
数字生成的生成式 AI 采用率一直很高。在 2022 年推出 OpenAI 聊天 GPT 的推动下,这项新技术在几个月内积累了超过 1 亿用户,几乎推动了各行各业的开发活动激增。
到 2023 年,开发者开始使用 Meta、Mistral、Stability 等公司的 API 和开源社区模型创建 POC。
进入 2024 年后,企业组织正将注意力转向大规模生产部署,其中包括将 AI 模型连接到现有企业基础设施、优化系统延迟和吞吐量、日志记录、监控和安全性等。这种生产路径既复杂又耗时,需要专门的技能、平台和流程,尤其是大规模部署。
NVIDIA NIM 是 NVIDIA AI Enterprise 的一部分,为开发 AI 驱动的企业应用程序和在生产中部署 AI 模型提供了简化的路径。
NIM 是一套经过优化的云原生微服务,旨在缩短上市时间,并简化生成式 AI 模型在云、数据中心和 GPU 加速工作站的任何位置的部署。它使用行业标准 API,抽象化 AI 模型开发和生产包装的复杂性,从而扩展开发者池。
用于优化 AI 推理的 NVIDIA NIM
NVIDIA NIM 旨在弥合复杂的 AI 开发环境与企业环境的运营需求之间的差距,使 10 到 100 倍的企业应用开发者能够为其公司的 AI 转型做出贡献。
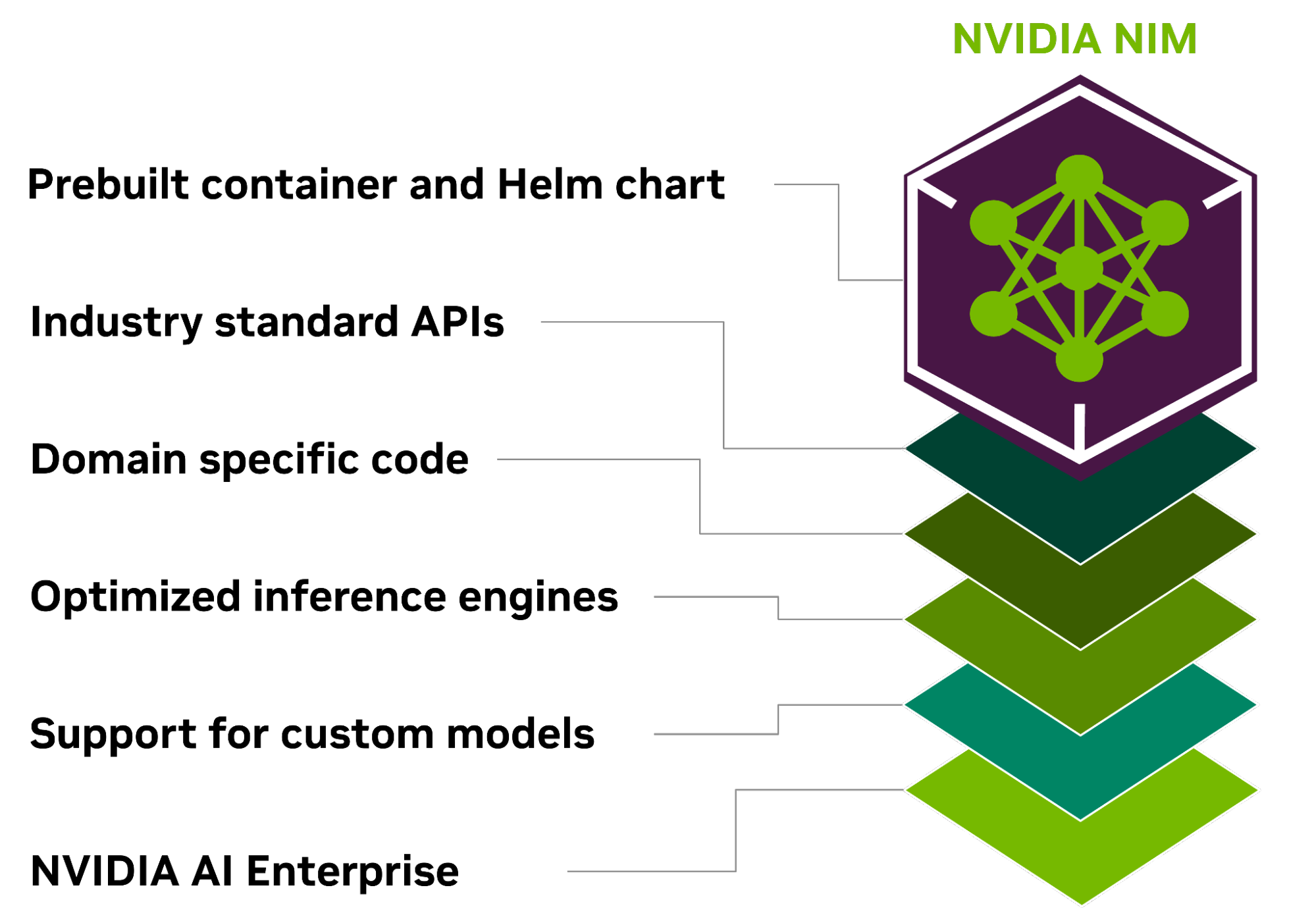
NIM 的一些核心优势包括以下内容。
随时随地部署
NIM 专为可移植性和可控性而构建,支持跨各种基础设施 (从本地工作站到云再到本地数据中心) 进行模型部署。其中包括 NVIDIA DGX、 NVIDIA DGX 云、 NVIDIA 认证系统、 NVIDIA RTX 工作站和 PC。
预构建的容器和 Helm Chart 打包了优化模型,并在不同的 NVIDIA 硬件平台、云服务提供商和 Kubernetes 发行版中进行了严格验证和基准测试。这支持所有 NVIDIA 驱动的环境,并确保组织可以在任何地方部署其生成式 AI 应用,同时保持对其应用及其处理的数据的全面控制。
使用行业标准 API 进行开发
开发者可以通过符合每个领域行业标准的 API 访问 AI 模型,从而简化 AI 应用的开发。这些 API 与生态系统中的标准部署流程兼容,使开发者能够快速更新其 AI 应用 (通常只需 3 行代码)。这种无缝集成和易用性有助于在企业环境中快速部署和扩展 AI 解决方案。
利用特定领域的模型
NIM 还通过几个关键功能满足了对特定领域解决方案和优化性能的需求。它包含特定于领域的 NVIDIA CUDA 库,以及为语言、语音、视频处理、医疗健康等各个领域量身定制的专用代码。这种方法可确保应用程序准确无误并与其特定用例相关。
在优化的推理引擎上运行
NIM 针对每个模型和硬件设置利用经过优化的推理引擎,在加速基础设施上提供尽可能好的延迟和吞吐量。这降低了在扩展推理工作负载时运行推理工作负载的成本,并改善了最终用户体验。除了支持优化的社区模型外,开发者还可以通过使用从未离开数据中心边界的专有数据源对模型进行对齐和微调,从而实现更高的准确性和性能。
支持企业级 AI
作为 NVIDIA AI Enterprise 的一部分,NIM 采用企业级基础容器构建,通过功能分支、严格的验证、通过服务级别协议提供的企业级支持以及针对 CVE 的定期安全更新,为企业 AI 软件提供坚实的基础。全面的支持结构和优化功能突出了 NIM 作为在生产环境中部署高效、可扩展和定制的 AI 应用的关键工具的作用。
加速 AI 模型随时可供部署
支持多种 AI 模型,包括社区模型 NVIDIA AI 基础模型 和 NVIDIA 合作伙伴提供的定制 AI 模型。NIM 支持跨多个领域的 AI 用例,包括 大型语言模型 (LLM)、视觉语言模型 (VLM),以及用于语音、图像、视频、3D、药物研发、医学成像等的模型。
