
今天,NVIDIA 宣布发布 Early Access ( EA )的 cuFFTMp 。 cuFFTMp 是 cuFFT 的多节点、多进程扩展,使科学家和工程师能够在 exascale 平台上解决具有挑战性的问题。
FFTs ( Fast Fourier Transforms )广泛应用于分子动力学、信号处理、计算流体力学( CFD )、无线多媒体和机器学习等领域。有了 cuFFTMp , NVIDIA 现在不仅支持单个系统中的多个 GPU ,还支持跨多个节点的多个 GPU 。
图 1 显示, cuFFTMp 达到 1.8 PFlop / s 以上,超过该规模转换峰值机器带宽的 70% 。
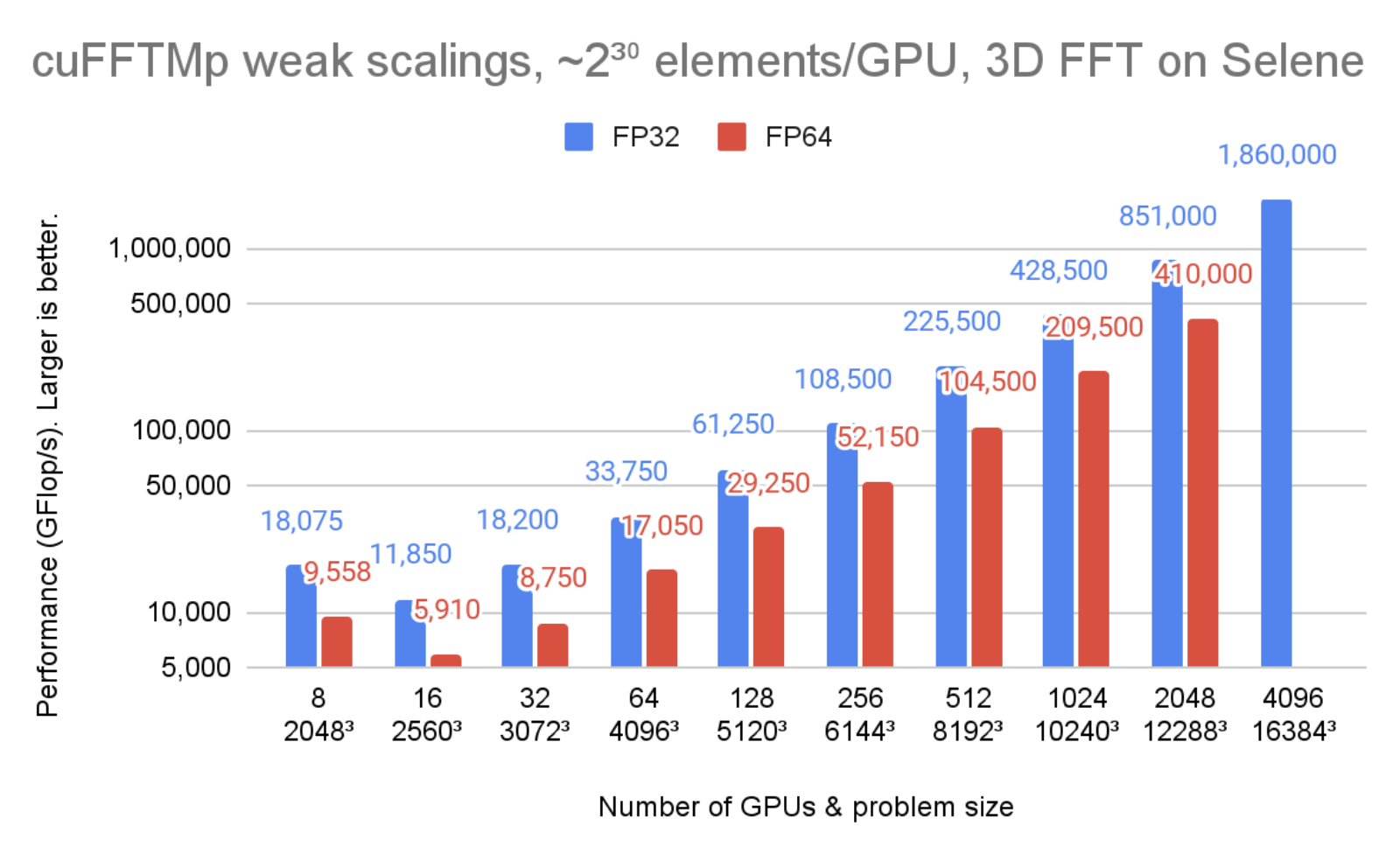
在图 2 中,问题大小保持不变,但 GPU 的数量从 8 增加到 2048 。可以看到, cuFFTMp 成功地扩展了问题,将单精度时间从 8 GPU ( 1 个节点)的 78ms 提高到 2048 GPU ( 256 个节点)的 4ms 。
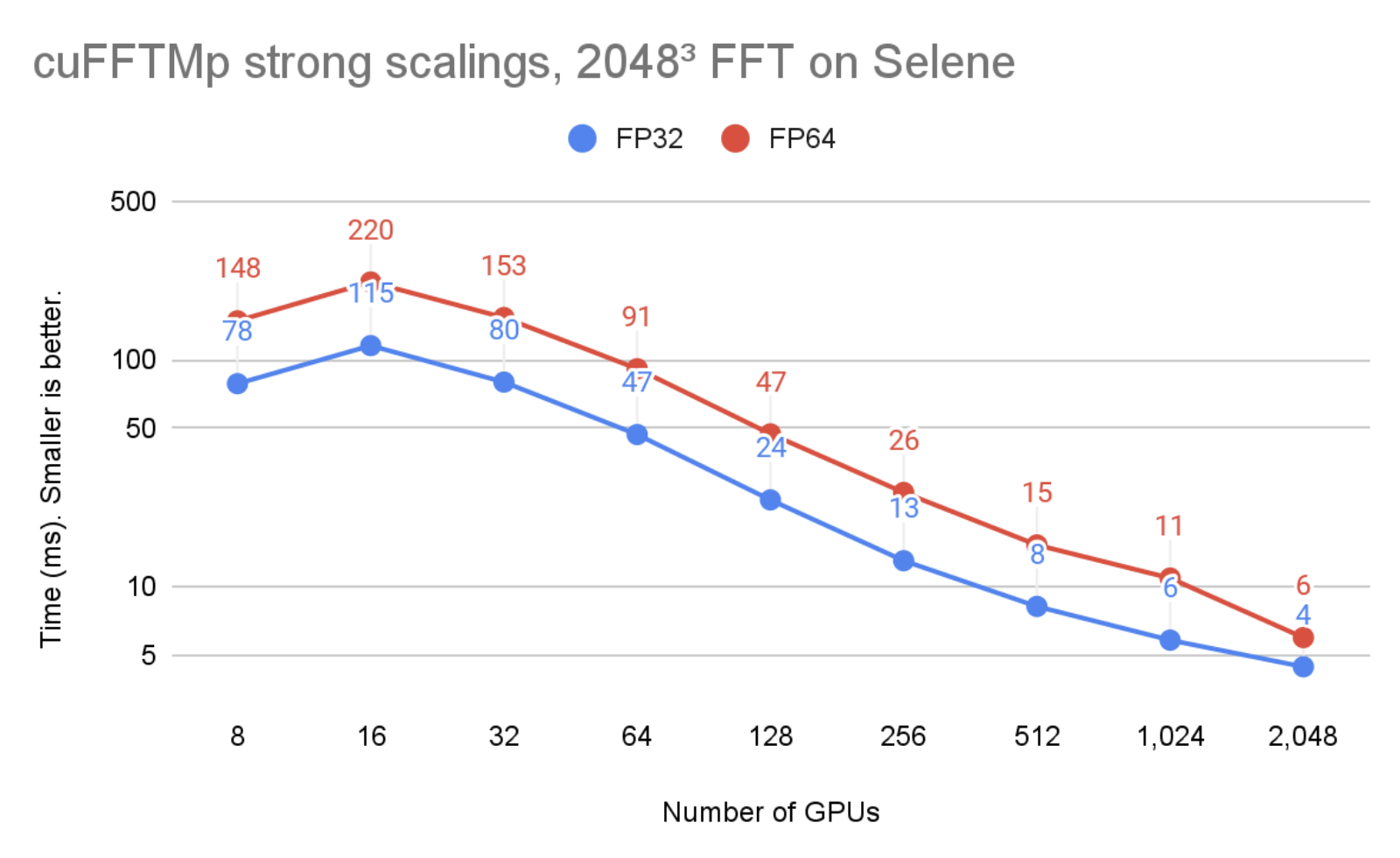
