
随着大语言模型 (LLM) 推理工作负载的复杂性不断增加,单个单一的服务进程开始达到其极限。预填充和解码阶段具有截然不同的计算配置文件,但传统部署迫使它们使用相同的硬件,导致 GPU 未得到充分利用,扩展缺乏灵活性。
解服务通过将推理工作流分为预填充、解码和路由等不同阶段来解决这一问题,每个阶段都作为独立服务运行,并且可以根据自己的条件进行资源和扩展。
本文将概述如何在 Kubernetes 上部署解推理,探索不同的生态系统解决方案及其在集群上的执行方式,并评估其开箱即用的功能。
聚合推理和分解推理有何区别?
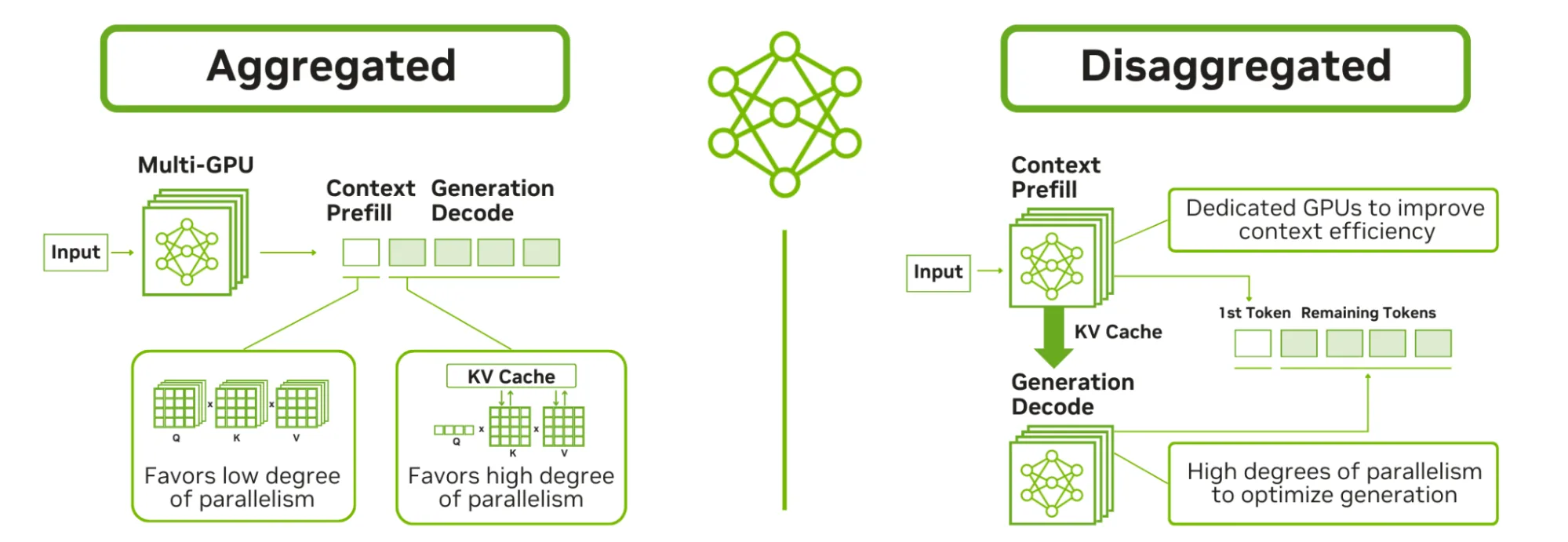
在深入研究 Kubernetes manifests 之前,它有助于了解 LLM 的两种推理部署模式:在聚合服务中,单个进程 (或紧密合的进程组) 处理从输入到输出的整个推理生命周期。解服务将工作流划分为不同的阶段,例如预填充、解码和路由,每个阶段都作为独立的服务运行 (请参见下面的图 1) 。
聚合推理
在传统的聚合设置中,单个模型服务器 (或并行配置中经过协调的服务器组) 会处理完整的请求生命周期。用户提示输入,服务器将其标记化,运行预填充以构建上下文,以自回归方式 (解码) 生成输出 tokens,并返回响应。一切都发生在单个进程或紧密合的 Pod 组中。
这在概念上很简单,适用于许多用例。但这意味着您的硬件可以在两种截然不同的工作负载之间交替使用:预填充是计算密集型工作负载,可受益于高浮点运算 (FLOPS) ,而解码则受内存带宽限制,可受益于大容量、快速的内存。
分类推理
分解架构将这些阶段分离为不同的服务:
- 预填充工作者处理输入提示。这是计算密集型问题。您希望充分利用 GPU 以实现高吞吐量,并且可以积极地进行并行化。
- 解码工作线程每次生成一个输出 tokens。由于 LLM 的自回归性质,这是受内存带宽限制的。您需要能够快速访问高带宽内存 (HBM) 的 GPU。
- 路由器/ 网关引导传入请求,管理预填充和解码阶段之间的键值 (KV) 缓存路由,并处理工作节点中请求的负载均衡。
为何要解?脱颖而出的原因有三个:
- 每个阶段不同的资源和优化配置文件:借助解聚,您可以将 GPU 资源、模型分片技术和批量大小与每个阶段的需求相匹配,而不是在单一方法上做出妥协。
- 独立扩展:预填充和解码流量模式各不相同。长上下文提示词会产生大量的预填充突发,但会产生稳定的解码流。通过独立扩展每个阶段,您可以对实际需求做出响应。
- 更高的 GPU 利用率:分离阶段可让每个阶段使其目标资源达到饱和 (计算预填充、解码内存带宽) ,而不是交替使用。
NVIDIA Dynamo 和 llm-d 等框架都采用了这种模式。问题是:如何在 Kubernetes 上进行编排?
