
如果您的 AI 智能体能够像读取文本文件一样轻松地即时解析复杂的 PDF、提取嵌套表格并“查看”图表中的数据,该怎么办?借助 NVIDIA Nemotron RAG,您可以构建高吞吐量的智能文档处理工作流,精准应对大规模文档处理任务。
本文将逐步介绍多模态检索工作流的核心组件。首先,我们将展示如何利用开源的 NVIDIA NeMo Retriever 库,通过 GPU 加速的微服务将复杂文档分解为结构化数据。接着,演示如何将这些数据与 Nemotron RAG 模型连接,确保您的助手能够提供有依据、准确且可完全追溯至来源的回答。
我们来深入了解一下。
模型和代码的快速链接
访问本教程的以下资源:
🧠 Hugging Face 上的模型:
- nvidia/llama-nemotron-embed-vl-1b-v2 多模态嵌入模型
- nvidia/llama-nemotron-rank-vl-1b-v2 交叉编码器重排序模型
- 源自 Nemotron RAG 系列的模型提取
☁️ 云端点:
代码和文档:
- NeMo 检索器库 (GitHub)
- 教程 Notebook 可在 GitHub 上获取
预备知识
要学习本教程,您需要以下内容:
系统要求:
- Python 3.10 至 3.12(已在 3.12 版本上测试)
- 配备至少 24 GB VRAM 的 NVIDIA GPU,用于本地模型部署
- 250 GB 磁盘空间(适用于模型、数据集和向量数据库)
API 访问:
- NVIDIA API 密钥(前往 build.nvidia.com 获取免费访问权限)
Python 环境:
[project]
name = "idp-pipeline"
version = "0.1.0"
description = "IDP Nemotron RAG Pipeline Demo"
requires-python = "==3.12"
dependencies = [
"ninja", "packaging", "wheel", "requests", "python-dotenv", "ipywidgets", # Utils
"markitdown", "nv-ingest==26.1.1", "nv-ingest-api==26.1.1", "nv-ingest-client==26.1.1", # Ingest
"milvus-lite==2.4.12", "pymilvus", "openai>=1.51.0", # Database & API
"transformers", "accelerate", "pillow", "torch", "torchvision", "timm" # ML Core
]
所需时间:
完整实现需要一到两个小时(若需编译 flash-attn 等 GPU 优化的依赖,则耗时更长)
内容:面向文档处理的生产级多模态 RAG 工作流
