
NVIDIA Ampere、NVIDIA Hopper 和 NVIDIA Blackwell 系列中的 NVIDIA 旗舰数据中心 GPU 均具有非均匀内存访问 (NUMA) 特性,但对外呈现为单一内存空间。因此,大多数程序不会受到内存非均匀性的影响。然而,随着新一代 GPU 带宽的不断提升,在兼顾计算与数据局部性时,性能和能效将获得显著提升。
NVIDIA 旗舰数据中心 GPU 在 NVIDIA Ampere、NVIDIA Hopper 和 NVIDIA Blackwell 系列中均具有非均匀内存访问 (NUMA) 行为,但暴露了单一内存空间。因此,大多数程序不会受到内存非均匀性的影响。然而,随着新一代 GPU 带宽的不断提升,在兼顾计算与数据局部性时,性能和能效将获得显著提升。
本文首先分析 NVIDIA GPU 的内存层次结构,探讨通过裸片到裸片链路进行数据传输对功耗与性能的影响。接着,回顾如何利用 NVIDIA 多实例 GPU(MIG) 模式实现数据定位。最后,展示在 Wilson-Dslash Stencil Operator 用例中,运行 MIG 模式与未实现数据本地化情况下的对比结果。
NVIDIA GPU 中的显存层次结构
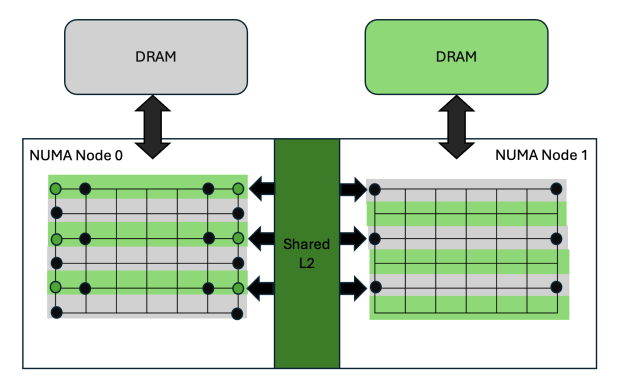
考虑图 1 中包含两个 NUMA 节点的内存层次结构的抽象视图。当节点 0 上的流式多处理器 (SM) 需要访问节点 1 的动态随机访问内存 (DRAM) 中的内存位置时,必须通过 L2 结构传输数据。以 NVIDIA Blackwell GPU 为例,每个 NUMA 节点均为一个独立的物理裸片,这会增加延迟以及数据传输所需的功耗。尽管系统复杂性随之提升,但 NUMA 无感知的代码仍可达到峰值 DRAM 带宽。
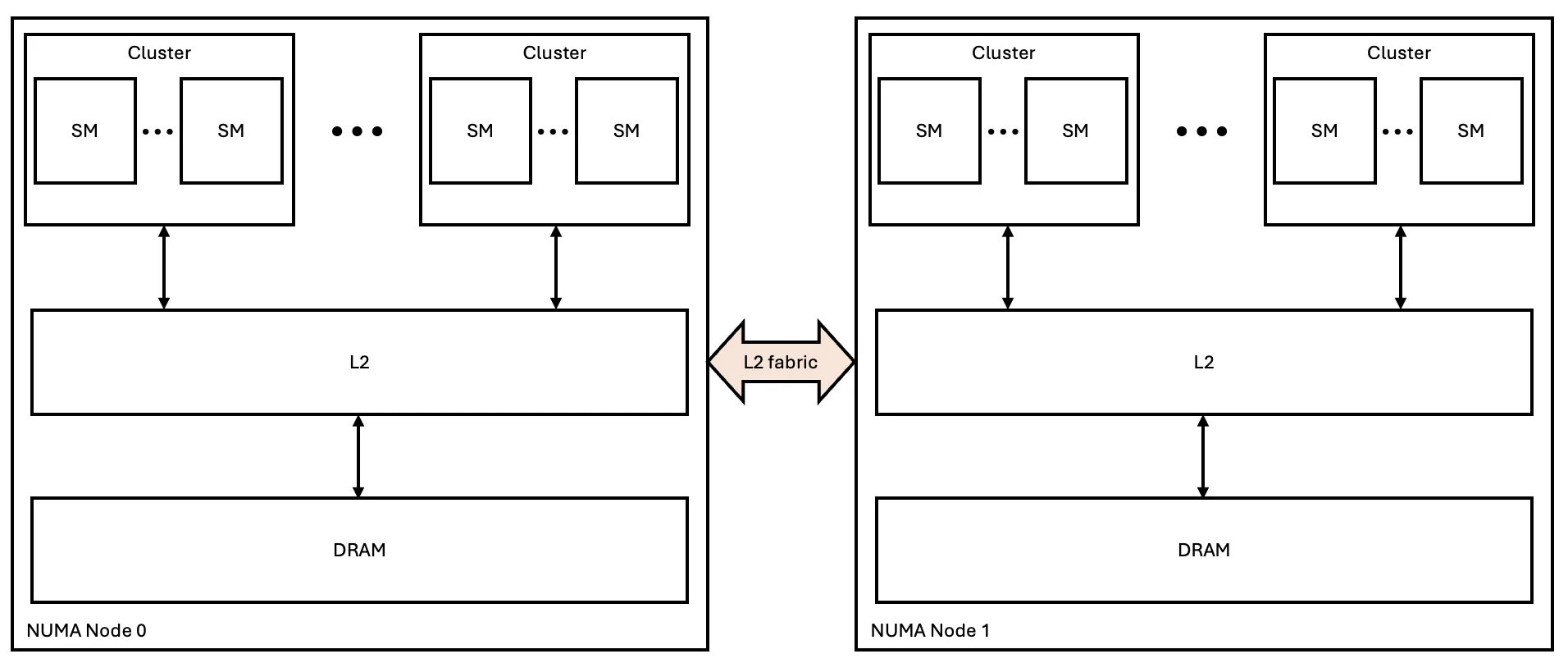
为了解决这些问题,尽量减少 NUMA 节点之间的数据传输是必要的。当向用户提供单个内存空间时,NVIDIA 架构会在 L2 缓存中采用一致性机制,以降低 NUMA 节点间的数据传输开销。该机制能够避免通过 L2 网络接口重复读取相同内存地址的数据。理想情况下,一旦地址数据被载入本地二级缓存,后续对该地址的所有访问都将命中缓存。
