
根据美国质量协会( ASQ )的说法,缺陷会让制造商付出 几乎占总销售收入近20%的代价。我们每天互动的产品,如手机、汽车、电视和电脑,需要精确制造,以便在不同的条件和场景下提供价值。
基于人工智能的计算机视觉应用程序正在帮助发现制造过程中的缺陷,比传统方法更快、更有效,使公司能够提高产量,交付质量一致的产品,并减少误报。事实上,根据一项研究,如今 64% 的制造商已经部署了人工智能来帮助日常活动, Google Cloud生产报告指出39% 的制造商使用人工智能进行质量检查.
为这些视觉应用提供动力的人工智能模型必须经过训练和调整,以预测许多用例中的特定缺陷,例如:
- 汽车制造缺陷,如裂纹、油漆缺陷或装配不当
- 半导体和电子产品缺陷,如 PCB 上的组件错位、焊点断裂或过多,或灰尘或毛发等异物
- 电信缺陷,如裂缝、蜂窝塔和电线杆腐蚀
训练感知人工智能模型需要收集特定缺陷的图像,这在生产环境中既困难又昂贵
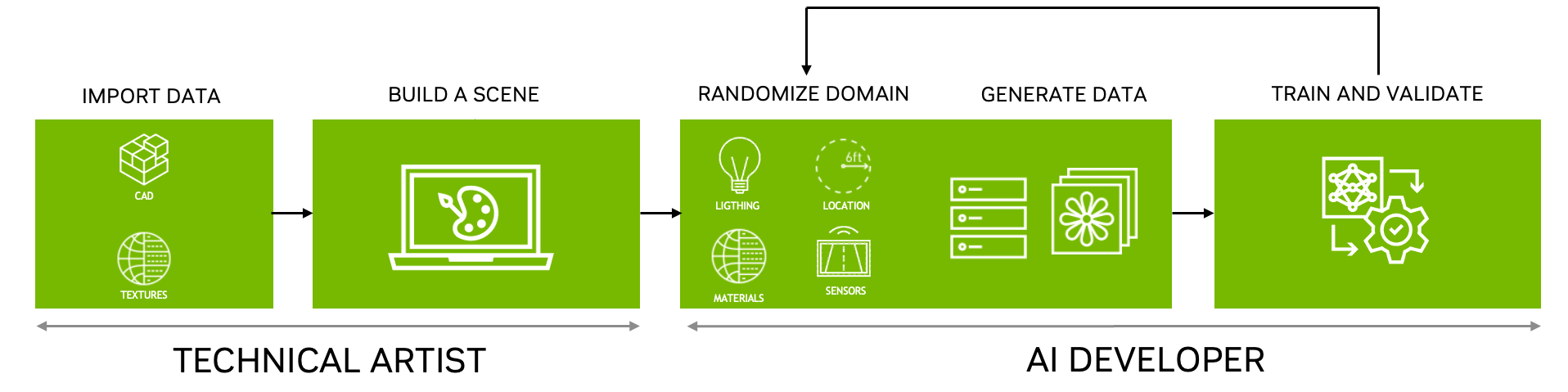
NVIDIA Omniverse Replicator可以通过生成合成数据以引导人工智能模型训练过程。 Replicator 是中的一个可扩展基础应用程序NVIDIA Omniverse,一个使个人和团队能够开发的计算平台Universal Scene Description (USD)– 基于三维工作流和应用程序。
开发人员可以使用 Omniverse Replicator 通过改变许多参数(如缺陷类型、位置、环境照明等)来轻松生成不同的数据集,以引导和加快模型训练和模型迭代。参观Develop on NVIDIA Omniverse了解更多信息。