本教程以可在 GitHub 上启动的 Jupyter Notebook 形式提供,方便您动手实践。以下是构建过程的概述。
- 解锁捕获的数据: 首先利用 NeMo Retriever 库 从复杂文档中提取关键信息。
- 上下文感知编排: 通过微服务架构分解文档,优化 Nemotron RAG 模型的数据处理流程,构建高效且具备上下文理解能力的系统。
- 高吞吐量转换: 借助 GPU 加速计算与 NVIDIA NIM 微服务 扩展工作负载,实现大规模数据集的并行转换,生成可搜索的智能内容。
- 检索精度高: 将优化后的数据输入 Nemotron RAG 模型,使 AI 智能体 能够精准定位表格或段落,可靠地响应复杂查询。
- 基于来源的可靠性: 最终集成将检索结果与助手系统连接,提供有依据的答案,并附带对特定页面或图表的透明引用。
为什么传统的 OCR 和纯文本处理难以应对复杂文档
在构建工作流之前,需充分了解标准文本提取无法应对的以下核心挑战:
- 结构复杂性:文档包含矩阵和表格,其中数据之间的关联至关重要。标准 PDF 解析器常会合并行列,破坏原有结构,将“模型 A: 95°C max”与“模型 B: 120°C max”合并为一段无法解析的文本,进而导致制造、合规性判断及决策过程中出现偏差。
- 多模态内容: 关键信息常以图表、图形或扫描图像的形式呈现,纯文本解析器难以捕捉此类内容。性能趋势、诊断结果以及流程图均需通过视觉方式准确理解。
- 引用要求: 在受监管行业中,审计追踪要求答案具备精确的出处。回应必须附带可追溯的参考信息,例如“第 4.2 节,第 47 页”,而非仅提供无来源的事实陈述。
- 条件逻辑: “如果”类规则通常跨越多个段落或页面。理解“在 0 ° C 以下使用协议 A,否则使用协议 B”这类指令,需保留文档的层级结构并支持跨页交叉引用,这对技术手册、政策文件及监管指南尤为重要。
这些挑战说明了为何 Nemotron RAG 采用专门的提取模型、结构化嵌入以及由引用支持的生成方式,而非简单的文本解析。
智能文档处理部署的关键注意事项
构建文档处理流程时,以下因素决定了其生产可行性:
- 块大小权衡:较小的块(256-512 tokens)支持精确检索,但可能丢失上下文信息;较大的块(1024-2048 tokens)可保留更完整的上下文,但会降低检索精度。对于企业文档,采用 512-1024 tokens 的块大小并配合 100-200 token 的重叠,能够在上下文保留与检索精度之间取得平衡。
- 提取深度: 需决定是按页面分割内容,还是以整个文档为单位进行处理。页面级分割有利于精确引用和来源验证,而文档级分割则有助于保留叙事逻辑和更广泛的背景信息。应根据实际需求——是侧重源位置的准确性,还是强调对整体内容的理解——做出选择。
- 表格输出格式:将表格转换为 Markdown 格式,可在保留行/列结构的同时,适配 LLM 的原生解析能力,显著减少因纯文本线性化导致的数字幻觉问题。
