
NVIDIA Run:ai v2.24 引入了基于时间的公平分享,这是一种全新的调度模式,可为 Kubernetes 集群实现公平分享调度,并提供对超配额资源的时间感知能力。该功能基于开源 KAI Scheduler 构建,为 NVIDIA Run:ai 提供支持,有效应对共享 GPU 基础设施中的长期挑战。
假设两个优先级相同的团队共享一个集群。团队 A 持续提交规模较小的作业,而团队 B 则需要运行占用更多资源的大型作业。每当有资源被释放时,团队 A 的小型作业便会立即适配并被调度执行。由于团队 B 的大型作业仍在等待足够的资源,尚未开始运行,而此时团队 A 的下一个小作业又将请求资源并占据释放出的容量。结果,尽管两个团队具有相同的优先级和资源使用权,团队 A 卻能够接连不断地执行任务,而团队 B 的作业则可能长期停留在队列中,无法获得执行机会。
基于时间的 fairshare 通过引入调度程序的内存机制来解决此问题。调度程序不再立即计算公平比例,而是持续跟踪历史资源使用情况,并依据各队列过去的资源消耗动态调整分配权重。近期使用较多资源的团队,在超额分配时获得的优先级评分较低,而长期等待资源的团队则会得到相应的优先级提升。
基于时间的公平分享结果按天和周的时间比例进行计算。这实现了 GPU 资源的真正时间共享、对偶发大型作业的突发访问支持,以及与每周或每月 GPU 小时预算相匹配的资源规划。重要的是,原有的保证配额和队列优先级机制仍保持不变,继续发挥作用。
本文将更详细地阐述该问题,介绍实际应用案例,并演示如何在 NVIDIA Run:ai 和 KAI Scheduler 中启用基于时间的公平共享功能。
为什么超额 GPU 资源公平性很重要?
企业部署已呈现出一致的模式:当组织从静态 GPU 分配转向动态调度时,集群的使用会变得更加动态。超额资源(超出保证配额的共享池)成为利用率较高的资源类型之一。团队经常超出其保证的分配,从而提升 GPU 利用率,并为研究人员提供更多的计算时间。
这使得超额公平至关重要。当集群值的很大一部分来源于此共享池时,需在时间维度上对该池进行公平分配。
无状态公平共享调度的工作原理是什么?
经典的无状态公平共享算法将集群资源划分为两个阶段。首先,分配适当的配额,即每个队列有权获得的有保证资源。这一分配始终优先进行,且不受历史使用情况的影响。基于时间的公平分享不会改变这一行为。
满足应得的配额后,任何剩余容量将构成 Over-Quota 池,供各队列依据其权重竞争使用。这正是时间点公平性失效的原因。
划分超出配额的资源时,调度程序:
- 按优先级层级对队列进行分组,并从高优先级开始
- 依据该层级中的权重计算公平份额:
- 占用率低于合理比例的队列优先获取资源
- 以工作负载提交时间作为排序依据,打破资源竞争中的并列情况
- 若仍有剩余资源,则进入下一优先级层级并重复上述过程

这就是问题的关键。请考虑以下两种争夺超额配额资源的队列类型。
当队列权重相同时:两者获得相等的计算公平比例。作业完成后资源释放,两个队列进入完全相同的状态——分配相同(均为零)、公平共享相同,且均有待处理的作业。调度程序无法区分二者,将回退至 Tie-Breaker(按队列创建时间,再按字母顺序排序),导致同一队列始终胜出。
当队列的权重不同时:权重较高的队列会获得较大的公平比例,这是正确的。但时间点计算并不跟踪队列是否会随着时间的推移实际获得相应的比例。例如,若队列 A 的权重为 3,而队列 B 的权重为 1,则调度程序会正确计算出 A 有权获得 75% 的超出配额资源(3/4),B 有权获得 25%(1/4)。然而,若队列 A 提交大量工作负载,而队列 B 提交许多较小的工作负载,则队列 B 可能更容易接近其公平比例,而队列 A 的大型作业则使其难以迅速达到该比例。由于队列 B 在每个决策点均显示“未充分分配”,调度程序会持续优先考虑队列 B。随着时间推移,队列 B 最终运行的工作负载可能远超其 25% 的授权份额。
在这两种情况下,调度程序都缺乏内存,无法得知一个团队刚完成任务,而另一个团队已等待数小时。
基于时间的公平分享是如何运作的?
