
大型语言模型 (LLM) 在理解和生成类似人类的响应方面具有前所未有的能力,这给世界留下了深刻的印象。它们的聊天功能在人类和大型数据语料库之间提供了快速且自然的交互。例如,它们可以从数据中总结和提取亮点,或者用自然语言替换 SQL 查询等复杂查询。
虽然假设这些模型可以轻松地创造商业价值非常吸引人,但遗憾的是现实并非总是这样。幸运的是,企业可以通过使用自己的数据来增强大型语言模型(LLM),从而从中提取价值。这可以通过检索增强生成(RAG)来实现,正如 NVIDIA 生成式 AI 示例 在面向开发者的 GitHub 库中所展示的。
通过使用业务数据增强 LLM,企业可以提高其 AI 应用的敏捷性并响应新的开发。例如:
- 聊天机器人:许多企业已经在其网站上使用 AI 聊天机器人来支持基本的客户互动。通过 RAG,公司能够构建高度针对其产品的聊天体验。例如,可以轻松回答有关产品规格的问题。
- 客户服务:公司可以授权实时服务代表使用准确、最新的信息轻松回答客户问题。
- 企业搜索:企业在整个组织内拥有丰富的知识资源,包括技术文档、公司政策、IT 支持文章和代码库。员工可以通过查询内部搜索引擎,以更快、更高效的方式检索信息。
本文介绍了在构建 LLM 应用时使用 RAG 技术的好处,以及 RAG 工作流的组成部分。阅读完本文后,欢迎参阅RAG 101:检索增强型生成问题的解答。
RAG 的优势
使用 RAG 有几个优势:
- 通过实时数据访问为 LLM 解决方案提供支持
- 保护数据隐私
- 减轻 LLM 的幻觉
通过实时数据访问为 LLM 解决方案提供支持
企业中的数据不断变化。使用 LLM 的 AI 解决方案可以通过 RAG 保持最新状态,这有助于直接访问其他数据资源。这些资源可以由实时和个性化数据组成。
保护数据隐私
确保数据隐私对于企业至关重要。借助自托管 LLM (在 RAG 工作流程中演示),敏感数据可以像存储数据一样保存在本地。
减轻 LLM 的幻觉
当 LLM 未提供真实的实际信息时,它们通常会提供错误但令人信服的响应。这称为幻觉RAG 通过为 LLM 提供相关和派系信息来降低产生幻觉的可能性。
构建和部署首个 RAG 工作流
典型的 RAG 流程由几个阶段组成。文档提取过程离线进行,当输入在线查询时,会检索相关文档并生成响应。
图 1 展示了可以在数据中心构建和部署的加速 RAG 工作流,详情请参见 NVIDIA Generative AI Examples GitHub 库。
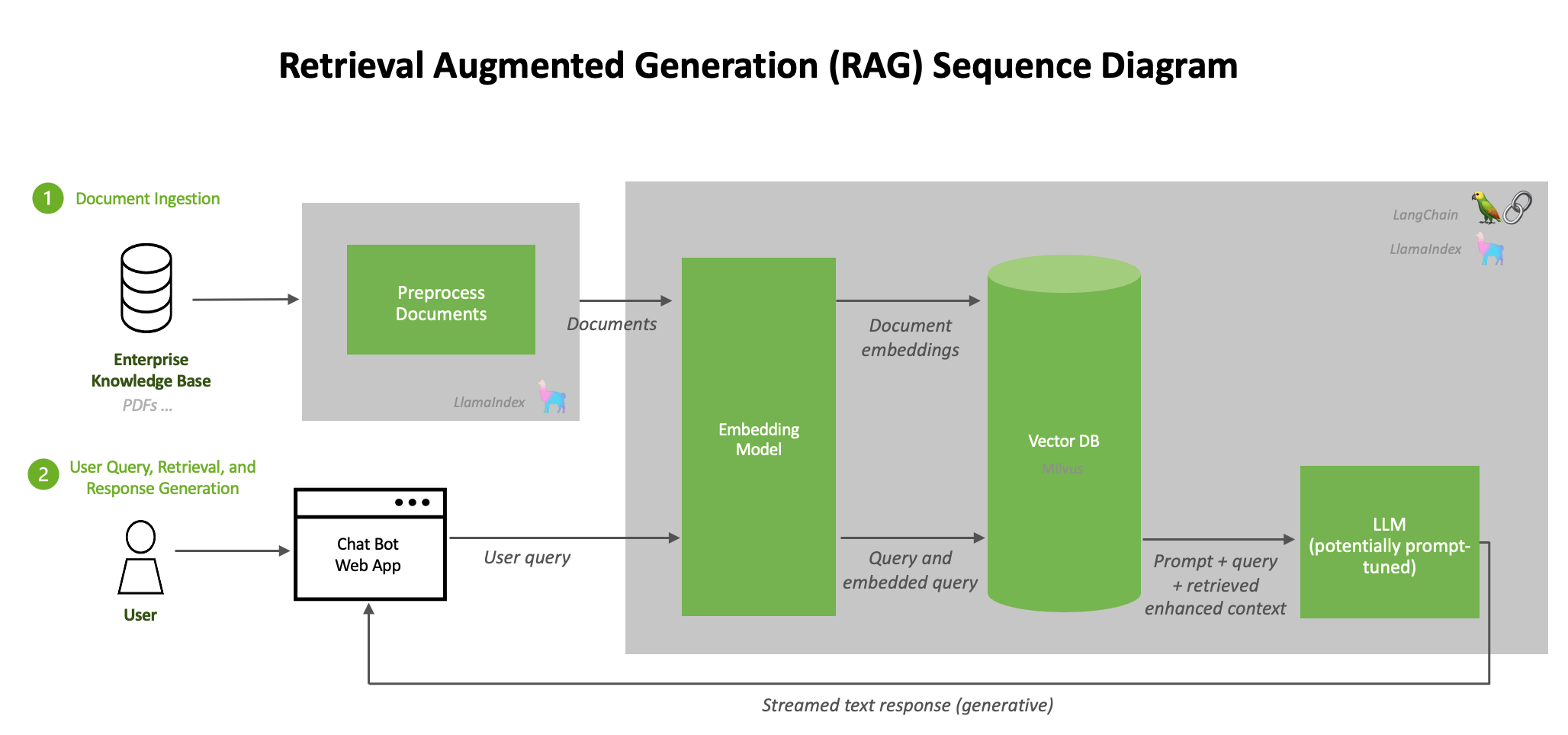