- 库与容器模式:库模式(SimpleBroker)适用于开发阶段及小规模文档集(约 100 个文档);在生产环境中,面对数千个文档的处理需求,应采用基于 Redis/Kafka 的容器模式,以实现系统的横向扩展与高可用性。
这些配置选择直接关系到检索的准确性、引用的精确性以及系统的可扩展性。
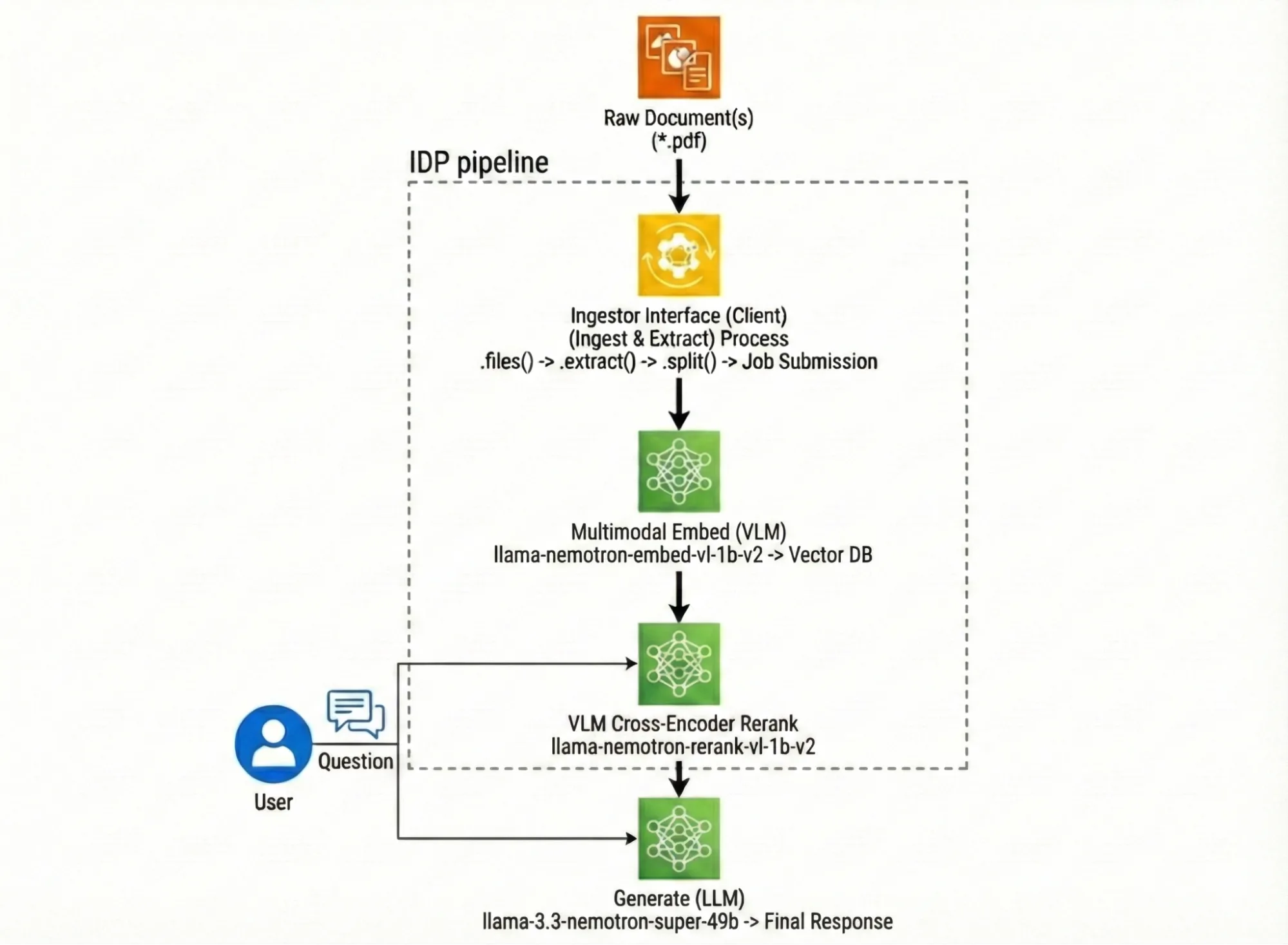
多模态 RAG 工作流包含哪些组件?
在为您的问题生成引用答案之前,智能文档处理流程分为三个主要阶段,每个阶段均有明确的输入与输出约定。
第 1 阶段:提取(Nemotron 分页元素、表格/图表提取及 OCR)
- 输入:PDF 文件
- 输出:包含结构化项目的 JSON:文本块、表格标记、图表图像
- 运行方式:支持库调用、自行托管(Docker)及远程客户端
第 2 阶段:嵌入 (llama-nemotron-embed-vl-1b-v2)
- 输入:提取的项目(文本、表格、图表图像)
- 输出:每个商品及原始内容的 2048 维向量
- 主要功能:支持多模态编码——可单独处理文本、单独处理图像,或同时处理图像与文本
- 运行方式:支持在 GPU 上本地运行,或在 NIM 上远程运行(即将推出)
第 3 阶段:重排序 (llama-nemotron-rerank-vl-1b-v2)
- 输入:嵌入搜索中的 Top-K 候选项
- 输出:排序列表(相关性由高到低)
- 主要功能:交叉编码器;可同时分析(查询、文档、可选图像)
- 运行方式:支持在 GPU 上本地运行,或通过 NIM 远程运行(即将推出)
- 为何重要:有效过滤“表面相似但实际不符”的结果;VLM 版本还能结合图像验证相关性
设置处理管道后,即可生成答案:
生成 (Llama-3.3-Nemotron-Super-49B)
- 输入:排名靠前的文档 + 用户问题
- 输出:“Grounded”(接地),引用答案
- 关键功能:遵循严格的系统提示以引用来源,承认不确定性
- 运行方式:可在本地运行,或在 build.nvidia.com 上运行 NIM
用于构建每个工作流组件的代码
尝试为文档处理工作流的各个部分添加起始代码。
提取
提取将 PDF 从“像素和布局”转换为结构化的可查询单元,因为下游的检索和推理模型若直接处理原始页面坐标和扁平化文本,将难以可靠保留其语义信息。・NeMo Retriever 库旨在通过专门的提取功能(文本、表格、图表/图形)保留文档结构(如表格、图表及图注),而非将所有内容视为纯文本。* 世界银行的“秘鲁 2017 年国家概况”构成一次强有力的压力测试,因其融合了叙述性文字、图表以及密集的附录表格——若提取能力不足,将触发与企业级 RAG 系统相同的失效模式。
# Start nv-ingest (Library Mode) and connect a local client (SimpleClient on port 7671).
print("[INFO] Starting Ingestion Pipeline (Library Mode)...")