在引入相干缓存之前,统一的二级缓存可让所有 SM 达到峰值带宽(如 NVIDIA Volta),但延迟受 SM 与不同二级缓存段之间距离的影响。在 NVIDIA Ampere 架构中,更大的芯片引入了 NUMA 节点的层次结构,每个节点拥有独立的二级缓存,并通过一致性互连与其他节点相连。
虽然自 NVIDIA Ampere 架构以来的大型数据中心 GPU 采用了这种设计(与较小的游戏 GPU 不同),但 L2 结构的连接仍可维持 NVIDIA Blackwell Ultra 架构中所述的峰值带宽。
随着 GPU 的不断发展,出现了两个挑战:延迟上升和功耗限制。
- 延迟增加: 远程访问 L2 缓存的部分会带来延迟上升,进而影响性能,特别是同步性能。
- 功率限制: 在大型 GPU 上,当 Tensor Core 处于活动状态时,功耗可能成为制约因素。通过本地化 L2 访问以降低功耗,可借助与 GPU Boost 相关的动态电压频率调整 (DVFS) 机制,降低 L2 网络时钟频率,同时提升计算时钟频率,从而显著增强 Tensor Core 的性能。
MIG 可减少 NUMA 节点之间的数据传输。该功能随 NVIDIA Ampere 架构推出,能够将单个 GPU 划分为多个实例。通过使用 MIG,开发者可为每个 NUMA 节点创建一个 GPU 实例,从而避免通过 L2 结构接口进行访问。
这种方法确实存在自身的成本,包括通过 PCIe 在不同 GPU 实例之间通信所产生的开销。下一节将介绍在 MIG 模式下运行工作负载并使用非本地内存的结果,以展示该方法的有效性。
使用 MIG 进行数据定位
MIG 可将受支持的 NVIDIA GPU 划分为多个独立实例,每个实例均配备专用的高带宽显存、缓存和计算核心,从而实现跨多个用户或工作负载的高效、高性能 GPU 利用。 MIG 能在单个 GPU 上实现高达 7 倍的资源利用率提升,支持多个虚拟 GPU(vGPU)及虚拟机(VM)在单一 GPU 上并行运行,同时提供与 vGPU 相同的隔离保障。