图 1 和图 2 在 Selene 集群上运行。 Selene 由 NVIDIA DGXA100 和 NVSwitch ( 300 GB / s / GPU ,双向)以及 Mellanox Infiniband HDR ( 200 GB / s / node ,双向)组成,每个节点 8xA100-80GB 。使用 nvcr 提供的 CUDA 11.4 和 NVIDIA HPC SDK 21.9 Docker 容器 进行测试。 io / NVIDIA / nvhpc:21.9-runtime-cuda11 。 4-ubuntu20 。 04.GPU 应用程序时钟设置为最大值。
性能和可扩展性
由于MPI_Alltoallv类型的全局集体通信,分布式 3D FFT 以通信受限而闻名。MPI_Alltoallv是分布式 FFT 的主要瓶颈,因为与高计算能力相比,节点间带宽较低,而且all_to_all类型通信的加速器感知 MPI 实现在质量上各不相同。
cuFFTMp 使用 NVSHMEM ,这是一个基于 OpenSHMEM 标准的新通信库,通过提供内核启动的通信,为 NVIDIA GPU 设计。 NVSHMEM 创建一个全局地址空间,其中包含集群中所有 GPU 的内存。从 CUDA 内核内部执行通信可以实现细粒度远程数据访问,从而降低同步成本,并利用 GPU 中的大规模并行性来隐藏通信开销。
