
这是标准并行编程系列的第四篇文章,旨在指导开发人员在标准语言中使用并行来加速计算的优势:
标准语言已经开始添加编译器可用于加速 GPU 和 CPU 并行编程的功能,例如 Fortran 中的do concurrent循环和数组数学内部函数。
使用标准语言特性有许多优点,主要优点是未来的可验证性。由于 Fortran 的do concurrent是一种标准语言功能,因此将来失去支持的可能性很小。
这个特性在初始代码开发中使用起来也相对简单,并且增加了可移植性和并行性。在初始代码开发中使用do concurrent有助于鼓励您在编写和实现循环时从一开始就考虑并行性。
对于初始代码开发,do concurrent是添加 GPU 支持的好方法,无需学习指令。然而,即使是已经通过使用 OpenACC 和 OpenMP 等指令进行 GPU 加速的代码,也可以从重构到标准并行性中获益,原因如下:
- 为那些不懂指令的人清理代码,或者删除大量使源代码分心的指令。
- 在供应商支持和支持寿命方面提高代码的可移植性。
- 该代码经得起未来考验,因为 ISO 标准语言在稳定性和可移植性方面有着可靠的记录。
替换多核 CPU 和 GPU 上的指令
POT3D 是一个 Fortran 代码,它使用表面场观测值作为输入,计算势场解以近似太阳日冕磁场。它继续被用于日冕结构和动力学的大量研究。
该代码使用 MPI 进行高度并行化,并使用 MPI 和 OpenACC 进行 GPU 加速。 它是开源的,在 GitHub 上可用 。它也是 SPEHPC 2021 基准套件 的一部分。
我们最近于 2021 于 WACCPD 举办了 使用 do concurrent 重构了另一个代码示例 。结果表明,可以用do concurrent替换指令,而不会损失多核 CPU 和 GPU 上的性能。然而,该代码有点简单,因为没有 MPI 。
现在,我们想探索在更复杂的代码中替换指令。 POT3D 包含标准 Fortran 并行处理的重要功能:缩减、原子、 CUDA-aware MPI 和本地堆栈数组。我们想看看do concurrent 是否可以替换指令并保持相同的性能。
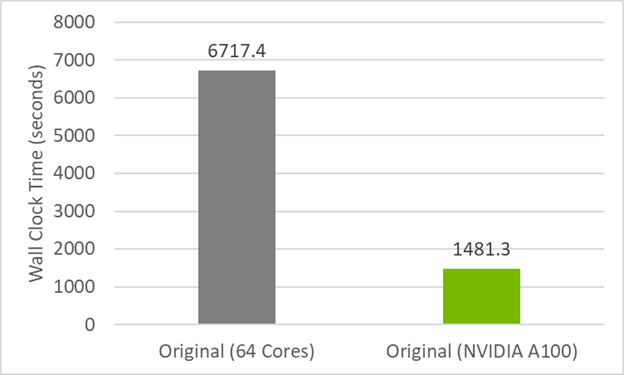
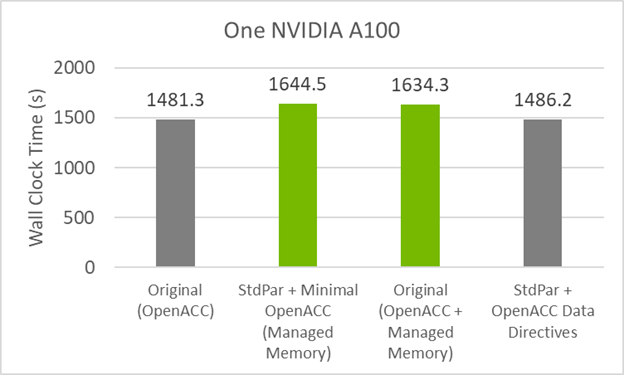
为了建立将代码重构为do concurrent的性能基线,首先查看图 1 中原始代码的初始计时。 CPU 结果在双插槽 AMD EPYC 7742 服务器上的 64 个 MPI 列组(每个插槽 32 个)上运行,而 GPU 结果在 NVIDIA A100 ( 40GB )服务器上的一个 MPI 列组上运行。 GPU 代码依赖于数据传输的数据移动指令(此处不使用托管内存),并使用 -acc=gpu -gpu=cc80、cuda11.5编译。运行时间是四次运行的平均值。
以下突出显示的文本显示了当前版本代码的代码行数和指令。您可以看到有 80 条指令,但我们希望通过使用do concurrent重构来减少这一数字。
| POT3D (Original) | |
| Fortran | 3,487 |
| Comments | 3,452 |
| OpenACC Directives | 80 |
| Total | 7,019 |
执行并发和 OpenACC
以下是一些与代码 POT3D 中的 OpenACC 相比的do concurrent 示例,例如三层嵌套的 OpenACC 并行循环:
!$acc enter data copyin(phi,dr_i)
!$acc enter data create(br)
…