这篇文章解释了如何使用合成数据,利用有限的地面实况数据进一步提高了其准确性,并将其与模型从未见过的图像进行了验证。使用这种方法,我们展示了用合成数据克服真实数据不足的价值,并展示了如何在模型训练过程中减少模拟与现实的差距
开发缺陷检测模型
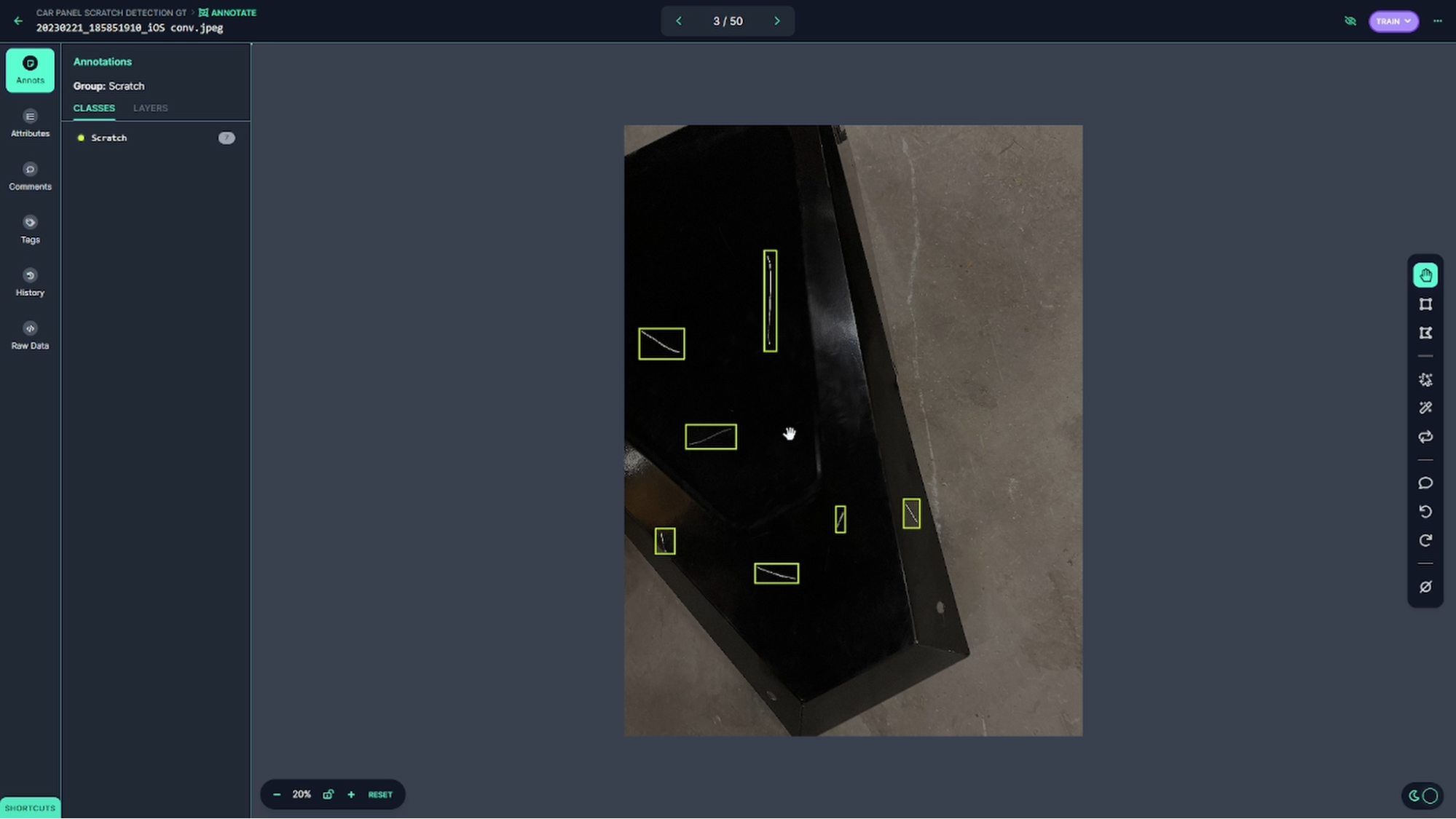
这个例子在汽车面板(前鼻锥)上产生划痕,如图 1 所示。请注意,此工作流需要Adobe Substance 3D Designer或预先生成的划痕库、 NVIDIA Omniverse 和基于下载的 USD 的样本。

整个工作流程从创建一组缺陷划痕开始,在本例中是在 Adobe Substance 3D Designer 中,并将这些缺陷划痕与 CAD 零件一起导入 NVIDIA Omniverse 。然后将 CAD 零件放置到场景(例如,制造车间或车间)中,并将传感器或相机放置在所需位置
场景设置后,使用 NVIDIA Omniverse Replicator 将缺陷按程序应用到 CAD 零件上,该 Replicator 生成注释数据,然后用于训练和评估模型。这个迭代过程一直持续到模型达到所需的 KPI 为止
创建划痕
擦伤和划痕是制造过程中常见的表面缺陷。一种称为法线映射用于在 3D 环境中表示这些纹理。法线贴图是高度信息的 RGB 图像表示,其与 3D 空间中相对于曲面的 X 、 Y 和 Z 轴直接对应。
本例中使用的法线贴图是在 Adobe Substance 3D Designer 中创建的,但也可以在大多数建模软件(如Blender或Autodesk Maya.