通过使用 NVSHMEM , cuFFTMp 独立于 MPI 实现的质量,这是至关重要的,因为不同 MPI 的性能可能会有很大差异。有关更多信息,请参阅 关于高性能系统 FFT 库基准测试的中期报告。第三章 。
图 3 显示,随着 GPU 的数量增加一倍, cuFFTMp 能够保持大约 75% 的峰值。
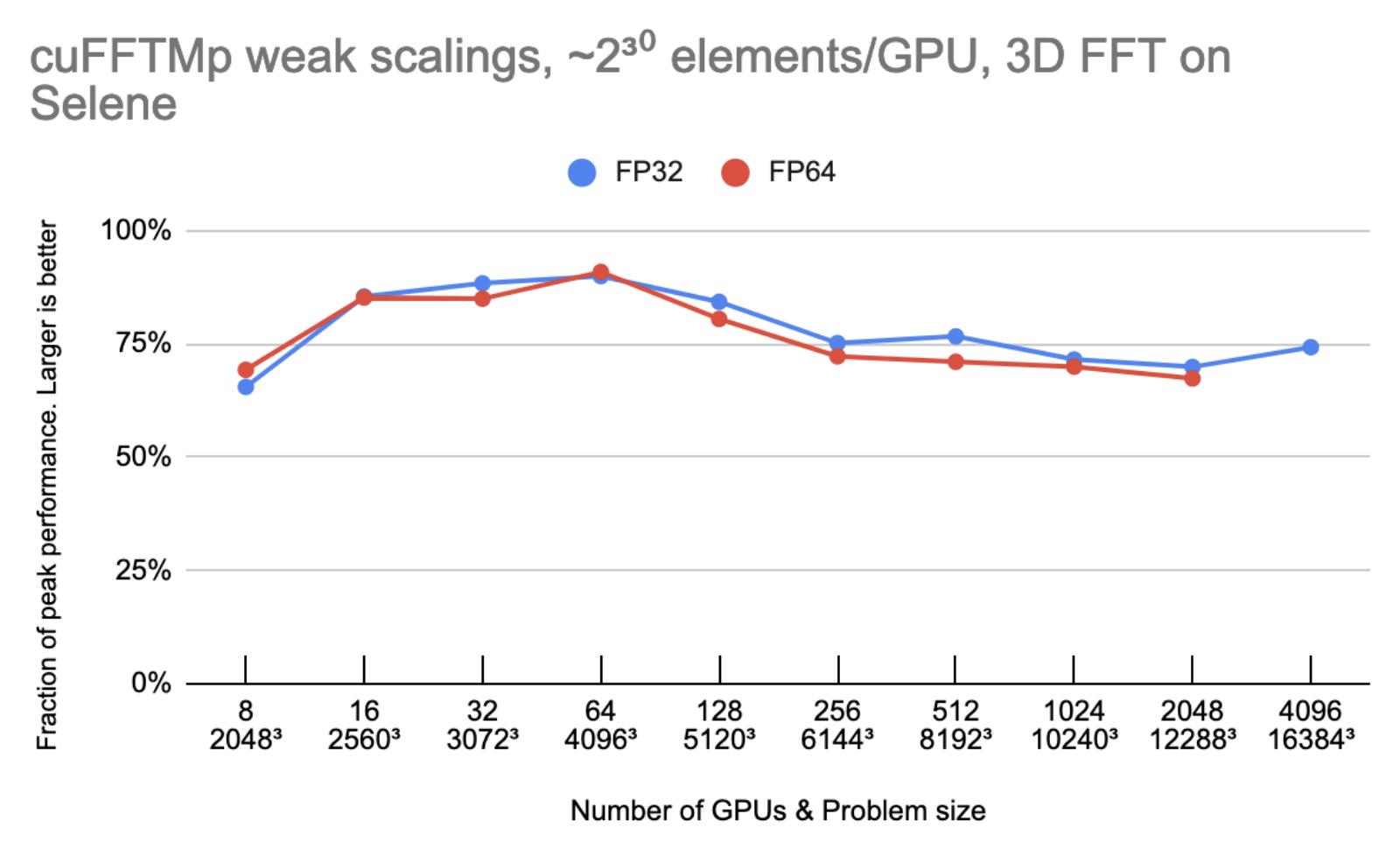
峰值性能是使用 2000 GB / s / GPU 的双向全局内存带宽, 300 GB / s / GPU 的双向 NVLink 带宽和 25 GB / s / GPU 的 Infiniband 带宽。
设 N 为 1D 变换大小, G 为 GPU 的个数。每个 GPU 都拥有 N 3/ G 元素(每个元素 8 或 16 字节),模型假设 N 3/ G 元素在全局内存中被读/写六次,并且 N 3 G 2元素从每个 GPU 发送一次到其他 GPU 。在 4096 GPU 上,非 InfiniBand 通信所花费的时间不到总时间的 10% 。
MPI 可移植性和多体系结构支持
如前所述, cuFFTMp 的性能不依赖于 MPI 实现。为了便于携带, cuFFTMp 要求启动 MPI ,并管理 CPU 上的数据分发。