!$acc parallel loop default(present) collapse(3) async(1)
do k=1,np do j=1,nt do i=1,nrm1 br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k))*dr_i(i) enddo enddo
enddo
…
!$acc wait
!$acc exit data delete(phi,dr_i,br)如前所述,此 OpenACC 代码使用标志-acc=gpu -gpu=cc80、cuda11.5进行编译,以在 NVIDIA GPU 上运行。
您可以使用 do concurrent 并行化这个相同的循环,并依赖于 NVIDIA CUDA 统一内存 用于数据移动,而不是指令。这将产生以下代码:
do concurrent (k=1:np,j=1:nt,i=1:nrm1) br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k ))*dr_i(i)
enddo如您所见,循环已从 12 行压缩为 3 行,而 CPU 中的 nvfortran 编译器保留了 CPU 的可移植性和 HPC SDK NVIDIA 的并行性
行数的减少得益于将多个循环压缩为一个循环,并依赖于托管内存,这将删除所有数据移动指令。使用cuda11.5、cuda11.5为 GPU 编译此代码。
对于 nvfortran ,激活标准并行(-stdpar=gpu)会自动激活托管内存。要使用 OpenACC 指令和do concurrent控制数据移动,请使用以下标志:-acc=gpu -gpu=nomanaged。
do concurrent 的 nvfortran 实现还允许定义变量的位置:
do concurrent (k=1:N, j(i)>0) local(M) shared(J,K) M = mod(K(i), J(i)) K(i) = K(i)- M
enddo这对于某些代码可能是必要的。对于 POT3D ,变量的默认位置将根据需要执行。默认位置与使用 nvfortran 的 OpenACC 相同。
并行执行 CPU 性能和 GPU 实现
用do concurrent 替换所有 OpenACC 循环,并依靠托管内存进行数据移动,这会导致代码中的指令为零,行数更少。我们删除了 80 条指令和 66 行 Fortran 。
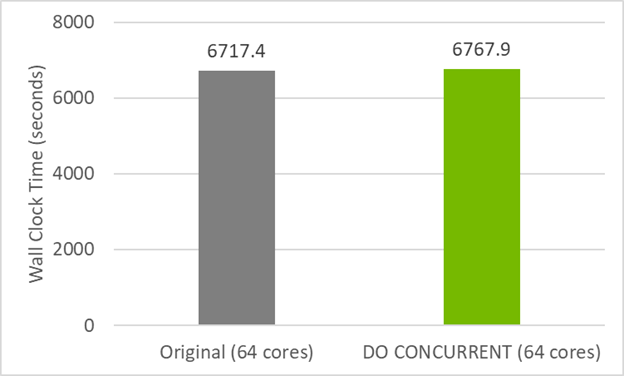
图 2 显示了此代码的do concurrent 版本在 CPU 上的性能与原始 GitHub 代码几乎相同。这意味着您没有通过使用 do concurrent 破坏 CPU 兼容性。相反,还添加了多核并行,可以通过使用标志-stdpar=multicore进行编译来使用。
与 CPU 不同,要在 GPU 上运行 POT3D ,必须添加几个指令。
首先,要利用 MPI 的多个 GPU ,需要一个指令来指定 GPU 设备编号。否则,所有 MPI 级别将使用相同的 GPU 。
!$acc set device_num(mpi_shared_rank_num)在本例中,mpi_shared_rank_num是节点内的 MPI 等级。假设启动代码时,每个节点的 MPI 列组数与每个节点的 GPU 数相同。这也可以通过为每个 MPI 列组设置CUDA_VISIBLE_DEVICES来实现,但我们更喜欢通过编程实现。
将托管内存与多个 GPU 一起使用时,请确保在分配任何数据之前完成设备选择(如!$acc set device_num(N))。否则,将创建额外的 CUDA 上下文,从而引入额外的开销。