尽管一旦划痕被带到 Omniverse 中,就可以对划痕的大小和位置进行随机化,但最好建立一个保存在文件夹中的整个法线图库,以生成一组稳健的合成数据。这些法线贴图应该是各种形状和大小,代表不同严重程度的划痕。
设置场景
现在,是时候设置场景了。首先,打开 Omniverse 代码import the CAD model of the part。在本例中,我们从中导入了 RX3 赛车手鼻板的 SOLIDWORKS.SLDPRT 文件Sierra Cars.

将 CAD 文件导入 Omniverse 后,将场景的背景设置为尽可能靠近地面实况数据的环境。在这种情况下,我们对车间进行了激光雷达扫描
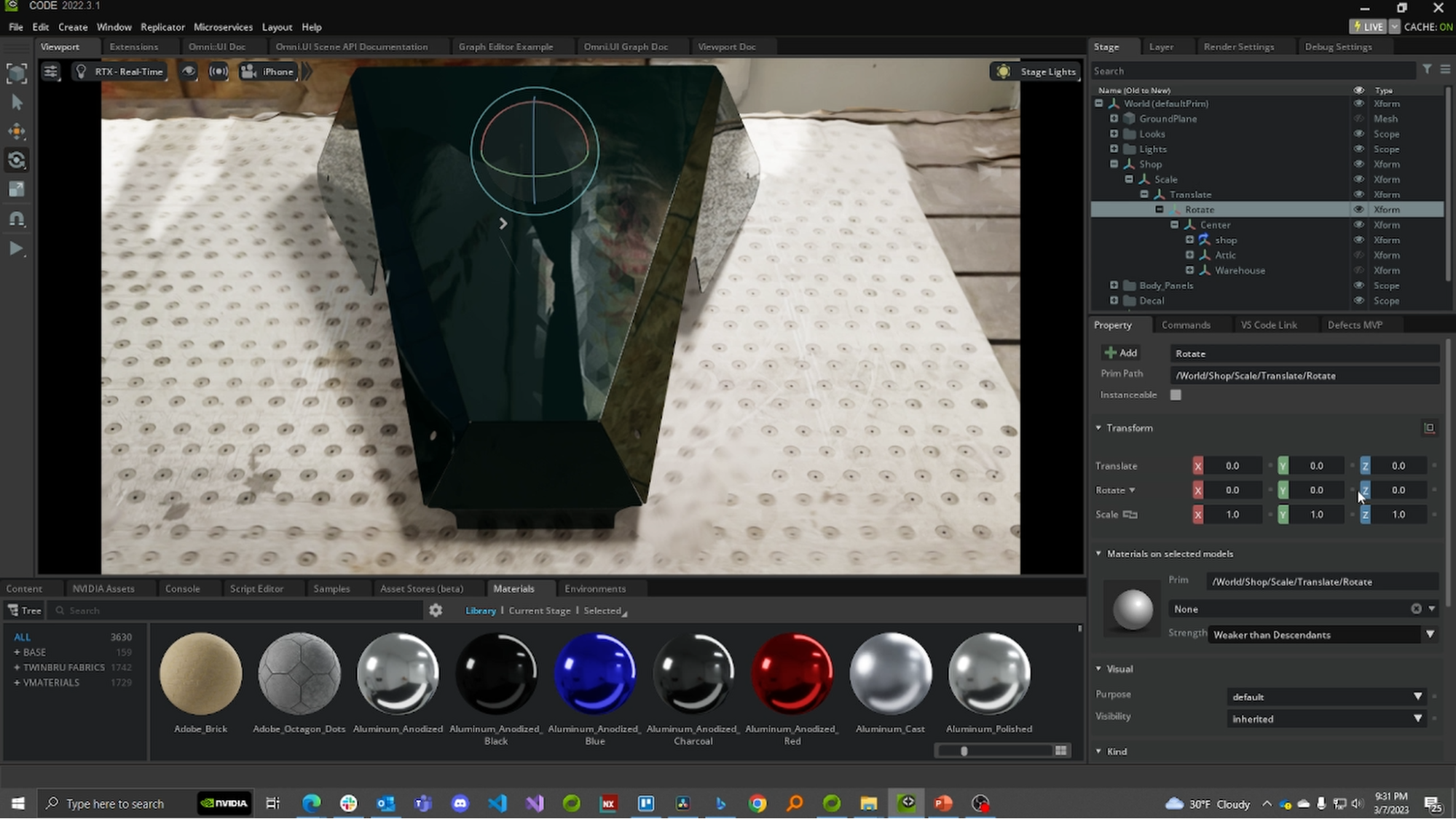
为了便于复制,我们将背景和 CAD 模型合并为 USD 场景,可在上下载Omniverse Exchange.
