
传统上,在各种消费级硬件中部署 AI 应用需要进行权衡。可以针对特定 GPU 配置进行优化,以牺牲便携性为代价来提升性能;也可以构建通用且可移植的引擎,但需在性能方面做出让步。弥补这一差距通常依赖手动调优、设置多个构建目标,或接受一定程度的折中。
NVIDIA TensorRT for RTX 旨在消除这种权衡。在 200 MB 以下的体积中,这一精简推理库提供即时 (JIT) 优化器,可在 30 秒内完成引擎编译。这使其成为消费级设备上实时、响应灵敏的 AI 应用的理想选择。
TensorRT for RTX 引入了自适应推理引擎,可在运行时根据您的特定系统自动优化,随着应用的持续运行,逐步提升编译与推理性能。无需手动调整,无需设置多个构建目标,也无需人为干预。
只需构建一次轻量级、便携式引擎,便可将其部署到任意位置,并根据用户的硬件环境自适应运行。引擎在运行时会自动编译针对特定 GPU 的专用内核,学习工作负载模式,并随着使用不断优化性能,整个过程无需开发者干预。有关更多详细信息,请参阅 RTX 版 NVIDIA TensorRT 文档。
自适应推理
借助 TensorRT for RTX,运行时性能会随着时间推移而不断提升,且无需任何人工干预。三大功能协同作用,实现这种自我优化:Dynamic Shape 专用内核根据工作负载的形状动态调整性能,CUDA 图形技术消除执行这些内核时的开销,运行时缓存则使这些优化在各会话间持续保留。结果:引擎的运行速度越来越快。
- Dynamic Shapes Kernel Specialization(动态形状内核专用):自动为运行时遇到的形状编译更高效的内核,并实现无缝切换,通过针对实际工作负载条件的专用优化,实时提升性能。
- 内置 CUDA 图形:自动将核函数作为单个批次进行捕获、实例化和执行,有效降低核函数启动开销,提升推理性能,同时与动态形状机制无缝集成。
- 运行时缓存:通过在跨会话过程中保存已编译的内核,减少 JIT 编译的时间开销,降低初始化延迟,避免重复编译。
