
部署 LLM 的组织面临着推理工作负载的挑战,这些工作负载具有差异化的资源需求。小型嵌入模型可能仅需几 GB 的 GPU 显存,而参数规模超过 70B 的大语言模型则可能需要多个 GPU 协同运行。这种多样性往往导致 GPU 平均利用率偏低、计算成本上升以及延迟表现不稳定。
问题不只是将更多工作负载打包到 GPU 上,而是要对其进行智能调度。若缺乏能够理解推理工作负载模式的编排机制,组织将面临过度调配(造成资源浪费)与不足调配(导致性能下降)之间的权衡。
这篇博文涵盖:
- 推理利用率问题: 传统调度方式未能充分释放 GPU 资源潜力的原因。
- NVIDIA NIM 如何实现生产级推理: 容器化微服务在模型标准化部署中的关键作用。
- NVIDIA Run:ai 的智能调度策略: 四项核心功能,可在降低延迟、提升每 GPU 的 TPS 的同时,提高 GPU 利用率并减少计算成本。
- 基准测试结果: 在吞吐量损失极小的情况下,GPU 利用率提升约 2 倍;在动态分数驱动的高并发场景中,吞吐量提升约 1.4 倍;启用 GPU 显存交换后,首次请求延迟改善达 44 至 61 倍。
- 入门指南: 在 NVIDIA Run:ai 上结合 NIM 实践上述策略的实用操作指引。
推理利用率问题
GPU 利用率决定了在给定集群上可以运行的工作负载数量以及成本。在实践中,多数推理部署会导致大量 GPU 容量闲置,原因在于为每个模型分配一个完整的 GPU“只是为了安全”,或由于缺乏内存隔离的简单共享在流量高峰时引发内存不足(OOM)和延迟激增。