使用扩展来随机化划痕
为了为模型创建一组不同的训练数据,有必要生成各种合成划痕。本示例使用 Omniverse Kit 上构建的参考扩展来随机化划痕的位置、大小和旋转。有关更多详细信息,请访问NVIDIA-Omniverse/kit-extension-sample-defectsgen在 GitHub 上。
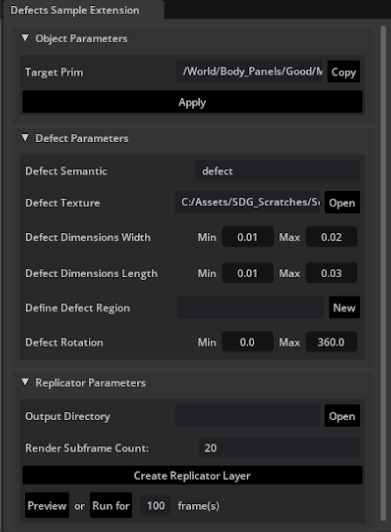
应该注意的是,该参考扩展是为了操作代理对象而构建的,该代理对象将法线贴图作为纹理投影到 CAD 零件的表面上。通过更改扩展中的参数,实际上是在更改投影纹理的立方体的大小和形状

在使用所需参数运行扩展后,输出将是一组带注释的参考图像,保存到文件夹中(可以通过扩展定义),作为. png 、. json 和. npy 文件。
模型培训和验证
Omniverse 扩展的输出是标准文件格式,可以与许多本地或基于云的模型训练平台一起使用,但custom writer可以被构建为格式化数据以与特定模型和平台一起使用
