
在过去的 25 年中,实时渲染的发展始终由硬件的持续进步所推动。其目标是在 16 毫秒内生成尽可能高保真的图像,这一需求促进了图形硬件、工作流程以及渲染技术领域的诸多创新。
然而,随着摩尔定律的放缓,我们必须探索新的计算架构,以满足实时应用日益增长的需求。与此同时,传统图形技术正逐渐逼近性能极限,亟需创新手段来进一步提升视觉真实感与渲染效率。这带来了一个根本性难题:在无法完全依赖传统硬件进步的前提下,如何持续推动实时渲染技术的发展?
神经网络着色是一种创新性技术,能够将可训练模型直接集成到图形渲染管线中,从而在画质与性能方面实现显著提升。该技术充分利用 NVIDIA Tensor Core 等专用 AI 硬件,实现神经网络的高效实时运行。
在本博客中,我们将为您介绍基础知识,助您轻松入门这项变革性技术。
什么是神经网络着色?
神经网络着色的核心在于将图形管线中的部分环节开放给训练。这一方法可应用于任何具备参数的组件,并利用机器学习技术对这些参数进行优化。其中,最具潜力的方向是在着色器中内联执行的小型神经网络,它们能够与渲染器的其他部分协同工作,实现更高效的图形处理。
这些小型网络能够高效地实现实时运行,尤其在协作向量等技术的助力下,可实现硬件加速。一方面,这提升了现有硬件的效率,使屏幕显示效果日益复杂,而无需依赖晶体管持续微缩;另一方面,使着色器具备可训练性本身具有重要价值,因为神经网络着色器能够解决传统工作流程难以应对的问题。这为图形开发工具箱增添了一项实用的新手段,且目前仍具备显著的应用潜力。
这将如何改变这种方法?
传统工程通常涉及问题的理解、求解、编码与执行。然而,某些问题本身缺乏明确的解决方案,或其解法在实时计算中成本过高,神经网络着色便是典型例子。在这些情况下,优化方法便显得尤为重要。我们不再直接求解问题,而是利用已知的输入与输出数据,训练一个可调节的数学模型,通过迭代调整参数,逐步逼近一个近似但实用的解决方案。
现代神经网络着色可借助 Slang 等功能强大的工具实现。Slang 是一种日益成为游戏开发关键技术的着色语言,由负责开发和维护 OpenGL 与 Vulkan 等 API 的标准机构 Khronos 主导托管。该语言具备广泛的平台兼容性,支持 HLSL、SPIR-V、Metal 等多种后端。Slang 融合了现代编程语言特性,例如泛型,并支持自动微分(autodiff),这对于神经网络着色至关重要,能够实现复杂微积分运算的自动化。
SlangPy 是 Slang 的 Python 接口,提供功能全面的中等级别图形 API,可直接访问计算缓冲区、纹理等核心图形资源。它支持多种平台,涵盖 D3D12、Vulkan、CUDA 和 Metal,并具备函数式 API,允许从 Python 环境中直接调用 Slang 着色器函数。
如需动手实践,可参考 SIGGRAPH 的专题介绍实验室及相关可下载实验资料。此外,您还可以观看 Slang Birds of a Feather 会议视频,了解社区的讨论与见解。
从何处着手?:一个简单的 Mipmap 示例

我们先通过一个具体示例来说明这些概念:Mipmap 生成问题。传统的 Mipmap 适用于反射率贴图等颜色纹理,即使采用简单的框式滤波器,反射率贴图也能实现良好的下采样效果。然而,用于表示几何或拓扑结构的贴图在降低分辨率时往往表现不佳,因为无法对几何信息应用类似的简单滤波方法,也无法将原本代表凹槽或凸起的特征简单地合并为平面。
这种朴素的方法会导致镜面高光出现杂乱的伪影,从而产生原本不存在的表面细节。这一长期存在的问题已有解析性解决方案,例如 Toksvig 方法。该方法通过根据 Mipmap 层级的法线方差来调整材质的粗糙度,对法线贴图进行滤波,同时兼顾不同尺度下的几何复杂性。
尽管这些分析方法适用于特定场景,但通常需要依赖领域专业知识以及精细的参数调优。相比之下,神经优化提供了一种更具通用性的解决方案:我们可以通过生成 Mipmap,来最小化下采样渲染结果与参考的“理想”Mipmap 之间的差异,从而在无需显式进行分析推导的情况下,学习到最优的表示形式。
优化的工作原理
优化过程包括两个阶段:
- 前向阶段:采用传统方法渲染理想输出,生成实际输出,再计算理想输出与实际输出之间的差异。
- 后向阶段:利用自动微分计算如何调整输入以减小误差。
关键的见解在于,我们可以利用 Slang 的自动微分功能,在编译时自动生成整个渲染过程的反向导数。相比手动微分,这种方法更快、更便捷,并且当修改前向代码时,反向导数也能始终保持同步。
这是一个简单的示例,用于说明开发者在 Slang 中如何处理此类问题。请注意,该示例仅作说明用途,在实际运行前,需根据具体应用场景补充输入纹理数据并实现相应的 BRDF 函数。
// Define our trainable mipmap parameters
struct MaterialParameters
{
GradOutTensor<float3, 2> albedo;
GradOutTensor<float3, 2> normal;
};
// Our differentiable render function
[Differentiable]
float3 render(int2 pixel, MaterialParameters material, no_diff float3 light_dir, no_diff float3 view_dir)
{
// Bright white light
float light_intensity = 5.0;
// Sample very shiny BRDF (it rained today!)