如果没有智能编排,团队将不得不在资源配置过度(造成浪费)与配置不足(带来性能风险)之间做出权衡。
NVIDIA NIM 如何提供生产推理
NVIDIA NIM 软件包将推理引擎优化为容器化微服务,具备以下优势:
- 打包的推理引擎:预配置推理运行时,提升吞吐量并降低延迟
- 行业标准 API:提供与 OpenAI 兼容的端点,便于集成
- 模型优化:自动选择量化、批处理及加速技术
- 生产就绪型容器:预构建并包含依赖项,经过大规模测试
- 安全性和合规性:支持企业级安全控制与容器签名,满足部署要求
- 企业级支持:NVIDIA 提供生产环境部署的技术支持与维护
NIM 实现了部署层的标准化,但要进一步提升 GPU 利用率,仍需智能编排。因此,NVIDIA Run:ai 的调度功能至关重要。
NVIDIA Run:ai 如何为 NVIDIA NIM 实现高效资源管理
推理利用率不仅仅是调度,更要适应工作负载的行为模式。借助 NVIDIA Run:ai,NIM 部署可实现推理优先、具备完全内存隔离的 GPU 分片、基于工作负载需求的智能调度、动态内存管理以及自动扩展(包括副本扩展与零扩展)。这使用户能够追踪流量,并在模型空闲时释放 GPU 资源。
推理优先级可保护面向用户的工作负载
NVIDIA Run:ai 会自动为推理工作负载分配较高的默认优先级,确保训练作业不会抢占推理工作负载的资源。为何如此重要:
- 推理为用户提供服务: 延迟峰值和机器时间会影响用户体验及 SLA 合规性。
- 训练可容忍中断: 模型训练能够暂停并恢复,而推理请求无法等待。