对于这个演示,我们构建了一个自定义的 COCO JSON 编写器,将输出引入Roboflow,一个基于浏览器的平台,用于训练和部署计算机视觉模型。
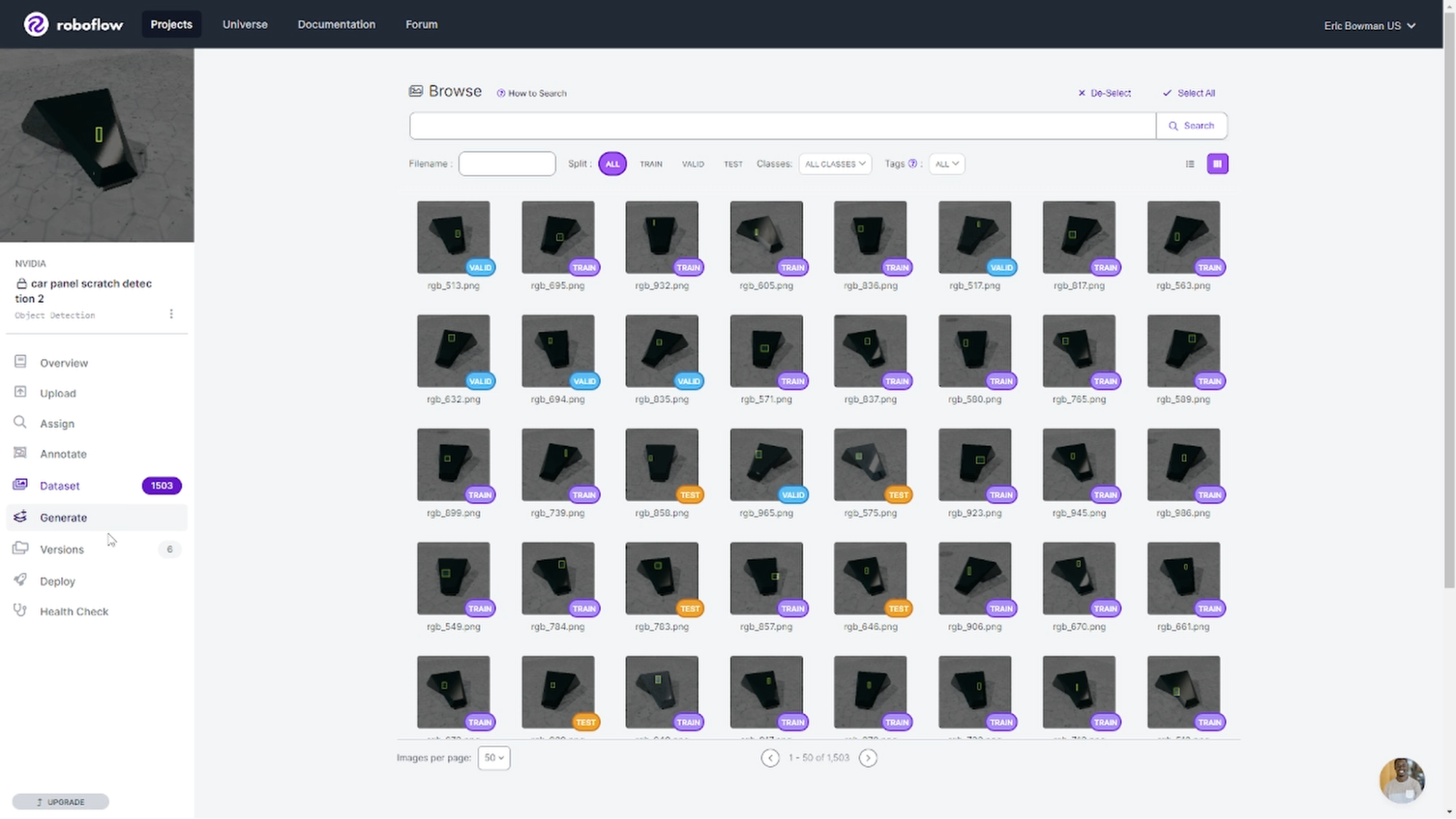
通过 Roboflow 用户界面,我们从一组 1000 张合成图像开始训练 YOLOv8 模型,该模型是根据其对象检测速度选择的。这只是了解模型如何使用此数据集的一个起点。考虑到模型训练是一个迭代过程,最好从小处着手,在每次迭代中提高数据集的大小和多样性

最初模型的结果很有希望,但并不完美(图 9 )。对初始模型的一些观察结果包括:
- 长划痕检测不好
- 捕捉到反光边缘
- 车间地板上的划痕也包括在内
解决这些问题的可能补救措施包括:
- 调整延伸参数以包括更长的划痕
- 在生成的场景中包括零件的更多角度
- 改变照明和背景场景
用地面实况图像增强合成数据是另一种策略。尽管 Replicator 中的文件是自动注释的,但我们使用 Roboflow 内置工具进行手动注释。