float3 brdf_sample = sample_brdf( // assume we've implemented our BRDF elsewhere
material.get_albedo(pixel), // albedo color
normalize(light_dir), // light direction
normalize(view_dir), // view direction
material.get_normal(pixel), // normal map sample
0.05, // roughness
0.0, // metallic (no metal)
1.0 // specular
);
// Combine light with BRDF sample to get pixel colour
return brdf_sample * light_intensity;
}
// Simple box filter downsampling function
float3 downsample(
int2 pixel,
Tensor<float3, 2> source)
{
float3 res = 0;
res += source.getv(pixel * 2 + int2(0, 0));
res += source.getv(pixel * 2 + int2(1, 0));
res += source.getv(pixel * 2 + int2(0, 1));
res += source.getv(pixel * 2 + int2(1, 1));
return res * 0.25;
}
// Loss function comparing our mipmap to reference
[Differentiable]
float3 loss(
no_diff int2 pixel,
no_diff float3 reference,
MaterialParameters material,
no_diff float3 light_dir,
no_diff float3 view_dir)
{
float3 color = render(pixel, material,
light_dir, view_dir);
float3 error = color - reference;
return error * error; // Squared error
}
以下是使用 Python 或 SlangPy 调用该代码的方法:
import slangpy as spy
import pathlib
# Create a device and load the Slang module
device = spy.create_device(
include_paths=[
pathlib.Path(__file__).parent.absolute(),
]
)
module = spy.Module.load_from_file(device, "example.slang")
# Load some materials.
albedo_map = spy.Tensor.load_from_image(device, "PavingStones070_2K.diffuse.jpg", linearize=True)
normal_map = spy.Tensor.load_from_image(device, "PavingStones070_2K.normal.jpg", scale=2, offset=-1)
def downsample(source: spy.Tensor, steps: int) -> spy.Tensor:
for i in range(steps):
dest = spy.Tensor.empty(
device=device,
shape=(source.shape[0] // 2, source.shape[1] // 2),
dtype=source.dtype)
module.downsample(spy.call_id(), source, _result=dest)
source = dest
return source
# Allocate a tensor for output + call the render function
output = spy.Tensor.empty_like(albedo_map)
module.render(pixel = spy.call_id(),
material = {
"albedo": albedo_map,
"normal": normal_map,
},
light_dir = spy.math.normalize(spy.float3(0.2, 0.2, 1.0)),
view_dir = spy.float3(0, 0, 1),
_result = output)
# Downsample the output tensor.
output = downsample(output, 2)
# Save it to a file
output_filename = "render_output.png"
output.save_to_image(output_filename)
到目前为止,我们已经完成了原始输入纹理的提取,对其进行下采样并保存为纹理。接下来,需要根据一系列可训练参数计算输出结果,并评估该结果与原始结果之间的差异。我们的目标是通过训练较小的输入纹理,使其产生与全分辨率参考图像相同的效果。因此,首先需要计算这些纹理之间的损失。