每个逻辑微服务都被分割成多个容器,并托管在 NGC 的公共目录中。从更高层次上讲,RAG 系统的架构可以概括为图 1 所示的流程:
- 文档预处理、提取和嵌入生成的循环流程
- 包含用户查询和响应生成的推理工作流
文档提取
首先,来自不同来源(例如数据库、文档或实时 Feed)的原始数据被提取到 RAG 系统中。为了对这些数据进行预处理,LangChain 提供了各种文档加载器,以加载来自许多不同来源的多种形式的数据。
术语文档加载器的使用可能会引起误解。源文档并不局限于您可能想到的标准文档类型(如 PDF、文本文件等)。例如,LangChain 支持从 Confluence、CSV 文件、Outlook 电子邮件等多种来源加载文档,详情请参见更多信息。LlamaIndex 也提供了多种文档加载器,您可以在LlamaHub上找到它们。
文档预处理
文档加载完成后,通常会进行转换。一种转换方法是文本分割,它将长文本分解为较小的片段。这对于将文本拟合到嵌入模型中非常必要,例如 e5-large-v2 的最大令牌长度为 512。虽然分割文本听起来很简单,但这可能是一个细致入微的过程。
生成嵌入
提取数据时,必须将其转换为系统可以高效处理的格式。生成嵌入需要将数据转换为高维向量,以数字格式表示文本。
将嵌入存储在向量数据库中
已处理的数据和生成的嵌入被存储在专门的数据库中,称为向量数据库。这些数据库针对处理向量化数据进行了优化,以实现快速的搜索和检索操作。将数据存储在如 RAPIDS RAFT 加速的向量数据库 和 Milvus 中,可以保证信息的可访问性,并实现 实时交互中的快速检索。
LLM
LLM 是 RAG 流程的基础生成组件。这些先进的通用语言模型基于庞大的数据集进行训练,使它们能够理解和生成类似人类的文本。在 RAG 环境中,LLM 用于根据用户查询和用户查询期间从向量数据库检索的上下文信息生成完全形成的响应。
查询
当用户提交查询时,RAG 系统使用索引数据和向量执行高效搜索。系统通过比较查询向量与向量数据库中存储的向量来识别相关信息。然后,LLM 使用检索到的数据制定适当的响应。
通过测试此示例工作流程,您可以快速部署此系统,详情请访问 NVIDIA/GenerativeAIExamples GitHub 库。
开始在企业中构建 RAG
通过使用 RAG,您可以轻松为 LLM 提供最新的专有信息,并构建一个能够提高用户信任度、改善用户体验和减少幻觉的系统。
探索 NVIDIA AI 聊天机器人 RAG 工作流程,开始构建能够利用最新信息,以自然语言准确回答特定领域问题的聊天机器人。