可以利用 MIG 提供的功能实现 NUMA 节点的定位。通过为每个 NUMA 节点创建一个 MIG 实例,能够确保不同 GPU 实例之间的隔离,从而有效避免 NUMA 节点间的流量干扰。
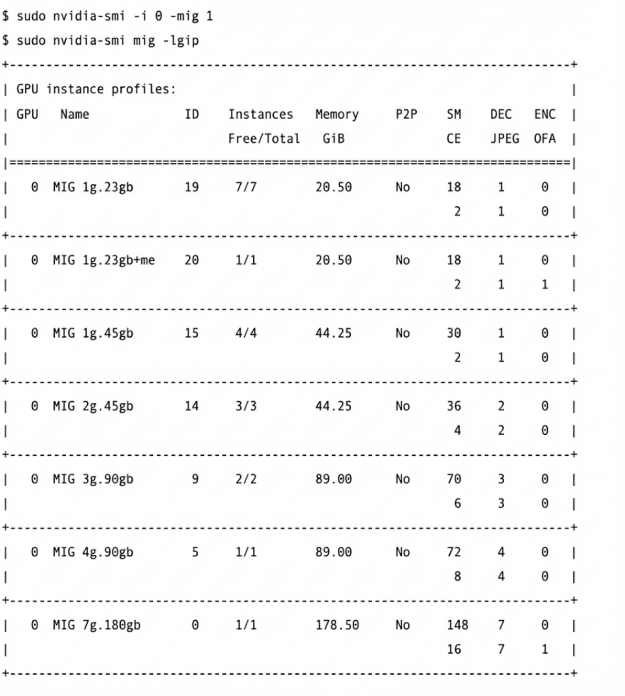
MIG 允许将物理 GPU 拆分为多个 GPU 实例 (GI),每个实例可包含一个或多个计算实例 (CI)。CI 包含属于 GI 的全部 SM(当每个 GI 仅包含一个 CI 时),或部分 SM。为了在 GI 中实现与 NUMA 节点的对应关系,我们的思路是创建两个 GPU 实例,分别映射到两个 NUMA 节点上。在 Blackwell GPU 上,您可以启用 MIG 模式,并列出可用的 GPU 实例配置,如图 2 中的代码所示。
由于 Blackwell 包含两个 NUMA 节点(每个小芯片对应一个),因此应选择 SM 数量较多且支持两个实例的配置文件。如图 2 所示,这是 ID 为 9 的配置文件,可支持两个实例。每个实例将拥有 89 GB 内存和 70 个 SM。若启用两个此类实例,总计可使用 70 × 2 = 140 个 SM,而非设备全部的 148 个 SM。
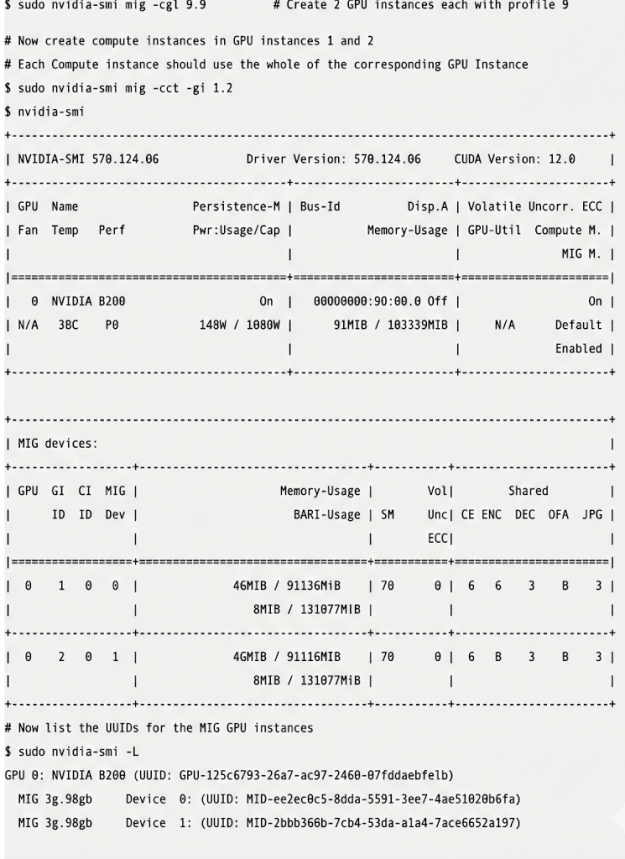
此时,需要在每个 GPU 实例中创建一个 CI,可通过图 3 所示的命令完成此操作。主 GPU 与 GPU 实例现在均拥有各自的标识符哈希码,并将这些哈希码用于两个 NUMA 节点:
MIG 3g.90gb Device 0: (UUID:
MIG-ee2ec0e5-0dda-5591-9ee7-4ae51028b6fa)
MIG 3g.90gb Device 1: (UUID:
MIG-2bbb368b-7cb0-53da-b1a4-7ace0652a197)
要使用这些设备,请将其添加到 CUDA_VISIBLE_DEVICES 环境变量中。例如,若要运行双进程 MPI 作业,可创建一个包装器脚本(wrapper.sh):
#!/bin/bash