# Loss between downsampled full res output (the reference),
# and result from quarter res inputs.
loss_output = spy.Tensor.empty_like(output)
module.loss(pixel = spy.call_id(),
material = {
"albedo": downsample(albedo_map, 2),
"normal": downsample(normal_map, 2),
},
reference = output,
light_dir = spy.math.normalize(spy.float3(0.2, 0.2, 1.0)),
view_dir = spy.float3(0, 0, 1),
_result = loss_output)
这段代码告诉我们当前结果与预期结果之间的差异,但并未说明如何调整参数以降低损失。为此,我们需要计算梯度,而这正是 Slang 的自动微分(autodiff)发挥作用的地方。为了实现这一点,我们向 Slang 代码中添加一个函数:
void calculate_grads(
int2 pixel,
MaterialParameters material,
MaterialParameters ref_material)
{
float3 light_dir = random_direction(); // Assume we've implemented
float3 view_dir = random_direction(); // a properly random direction
// generator
// Render the high-quality reference using our standard render function
float3 reference = render(pixel, ref_material, light_dir, view_dir);
// Backpropagate
bwd_diff(loss)(pixel, reference, material, light_dir, view_dir, 1.0);
}
该新函数通过计算损失函数相对于纹理中每个像素输入的导数,来求得材质纹理各像素的梯度。这些梯度指示了如何调整输入纹理,以降低损失值。
该过程的最后一步是利用这些梯度更新输入纹理,并通过反复迭代,逐步逼近我们的目标。为此,我们需要引入一个 Slang 函数来执行更新操作。在本示例中,可以采用一种极为简单的优化器,但在实际应用中,通常会使用更为复杂的优化器,例如 Adam 优化器。<!–
void optimizer_step(inout float3 parameter, float3 derivative, float learning_rate)
{
parameter -= learning_rate * derivative;
}
现在,我们可以重复这两个步骤:计算梯度,并利用梯度更新纹理参数,直至训练出一个新的高效 Mipmap。这一过程可通过一个简单的 Python 循环实现。
for iteration in range(num_iterations):
# Step 1: Calculate gradients via automatic differentiation
module.calculate_grads(
pixel=spy.call_id(),
material=trainable_material,
ref_material=reference_material
)
# Step 2: Update parameters using the optimizer
module.optimizer_step(
pixel=spy.call_id(),
trainable_material["albedo"],
learning_rate=learning_rate
)
# Repeat for normal map...
请注意,我们用于计算像素颜色的渲染代码同样可用于训练 Mipmap 参数。编译器会自动为整个纹理生成梯度,从而简化复杂 Mipmap 生成模型的训练过程。
尽管这是一个有意简化的示例代码,但您仍可将其作为离线预处理方法集成到实时渲染项目中,以针对难以处理的非线性纹理学习更优的 Mipmap。您甚至可以训练适用于每个材质类别的共享模型,并根据具体素材进行选择性微调。
学习着色器中神经网络的基础知识
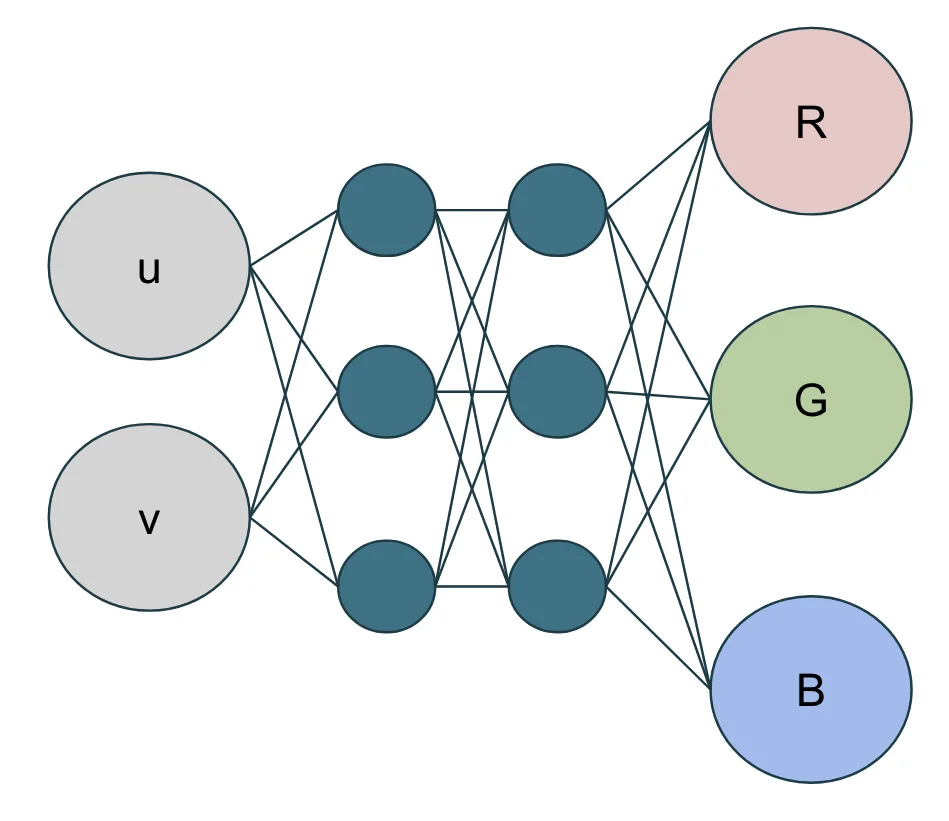
除了简单的参数优化,我们还可以将完整的神经网络直接嵌入到着色器中。神经网络本质上是一种数学函数,能够近似表达输入与输出之间的复杂关系。通过训练网络,我们可以让其自动学习这些关系,而无需编写显式代码来进行计算。<!–
为何在着色器中使用神经网络?
神经网络在图形领域擅长处理多项关键任务。
- 压缩: 相比传统方法,小型网络能够以更少的参数表示复杂的纹理或材质。
- 近似: 它们可通过简单而快速的操作,逼近原本需要高成本计算的复杂过程(如复杂的光照模型)。
- 泛化: 经过训练后,能够有效应对难以通过显式编程处理的各类变化和边缘情况。
- 优化: 对于缺乏解析解或求解成本过高的问题,可学习到接近最优的解决方案。