为什么调度是 Kubernetes 上多 pod 推理性能的关键
部署多 pod 推理工作负载 (模型并行聚合模型或分解模型) 只是其中的一半。调度程序在集群中放置 pod 的方式直接影响性能;将 Tensor Parallel (TP) 组的 pod 放置在具有高带宽 NVIDIA NVLink 互连的同一机架上可能意味着快速推理与网络瓶颈之间的区别。三种调度功能在此最为重要:
- 分组调度可确保以全部或全部语义放置组中的所有 POD,从而防止浪费 GPU 的部分部署。
- 分层群组调度将基本的群组调度扩展到多级工作负载。在解推理中,您需要为每个组件或角色提供最低保证:每个 Tensor Parallel 组 (例如,四个 POD 组成一个解码实例) 必须以原子方式调度,整个系统 (至少 n 个预填充实例+ 至少 m 个解码实例+ 路由器) 也需要系统级协调。如果不这样做,一个角色可以使用所有可用的 GPU,而另一个角色则会无限地等待,即部分部署可容纳资源,但无法服务请求。
- 拓扑感知放置可在具有高带宽互连的节点上对紧密合的POD进行共置,从而更大限度地降低节点间通信延迟。
这三种功能决定了 AI 调度程序 (例如 KAI Scheduler) 如何根据应用的调度限制来放置 Pod。此外,对于 AI 编排层而言,确定需要进行分组调度的内容以及时间也很重要。例如,当预填充独立扩展时,需要在不中断现有解码 POD 的情况下,确定新 POD 组成具有最低可用性保证的小组。因此,编排层和调度程序需要在整个应用生命周期中紧密协作,处理多级自动扩展、滚动更新等,以确保 AI 工作负载的最佳运行时条件。
这正是更高级别的工作负载抽象派上用场的地方。APIs 如 LeaderWorkerSet (LWS) 和 NVIDIA Grove 允许用户以声明方式表达其推理应用的结构:存在哪些角色、它们之间的关系、它们应如何扩展以及哪些拓扑约束条件重要。API 的 Operator 会将该应用级意图转换为具体的调度约束条件 (包括 PodGroups、gang requirements、拓扑提示) ,以确定要创建和何时创建的群组。
KAI Scheduler 在满足这些约束条件方面发挥着关键作用,解决以下问题:帮调度、分层帮调度和拓扑感知放置。在本文中,我们使用 KAI 作为调度程序,不过社区中还有其他调度程序支持这些功能的子集。读者可以通过云原生计算基金会 (CNCF) 生态系统探索更广泛的调度环境。
部署解推理
分解架构具有多个角色,每个角色都有不同的资源配置文件和扩展需求。由于分解工作流中的每个角色都是不同的工作负载,因此 LWS 的一种自然方法是为每个角色创建单独的资源。
预填充工作节点 (四个副本,2 度张量并行) :
apiVersion: leaderworkerset.x-k8s.io/v1kind: LeaderWorkerSetmetadata: name: prefill-workersspec: replicas: 4 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: prefill-leader spec: containers: - name: prefill image: <model-server-image> args: ["--role=prefill", "--tensor-parallel-size=2"] resources: limits: nvidia.com/gpu: "1" workerTemplate: spec: containers: - name: prefill image: <model-server-image> args: ["--role=prefill"] resources: limits: nvidia.com/gpu: "1" |
解码工作节点 (两个副本,4 度张量并行) :
apiVersion: leaderworkerset.x-k8s.io/v1kind: LeaderWorkerSetmetadata: name: decode-workersspec: replicas: 2 leaderWorkerTemplate: size: 4 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: decode-leader spec: containers: - name: decode image: <model-server-image> args: ["--role=decode", "--tensor-parallel-size=4"] resources: limits: nvidia.com/gpu: "1" workerTemplate: spec: containers: - name: decode image: <model-server-image> args: ["--role=decode"] resources: limits: nvidia.com/gpu: "1" |
路由器 (标准部署,无需 leader-worker 拓扑) :
apiVersion: apps/v1kind: Deploymentmetadata: name: routerspec: replicas: 2 selector: matchLabels: app: router template: metadata: labels: app: router spec: containers: - name: router image: <router-image> env: - name: PREFILL_ENDPOINT value: "prefill-workers" - name: DECODE_ENDPOINT value: "decode-workers" |