run_pipeline(block=False, disable_dynamic_scaling=True, run_in_subprocess=True, quiet=True)
time.sleep(15) # warmup
client = NvIngestClient(
message_client_allocator=SimpleClient,
message_client_port=7671, # Default LibMode port
message_client_hostname="localhost"
)
# Submit an extraction job: keep tables as Markdown + crop charts (for downstream multimodal RAG).
ingestor = (Ingestor(client=client)
.files([PDF_PATH])
.extract(
extract_text=True,
extract_tables=True,
extract_charts=True, # chart crops
extract_images=False, # focus on charts/tables
extract_method="pdfium",
table_output_format="markdown"
)
)
job_results = ingestor.ingest()
extracted_data = job_results[0]
嵌入
嵌入将每个提取的项目转换为固定大小的向量,从而在大型文档集合中实现毫秒级的相似性搜索。采用多模态嵌入器是解锁视觉内容丰富的 PDF 的关键。由于其设计目标是将文档页面以文本、图像、以及图文混合的形式进行嵌入,因此能够检索图表和表格作为证据,而非忽略它们。在此工作流中,每个项目均以 2048 维以上的向量形式存入 Milvus,生成的前 K 个候选结果将进行重新排序。
# Vector DB contract: 2048-dim vectors + original payload/metadata stored in Milvus.
HF_EMBED_MODEL_ID = "nvidia/llama-nemotron-embed-vl-1b-v2"
COLLECTION_NAME = "worldbank_peru_2017"
MILVUS_URI = "milvus_wb_demo.db"
milvus_client = MilvusClient(MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
milvus_client.create_collection(collection_name=COLLECTION_NAME, dimension=2048, auto_id=True)
# Multimodal encoding: text-only vs image-only vs image+text (table markdown + chart/table crop).
with torch.inference_mode():
if modality == "image_text":
emb = embed_model.encode_documents(images=[image_obj], texts=[content_text])
elif modality == "image":
emb = embed_model.encode_documents(images=[image_obj])
else:
emb = embed_model.encode_documents(texts=[content_text])
# (Notebook then L2-normalizes emb[0] and inserts {vector, text, page, type, has_image, image_b64, ...} into Milvus.)
重排序
重排序是嵌入检索后应用的精度层。由于使用交叉编码器对所有文档进行排名成本过高,因此只需对嵌入模型返回的候选列表进行重新排序。多模态跨编码器重排序器对于企业 PDF 尤其有价值,因为它能够利用用户信任的相同证据(如表格和图表,可与文本一同选取)来判断相关性,从而使“看起来相似”的结果被过滤,真正包含答案的内容得以提升。在 Notebook 中,重排序从 Milvus 的命中结果开始,随后进入评分循环(此处未显示),该循环为每位候选文档分配 logits,并据此排序,生成最终的排名上下文,用于答案生成。
# Stage 1: embed query -> dense retrieve from Milvus (high recall).
with torch.no_grad():
q_emb = embed_model.encode_queries([query])[0].float().cpu().numpy().tolist()
hits = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[q_emb],
limit=retrieve_k,
output_fields=["text", "page", "source", "type", "has_image", "image_b64"]
)[0]
# Stage 2: VLM cross-encoder rerank (query + doc_text + optional doc_image) (high precision).
batch = rerank_inputs[i:i+batch_size] # list of {"question","doc_text","doc_image"} dicts (built from hits)
inputs = rerank_processor.process_queries_documents_crossencoder(batch)
inputs = {k: v.to("cuda") if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
with torch.no_grad():
logits = rerank_model(**inputs).logits.squeeze(-1).float().cpu().numpy()
# (Notebook then attaches logits as scores and sorts valid_hits descending.)
优化检索的后续步骤是什么?
随着智能文档处理管线的上线,生产路径已全面开放。该架构的优势在于其灵活性:可尝试将新数据源接入 NeMo Retriever 库,或通过专用的 NIM 微服务 提升检索准确性。
随着文档库的发展,您会发现该架构可作为可扩展的基础,用于构建能够理解企业知识细微差别的多智能体系统。通过将前沿模型与 NVIDIA Nemotron 结合,并利用 LLM 路由器进行协同,您能够在优化成本与效率的同时,维持高性能表现。此外,您还可以深入了解 Justt 如何借助 Nemotron 将提取错误率降低 25%,从而提升客户财务退款分析的可靠性。
加入使用 NVIDIA Blueprint for Enterprise RAG 构建的开发者社区。NVIDIA Blueprint 获得十余家行业领先的 AI 数据平台提供商 的信任,可在 build.nvidia.com、GitHub 和 NGC 目录 中获取。