基础模组
神经网络的基本构成单元十分简单:输入(浮点数值)、权重(可调节参数)、偏置(另一种可调节参数)以及非线性激活函数。网络通过调整权重和偏置来学习,以减小预测结果与预期输出之间的误差。
以纹理表示为例,我们可以构建一个简单的网络,将纹理的 UV 坐标作为输入,输出对应的 RGB 颜色。仅用 9 个参数(6 个权重和 3 个偏置),就能表达传统方法中需要 20 万个浮点运算才能呈现的内容。
对于该特定网络,我们选用双曲正切函数 (tanh()) 作为激活函数,这是一种在神经网络中简单且常见的选择。为了训练网络,我们采用框架内置的优化步骤。可以看到,Python 中的 NetworkParameters 类提供了 optimize() 方法,该方法实际上是 Slang 模块中 adamOptimize() 函数的封装。真正的优化算法则在 adamOptimize() 函数中实现,并在 GPU 上执行。本例中所使用的优化器是 Adam 优化器的一个基础版本。
以下是 Slang 中神经网络的基本实现方法:
import slangpy;
// Simple activation function (tanh)
[Differentiable]
float activation(float x)
{
return tanh(x);
}
// Simple Adam optimizer for a single parameter
void adamOptimize(
inout float primal, // The parameter to optimize
inout float grad, // The gradient
inout float m_prev, // First moment (running average of gradient)
inout float v_prev, // Second moment (running average of squared gradient)
float learning_rate, // Learning rate
int iteration) // Current iteration number
{
const float ADAM_BETA_1 = 0.9;
const float ADAM_BETA_2 = 0.999;
const float ADAM_EPSILON = 1e-8;
// Update first and second moments
float m = ADAM_BETA_1 * m_prev + (1.0 - ADAM_BETA_1) * grad;
float v = ADAM_BETA_2 * v_prev + (1.0 - ADAM_BETA_2) * (grad * grad);
m_prev = m;
v_prev = v;
// Bias correction
float mHat = m / (1.0f - pow(ADAM_BETA_1, iteration));
float vHat = v / (1.0f - pow(ADAM_BETA_2, iteration));
// Update parameter
primal -= learning_rate * (mHat / (sqrt(vHat) + ADAM_EPSILON));
// Reset gradient
grad = 0;
}
// Network parameters with automatic differentiation support
struct NetworkParameters<int Inputs, int Outputs>
{
RWTensor<float, 1> biases;
RWTensor<float, 2> weights;
AtomicTensor<float, 1> biases_grad;
AtomicTensor<float, 2> weights_grad;
[Differentiable]
float get_bias(int neuron)
{
return biases.get({neuron});
}
[Differentiable]
以下是使用 Python 设置和训练网络的方法:
import slangpy as spy
import numpy as np
import pathlib
# Create device and load the Slang module
device = spy.create_device(
include_paths=[
pathlib.Path(__file__).parent.absolute(),
]
)
module = spy.Module.load_from_file(device, "example.slang")
# Python wrapper for the Slang NetworkParameters struct
class NetworkParameters(spy.InstanceList):
def __init__(self, inputs: int, outputs: int):
super().__init__(module[f"NetworkParameters<{inputs},{outputs}>"])