目前, TMP 静态链接到 NVSHMEM 。 NVSHMEM 使用一个小型 MPI “引导插件”( NVSHMEM _ bootstrap _ MPI.so ),它是使用 MPI 构建的,并在运行时自动加载。此引导程序针对 HPC SDK 中包含的 OpenMPI 版本。对于依赖于另一个 MPI 实现的用户应用程序, EA 包包括帮助程序脚本,用于构建针对不同 MPI 的引导程序。
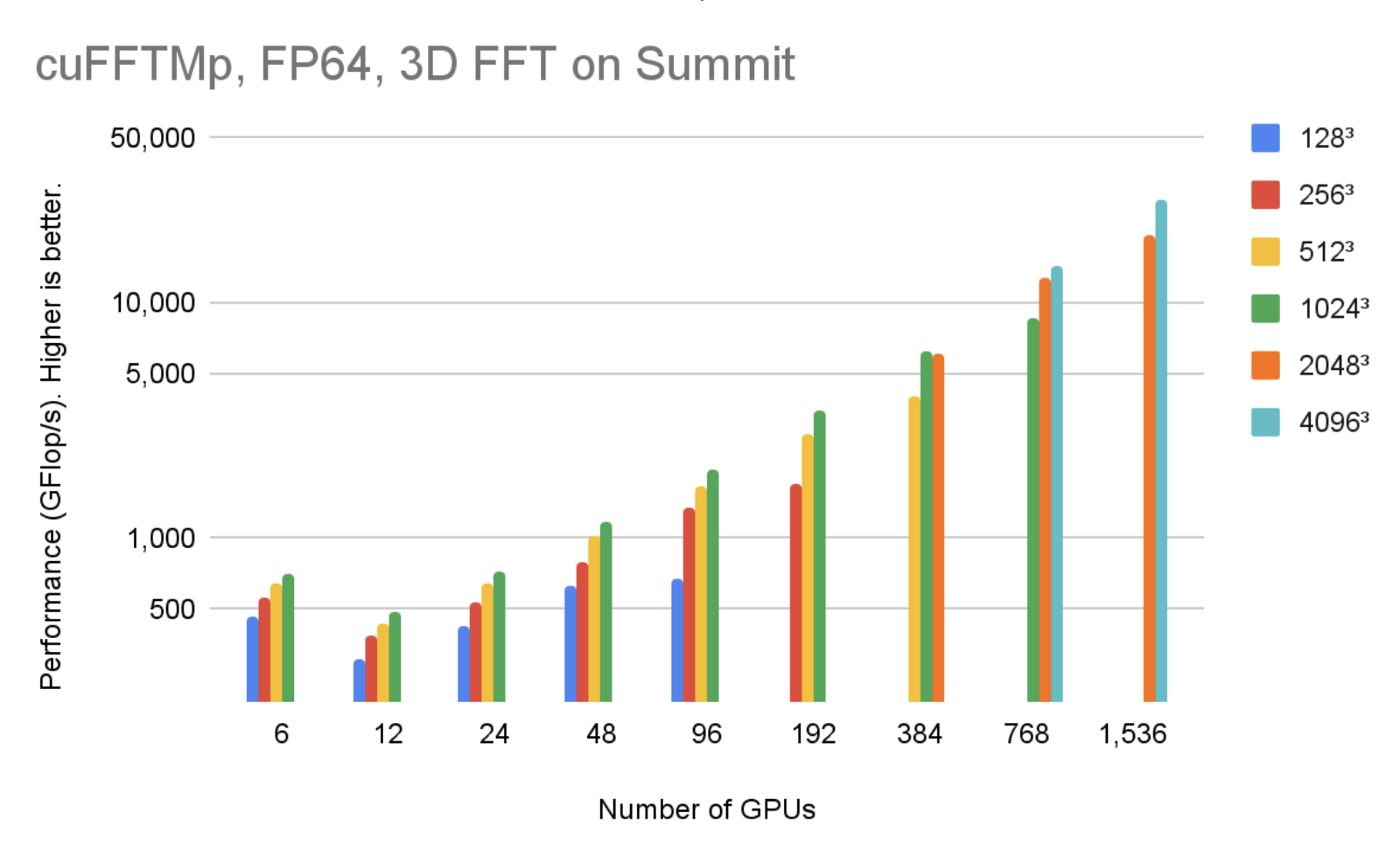
cuFFTMp 同时支持 Linux x86 _ 64 和 IBM POWER 体系结构。您可以下载不同体系结构的 EA 包。图 4 显示,在 256 个节点中使用 1536V100 GPU , cuFFTMp 可以达到 50Tflop / s 以上,转换 40963复杂的数据点,仅占 Summit 系统的 5% 。
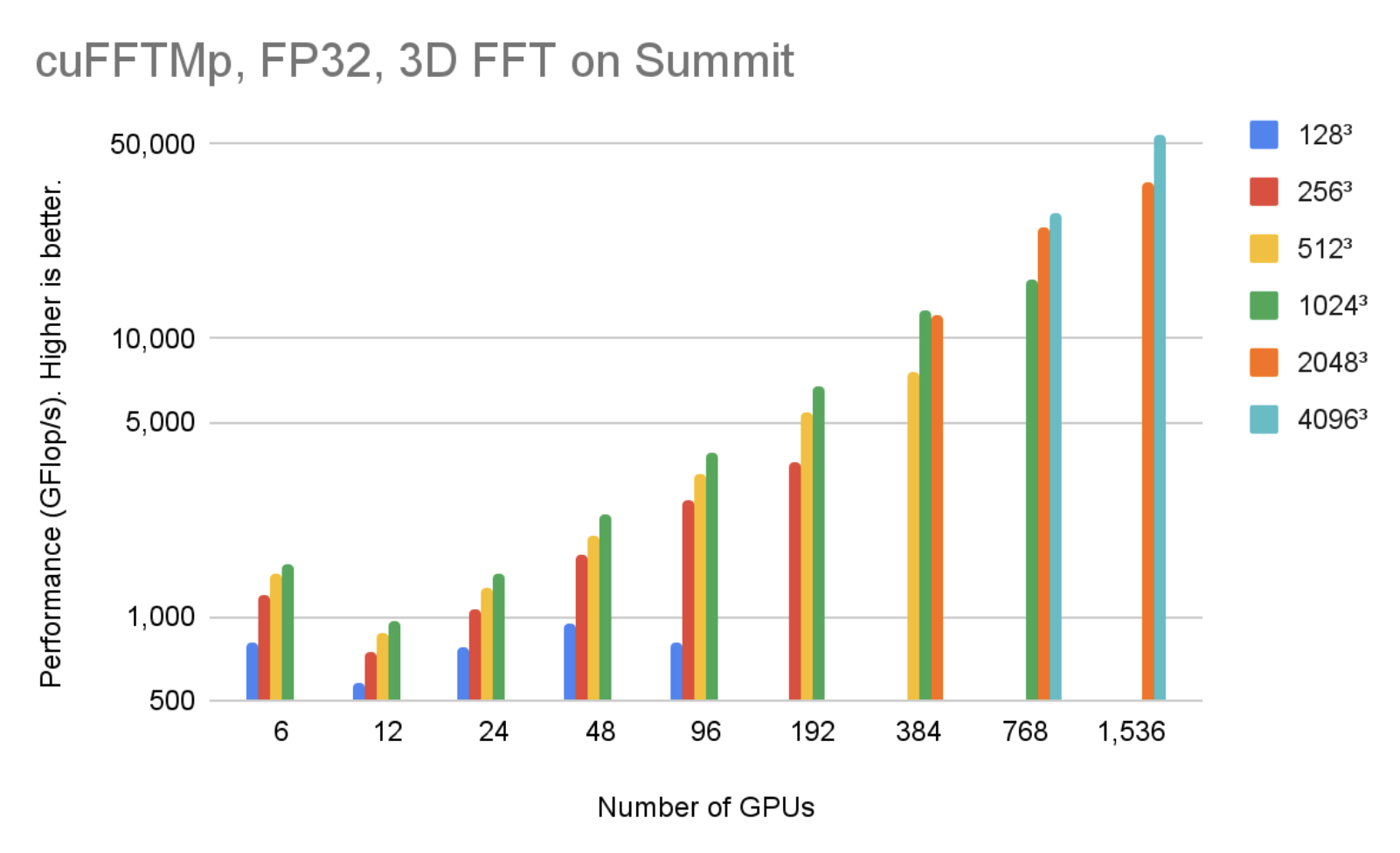
图 5 显示,在 256 个节点中使用 1536V100 GPU 时, cuFFTMp 可以达到 4096 个以上的 TFlop / s3复杂的数据点,仅占 Summit 系统的 5% 。
轻松过渡到 TMP