#
case $SLURM_PROCID in
0)
CUDA_VISIBLE_DEVICES=”MIG-ee2ec0e5-0dda-5591-9ee7-4ae51028b6fa”
;;
1)
CUDA_VISIBLE_DEVICES=”MIG-2bbb368b-7cb0-53da-b1a4-7ace0652a197”
;;
esac
$*
然后启动 MPI 作业:
$ mpirun -n 2 ./wrapper.sh my_executable
随后,当所有工作完成后,可以关闭 MIG 模式。

使用 MIG 进行本地化有哪些好处?
作为演示使用 MIG 进行定位优势的示例应用,可考察 Wilson-Dslash Stencil 算子,该算子源自 QUDA 库,是格点量子色动力学(LQCD)中的关键计算内核。此库被用于加速多个大型 LQCD 代码,例如 Chroma 和 MILC。
Dslash 核是定义在四维环形格点上的有限差分运算,每个格点的数据会依据其八个正交邻点的值进行更新。本例中的四个维度分别为三个空间维度(X、Y、Z)和一个时间维度(T)。该内核的性能受限于内存带宽。
如果网格平均划分为两个 NUMA 节点(例如沿时间轴方向),则每个域都需要访问另一域在 T 维边界上的格点站点。如图 5 所示,子域边界上的绿色格点站点需要相邻红色站点的数据以完成计算模板。晶格在概念上分布于两个 NUMA 节点之上,其中绿色站点依赖红色站点提供模板所需的边界信息。可能的数据访问路径包括非本地化模式下的常规内存访问(黑色箭头),或在 MIG 本地化模式下通过主机进行的 MPI 消息传递(黑色箭头)。
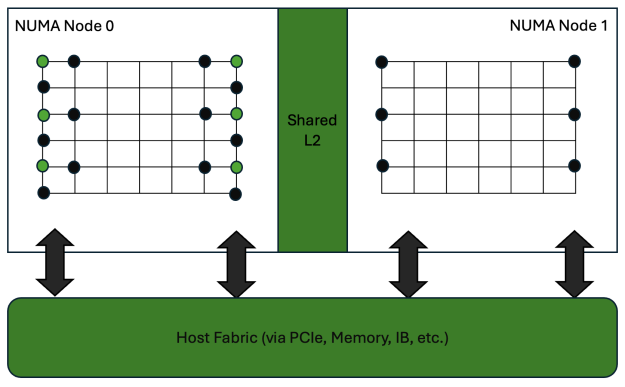
访问相邻节点较为便捷的方式是通过共享二级缓存和互连。然而,在 MIG 模式下运行时,MIG 实例之间的通信需经由 PCle 或 NVLink 通过 MPI 实现。因此,与访问连接到 MIG 实例的主显存相比,该路径将更为缓慢。