self.inputs = inputs
self.outputs = outputs
# Biases and weights for the layer.
self.biases = spy.Tensor.from_numpy(device,
np.zeros(outputs).astype('float32'))
self.weights = spy.Tensor.from_numpy(device,
np.random.uniform(-0.5, 0.5, (outputs, inputs)).astype('float32'))
# Gradients for the biases and weights.
self.biases_grad = spy.Tensor.zeros_like(self.biases)
self.weights_grad = spy.Tensor.zeros_like(self.weights)
# Temp data for Adam optimizer.
self.m_biases = spy.Tensor.zeros_like(self.biases)
self.m_weights = spy.Tensor.zeros_like(self.weights)
self.v_biases = spy.Tensor.zeros_like(self.biases)
self.v_weights = spy.Tensor.zeros_like(self.weights)
# Calls the Slang 'optimize' function for biases and weights
def optimize(self, learning_rate: float, optimize_counter: int):
module.adamOptimize(self.biases, self.biases_grad, self.m_biases,
self.v_biases, learning_rate, optimize_counter)
module.adamOptimize(self.weights, self.weights_grad, self.m_weights,
self.v_weights, learning_rate, optimize_counter)
# Create network parameters for a layer with 2 inputs and 3 outputs
params = NetworkParameters(2, 3)
print(f"Created NetworkParameters with {params.inputs} inputs and {params.outputs} outputs")
print(f"Biases shape: {params.biases.shape}")
print(f"Weights shape: {params.weights.shape}")
print(f"Initial weights:\n{params.weights.to_numpy()}")
对于更复杂的网络,可以轻松地添加多个层级:
// Multi-layer network for more complex texture generation
struct Network {
NetworkParameters<2, 32> layer0;
NetworkParameters<32, 32> layer1;
NetworkParameters<32, 3> layer2;
[Differentiable]
float3 eval(no_diff float2 uv)
{
float inputs[2] = {uv.x, uv.y};
float output0[32] = layer0.forward(inputs);
[ForceUnroll]
for (int i = 0; i < 32; ++i)
output0[i] = activation(output0[i]);
float output1[32] = layer1.forward(output0);
[ForceUnroll]
for (int i = 0; i < 32; ++i)
output1[i] = activation(output1[i]);
float output2[3] = layer2.forward(output1);
[ForceUnroll]
for (int i = 0; i < 3; ++i)
output2[i] = activation(output2[i]);
return float3(output2[0], output2[1], output2[2]);
}
}
这种方法的巧妙之处在于,原本用于简单参数优化的 autodiff 基础设施同样适用于神经网络的训练。编译器能够自动为整个网络生成梯度,从而高效地训练复杂的纹理生成模型。
获得更好结果的关键技术
小型网络需要经过精心设计才能有效运行。所采用的技术应根据具体应用场景进行选择,适用于生成纹理的方法未必适合材质评估或光照计算。以下是一些能够显著提升我们当前研究的纹理示例效果的关键技术:
- 激活函数:在机器学习中,修正线性单元(ReLU)是一种常用的激活函数,它对正输入保持原值输出,而对负输入则输出零。尽管ReLU在计算效率和多数神经网络任务中表现良好,但由于其输出为零的特性,可能导致分段线性的结果。在2D纹理生成等应用中,这种特性可能引发可见的三角形伪影。相比之下,指数函数等更为平滑的激活函数通常能提供更优的视觉效果。因此,激活函数的选择应根据具体应用场景权衡决定。