每个角色都作为自己的资源管理。您可以独立扩展、预填充和解码,并根据不同的计划进行更新。
需要注意的是,调度程序将预填充工作负载和解码工作负载视为独立的工作负载。调度程序会成功放置这些数据集,但却无法知晓这些数据集是否构成了单个推理工作流。在实践中,这意味着以下几点:
- 在预填充和解码 (将其放置在同一机架上以实现快速 KV 缓存传输) 之间的拓扑协调需要手动添加在两个 LWS 资源中引用标签的 POD 亲和性规则。
- 扩展一个角色并不会自动将另一个角色考虑在内:如果突发的长上下文请求需要更多的预填充能力,您可以扩展预填充工作者,但新的预填充 Pod 不能保证靠近现有的解码 Pod,除非您自己配置了 Affinity。
- 推出新的模型版本意味着在三个独立资源之间协调更新 – LWS 的分区更新机制支持对每个资源进行分阶段部署,但跨资源的同步由外部管理。
最后一点值得注意。推理框架动作迅速,并不总是保证版本之间的向后兼容性,因此旧版本上的预填充 Pod 和新版本上的解码 Pod 可能无法通信。模型的加载也需要时间,预填充和解码工作节点通常会以不同的速度准备就绪。在不同步的部署过程中,这可能会造成暂时的不平衡,许多新的解码 POD 已准备就绪,但很少有新的预填充 POD (反之亦然) 。这可能会在推理工作流中造成瓶颈,直到一切顺利为止。
这些模式是有效的。协调只发生在 Kubernetes 基元之外:在推理框架的路由层、自定义自动缩放器、定制运算符中,甚至是手动进行。另一种选择是使用 Grove 的 API,该 API 采用不同的方法,将该协调转移到 Kubernetes 资源本身。
它在单个 PodCliqueSet 中表示所有角色:
apiVersion: grove.io/v1alpha1kind: PodCliqueSetmetadata: name: inference-disaggregatedspec: replicas: 1 template: cliqueStartupType: CliqueStartupTypeExplicit terminationDelay: 30s cliques: - name: router spec: roleName: router replicas: 2 podSpec: schedulerName: kai-scheduler containers: - name: router image: <router-image> resources: requests: cpu: 100m - name: prefill spec: roleName: prefill replicas: 4 startsAfter: [router] podSpec: schedulerName: kai-scheduler containers: - name: prefill image: <model-server-image> args: ["--role=prefill", "--tensor-parallel-size=2"] resources: limits: nvidia.com/gpu: "1" autoScalingConfig: maxReplicas: 8 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - name: decode spec: roleName: decode replicas: 2 startsAfter: [router] podSpec: schedulerName: kai-scheduler containers: - name: decode image: <model-server-image> args: ["--role=decode", "--tensor-parallel-size=4"] resources: limits: nvidia.com/gpu: "1" autoScalingConfig: maxReplicas: 6 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 80 topologyConstraint: packDomain: rack |
Grove Operator 为每个角色管理 PodCliques,并协调所有角色的调度、启动和生命周期。YAML 中需要注意的几点:
startsAfter:【router】在预填充和解码时,系统会告知操作员在路由器准备就绪之前为其启动打开大门。这一点以声明方式表示,并通过 init 容器执行。首次部署时,路由器 POD 会先启动并准备就绪,然后预填充和解码 POD 会并行启动 (因为两者都依赖于路由器) 。autoScalingConfig您可以在每个集群中定义每个角色的扩展策略。操作员为每个模型创建水平 Pod 自动缩放器 (HPA) ,因此可以根据自己的指标独立地预填充和解码缩放。topology 使用 packDomain 约束:rack 告知 KAI Scheduler 将所有 Clie 打包到同一机架中,从而通过高带宽互连优化预填充和解码阶段之间的 KV 缓存传输。
应用此清单后,您可以检查 Grove 创建的所有资源:
$ kubectl get pcs,pclq,pg,podNAME AGEpodcliqueset.grove.io/inference-disaggregated 45sNAME AGEpodclique.grove.io/inference-disaggregated-0-router 44spodclique.grove.io/inference-disaggregated-0-prefill 44spodclique.grove.io/inference-disaggregated-0-decode 44sNAME AGEpodgang.scheduler.grove.io/inference-disaggregated-0 44sNAME READY STATUS AGEpod/inference-disaggregated-0-router-k8x2m 1/1 Running 44spod/inference-disaggregated-0-router-w9f4n 1/1 Running 44spod/inference-disaggregated-0-prefill-abc12 1/1 Running 44spod/inference-disaggregated-0-prefill-def34 1/1 Running 44spod/inference-disaggregated-0-prefill-ghi56 1/1 Running 44spod/inference-disaggregated-0-prefill-jkl78 1/1 Running 44spod/inference-disaggregated-0-decode-mn90p 1/1 Running 44spod/inference-disaggregated-0-decode-qr12s 1/1 Running 44s |
一个 PodCliqueSet、三个 PodCliques (每个角色一个) 、一个用于协调调度的 PodGang,以及匹配每个角色副本数量的 Pod。这个startsAfter通过 init 容器强制执行依赖关系:预填充和解码 pod 在路由器准备就绪后才启动主容器。
扩展分解的工作负载
在运行解工作负载后,扩展成为核心运营挑战。预填充和解码存在不同的瓶颈;团队可能希望根据到第一个 token (TTFT) 的时间自动扩展预填充工作流,并独立基于 inter-token 延迟 (ITL) 对工作流进行解码,以满足服务水平协议 (SLA) 的要求,同时更大限度地降低 GPU 成本。
在实践中,分解扩展在三个级别上运行:
- 按角色扩展:在单个角色中添加或删除 Pod (例如。将预填充副本从 4 个扩展到 6 个)
- 按 TP 组扩展: 将完整的 Tensor Parallel 组扩展为原子单元,因为您无法添加半个 TP 组。
- 跨角色协调: 当您添加预填充容量时,您可能还需要扩展路由器以处理更高的吞吐量,或者扩展解码以消耗额外的预填充输出。
不同的工具适用于不同的级别。
推理框架如何协调扩展
推理框架可通过自定义自动缩放器解决应用级别的扩展问题,这些自动缩放器可监控特定于推理的指标。llm-d 的工作负载变体自动缩放器 (WVA) 可通过 Prometheus 监控每个 Pod 的 KV 缓存利用率和队列深度,并使用闲置容量模型来确定何时应添加或删除副本。WVA 不会直接扩展部署,而是会将目标副本数量作为基于 HPA/ Kubernetes 的标准事件驱动自动缩放 (KEDA) 所遵循的 Prometheus 指标,从而将缩放驱动保留在 Kubernetes 原生基元中。
NVIDIA Dynamo 规划器采用了一种不同的方法:它原生理解解服务,运行单独的预填充和解码缩放循环,分别针对 TTFT 和 ITL SLA。它使用时间序列模型预测未来的需求,根据分析的每个 GPU 吞吐量曲线计算副本需求,并在两个角色之间强制实施全球 GPU 预算。
这种全局可见性很重要,因为在实践中,预填充和解码之间的最佳比率会随着请求模式的变化而改变。在不进行缩放解码的情况下将预填充扩展为原来的 3 倍,而额外的输出也无济于事 – 解码瓶颈和 KV 缓存传输队列增加。应用级自动缩放器可以处理此问题,因为它们可以看到完整的工作流;针对单个资源的 Kubernetes 原生 HPA 本身并不能保持跨资源比率。
使用单独的 LWS 资源进行扩展
每个角色使用一个 LWS,您可以独立扩展每个角色:
kubectl scale lws prefill-workers --replicas=6kubectl scale lws decode-workers --replicas=3 |
标准 HPA 可以单独针对每个 LWS,或者外部自动缩放器 (如 Dynamo 规划器或 llm-d 的自动缩放器) 可以协调决策和更新。协调逻辑位于自动缩放器中,而非 Kubernetes 资源本身。
使用 Grove 进行扩展
Grove 将每个角色的扩展功能整合到单个资源中。每个 PodClique 都有自己的副本数量和可选项autoScalingConfig因此,HPA 可以根据每个角色的指标独立管理角色:
kubectl scale pclq inference-disaggregated-0-prefill --replicas=6 |
操作员创建额外的预填充 Pod,同时保持路由器和解码不变:
NAME AGEpodclique.grove.io/inference-disaggregated-0-router 5mpodclique.grove.io/inference-disaggregated-0-prefill 5mpodclique.grove.io/inference-disaggregated-0-decode 5mNAME READY STATUS AGEpod/inference-disaggregated-0-router-k8x2m 1/1 Running 5mpod/inference-disaggregated-0-router-w9f4n 1/1 Running 5mpod/inference-disaggregated-0-prefill-abc12 1/1 Running 5mpod/inference-disaggregated-0-prefill-def34 1/1 Running 5mpod/inference-disaggregated-0-prefill-ghi56 1/1 Running 5mpod/inference-disaggregated-0-prefill-jkl78 1/1 Running 5mpod/inference-disaggregated-0-prefill-tu34v 1/1 Running 12s # newpod/inference-disaggregated-0-prefill-wx56y 1/1 Running 12s # newpod/inference-disaggregated-0-decode-mn90p 1/1 Running 5mpod/inference-disaggregated-0-decode-qr12s 1/1 Running 5m |
六个预填充 POD、两个路由器 POD、两个解码 POD,仅对预填充进行了更改。
对于在内部使用多节点 Tensor Parallelism 的角色,PodCliqueScalingGroup 可确保多个 PodCliques 作为一个单元一起扩展,同时保留它们之间的复制比。例如,在每个预填充实例由一个 leader pod 和四个 worker pod 组成的配置中:
podCliqueScalingGroups: - name: prefill cliqueNames: [pleader, pworker] replicas: 2 minAvailable: 1 scaleConfig: maxReplicas: 4 |
对于副本:二,这将创建两个完整的预填充实例:两个 x (一个领导者+ 四个工作者) = 总共 10 个 POD。这个最小可用:1保证意味着系统不会扩展到一个完整的 Tensor Parallel 组以下。
将群组从两个副本扩展到三个副本可添加第三个完整实例,同时保持 1:4 的领导者与员工比率:领导者与员工比率:
$ kubectl scale pcsg inference-disaggregated-0-prefill --replicas=3 |
领导者和工人派系共同组成一个整体,新的复制品 ( prefill-2) 有一个请求者POD 和 4工作者pod,匹配比率。我们为第三个副本创建了一个新的 PodGang,以确保它得到轮班调度。
NAME AGEpodcliquescalinggroup.grove.io/inference-disaggregated-0-prefill 10mNAME AGEpodclique.grove.io/inference-disaggregated-0-prefill-0-pleader 10mpodclique.grove.io/inference-disaggregated-0-prefill-0-pworker 10mpodclique.grove.io/inference-disaggregated-0-prefill-1-pleader 10mpodclique.grove.io/inference-disaggregated-0-prefill-1-pworker 10mpodclique.grove.io/inference-disaggregated-0-prefill-2-pleader 8s # newpodclique.grove.io/inference-disaggregated-0-prefill-2-pworker 8s # newNAME AGEpodgang.scheduler.grove.io/inference-disaggregated-0 10mpodgang.scheduler.grove.io/inference-disaggregated-0-prefill-0 10mpodgang.scheduler.grove.io/inference-disaggregated-0-prefill-1 8s # new |
开始使用
无论您是运行单个解管道,还是在集群中运行数十个,这方面的基础模组都在不断涌现,社区正在以开放的方式构建它们。本博客中的每种方法都代表了简单性和集成协调性之间的不同点。
正确的选择取决于您的工作负载、团队的运营模型,以及您希望平台处理的生命周期管理与应用层之间的关系。
有关更多信息,请查看这些资源。
与我们一起参加 Kubecon EU
如果您要参加在阿姆斯特丹举办的 KubeCon EU 2026,请亲临展位号 241 并 参加会议,我们将介绍一个端到端开源 AI 推理堆栈。探索 Grove 部署指南,并在 GitHub 或 Discord 上提问。我们很想听听您对 Kubernetes 上的分解推理有何看法。