这种自动优先级分配消除了多数环境中的手动调整。对于运行混合工作负载的组织而言,这能确保训练任务根据推理需求灵活安排,而非与推理任务相互竞争。GPU 可在推理负载较低时执行训练,从而在面向用户的请求到达时自动释放资源。
在 GPU 上对多个小型模型进行分块与 Bin 打包
许多 NIM 工作负载(如嵌入、重排序和小型 LLM)几乎不需要占用整块 GPU。当与 GPU 分数 结合使用时,NVIDIA Run:ai 采用 Bin 打包策略,优先填满已有 GPU,再分配新的 GPU,从而显著提升整个集群的利用率。
GPU 分数与 Bin 打包的工作原理:
- GPU 分片可提供真正的内存隔离(非软件限制),每个模型均可获得有保证的内存分配。
- Bin Packing 会根据当前利用率对 GPU 进行评分,并在分配新任务时优先选择已部分使用的 GPU。
- 调度程序优先将新工作负载分配至部分使用的 GPU,以提升资源利用效率。
基准测试结果:
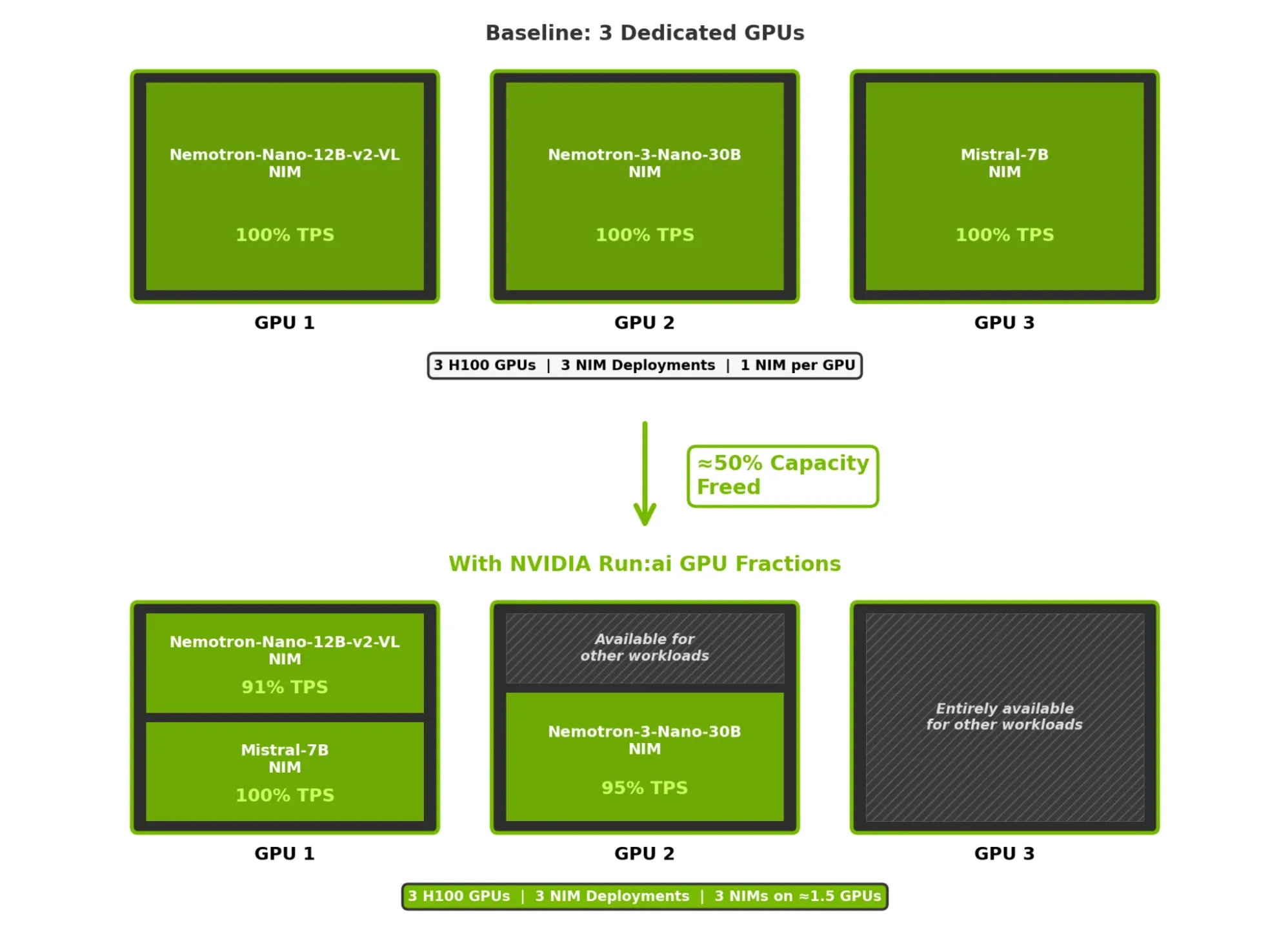
该方法通过在 NVIDIA H100 GPU 上模拟三个 NIM 模型(7B LLM、12B VLM 和 30B MoE)的场景进行了测试:
- 场景 A: 三个 GPU,每个 NIM 配备一个 H100 GPU(基准)
- 场景 B: 在 1.5 个 H100 GPU 上通过 NVIDIA Run:ai 调度运行三个 NIM,保持 NIM 配置与客户端负载模式不变
练习短上下文和长上下文提示时,主要发现包括:
- 每个 NIM 均保留了约 91 – 100% 的单 GPU 吞吐量,从 Time-to-First-token (TTFT) 到端到端 (E2E) 延迟略有增加。
- Mistral-7B 的专用 GPU 吞吐量达到 834 token/s,长上下文输入下达到 100% 利用率。
- Nemotron-3-Nano-30B 保留了 95% 的吞吐量(582 与 614 token/s)。
- Nemotron-Nano-12B-v2-VL 在短上下文输入时保留了 91% 的吞吐量(658 与 723 token/s)。
之前需要三个专用 H100 的三个 NIM 微服务被整合至约 1.5 个 H100 上,从而释放出剩余算力以处理其他工作负载。
动态 GPU 分配可在高负载并发请求下维持性能
静态 GPU 分数可确保显存隔离,但其设定了“固定上限”,从而形成“标准容量”。随着并发请求的增加,每个 NIM 的 KV 缓存会动态增长,以跟踪活动序列。当增长达到固定分数边界时,吞吐量趋于稳定,延迟随之降低。这一瓶颈导致我们必须在两者之间做出艰难权衡:过度分配分数(造成 GPU 容量浪费),或限制并发性以维持在固定的显存预算范围内。
NVIDIA Run:ai 的动态 GPU 分配通过将固定分配替换为请求/限制模型来解决此问题,并采用 Kubernetes 资源语义来管理 GPU 显存。
- 请求: 保障的最低分数,始终为工作负载保留。
- 限制: 可突发上限,使 NIM 能够在按需 KV 缓存或计算压力增加时扩展到可用的 GPU 显存。