cuFFTMp 只是当前多 GPU cuFFT 库的扩展。大多数现有的多 GPU 函数适用于 TMP 。作为一个分布式多进程库, cuFFTMp 要求 MPI 被引导(“启动”),并期望数据分布在 MPI 进程之间。下表显示了将应用程序从使用 multi- GPU cuFFT 转换为 cuFFTMp 所需的代码。
| Multi-GPU, single-process cuFFT | cuFFTMp |
|---|---|
#include <cufftXt.h> |
#include <cufftMp.h> |
| // host buffer h_f size NX*NY*NZ | // host buffer h_f size my_NX*NY*NZ |
| cufftHandle plan_c2c; cufftCreate(&plan_c2c); |
|
|
for (auto i = 0; i < NGPUS; ++i) |
cufftMpAttachComm(plan, CUFFT_COMM_MPI, MPI_COMM_WORLD) |
|
size_t worksize; |
|
| MPI_Finalize(); | |
Slab 、 pencil 和 block 分解是多维 FFT 算法中用于跨节点并行计算的数据分布方法的典型名称。 cuFFTMp EA 仅支持优化的 slab ( 1D )分解,并提供辅助功能,例如 cufftXtSetDistribution 和 cufftMpReshape ,以帮助用户从任何其他数据分发重新分发到 cuFFTMp 的 slab 数据分发。
