Kubernetes 支持生产环境中绝大多数 AI 工作负载。然而,维护 GPU 节点、保障应用稳定运行、持续推进训练任务,以及实现跨 Kubernetes 集群的流量调度,说起来容易,做起来却颇具挑战。
NVSentinel 旨在应对这些挑战,是一款专为 Kubernetes AI 集群设计的开源系统。它能够持续监控 GPU 的运行状态,并在工作负载发生中断前自动修复问题。
适用于 Kubernetes GPU 集群的运行状况系统
NVSentinel 是一个专为运行 GPU 工作负载的 Kubernetes 集群设计的智能监控与自我修复系统。如同建筑中的火灾警报系统能够持续检测烟雾并在发现威胁时自动响应,NVSentinel 也能实时监控 GPU 硬件状态,并在出现故障时自动采取应对措施。它属于更广泛的医疗自动化开源工具生态的一部分,致力于提升 GPU 的可用性、资源利用率和运行稳定性。
GPU 集群成本高昂,发生故障带来的损失也十分严重。在现代人工智能和高性能计算领域,组织通常使用 NVIDIA GPU 构建大型服务器集群,单台服务器的价格可能高达数万美元。一旦这些 GPU 出现故障,可能导致以下后果:
- 静默损坏:有缺陷的 GPU 产生错误结果,且未能被及时检测到
- 级联故障:单个异常 GPU 导致整个多日训练任务失败
- 资源浪费:正常的 GPU 因等待故障节点恢复而处于空闲状态
- 人工干预:需工程师随时待命,响应并排查系统问题
- 效率降低:数据科学家耗费数小时重新执行失败的实验
传统的监控系统虽然能够检测到问题,却往往难以真正解决问题。准确诊断并修复GPU故障仍需深厚的专业知识,且修复过程可能耗时数小时甚至数天。
NVIDIA 运营着全球规模最大的 GPU 集群之一,为 NVIDIA Omniverse、NVIDIA Cosmos 和 NVIDIA Isaac GR00T 等产品及研究项目提供支持。要大规模地保持这些集群的稳定运行,自动化至关重要。
在过去一年中,NVIDIA 团队在 NVIDIA DGX 云集群 内部持续开发和测试 NVSentinel。该系统能在几分钟内检测并隔离 GPU 故障,相比以往的数小时大幅缩短了响应时间,有效减少了停机时间,提升了资源利用率。
NVSentinel 的工作原理是什么?
NVSentinel 部署于每个运行中的 Kubernetes 集群。部署完成后,系统将持续监控节点异常、分析事件,并自动执行节点隔离、排水、标记或触发外部修复流程等操作。NVSentinel 的主要功能包括持续监控、数据聚合与分析等,具体如下。
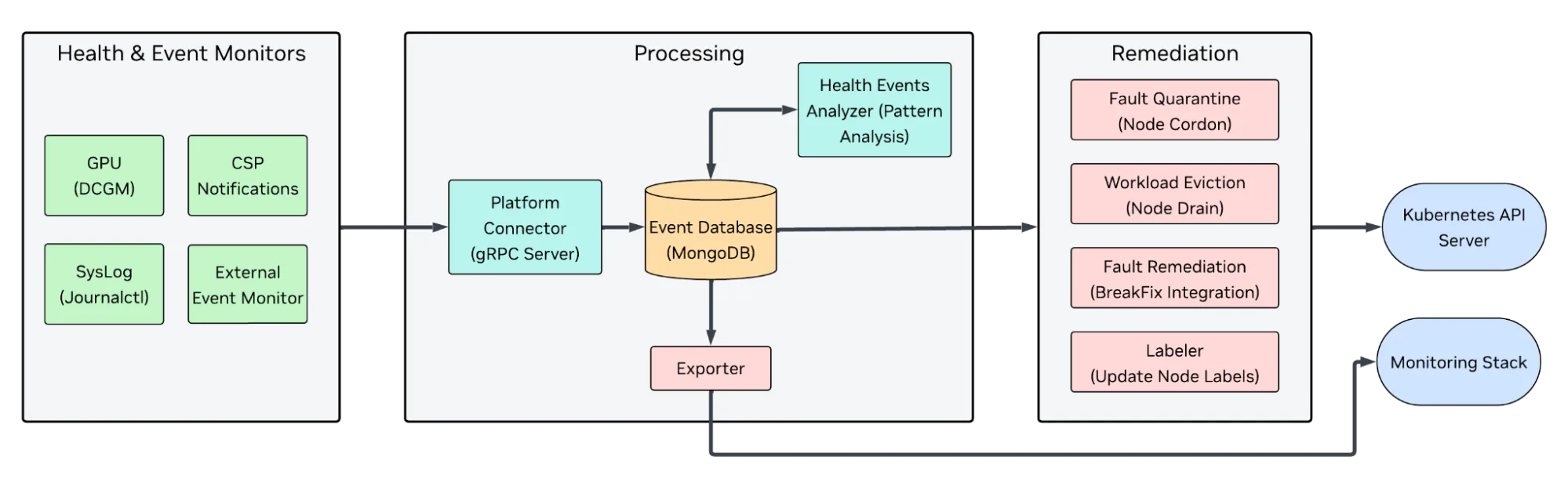
持续监控