当 NIM 运行其请求时,请求和限制之间未使用的空间仍可用于托管工作负载。当并发流量出现峰值时,NIM 会迅速接近其上限,占用内存并将资源转为活动吞吐量。系统会自动处理请求与限制之间的状态转换。工作负载可在需要时动态扩展,在需求下降时释放资源,从而在无需人工干预的情况下显著提升 GPU 的整体利用率。
基准测试结果:
使用与实验 1 相同的三个 NIM 模型和 1.5 块 H100 GPU 资源,将静态评分替换为动态评分,以评估并发量增加时的性能表现:
- Mistral-7B NIM(请求:0.3,限制:0.4)
- Nemotron-Nano-12B-v2-VL NIM(请求:0.4,限制:0.5)
- Nemotron-3-Nano-30B NIM(请求:0.65,限制:0.75)
场景对比:
- 场景 A(静态分数 + bin 打包):实验 1 中的固定分数部署(参见图 1),其中每个 NIM 均具有完全隔离的显存上限。
- 场景 B(动态分数 + bin 打包):在约 1.5 个 H100 GPU 上采用相同的 bin 打包布局,但每个 NIM 使用请求/限制对,而非固定分配。
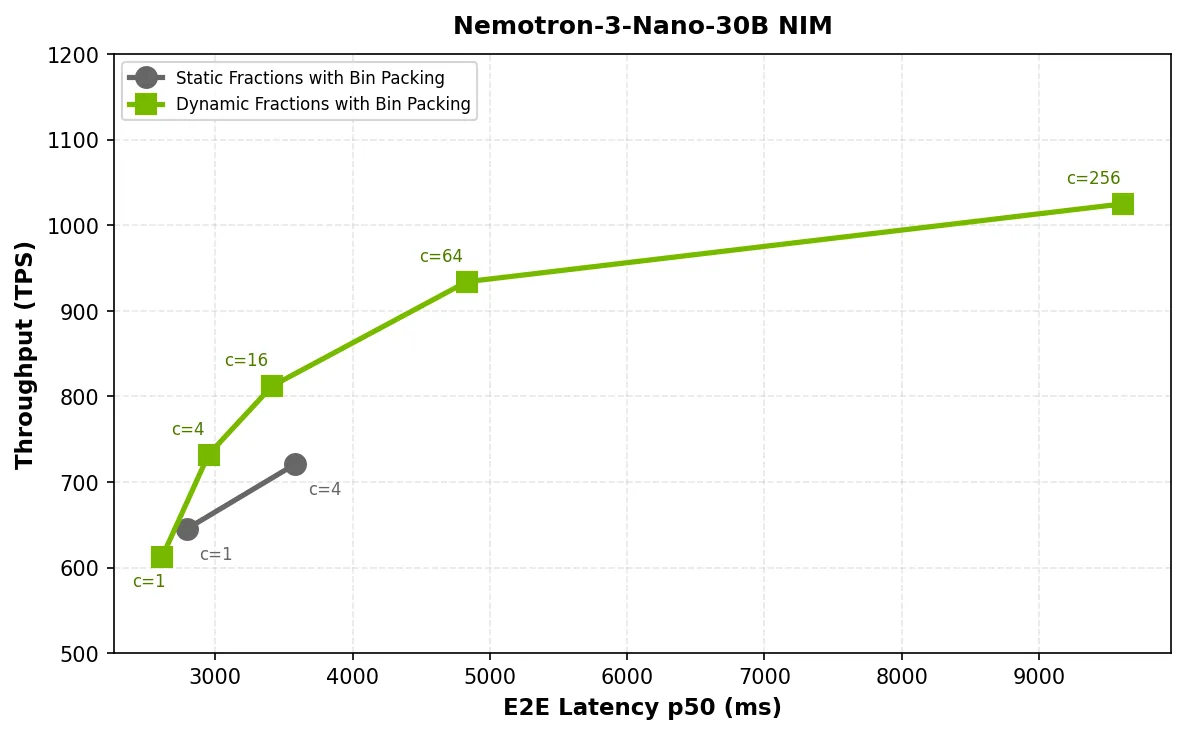
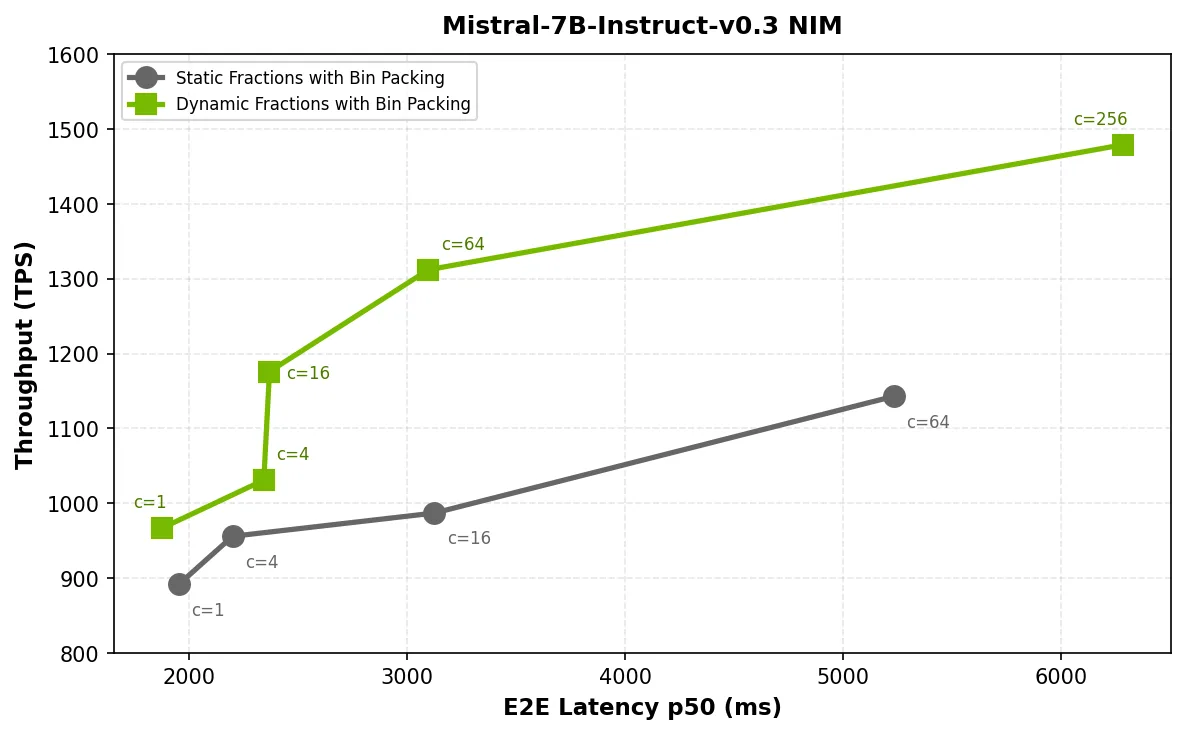
在图 2、3 和 4 中,由于模型无法访问额外的内存来处理持续增长的 KV 缓存,随着并发率上升,静态分数在性能上出现瓶颈,导致吞吐量停滞,延迟随之增加。而采用动态分数后,NIM 微服务能够在流量高峰期间突破限制,并在负载降低时释放内存,从而有效缓解压力。