对于几乎不需要在两个 MIG 实例之间进行通信的工作负载,采用 MIG 模式通常更具优势。相反,若将边界上的黑色站点进行打包并通过 MPI 发送,则会引入额外的延迟(包括缓冲区的打包、发送和解压缩过程)。虽然这种方式未利用共享的二级缓存之间的互连来节省 GPU 功耗,但确实会通过主机进行数据传输而消耗额外电力(例如,通过 PCIe)。
需要在两个进程之间传输的数据量与消息中要传输的面部站点数量相关,特别是与分割方向正交的三维表面。在此示例中,拆分始终在 T 方向,因此每个 NUMA 节点在概念上最终都有 (Ns Nt)/2 个站点,其中 Ns 是空间体积中的站点数,Nt 是时间维度的长度。表面与体积之比为 Ns/(Ns Nt/2) = 2/Nt。在此问题中,Nt = 64,表面与体积之比保持不变,维持在 1/32 ~ 3.13%。
图 6 显示了未定位的案例。全局内存由两个通过内存控制器连接到 NUMA 节点的内存模块组成。格子上的彩色突出显示表明,数据可能来自本地 DRAM,或通过共享 L2 缓存访问的远程 DRAM。
这将与未采用 MIG 的基准情况进行对比。在此情况下,数据与处理均未进行定位,图 8 更准确地描述了该场景。每个 NUMA 节点都会从其本地内存控制器以及其他 NUMA 节点获取数据。实际上,系统中仅存在一个全局网格,图中将两个 NUMA 节点的部分分开显示仅为示意,并非实际分离。
在这种情况下,用于处理站点集合的线程块会依据调度程序的调度策略被分配到不同的 NUMA 节点。由于数据均匀分布在两个 NUMA 显存上,导致在共享 L2 之间传输的数据量远大于 MIG 定位时仅传递必要表面站点数据的情况,这可能带来显著的电力开销。
另一方面,整个操作可由单个内核完成。通过将用于消息传递的缓冲区进行打包,并在最后累加接收到的面片,即可避免产生延迟。
有关实验结果,请查看在不同 GPU 功率限制(以瓦为单位)下工作负载执行的加速情况。加速比是指在相同功率限制下(例如,均在 700 W 下运行)非本地化方法与 MIG 方法所测得的壁钟时间之比。
如图 7 所示,在 GPU 功率限制为 400 W 时,MIG 的性能优于非本地数据,速度提升可达 2.25 倍,具体取决于工作负载的规模。其原因是,当 GPU 在较低功率限制下运行时,L2 网络接口的功耗可能成为性能瓶颈。而在 MIG 模式下,由于 NUMA 节点间的数据传输不消耗 L2 网络功耗,因此工作负载能够更高效地执行。