如需实时查看这些功能在实际扩散模型管道中如何协同工作并实现显著加速,敬请观看 RTX 版 TensorRT 自适应推理加速演示视频。
静态优化与自适应推理工作流程
传统的推理框架要求开发者预估输入形状,并在编译时为每个目标设备构建相应的优化引擎。TensorRT for RTX 采用了不同的方法:引擎能够在运行时根据实际工作负载进行自适应调整。表 1 对比了这两种工作流程。
| 组件 | 静态工作流 | 自适应推理 |
| 构建目标 | 每个 GPU 多个引擎 | 单个便携式引擎 |
| 形状灵活性 | 在构建时针对预测形状进行优化 | 在运行时根据实际出现的形状自动调整优化 |
| 推理运行 1 | 可获得优异性能(若预先调整形状) | 接近最优表现 |
| 推理运行 N | 保持一致的高性能 | 性能随着新形状(及缓存特化)的出现而持续提升 |
| 开发者努力 | 手动调优每个配置 | 零干预 |
自适应推理弥补了与静态工作流程之间的差距,实现了优异的性能,同时消除了构建的复杂性和开发者的负担。
性能比较:自适应与静态
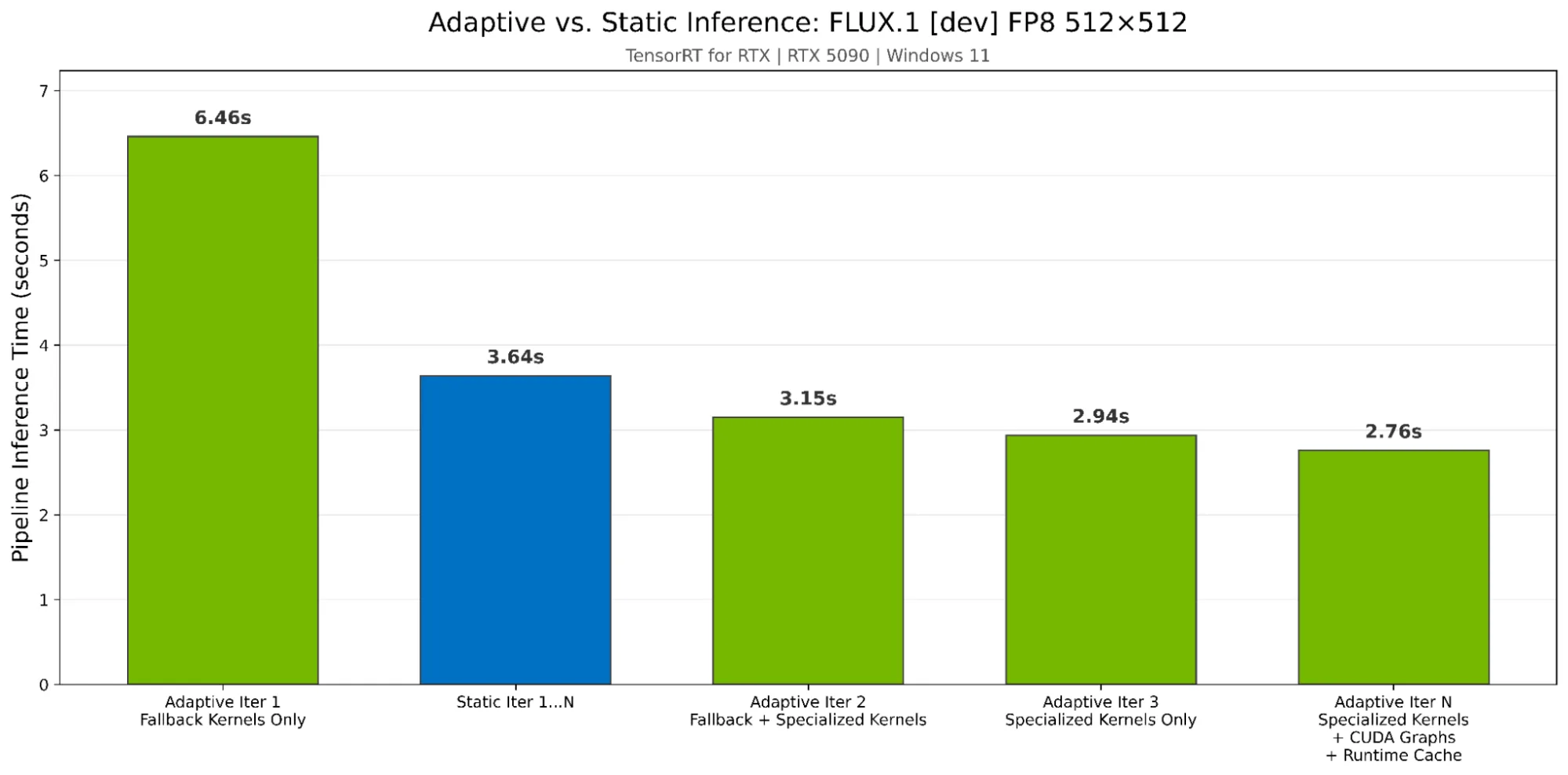
为了演示自适应推理的性能,我们在 RTX 5090 D 上使用 TensorRT for RTX 1.3,将 FP8 精度下的 FLUX.1 [dev] 模型与静态优化器进行对比,输入分辨率为 512 × 512,后者基于 RTX 1.3。如图 1 所示,从第 2 次迭代开始,自适应推理便超越了静态优化,在启用全部功能的情况下,运行速度提升了 1.32 倍。此外,运行时缓存可将 JIT 编译时间从 31.92 秒缩短至 1.95 秒(加速 16 倍),使后续会话能够立即以峰值性能启动。
激励人心的例子
基于 ONNX 模型创建 TensorRT 引擎提供了一个具有启发性的示例:
import tensorrt_rtx as trt_rtx
logger = trt_rtx.Logger(trt.Logger.WARNING)
builder = trt_rtx.Builder(logger)
