
如果使用相同的输入数据进行多次运行时能够产生完全一致的逐位计算结果,则该计算被称为确定性计算。这看似简单,但在实际中却难以实现,尤其是在并行编程和浮点运算的场景下。其原因在于浮点加法和乘法不满足严格的结合律,即 (a + b) + c 可能不等于 a + (b + c),这是由于中间结果在以有限精度存储时会产生舍入误差。其中,有限精度存储的更多信息请参考。
借助 NVIDIA CUDA 核心计算库 (CCCL) 3.1,CUB——一种用于光速并行设备算法的低级 CUDA 库——新增了一个可接受执行环境的单相 API,使用户能够自定义算法行为。我们可以使用此环境来配置 reduce 算法的确定性属性。这一功能仅可通过新的单阶段 API 实现,因为两阶段 API 不支持执行环境。
以下代码展示了如何在 CUB 中设置确定性级别(可通过编译器资源管理器在线查找完整示例)。
auto input = thrust::device_vector<float>{0.0f, 1.0f, 2.0f, 3.0f};
auto output = thrust::device_vector<float>(1);
auto env = cuda::execution::require(cuda::execution::determinism::not_guaranteed); // can be not_guaranteed, run_to_run (default), or gpu_to_gpu
auto error = cub::DeviceReduce::Sum(input.begin(), output.begin(), input.size(), env);
if (error != cudaSuccess)
{
std::cerr << "cub::DeviceReduce::Sum failed with status: " << error << std::endl;
}
assert(output[0] == 6.0f);
我们首先确定输入和输出向量,然后利用 cuda::execution::requir e () 构建一个 cuda::std::execution::env 对象,并将确定性级别设为 not_guaranteed。
有三个确定性层级可用于归约,分别是:
not_guaranteedrun_to_rungpu_to_gpu
无法保证确定性
