 合作伙伴 NVIDIA 深度学习培训中心 (DLI) 的加入资格。