network = builder.create_network()
parser = trt_rtx.OnnxParser(network, logger)
with open("your_model.onnx", "rb") as f:
parser.parse(f.read())
Dynamic Shapes 内核专业化
模型往往具有不同的输入维度,涵盖不同的图像分辨率、可变序列长度或动态批量大小。Dynamic Shapes Kernel Specialization 能够针对应用在运行时遇到的形状,自动生成并缓存经过优化的内核,这些内核专为模型的输入维度量身定制。优化后的内核会被缓存并重复使用,使具有相同形状的后续推理以高效性能运行,从而显著降低灵活性与速度之间的权衡。
图 1 展示了 NVIDIA GeForce RTX 5090 D 上 TensorRT for RTX 动态形状 Kernel 专业化在不同模型类别中的推理加速效果。相较于使用通用“回退”内核,每个柱状图均体现了在为实际遇到的输入形状自动生成并切换专用内核时所获得的平均性能提升。
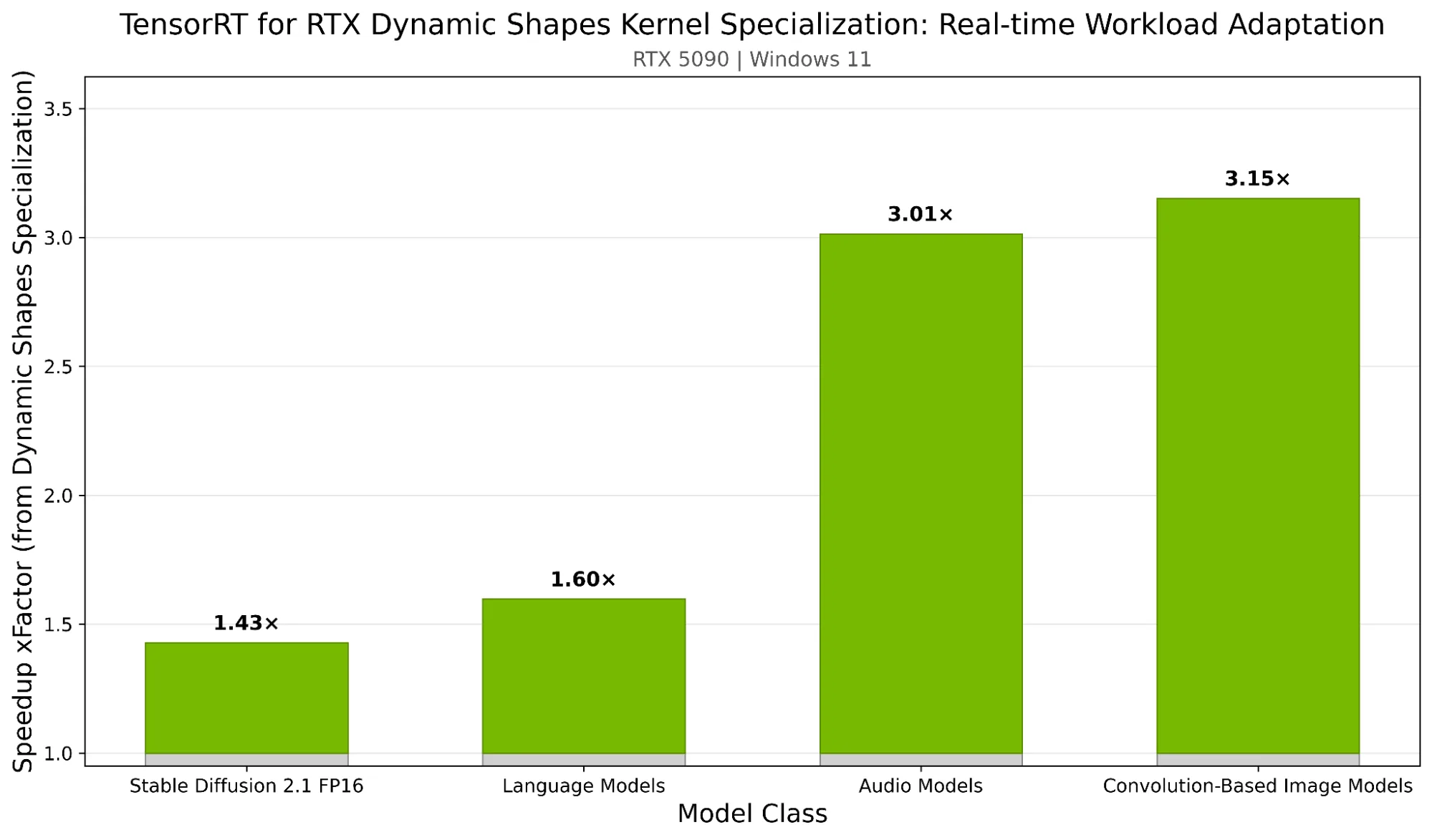
优势会随着工作负载的变化而进一步增强。能够处理不同输入形状的模型在所有配置下均表现出稳定的性能,同时具备灵活应对后续任务的能力。详细了解如何处理动态形状。
继续初始示例:
# Define optimization profile: min/opt/max shapes for dynamic dimensions
profile = builder.create_optimization_profile()
profile.set_shape("input",
min=(1, 3, 224, 224),
opt=(8, 3, 224, 224),
max=(32, 3, 224, 224)
)
config.add_optimization_profile(profile)