但是,当 GPU 功率限制增加时,在图 9 中由灰色、深绿色和黑色线以及部分绿色表示的实验中,MIG 模式的性能会略差。这是因为在更高的功率限制下,消息传递引入的额外延迟可能会超过其在定位方面的优势。
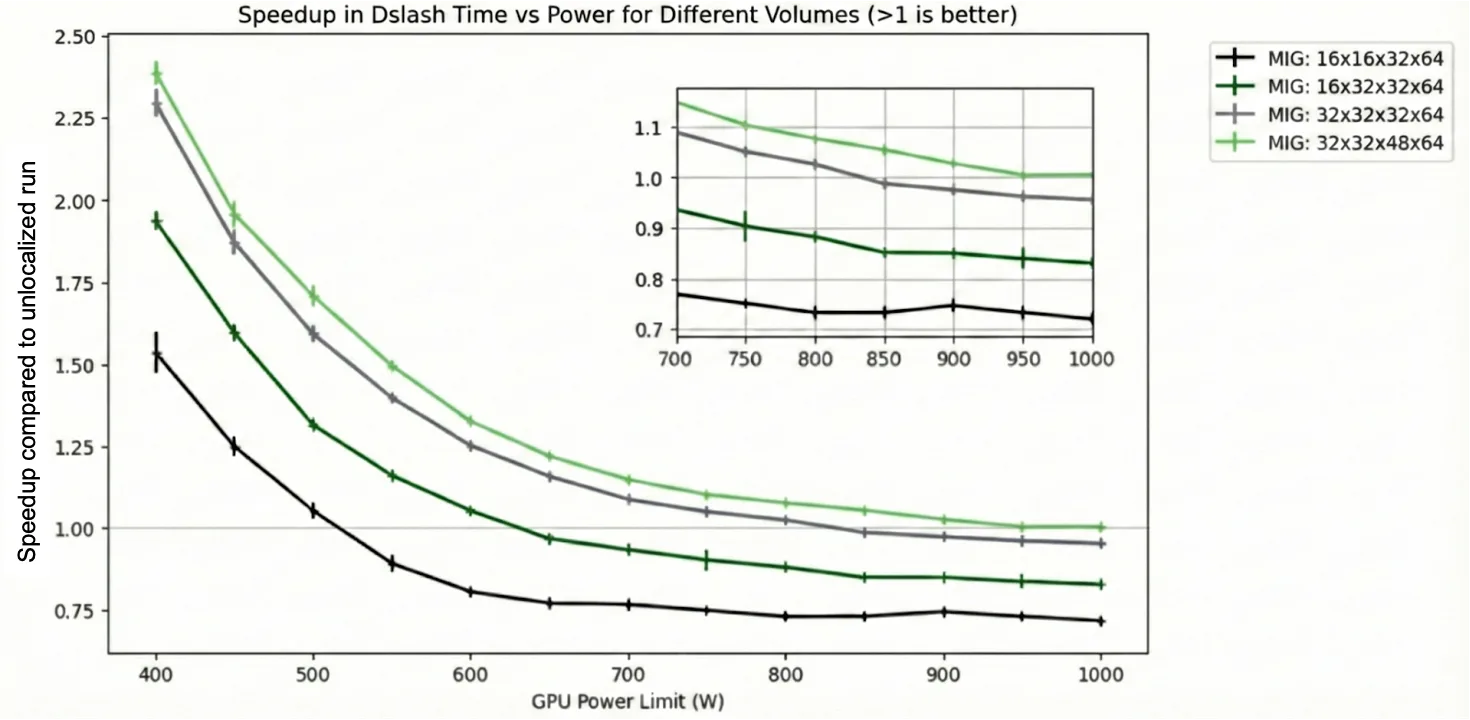
事实证明,即使在不确定的情况下,较小的机箱(尤其是图 7 中由黑色和深绿色线条表示的机箱)也不会在功率上限较高时耗尽可用功率。因此,它们从通过定位获得的 GPU 节能效果中受益较少,且在这些较小的体积下,由内核启动引起的延迟更为显著。相比之下,较大的机箱(例如绿色所示)需要更多功率,因此即使在较高的功率限制下,仍能比非本地化设置获得更明显的性能优势。
开始使用基于 MIG 的 NUMA 节点定位
NVIDIA 数据中心 GPU 中的本地二级缓存可能会影响 NUMA 以外工作负载的性能。我们在 MIG 模式下使用 Wilson-Dslash 算子的实验表明,当 GPU 在较低功率限制下运行,且通过 MPI(PCIe/NVLink)传输数据的速度相对于本地内存访问较慢时,采用基于 MIG 的 NUMA 节点定位策略,其运行速度可达相同功率限制下未进行定位情况的 2.25 倍。
虽然以更高的 1000 W 功率范围运行的系统可能比 400 W 配置实现更高的绝对性能,但基于 MIG 的定位在功率受限条件下展现出显著优势。在低功耗场景中,它能大幅提升性能,使其在严格的功率限制下运行时成为尤为有效的优化方案。
但是,通常情况下,MIG 无法提供持续实现有效数据定位所需的灵活性,尤其是在更高功率限制下进程间通信开销变得更加显著时。MIG 仅适用于规模过小、无法独立部署在 GPU 上的场景。因此,不建议将本博文中介绍的案例作为参考依据。为应对这些限制,目前正探索其他替代方案。
如需了解详情,请参阅如何使用 NVIDIA CUDA MPS 在不修改代码的情况下提升 GPU 显存性能。