基于时间的公平分享的核心理念很简单:针对每个队列,将其在配置时间窗口内实际消耗的超出配额的资源比例,与其根据权重应得的比例进行比较,然后据此作出相应调整。
例如,若队列 A 的权重为 3,队列 B 的权重为 1,则队列 A 应获得 75% 的超额资源,队列 B 应获得 25% 的资源。如果调度程序回顾上周的情况,发现队列 A 实际消耗了 90% 的资源,而队列 B 仅获得 10% 的资源,便会提高队列 B 的有效权重,同时降低队列 A 的有效权重,以调整未来的资源分配,使其趋向于 75/25 的比例。
其他一切均保持不变。应享的配额仍会优先得到保障。优先级排序依然适用。队列的层次结构运作方式与以往相同。基于时间的公平共享仅会改变超出配额部分的分配方式。
如何计算基于时间的公平分享?
调度程序利用三个输入来调节每个队列的有效权重:
- 权重: 根据队列相对于其他队列的配置权重,队列应获得的份额
- 用法:队列在可配置时间窗口内实际消耗的时间(默认值:一周)
- K 值: 调度程序用于纠正资源分配偏差的强度。数值越高,表示校正速度越快
当队列消耗超过合理比例时,其有效权重会相应降低;而当队列出现饥饿时,其有效权重则会逐步增加。通过这种机制,资源分配能够随着时间推移自然回归至预期比例。
可以直接从用户界面启用或禁用基于时间的公平共享(请参阅 NVIDIA Run:ai 文档的节点池部分),同时可通过 API 调整窗口大小、窗口类型和衰减率等参数,以平衡响应速度与稳定性。由于这些设置按节点池进行配置,管理员可在专用节点池中进行实验,而不会影响集群的其余部分。如需了解完整详情,请参阅 基于时间的公平共享文档。
一些值得注意的细节:
- 使用情况依据集群容量进行衡量,而非参照他人的使用状况,从而避免团队因利用闲置 GPU 而受到处罚。
- 优先级始终居于首位。基于时间的公平共享机制在各优先级内部运行,高优先级队列无论历史使用情况如何,都将优先于低优先级队列获得资源。