开发者可以使用 NVIDIA 托管的云 API 测试新的生成式 AI 模型,或者通过下载 NIM 来自行托管模型,并在主要云提供商或本地使用 Kubernetes 快速部署,以减少开发时间、复杂性和成本。
NIM 微服务通过打包算法、系统和运行时优化并添加行业标准 API 来简化 AI 模型部署流程。这使开发者能够将 NIM 集成到其现有应用程序和基础设施中,而无需大量定制或专业知识。
借助 NIM,企业可以优化其 AI 基础架构,以更大限度地提高效率和成本效益,而无需担心 AI 模型开发的复杂性和容器化。在加速 AI 基础架构的基础上,NIM 有助于提高性能和可扩展性,同时降低硬件和运营成本。
对于希望为企业应用程序定制模型的企业,NVIDIA 提供微服务,以便跨不同领域定制模型。NVIDIA NeMo 使用专有数据为 LLM、语音 AI 和多模态模型提供微调功能。NVIDIA BioNeMo 通过越来越多的生成生物学化学和分子预测模型集合加速药物研发。NVIDIA Picasso 通过 Edify 模型实现更快的创意工作流程。这些模型在视觉内容提供商的许可库中进行训练,从而能够部署自定义的生成式 AI 模型,以创建视觉内容。
NVIDIA NIM 入门
NVIDIA NIM 入门非常简单。在 NVIDIA API 目录,开发者可以访问各种 AI 模型,这些模型可用于构建和部署自己的 AI 应用。
通过图形用户界面直接在目录中开始原型设计,或直接与 API 免费交互。要在基础设施上部署微服务,只需注册 NVIDIA AI Enterprise 90 天评估许可证,并按照以下步骤操作。
- 从 NVIDIA NGC 下载要部署的模型。在本示例中,我们将下载为单个 A100 GPU 构建的 Lama-2 7B 模型版本。
ngc registry model download-version "ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01"如果您使用的是其他 GPU,则可以使用 ngc 注册表模型列表“ohlfw0olaadg/ea-participants/llama-2 -7b:”列出模型的可用版本
2.将下载的构件解压到模型库中:
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gz
3.使用所需模型启动 NIM 容器:
docker run --gpus all --shm-size 1G -v $(pwd)/model-store:/model-store --net=host nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01 nemollm_inference_ms --model llama-2-7b --num_gpus=14.部署 NIM 后,您可以开始使用标准 REST API 发出请求:
import requests
endpoint = 'http://localhost:9999/v1/completions'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
'model': 'llama-2-7b',
'prompt': "The capital of France is called",
'max_tokens': 100,
'temperature': 0.7,
'n': 1,
'stream': False,
'stop': 'string',
'frequency_penalty': 0.0
}
response = requests.post(endpoint, headers=headers, json=data)
print(response.json())
NVIDIA NIM 是一款功能强大的工具,可以帮助组织加速生产级 AI 之旅。立即开始您的 AI 之旅。