# ... build engine ...
# Configure dynamic shape kernel specialization strategy
# The default is Lazy compilation, explicitly set below for illustrative purposes
# Lazy compilation automatically swaps in kernels compiled in the background, adaptively improving perf for shapes encountered at runtime
runtime_config = engine.create_runtime_config()
runtime_config.dynamic_shapes_kernel_specialization_strategy = (
trt_rtx.DynamicShapesKernelSpecializationStrategy.LAZY
)
内置 CUDA 图形
现代神经网络每次推理可执行数百个独立的 GPU 内核。每次内核启动都会带来额外开销,通常需要 5-15 微秒的 CPU 与驱动程序处理时间。对于以小型运算为主的模型(如紧凑卷积、小矩阵乘法、元素级运算),此类启动时间可能成为性能瓶颈。
当每个内核的启动开销主导执行时间时,GPU 会在 CPU 队列工作期间处于闲置状态,导致队列时间接近甚至超过实际的 GPU 计算时间。这种情况称为“受队列限制”,可通过使用 CUDA 图形加以解决。
CUDA 图形将整个推理序列捕获为图结构,从而消除内核启动开销,并优化常见用例(包括重复的模型调用)。TensorRT for RTX 能够在单次运算中启动完整的计算图,而不是逐个启动核函数。
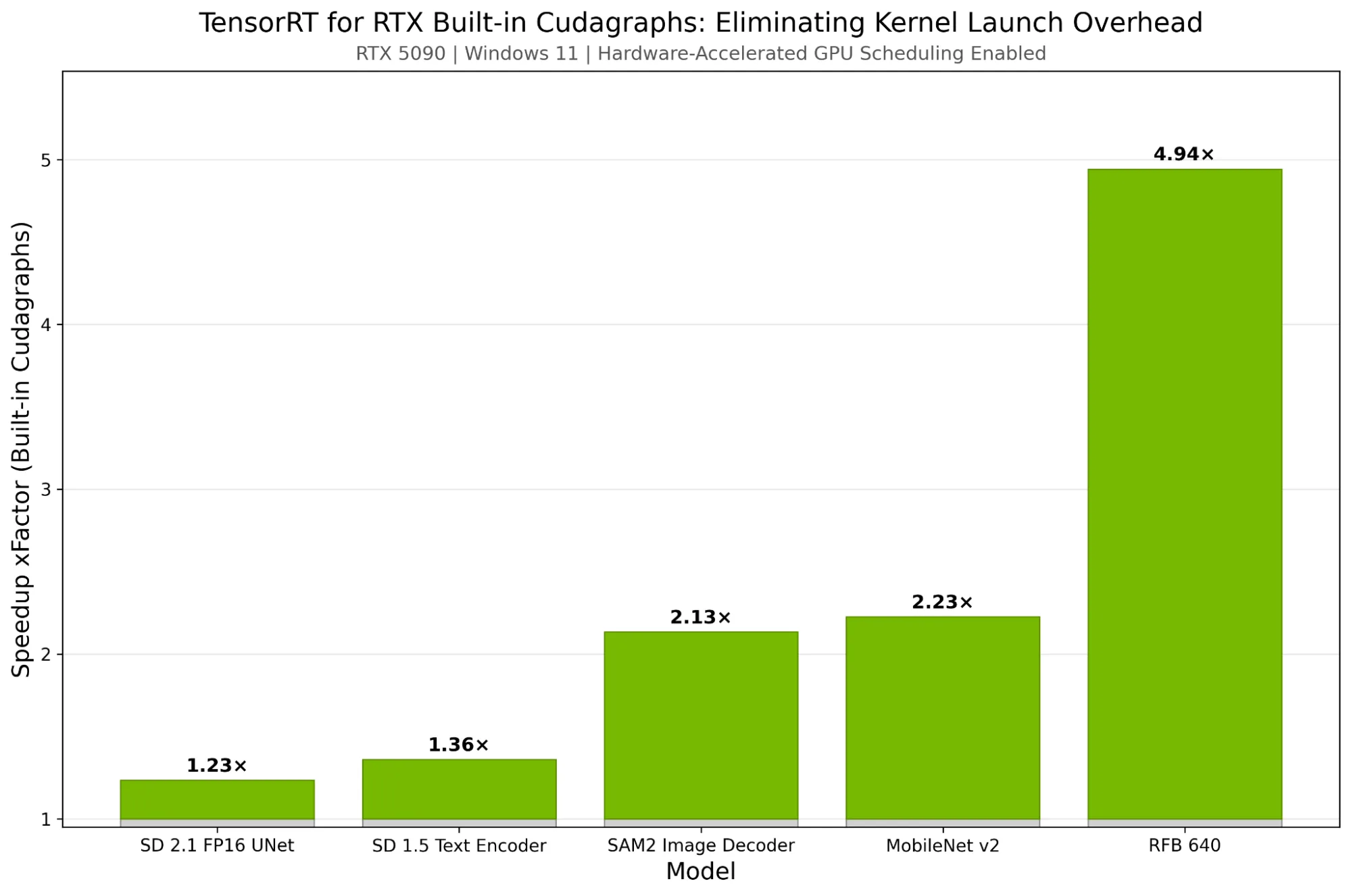
这可以将每次推理迭代的时间缩短数毫秒,例如,在配备 RTX 5090 GPU 的 Windows 计算机上测量 SD 2.1 UNet 模型的每次运行时,可实现 1.8 毫秒(23%)的性能提升。此功能在启用硬件加速 GPU 调度的 Windows 系统上尤为有效。包含大量小内核的模型受益更为显著,有助于提升受队列限制的工作负载的运行效率。
此外,在动态形状的环境中,内置 CUDA 图形仅支持捕获并执行特定形状的内核。这种方法可确保 CUDA Graph 专注于加速性能较高的内核,通常是使用频率较高的内核。详细了解如何使用内置 CUDA 图形。