// Some alternative activation functions
[Differentiable]
float3 smoothActivation(float3 x) {
return exp(x); // Exponential activation for smoother output
}
[Differentiable
float3 leakyReLU(float3 x) {
return max(0.1 * x, x); // Leaky ReLU prevents dead neurons
}
- Leaky ReLU:当 ReLU 的输入为负数时,其输出为零,同时梯度也为零。这意味着在反向传播过程中,权重不会得到更新。如果某个神经元在训练过程中持续接收负输入,就可能永久进入“死亡”状态,即始终输出零,无法再进行学习。这种情况在规模较小的网络中尤为突出,因为少数神经元的失效也可能显著影响整体性能。相比之下,Leaky ReLU 在输入为负时会输出一个较小的负值(通常为输入的 0.01 倍),从而确保梯度不会完全为零。这种微小的负斜率使神经元能够保持活跃,持续对梯度更新作出响应,避免永久失活。
- 频率编码:我们并非直接将原始的 UV 坐标输入神经网络,而是先将其通过多个频率的正弦和余弦函数进行变换。这种方法能够在不增加计算开销的前提下提升模型表现。神经网络通常难以从低维输入中捕捉高频模式,例如精细的细节或 sharp 的边界变化。通过将坐标映射为形如 [sin(2πu)、cos(2πu)、sin(2πv)、cos(2πv)] 的形式,我们为网络引入了丰富的频率分量,使其能够同时学习低频(平滑变化)和高频(细节变化)特征。这对于 UV 坐标等空间相关输入尤其有效;而对于频率信息不关键的非空间输入,该方法的增益则相对有限。
// Frequency encoding for better neural texture representation
float4 encodeUV(float2 uv) {
float4 encoded;
encoded.x = sin(uv.x * 2.0 * 3.14159);
encoded.y = cos(uv.x * 2.0 * 3.14159);
encoded.z = sin(uv.y * 2.0 * 3.14159);
encoded.w = cos(uv.y * 2.0 * 3.14159);
return encoded;
}
// Enhanced network with frequency encoding
[Differentiable]
float3 evaluateNetworkWithEncoding(NeuralNetwork net, float2 uv) {
float4 encoded = encodeUV(uv);
// Now use 4D input instead of 2D
float3 output = float3(0.0, 0.0, 0.0);
for (int i = 0; i < 3; i++) {
output[i] = net.biases[i];
for (int j = 0; j < 4; j++) {
output[i] += net.weights[i * 4 + j] * encoded[j];
}
}
return smoothActivation(output);
}
硬件如何加速协作向量
现代 GPU 配备了专用的 Tensor Core,能够高效地执行矩阵乘法运算。然而,使用 Tensor Core 需要线程间的协同工作,所有线程必须同步运行,共同完成矩阵计算任务。
协作向量为访问该硬件提供了一种便捷途径。开发者可以将着色器代码编写为常规的矩阵-向量乘法,编译器会自动将其映射到 Tensor Core 硬件,无需手动进行数据打包或统一控制流。
以下是利用协作向量实现神经网络加速的方法:
struct FeedForwardLayer<int InputSize, int OutputSize>
{
ByteAddressBuffer weights;
uint weightsOffset;
ByteAddressBuffer biases;
uint biasesOffset;
CoopVec<float, OutputSize> eval(CoopVec<float, InputSize> input)
{
let output = coopVecMatMulAdd<float, OutputSize>(
input, CoopVecComponentType.Float32, // input and format
weights, weightsOffset, CoopVecComponentType.Float32, // weights and format
biases, biasesOffset, CoopVecComponentType.Float32, // biases and format
CoopVecMatrixLayout.ColumnMajor, // matrix layout
false, // is matrix transposed
sizeof(float) * InputSize); // matrix stride
return max(CoopVec<float, OutputSize>(0.0f), output); // ReLU activation
}
}
现实世界的应用程序:您可以构建哪些内容?