在浮点归约中,结果可能受元素组合顺序的影响。若两次运行过程中归约运算符的应用顺序不同,则最终数值可能会有细微差异。在多数应用中,这类差异是可以接受的。通过放宽对严格确定性的要求,归约的实现可灵活调整运算顺序,从而提升运行时性能。
在 CUB 中,not_guaranteed 降低了确定性级别,使得原子操作(跨线程的无序执行可能导致运行间操作顺序不同)能够用于计算块级部分聚合以及最终归约值。由于原子操作会将块级部分聚合结果合并到最终结果中,因此可在单次核函数启动中完成整个归约过程。
非确定性归约变体通常比逐次运行的确定性版本执行得更快,尤其在处理较小的输入数组时。在单个核函数中完成归约操作,能够减少多次启动核函数带来的延迟,显著降低额外的数据移动,并避免附加的同步开销。其权衡在于,由于缺乏确定性行为,不同运行间的结果可能会有轻微差异。
运行对运行确定性
虽然非确定性降低可带来潜在的性能提升,但 CUB 还提供了一种模式,能够确保在整个运行过程中获得一致的结果。默认情况下,cub::DeviceReduce 为“运行到运行”的确定性模型,对应于在单相 API 中将确定性级别设置为 run_to_run。在此模式下,对于相同的输入、内核启动配置和 GPU,多次调用将产生相同的输出。
这种确定性是通过将归约构建为固定的分层树来实现的,而不是依赖原子操作,因为原子更新的顺序在不同运行中可能有所不同。在每个归约阶段,元素首先在单个线程内进行组合,随后利用 shuffle 指令对线程束内所有线程的中间结果进行规约,再通过共享内存完成块范围内结果的聚合。最后,由第二个内核汇总各块的结果,生成最终输出。由于该执行序列是预先确定的,且不依赖于线程执行的相对时间,因此相同的输入、内核配置和 GPU 将产生完全一致的逐位结果。
GPU 到 GPU 确定性
对于需要高度再现性的应用程序,CUB 还提供 GPU 到 GPU 的确定性,从而保证在不同 GPU 上以相同输入进行多次运行时获得相同的结果。此模式对应将确定性级别设置为 gpu_to_gpu。
为了实现这种级别的确定性,CUB 采用了 可复制浮点累加器(RFA),该方案源自 NVIDIA GTC 2024 会议上的主题演讲,恢复 HPC 的科学方法:高性能可复制并行归约。 RFA 通过将所有输入值划分到固定数量的指数范围内(默认为三个区间),以应对浮点运算中因不同指数相加而产生的非结合性问题。这种固定且结构化的累加顺序确保了最终结果不依赖于 GPU 架构。