图 3 显示了在 RTX 5090 D GPU 上使用 TensorRT for RTX 实现的推理加速效果(Windows 11 系统,启用了硬件加速的 GPU 调度,并采用 CUDA 图形)。需要注意的是,在包含大量运行时间较短内核的图像网络中,CUDA 图形带来的性能提升尤为显著。
添加到示例中:
# Enable CUDA Graph capture for reduced kernel launch overhead
runtime_config.cuda_graph_strategy = trt_rtx.CudaGraphStrategy.WHOLE_GRAPH_CAPTURE
运行时缓存
JIT 编译可在 TensorRT for RTX 中实现可移植性,并针对 GPU 提供自动优化。运行时缓存通过在各个会话间保留已编译的核函数(包括前述的专用动态形状核函数),避免了重复编译,进一步增强了这一优势。
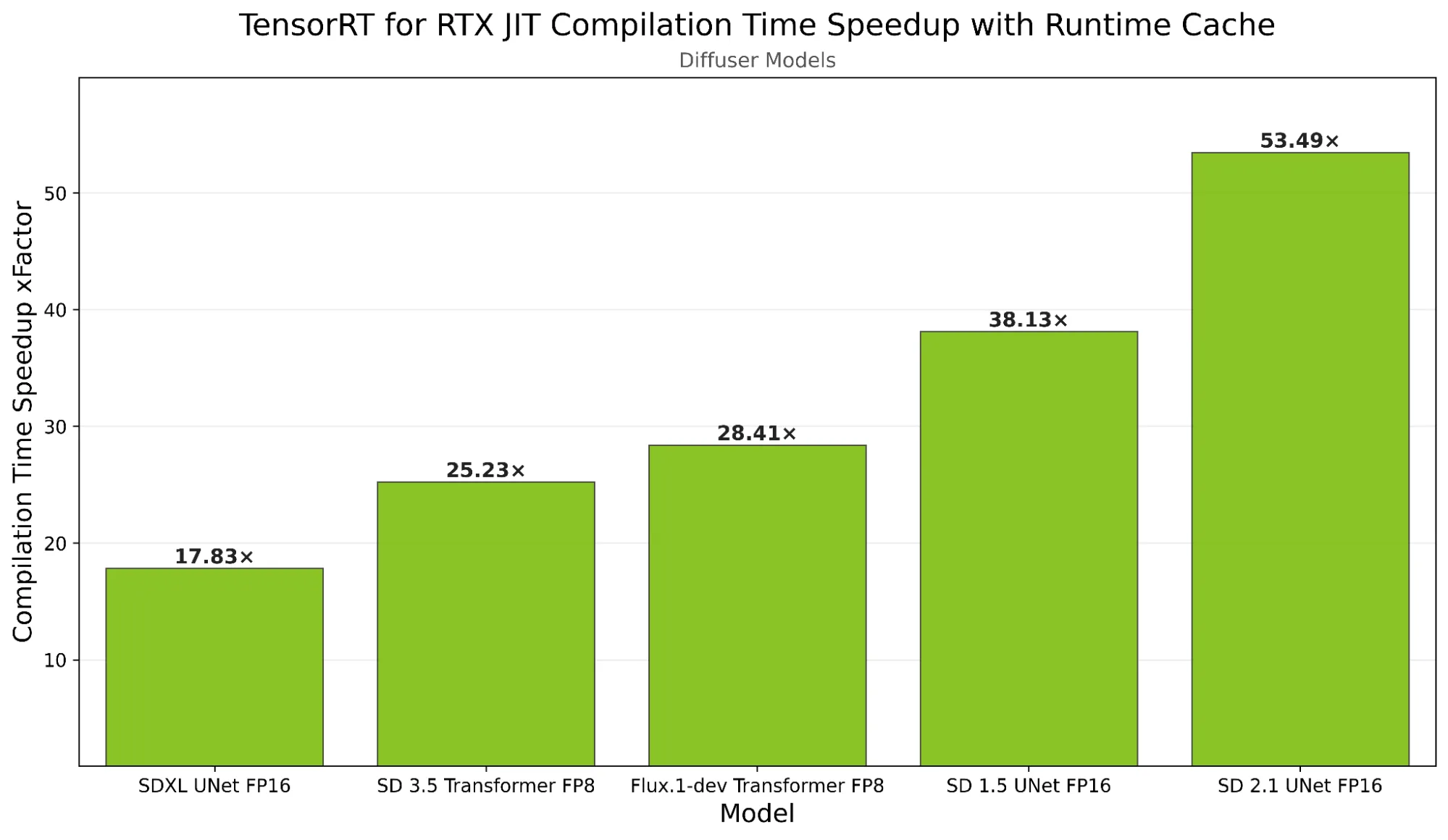
要使用运行时缓存,可先针对常见形状运行初始推理,采用优化实现来生成适配这些形状的专用内核。随后,通过运行时缓存 API,可将这些内核序列化为二进制 Blob 并保存至磁盘,以便后续重复使用。
通过在后续会话中加载此二进制 Blob,可确保立即提供经过优化的内核,从而消除对预热期的依赖,避免性能下降,并防止回退至通用内核,使应用在首次执行推理时即可达到理想性能水平。
此外,运行时缓存文件可与您的应用一同打包。如果您了解目标用户的特定平台(例如操作系统、GPU、CUDA 和 TensorRT 版本),便可针对这些环境预先生成运行时缓存。通过使用您提供的运行时缓存文件,用户能够从首次运行起就跳过所有内核编译开销,获得理想性能。详细了解如何使用运行时缓存。
完成示例:
from polygraphy import util
# Create runtime cache to persist compiled kernels across runs
runtime_cache = runtime_config.create_runtime_cache()
# Load existing cache if available
runtime_cache_file = "runtime.cache"