示例场景:一个集群,多种工作负载类型
本节将介绍一个真实场景,展示基于时间的公平共享机制如何解决异构集群中的资源争用问题。
一个 100-GPU 集群由两个机器学习团队共享,这两个团队的工作负载模式截然不同。LLM 团队专注于后训练和推理,保证分配 30 个 GPU;Vision 团队专注于计算机视觉研发,保证分配 20 个 GPU。两个团队的超配额权重相同,超额配额池中剩余的 50 个 GPU 可用于突发工作负载。
LLM 团队负责运行面向客户的推理端点,为生产流量提供服务。这些推理工作负载持续占用 10 个 GPU,至关重要,必须保证不间断运行。当团队需要根据客户反馈对模型进行优化时,可使用配额内剩余的 20 个 GPU 以及超配额池中的资源。
Vision 团队专注于计算机视觉研究:运行 VSCode、测试架构、执行超参数扫描以及训练物体检测模型。团队持续接收训练任务,这些任务会定期使用过配额池。
问题:突发访问被阻止
有一天,LLM 团队完成了对一批客户反馈的分析,并准备启动训练后运行任务。该任务需要 60 个 GPU,包括 20 个常规配额 GPU 和来自超配额池的 40 个 GPU。下文概述了采用与不采用基于时间的公平分享机制的情况。
为说明此场景,我们采用了 KAI Scheduler 中基于时间的开源公平共享模拟器。借助该工具,可对不同的集群配置进行建模,并直观展示资源分配情况。以下模拟准确呈现了示例场景中的实际状况。
为说明此场景,我们采用了 KAI Scheduler 中基于时间的开源公平共享模拟器。借助该工具,可对不同的集群配置进行建模,并直观展示资源分配情况。以下模拟准确呈现了示例场景中的实际状况。
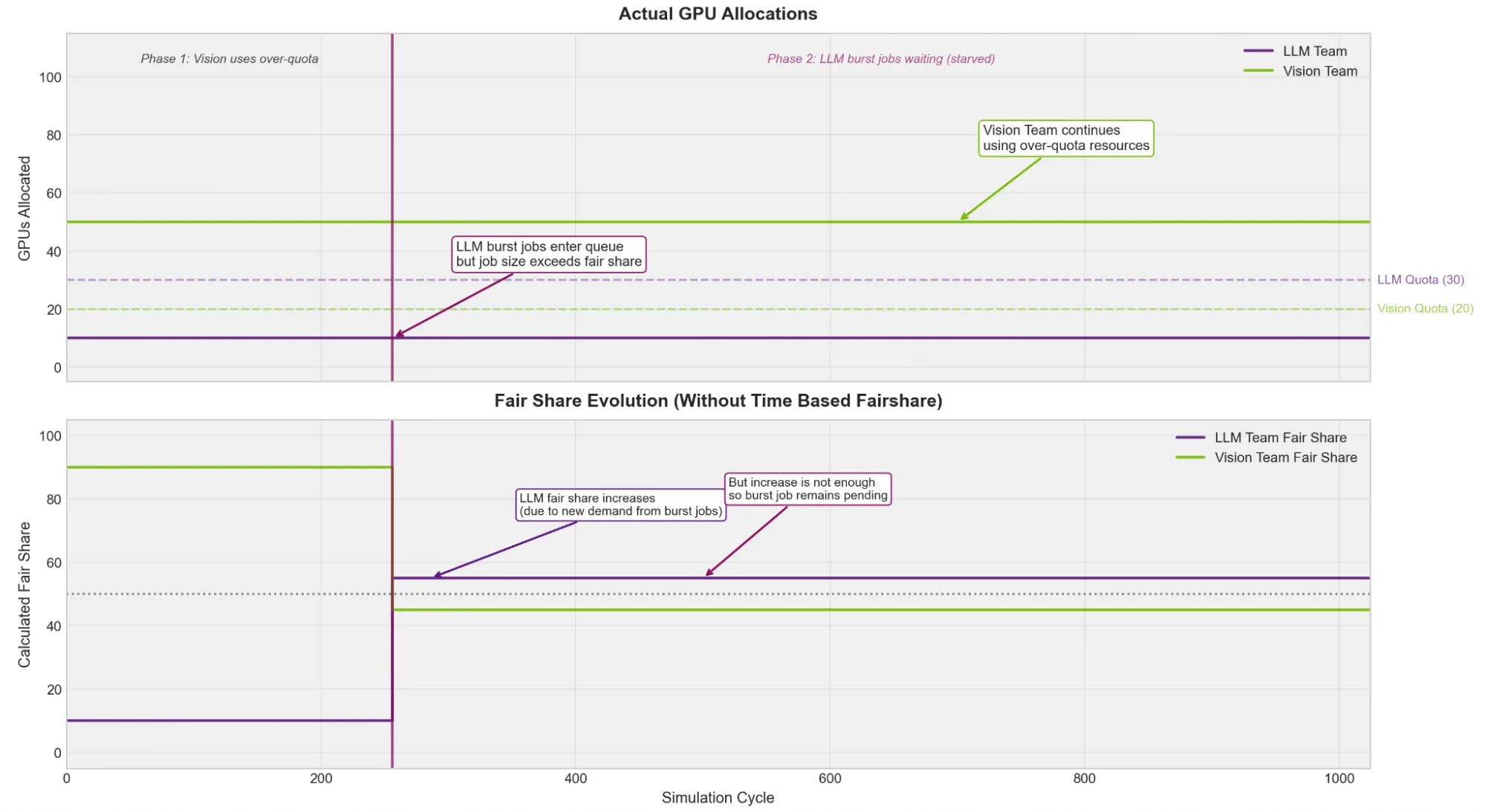
无基于时间的公平分享
- LLM 团队的推理端点持续在其 10 个有保证的 GPU 上运行(应有的配额受到保护)。