最终结果的准确性取决于箱子的数量:箱子数量越多,准确性越高,但也会增加中间求和的次数,从而影响性能。当前实现默认将数据桶数量设为 3,这一设置在性能与准确性之间提供了良好的平衡,是较为理想的默认配置。值得注意的是,此配置不仅具有严格的确定性,还能保证得到正确的数值结果,其误差界限比传统并行归约中常用的成对求和更为严格。
结果如何因确定性水平而异
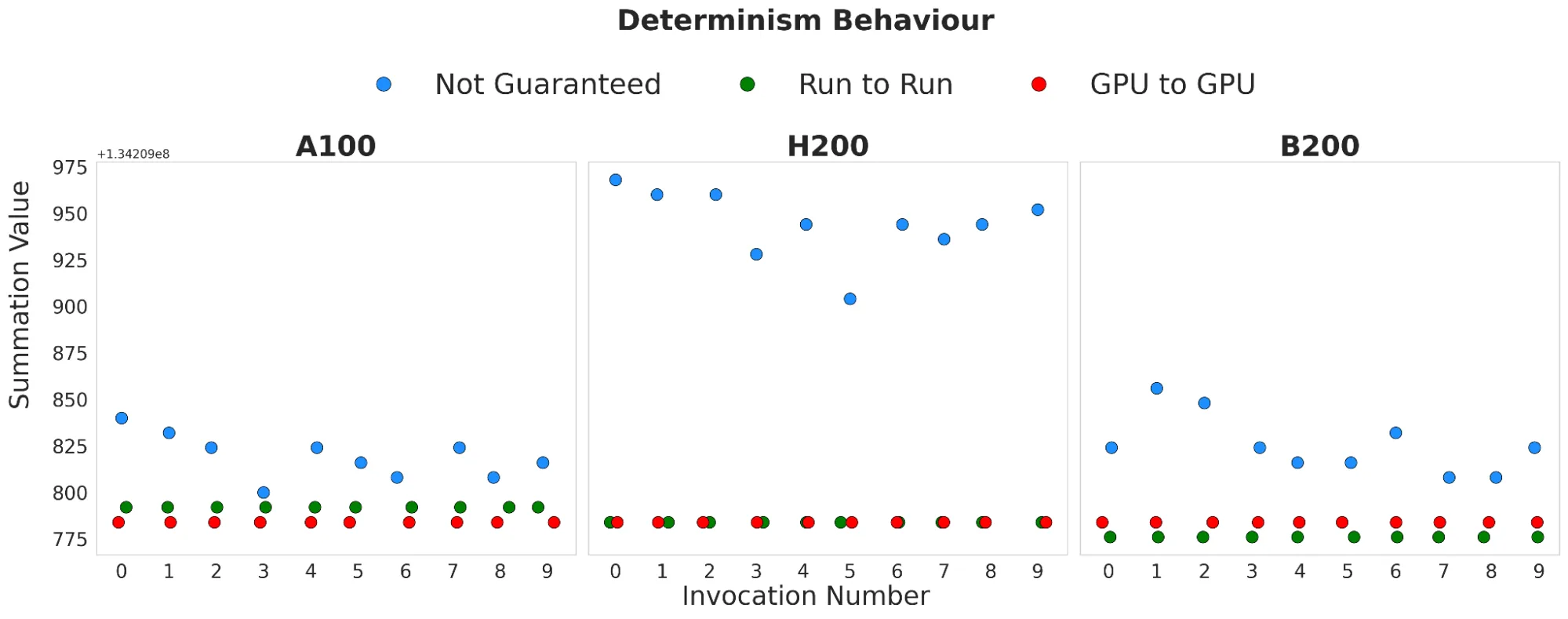
三个确定性水平在多次运行中所产生的变异量存在差异:
- 无保证的确定性 在每次调用时产生的求和结果会略有差异。
- 运行间确定性 可确保在单个 GPU 上每次调用的结果一致,但在不同 GPU 上运行时,结果可能有所不同。
- GPU 间确定性 则能保证无论由哪个 GPU 执行归约操作,每次调用的求和结果都完全相同。
如图 1 所示,针对每个确定性水平(以绿色、蓝色和红色圆圈表示),绘制了数组求和结果随运行次数变化的曲线。水平直线表示归约操作会产生相同的结果。
确定性性能比较
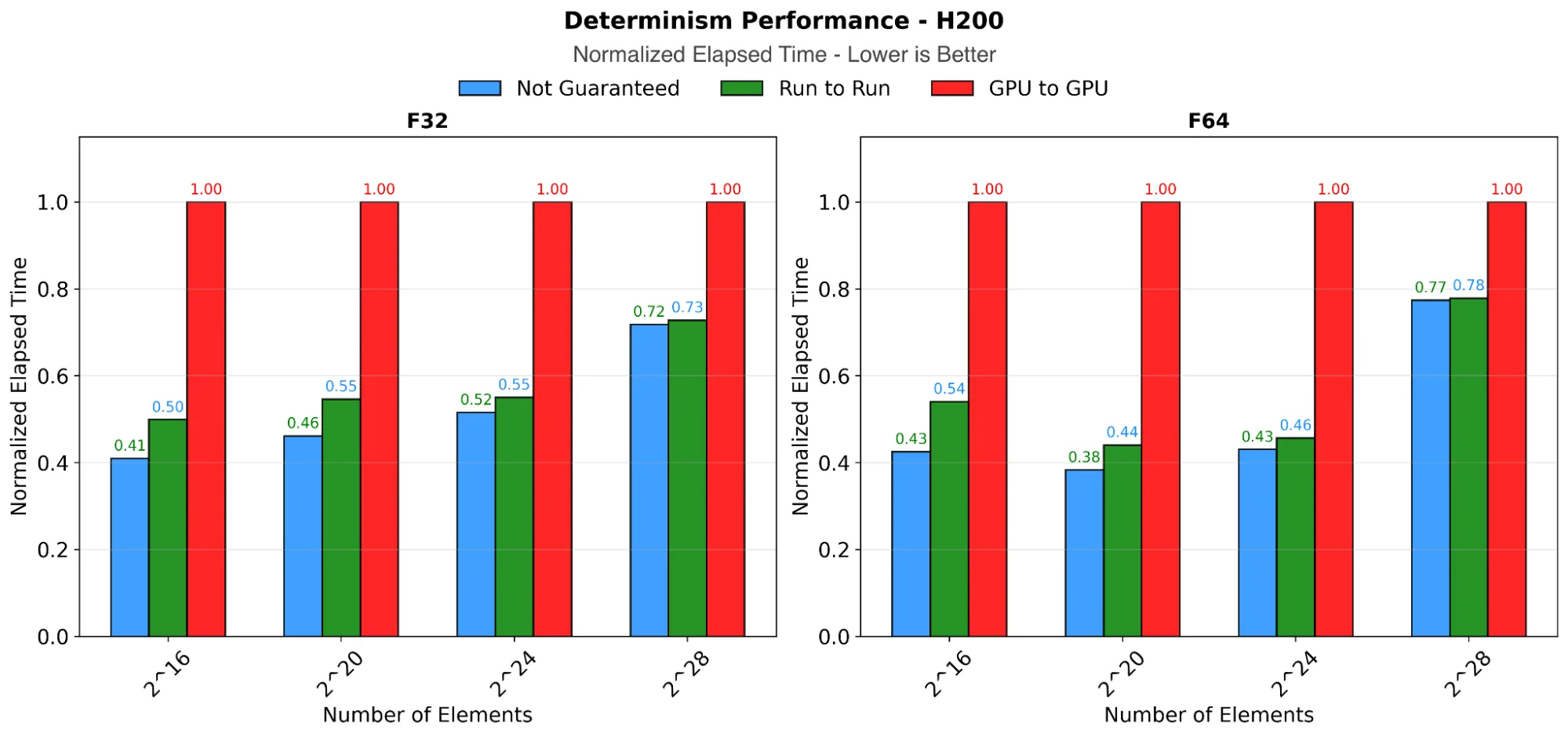
选择的确定性级别会影响 cub::DeviceReduce 的性能。无法保证的确定性及其宽松的要求可提供更高的性能。默认的“运行到运行”确定性提供了良好的性能,但相比无法保证的确定性略慢。GPU 到 GPU 的确定性可在不同的 GPU 上实现严格程度更高的再现性,这可能会显著降低性能,将大型问题的执行时间延长 20% 到 30%。
图 2 比较了在 NVIDIA H200 GPU 上,float32 和 float64 输入在不同确定性要求下的性能表现(越低越好)。结果清晰地展示了确定性级别的选择对不同数据类型执行时间的影响。
总结
通过引入单相 API 和显式确定性级别,CUB 提供了一个增强的工具箱,用于控制归约算法的行为与性能。用户可根据需求选择合适的确定性级别:从高性能、灵活且无保证的模式,到具备可靠运行间一致性的默认模式,再到严格实现 GPU 间可重现性的模式。
CUB 中的确定性不仅限于归约操作。我们计划将这一功能扩展到其他算法,使开发者能够对更广泛的并行 CUDA 基元实现可重现性控制。有关最新动态和讨论,请参阅 GitHub 上正在进行的关于扩展确定性支持的议题,关注我们的路线图,并提供您希望看到哪些算法具备确定性版本的反馈。