with util.LockFile(runtime_cache_file):
try:
loaded_cache_bytes = util.load_file(runtime_cache_file)
if loaded_cache_bytes:
runtime_cache.deserialize(loaded_cache_bytes)
except:
pass # No cache yet, will be populated during inference
runtime_config.set_runtime_cache(runtime_cache)
context = engine.create_execution_context(runtime_config)
# ... run inference ...
# Save cache for future runs
runtime_cache = runtime_config.get_runtime_cache()
with util.LockFile(runtime_cache_file):
with runtime_cache.serialize() as buffer:
util.save_file(buffer, runtime_cache_file, description="runtime cache")
开始使用自适应推理
三种技术协同工作,可高效实现自适应推理优化:
- Dynamic Shapes Kernel Specialization 可确保每个形状以理想状态运行。
- CUDA 图形 消除了执行这些优化内核的开销。
- 运行时缓存 使这些优化在各个会话中持久存在。
AI 应用能够适应各种输入维度,同时保持静态形状推理的性能特性。不会对您的应用程序设计造成任何妥协或人为限制。详细了解 TensorRT for RTX 性能优化最佳实践。
要体验基于 NVIDIA TensorRT for RTX 的自适应推理功能,请访问 NVIDIA/TensorRT-RTX GitHub 资源库,并尝试使用 TensorRT RTX Notebook 优化的 FLUX.1 [dev] 工作流。您还可以观看 TensorRT for RTX 的自适应推理加速演示视频,实时了解这些功能的实际表现。
开始为 NVIDIA RTX PC 构建 AI 应用,利用 NVIDIA 工具、SDK 和模型在 Windows 上简化开发流程,实现模型在设备端更快速、更私密的运行。