CufftMP EA 包包括 C ++和 Fortran 示例,覆盖了一系列用例: C2C 、 R2C / C2R 、不同的计划共享工作空间,以及从一个分布到另一个分布的数据或在 GPU 上重新分布。 cuFFTMp 使用 EA 包中包含的 HPC SDK 21.7 +编译器和包装器,为 Fortran 应用程序提供全面支持。
客户体验:湍流模拟
cuFFTMp 使科学家能够研究具有挑战性的流体湍流问题 物理学中最古老的悬而未决的问题 。
为了了解湍流行为,印度海得拉巴塔塔基础研究所( TFRI )的一个研究团队开发了 Fluid3D ,这是一个 CFD 软件包,使用伪谱方法对 Navier-Stokes 方程进行直接数值模拟( DNS )。通过将 Fluid3D 移植到 cuFFTMp 和 CUDA ,该团队现在可以在几个小时内模拟数千个 GPU 上更高的雷诺数流动,这是使用 MPI CPU 版本不可能完成的任务。
在图 6 中,湍流由不同尺度的漩涡组成,能量从大尺度的运动转移到小尺度。模拟和理解大型 DNS 运行中最小湍流结构的各向同性行为非常重要。

DNS 是提高对湍流理解的关键工具,伪谱方法因其计算效率和准确性而被广泛使用。