- Vision 团队一直在执行 CV 训练作业,消耗了超额资源。
- LLM 团队的 60-GPU 后训练任务已进入队列。
- 每当有超出配额的资源可用时,Vision 团队便立即提交更多待处理作业。
- Vision 团队的工作始终被优先调度。这种情况的发生,是因为 LLM 团队申请的 40-GPU 超额资源超出了其合理的比例。调度程序不会为超出合理比例的任务分配资源,而 Vision 团队仍有待处理的作业需要相应资源分配。
- 因此,LLM 团队的后训练任务只能持续等待、等待和等待。
LLM 团队的推理服务表现良好,且配额保障机制十分有效。然而,由于部分持续高负载的团队独占了超额配额池,导致其他团队的后训练任务实际上难以满足需求,偶尔使用的用户更是始终无法获得资源。
采用基于时间的公平分享
有关在节点池下配置基于时间的 fairshare,请参阅 NVIDIA Run:ai 文档 或 KAI 调度程序文档。
借助基于时间的公平共享机制,调度程序能够跟踪历史使用情况。当 LLM 团队提交训练后的工作任务时:
- 视觉团队在持续的 CV 训练中积累了大量的历史超额使用情况
- LLM 团队的过配额使用情况极少(他们一直稳定在配额范围内运行作业)
- 由于 LLM 团队曾因配额受限而处于“饥饿”状态,其有效公平份额因此得到提升
- LLM 团队的 60-GPU 作业已如期启动
如果后训练作业运行时间足够长,两个团队最终会共享超出配额的资源。LLM 团队先运行一段时间,使用次数持续增加。随着其历史使用率上升,视觉团队相对变得更加饥饿,从而开始获得更高的优先级。资源分配会在两者之间来回波动(有时 LLM 作业运行,有时 Vision 作业运行),最终实现随时间推移的公平共享,避免某个团队独占整个资源池。
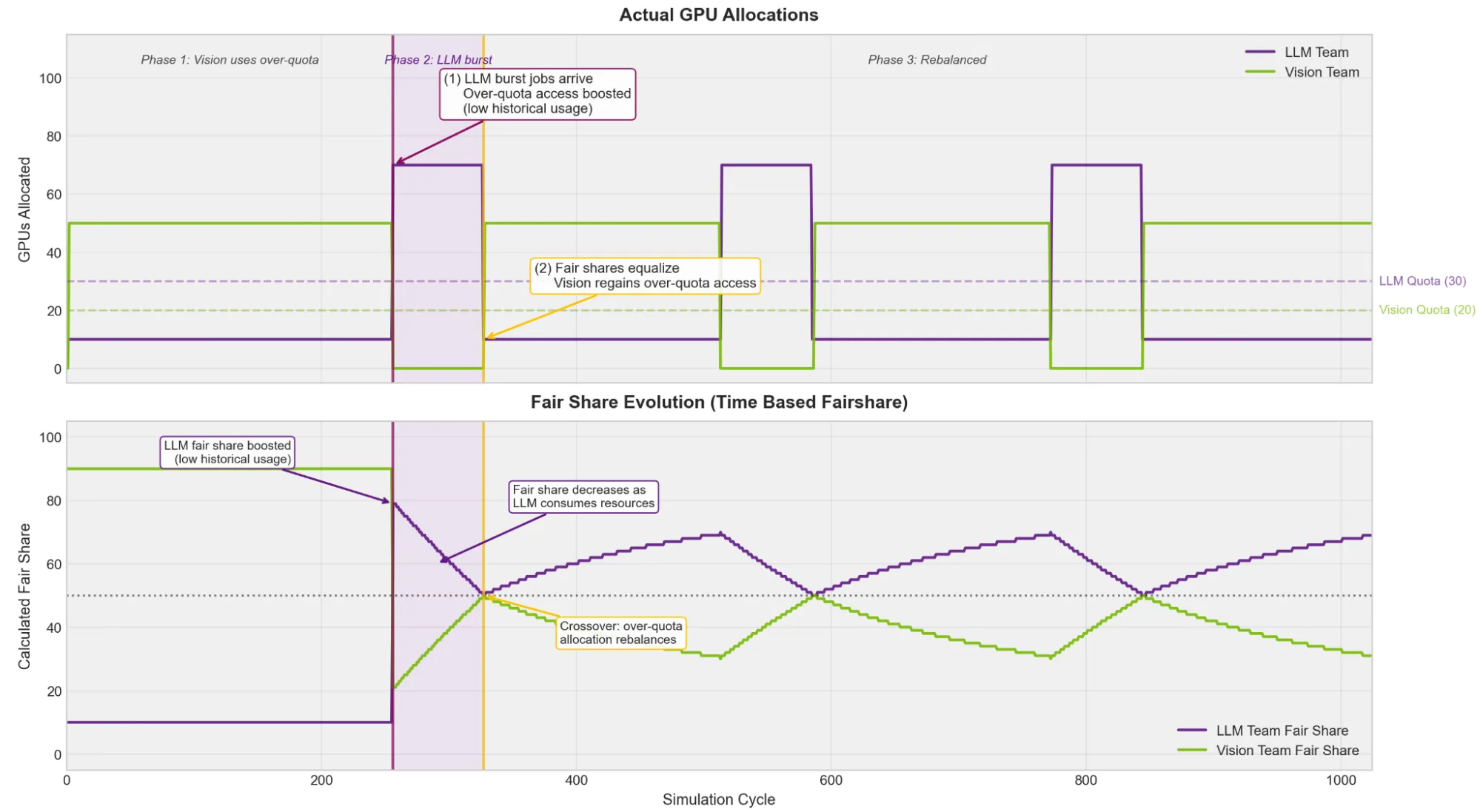
基于时间的公平分享实现了若干重要模式,包括:
- 受保护的关键工作负载:推理端点及其他生产服务在有保障的配额上运行,完全不受公平性调整的影响。
- 需要时突发访问:不持续消耗超额资源的团队仍可在需要时获得突发访问能力,而不会长时间甚至永久受阻。
- 随着时间的推移实现公平分配:任何团队都不会无限期地独占超额配额池。在设定的时间窗口内,资源将按比例分配给所有团队。
- 更公平地处理大型工作负载:在时间点公平分配机制下,执行大型任务的队列通常会被降低优先级,因为其他队列中的较小任务更容易匹配资源。基于时间的公平分享(fairshare)机制改善了这一情况:由于承载大型任务的队列累积使用量较少,其优先级会随着时间推移逐步提升,从而获得运行机会。
开始使用 NVIDIA Run:ai 实现基于时间的公平资源共享
基于时间的公平分享解决了时间点公平分享调度中的一个基本限制:缺乏内存。通过追踪历史使用情况,调度程序能够在不同时间窗口内公平地分配超出配额的资源,而不仅限于每次调度决策时的即时分配。有保证的配额保持不变——推理端点等关键工作负载始终受到保护。
准备开始了吗?NVIDIA Run:ai v2.24 支持基于时间的公平共享,并可通过平台用户界面轻松配置。相关设置按节点池进行,因此您可以在专用池中自由开展实验,而不会对整个集群引入新的调度模式。有关详细信息,请参阅基于时间的公平共享文档。
开源 KAI Scheduler 中提供了基于时间的公平共享功能。完成 配置步骤,启用 Prometheus,设置相关参数,然后启动调度任务。
想要在部署前试用基于时间的公平分享?请查看 基于时间的公平分享模拟器,在其中可对随时间变化的队列分配进行建模。只需在简单的 YAML 文件中定义您的队列、权重和工作负载,运行模拟,即可可视化资源在相互竞争的团队之间的动态分配情况。
要深入了解 NVIDIA Run:ai v2.24 版本中基于时间的公平共享及其他功能,请参加即将举办的网络研讨会,通过简化工作负载管理提升您的 AI 运营效率。