目前, nvfortran 编译器不支持并行循环上的数组缩减,这在代码的两个位置都是必需的。幸运的是,可以使用 OpenACC 原子指令代替数组缩减:
do concurrent (k=2:npm1,i=1:nr)
!$acc atomic sum0(i)=sum0(i)+x(i,2,k)*dph(k )*pl_i
enddo添加此指令后,使用-stdpar=gpu -acc=gpu -gpu=cc80、cuda11.5更改编译器选项以显式启用 OpenACC 。这只允许您使用三条 OpenACC 指令。这是该代码目前最接近没有指令的情况。
所有数据移动指令都是不必要的,因为所有数据结构都使用了 CUDA 托管内存。表 2 显示了此版本 POT3D 所需的指令数和代码行数。
| POT3D (Original) | POT3D (Do Concurrent) | Difference | |
| Fortran | 3487 | 3421 | (-66) |
| Comments | 3452 | 3448 | (-4) |
| OpenACC Directives | 80 | 3 | (-77) |
| Total | 7019 | 6872 | (-147) |
对于 POT3D 中的归约循环,您依赖于隐式归约,但这可能并不总是有效的。最近, nvfortran 添加了即将推出的 Fortran 202X reduce 子句,该子句可用于还原循环,如下所示:
do concurrent (k=1:N) reduce(+:cgdot) cgdot=cgdot+x(i)*y(i)
enddoGPU 性能、统一内存和数据移动
您已经用最少数量的 OpenACC 指令和依赖托管内存进行数据移动的do concurrent 开发了代码。这是目前最接近的无指令代码。
图 3 显示,与原始 OpenACC GPU 代码相比,此代码版本的性能下降了约 10% 。造成这种情况的原因可能是do concurrent , 托管内存或两者的组合。
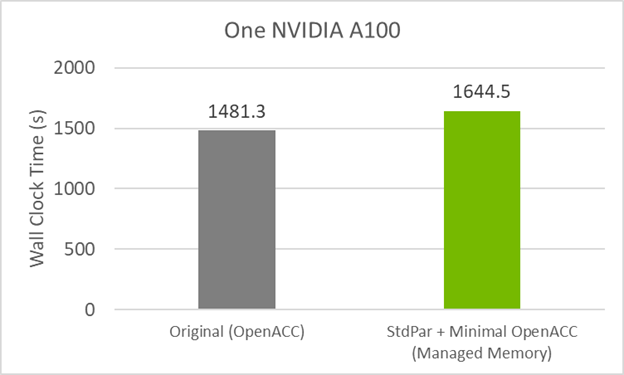
要查看托管内存是否会导致较小的性能损失,请在启用托管内存的情况下编译原始 GitHub 代码。这是通过在 GPU 之前使用的标准 OpenACC 标志之外使用编译标志-gpu=managed来实现的。
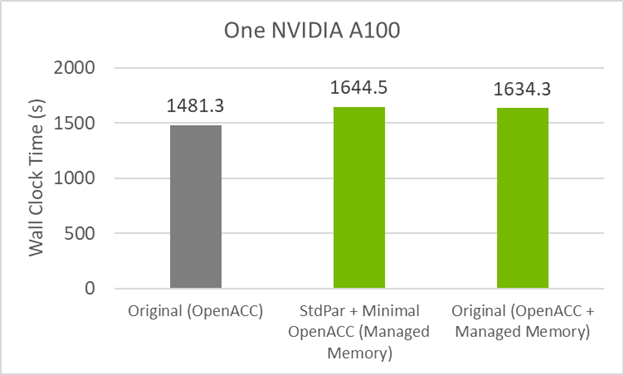
图 4 显示了 GitHub 代码现在在托管内存中的性能与最小指令代码类似。这意味着性能损失较小的罪魁祸首是统一内存。
要用最少的指令代码恢复原始代码的性能,必须将数据移动指令添加回。do concurrent和数据移动指令的组合如下代码示例所示:
!$acc enter data copyin(phi,dr_i)
!$acc enter data create(br)
do concurrent (k=1:np,j=1:nt,i=1:nrm1) br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k ))*dr_i(i)
enddo
!$acc exit data delete(phi,dr_i,br)这导致代码有 41 条指令,其中 38 条负责数据移动。要编译代码并依赖数据移动指令,请运行以下命令:
-stdpar=gpu -acc=gpu -gpu=cc80,cuda11.5,nomanaged
nomanaged关闭托管内存,-acc=gpu打开指令识别。
图 5 显示了与原始 GitHub 代码几乎相同的性能。此代码的指令比原始代码少 50% ,并提供相同的性能!