湍流模拟的挑战是需要获得高雷诺数( Re )。为了保持计算稳定性, Re 数受到网格分辨率的限制,即 Re 2.25 N 3,其中 N 是每个维度中的网格点数量。因此,模拟高 Re 数湍流需要数值分辨率,计算成本可能会很高,甚至会让人望而却步。
表 1 显示了最大 Re 数所需的网格分辨率以及模拟所需的内存。
| Grid resolution | Simulated Reynolds number | Memory requirement (GB) |
| 10243 | 199.2 | 88 |
| 20483 | 316.2 | 704 |
| 40963 | 501.9 | 5,632 |
| 81923 | 796.8 | 45,056 |
| 122883 | 1044.1 | 152,064 |
| 163843 | 1264.8 | 360,448 |
Fluid3D 在傅里叶空间中使用二阶指数时间步进法。模拟通常集成在数万个时间步上,每个时间步计算九个 3D FFT 。 FFT 主导整个仿真运行时。每个时间步长的壁面时间是衡量数值实验特定结构的求解时间是否合理的一个重要指标。
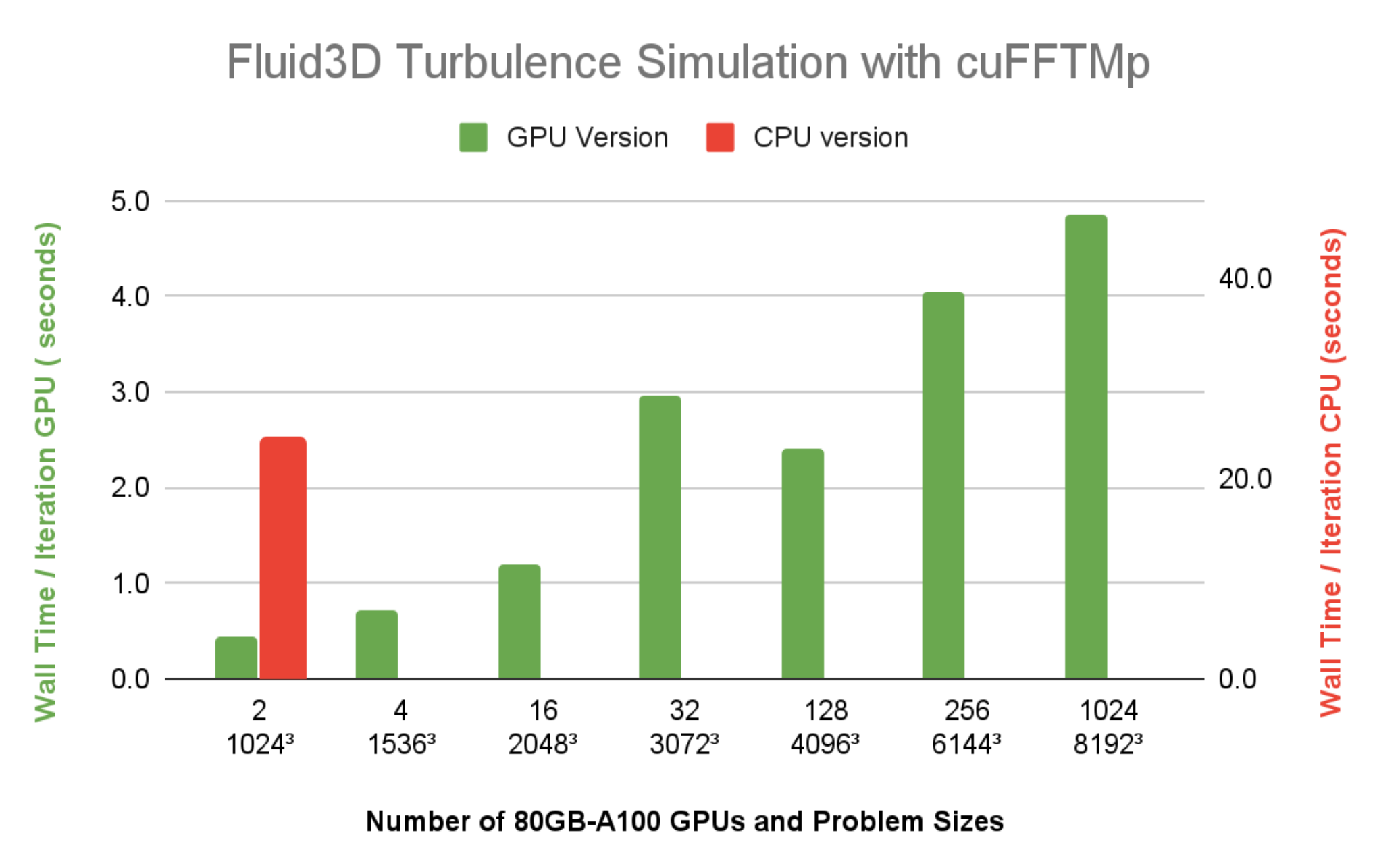