在所有三个 NVIDIA NIM 微服务中,动态组分可将吞吐量提升 1.4 倍,延迟降低至原来的 1.7 倍,并在并发场景下实现良好的可扩展性。例如:
- Nemotron-3-Nano-30B 在处理 256 个具有动态分数的并发请求时,可持续达到 1025 个 token/s 的吞吐量,而静态分数模式下仅能在不稳定前处理 4 个并发请求,吞吐量上限为 721 个 token/s(提升 1.4 倍)。
- 在处理 64 个并发的 2048-token 请求时,Mistral-7B-Instruct-v0.3 的 p50 端到端延迟从 5235 毫秒降低至 3098 毫秒(降低为原来的 1.7 倍)。
p50 延迟曲线保持平滑且单调,而非出现峰值或折叠,表明请求与限制空间适配了 KV 缓存的增长模式,从而提升了 GPU 利用率。
要点:
- 静态分数 + bin 打包: 适用于可预测的流量、低至中等并发、内存占用稳定的模型
- GPU 动态分数 + bin 打配: 适用于流量变化较大、高并发、KV 缓存增长显著的模型
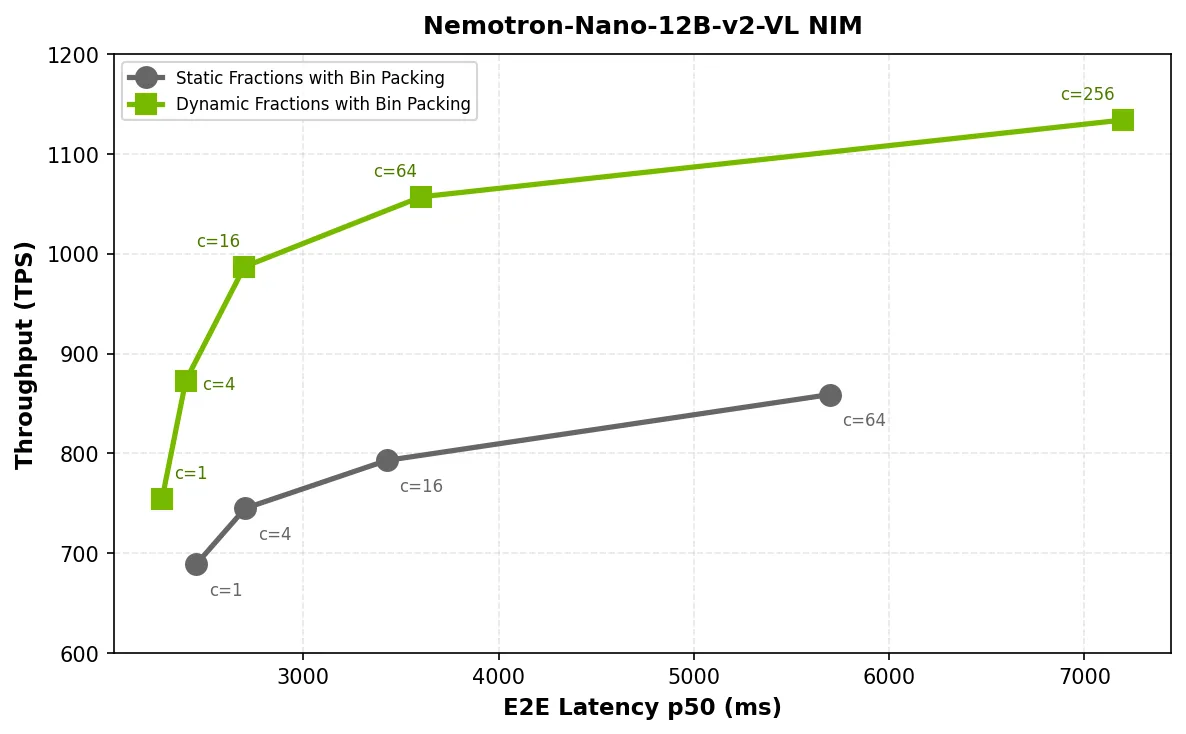
动态 GPU 分数能够突破高并发场景下静态分配的性能瓶颈,同时维持工作负载密度。采用静态分数时,KV 缓存无法超出固定的内存边界,推理引擎会因缺乏容纳新序列的空间而开始拒绝请求。动态 GPU 分数可有效缓解这一问题,因为 NIM 能够按需利用可用内存空间,使组织在无需额外分配 GPU 的情况下,兼具高效的资源利用率与应对流量高峰的弹性能力。