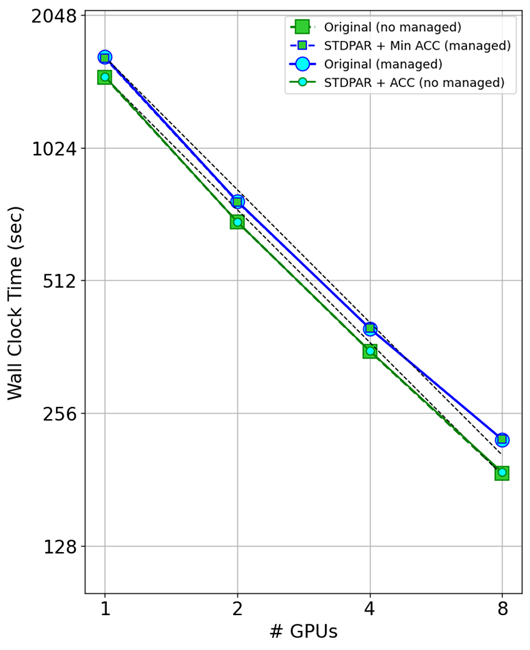
MPI + DO 并行扩展
图 7 显示了使用多个 GPU 的计时结果。主要的收获是do concurrent在多个 GPU 上与 MPI 一起工作。
查看打开托管内存的代码(蓝线),可以看到原始代码和最小指令代码的性能与使用多个 GPU 的性能几乎相同。
查看关闭托管内存的代码(绿线),您可以再次看到原始 GitHub 代码和代码的do concurrent版本之间的相同比例。这表明do concurrent可以与 MPI 一起工作,并且对您应该看到的缩放没有影响。
您可能还注意到,随着 GPU 的扩展,托管内存会导致开销。受管内存运行(蓝线)和数据指令线(绿线)彼此平行,这意味着开销随着 GPU 的数量而变化。
Fortran 标准并行编程综述
您可能会想,“标准 Fortran 听起来太好了,不可能是真的,有什么问题吗?”
Fortran 标准并行编程支持更干净的代码,并通过依赖 ISO 语言标准提高代码的未来证明性。使用最新的 nvfortran 编译器,您可以获得前面提到的所有好处。
虽然您在过渡到do concurrent时失去了当前的 GCC OpenACC / MP GPU 支持,但随着其他供应商在 GPU 上增加对do concurrent的支持,我们预计将来会获得更多的 GPU 支持。鉴于 ISO 语言标准的历史记录,我们相信这种支持会到来。
使用do concurrent目前确实存在一些限制,即缺乏对原子、设备选择、异步或优化数据移动的支持。然而,正如我们所展示的,这些限制中的每一个都可以使用编译器指令轻松解决。由于 Fortran 中的本机并行语言特性,所需的指令要少得多。
准备好开始了吗? 下载免费的 NVIDIA HPC SDK ,然后开始测试!如果您还对我们的研究结果感兴趣,请参阅 从指令到并行:标准并行的一个案例研究 GTC 课程。有关标准语言并行性的更多信息,请参阅 使用标准语言并行性开发加速代码 。
确认书
这项工作得到了国家科学基金会、 NASA 和空军科学研究办公室的支持。计算资源由圣地亚哥州立大学计算科学资源中心提供 .