图 7 显示了 Fluid3D 的每个时间步的壁时间小于 5 秒,分辨率为 81923,在 Selene 上使用 1024 个 A100 GPU ( 128 个节点)。带有 FFTW-MPI 的 CPU 版本,每次迭代需要 23.9 秒,分辨率为 10243在单个 64 核 CPU 节点上使用 64 MPI 列组的问题大小。与同样 1024 小时的墙时间相比3问题大小使用两个 A100 GPU ,很明显 Fluid3D 从 CPU 节点到单个 A100 的加速比超过 20 倍。
开始使用 cuFFTMp
有兴趣尝试使用 cuFFTMp 将应用程序转换为在多个节点上运行吗?请转到 cuFFTMp EA 的入门页面。下载 cuFFTMp 后,玩一下示例代码,看看它们与 multi- GPU 版本有多相似,以及它们如何在多个节点上扩展。
我们继续致力于改进 cuFFTMp ,包括添加批处理 API ,以及数据压缩以最小化通信。如果您有任何问题或新功能请求,请联系产品经理 Matthew Nicely 。
致谢
特别感谢印度海得拉巴塔塔基础研究所的 Prasad Perlekar 团队为我们提供多相湍流代码 Fluid3D ,并成为 cuFFTMp 的第一个采用者。
我们还感谢 NVIDIA 的整个 NVSHMEM 团队对 cuFFTMp 开发的支持。