我们介绍的技术为神经网络着色领域的众多令人振奋的应用奠定了基础,涵盖以下几个前景广阔的方面:
神经纹理压缩 (NTC)
神经纹理压缩是神经着色技术中颇具实用价值的应用之一。相较于传统的块压缩格式(如 BC1 和 BC7)所存在的固有局限,NTC 能够在相近的压缩率下实现更优的图像质量,或在同等质量水平下提供更高的压缩效率。
关键的见解在于采用小型神经网络作为解码器,并输入低精度的潜在纹理与位置编码。该方法具备以下优势:
- 可变比特率: 采用可变数量的低位深度隐性纹理,可实现广泛的编码比特率范围(每像素 0.5 到 20 位)。
- 独立解码: 每个像素均可独立解码,支持在着色器中直接进行采样。
- 无幻觉: 与大型图像生成模型不同,该方案使用为每个纹理单独训练的小型网络,不会像生成多指等伪影那样产生完全虚构的内容。
有关实现细节和示例,请参考 NVIDIA 神经纹理压缩库。
神经材质
神经材质是另一项功能强大的应用,它能够学习复杂的分层材质,并将其蒸馏为体积更小的网络,运行速度远超原始着色器代码。
该方法通过以光照方向、视角方向和潜在代码作为输入,训练网络输出材质颜色。为实现空间变化,我们进一步训练潜在代码的纹理,并将其作为额外输入提供给网络。
关键的创新在于训练过程中采用编码器网络,将原始材质纹理转换为潜在纹理,并将结果进行烘焙以供运行时使用。该方法可扩展至极高的纹理分辨率(4K及以上),同时避免了逐纹理优化所带来的收敛问题。
超越纹理和材质
神经网络着色的原理远不止于此,类似的技术还可应用于更多领域。
- 光照计算: 采用快速神经网络近似方法,模拟复杂的光照模型。
- 后处理效果: 学习并优化色调映射、色彩调整或风格化渲染效果。
- 几何处理: 利用神经网络实现几何图形的程序化生成与修改。
- 动画生成: 实现流畅的插值或程序化动画创作。
- 程序化生成: 基于学习到的模式,通过算法自动生成内容。
- 光线追踪去噪: 运用神经网络有效降低光线追踪图像中的噪点。
- 动画压缩: 借助学习到的特征表示,高效压缩动画数据。
- 网格简化: 在保持视觉细节的前提下,对3D网格进行简化处理。
关键在于明确哪些场景需要通过昂贵的计算或复杂的关系,才能从神经网络近似中获益。
未来:神经网络着色的重要性
神经网络着色不仅是一项新技术,更彻底改变了人们对实时图形的认知。通过使着色器具备可训练性,我们打开了全新的可能性。
- 质量与性能的平衡: 网络能够根据不同的质量等级进行自适应调整,从而实现自然的细节层次(LOD)系统。
- 功能可扩展性: 可便捷集成其他学习模块,用于执行重要性采样、过滤等任务。
- 平台灵活性: 同一神经资产可在不同硬件配置上运行,在高性能设备上直接进行推理与采样,而在性能受限的平台上则通过转码适配运行。
成功的关键在于构建一个涵盖优化技术以及针对神经着色的调试技能的思维工具箱。与任何新技术一样,掌握它需要经历一定的学习过程,但带来的回报十分可观。
入门:后续步骤
神经着色生态系统正快速走向成熟。以下是入门所需的关键工具与库:
要快速上手 Slang 和 autodiff,您可以在浏览器中直接使用 Slang Playground 进行尝试。如需获取更全面的资源与工具,建议探索 NVIDIA RTX 套件,该套件提供对神经着色技术的支持。若希望深入理解本指南所涵盖的概念,可观看 NVIDIA 在 SIGGRAPH 大会上推出的神经着色课程。
在下周的图形编程大会(GPC)上,欢迎关注我们关于《毁灭战士:黑暗时代中神经网络着色与路径追踪技术在实时图形中应用的专题分享。
该技术现已可用于实际生产。无论是处理纹理压缩、材质系统,还是开发全新的应用程序,神经网络着色都能提供强大的工具,显著提升实时图形的质量与性能表现。
单击此处查看完整的游戏开发者资源列表,并关注我们以获取最新的 NVIDIA 游戏开发资讯:
- 加入 NVIDIA 开发者计划(面向游戏行业)
- 关注我们的社交媒体: X、LinkedIn、Facebook、和 YouTube
- 加入我们的 Discord 社区