NVSentinel 采用模块化架构,部署 GPU 与系统监控组件,利用 NVIDIA DCGM 进行诊断,追踪散热异常、内存错误及硬件故障。同时,系统会分析内核日志,检测驱动崩溃和硬件相关错误,并支持与主流云服务商 API(如 AWS、GCP、OCI)集成,以识别计划内维护或硬件故障事件。其模块化设计便于扩展自定义监控模块和接入多样化数据源。
数据聚合和分析
收集到的信号将传入 NVSentinel 分析引擎,该引擎根据事件的严重程度和类型进行分类。它采用类似操作运行手册的基于规则的模式,有效区分瞬态问题、硬件故障以及系统集群异常。例如:
- 可能会记录并监控单个可纠正的 ECC 错误;
- 反复出现的不可纠正 ECC 错误将触发节点隔离;
- 驱动程序崩溃可能导致节点流失并引发封锁操作。
该方法将集群中的健康状态管理从“检测与告警”转变为“检测、诊断与响应”,并通过策略驱动的机制实现可声明式配置的自动化操作。
自动修复
当节点被判定为不健康时,NVSentinel 将协调 Kubernetes 层面的响应措施。
- 通过隔离机制防止工作负载中断,
- 设置向调度器和运维人员公开 GPU 或系统健康状态的 NodeConditions,
- 并触发外部修复钩子以重置或重新分配硬件资源。
NVSentinel 的修复工作流采用可插拔设计,能够与您现有的维修或重新调配流程无缝集成,便于连接各类自定义系统,例如服务管理平台、节点镜像工作流或云自动化工具。
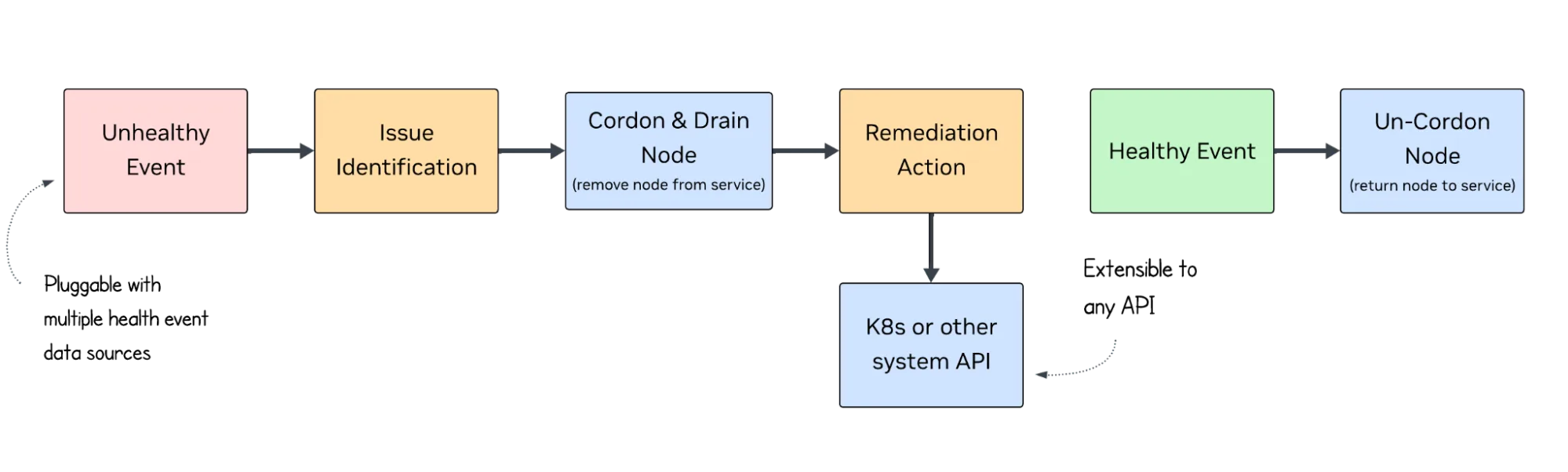
系统经过模块化分解,使操作人员能够灵活选用所需组件。该设计旨在适配多种运营模式,而非取而代之。您可根据实际需求进行选择。
- 仅部署监控与检测功能;
- 启用自动封锁及排险操作;
- 实现全闭环修复机制(适用于更复杂的环境)。
示例:检测 GPU 错误并从中恢复
以一项64-GPU训练任务为例,某个节点开始频繁报告双位ECC错误。传统情况下,这类问题可能被忽视,直到数小时后任务失败才被发现。而借助NVSentinel,GPU健康监控器能够及时识别异常模式,分析模块将该节点标记为性能下降,系统随即封锁并排空该节点,同时启动修复流程对资源进行重新调配。训练任务得以持续运行,显著减少中断时间,有效节省了大量GPU计算时间,避免了计算资源的浪费。
如何开始使用 NVSentinel
NVSentinel 利用通过 NVIDIA GPU Operator 部署的 NVIDIA 数据中心 GPU 管理器(DCGM),采集 GPU 和 NVIDIA NVSwitch 的运行状态信号。在支持 GPU Operator 和 DCGM 的环境中,NVSentinel 能够监控 GPU 级别的故障并采取相应措施。
支持的 NVIDIA 硬件涵盖所有受 DCGM 支持的数据中心 GPU,例如:
- NVIDIA H100(80 GB、144 GB、NVL)
- NVIDIA B200 系列