GPU 显存交换:高效服务使用频率较低的模型
为 LLM 服务的组织需要在延迟和成本之间进行根本性的权衡。从零开始扩展大语言模型(LLM)涉及完整的容器初始化、从磁盘加载模型权重以及分配 GPU 显存;这一过程可能耗时数十秒至数分钟。由于此类冷启动延迟对于面向用户的应用程序而言难以接受,多数组织倾向于过度调配资源,即在低流量或空闲期间,仍通过专用 GPU 保持多个副本持续运行。
这可保证低延迟,但会浪费 GPU 资源,为闲置的硬件支付费用,以规避冷启动风险。 Scale to Zero(一种在 Kubernetes 中完全关闭空闲副本并按需重新启动副本的模式)能够释放 GPU 资源,但因冷启动带来的延迟惩罚,难以适用于对延迟敏感的推理工作负载。
GPU 显存交换的工作原理:
通过 GPU 显存交换,模型将保留在 CPU 内存中,并在请求到达时于 CPU 与 GPU 之间动态交换模型权重。在任何时刻,GPU 显存中仅存放活跃模型的权重。当请求指向一个空闲模型时,NVIDIA Run:ai 的 GPU 显存交换机制会将当前加载模型的权重移至 CPU 内存,同时将目标模型加载至 GPU 显存,以维持可配置时间窗口内的热度状态。该模型从未完全脱离内存,而是在 GPU 与 CPU 之间灵活迁移,无需容器重启、磁盘 I/O 操作或冷启动初始化。