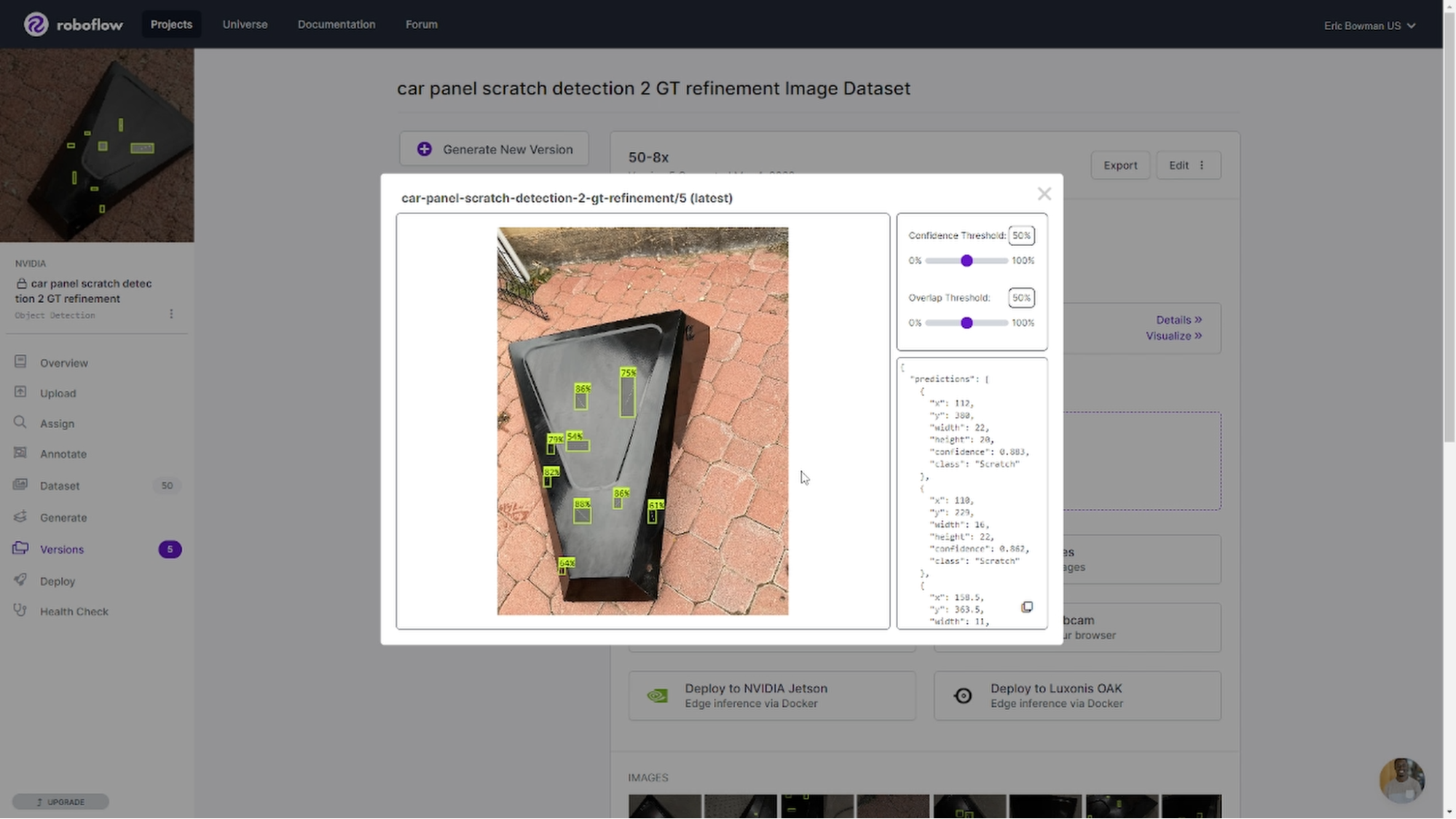
通过上面描述的一些调整,我们能够训练模型在每个验证图像上拾取更多的划痕,即使在更高的置信阈值下也是如此。
开始
在现实世界中,并不总是能够获得更多的地面实况图像。您可以使用NVIDIA Omniverse Replicator.
为了开始自己生成合成数据,下载 NVIDIA Omniverse.
你可以下载并安装来自 Github的参照插件和使用Omniverse Code探索工作流程。然后通过修改代码来构建您自己的缺陷检测生成工具。可以通过 Omniverse Exchange 上的缺陷检测演示包访问附带的 USD 文件和示例内容。有关扩展的其他技术详细信息,请参阅Omniverse Documentation.
下载标准许可证,开始使用 NVIDIA Omniverse,或学习如何Omniverse 企业版可以协助您的团队。如果你是一名开发人员,可以开始使用 Omniverse资源。