- NVIDIA A100(PCIe 和 SXM4)
- NVIDIA V100
- NVIDIA A30 / A40
- NVIDIA P100、P40、P4
- NVIDIA K80 及更新的 Tesla 架构数据中心 GPU
DCGM 为基于 NVSwitch 的系统提供遥测支持,使 NVSentinel 能够监控 NVIDIA DGX 和 HGX 平台,包括 DGX A100、DGX H100、HGX A100、HGX H100 以及 HGX B200。具体支持的产品列表请参考 DCGM Supported Products documentation。
请注意,NVSentinel 目前尚处于试验阶段,暂不建议在生产环境中使用。
安装
您可以通过一条命令将 NVSentinel 部署到 Kubernetes 集群中。
helm install nvsentinel oci://ghcr.io/nvidia/nvsentinel --version
v0.3.0 #Replace with any published chart version
NVSentinel 文档详细介绍了如何与 DCGM 集成,以及如何自定义监控器和操作,同时还涵盖了在本地和云端环境中的部署方法,两种部署场景均提供了示例清单。
更多旨在推进 GPU 运行状况的 NVIDIA 计划
NVSentinel 是 NVIDIA 一系列更广泛计划的重要组成部分,旨在提升客户在 GPU 健康状况、运行透明度和运营弹性方面的体验。这些计划包括 NVIDIA GPU Health 服务,该服务提供车队级别的遥测数据与完整性洞察,与 NVSentinel 的 Kubernetes 原生监控和自动化能力形成互补。上述举措共同体现了 NVIDIA 持续致力于帮助运营商在不同规模下构建更健康、更可靠的 GPU 基础设施。
开始使用 NVSentinel
NVSentinel 目前尚处于试验阶段,建议您试用该工具并通过 NVIDIA/NVSentinel 使用 GitHub 问题页面提供反馈。目前不建议在生产环境中使用 NVSentinel。未来的版本将扩展 GPU 遥测覆盖范围,支持更多日志记录系统(例如 NVIDIA DCGM),并引入更丰富的修复工作流程与策略引擎。随着项目逐步完善,我们还将增加更多稳定性检测机制和配套文档。
NVSentinel 是一个开源项目,欢迎广大开发者积极参与贡献。您可以通过以下方式加入我们:
- 在您自己的 GPU 集群上测试 NVSentinel
- 在 GitHub 上提交反馈与功能建议
- 参与贡献新的监控模块、分析规则或优化工作流程
请访问 NVIDIA/NVSentinel GitHub 仓库以开始使用,并根据 NVSentinel 项目路线图 获取定期更新。