GPU 显存交换适用于单 GPU、多 GPU 以及部分 GPU 工作负载。 此前基于单 GPU 部署的基准测试显示,与零扩展相比,首次生成 token 的时间(TTFT)缩短了 66 倍。在本次基准测试中,将 GPU 显存交换与部分 GPU 上的 NIM 部署相结合,用于验证当模型通过 bin 打包共享硬件资源且处于显存受限的情况下,是否仍能保持相同的延迟优势。
基准测试结果:
比较了在相同的三种 NIM 部署中,GPU 显存交换与零扩展之间的延迟:
- 场景 A(从零开始扩展):当流量到达时,每个 NIM 都会在专用的 H100 GPU 上从头开始加载(共使用三个 GPU)。
- 场景 B (GPU 显存交换):三个 NVIDIA NIM 微服务共享 1.5 个 H100 GPU(与先前实验的配置相当),在 GPU 显存与 CPU 内存之间进行交换操作。
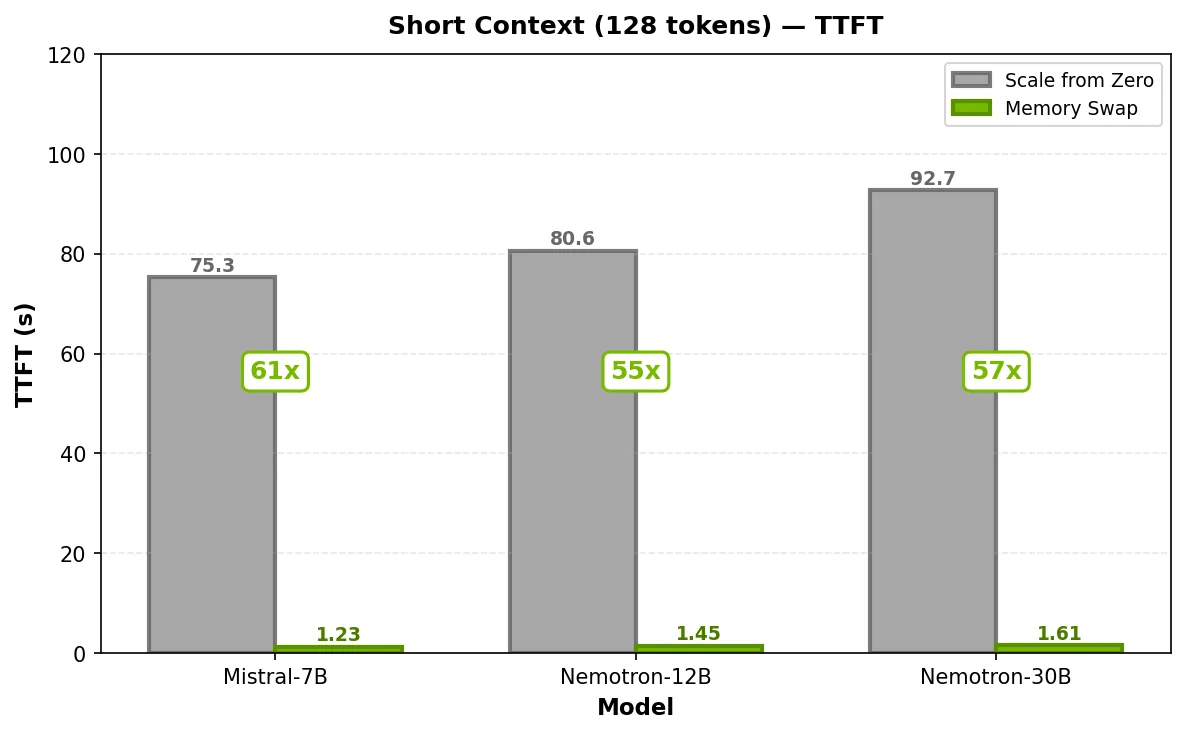
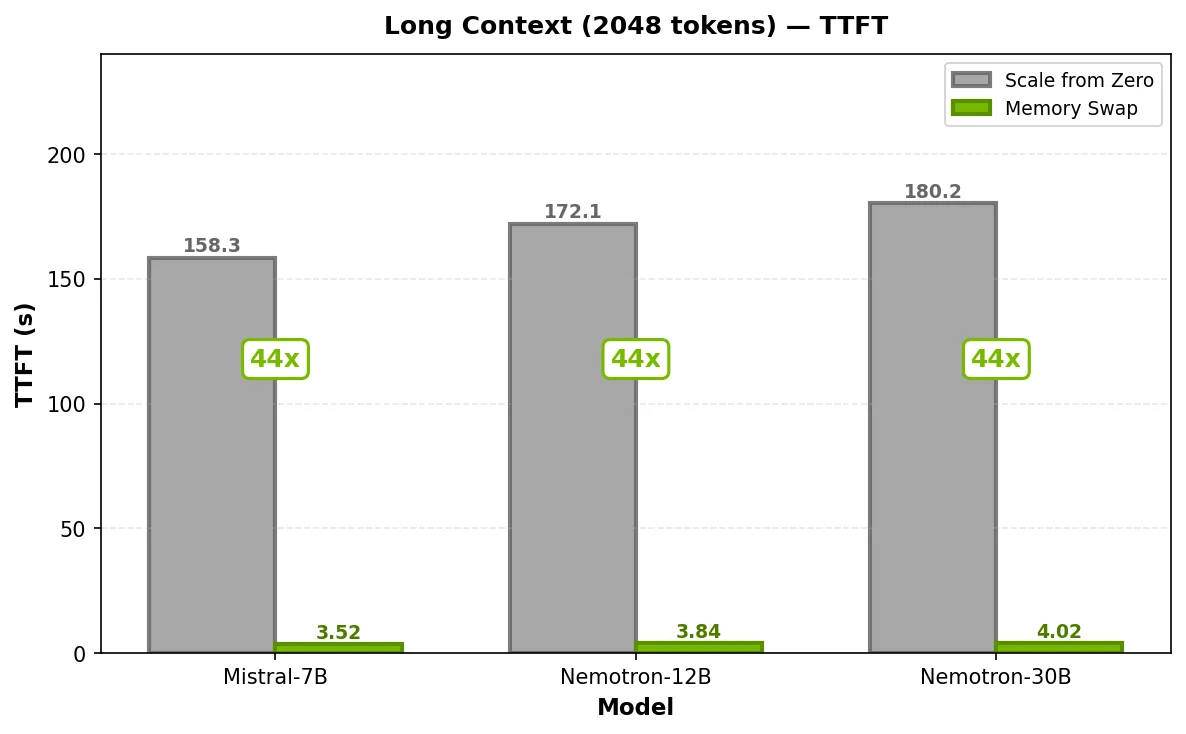
在零扩展且不常访问的 NIM 微服务中,由于完全冷启动,首次请求延迟较高。启用 GPU 显存交换后,首次请求延迟仍处于可接受范围,后续请求则达到预热后的 TTFT 水平。这三个 NIM 微服务均运行在一半的 GPU 上,从而释放剩余算力以支持高流量或其他工作负载。
在 128-token 输入下,冷启动 TTFT 介于 75.3 秒(Mistral-7B)到 92.7 秒(Nemotron-3-Nano-30B)之间,启用 GPU 显存交换后,该时间缩短至 1.23 – 1.61 秒,性能提升达 55 – 61 倍。在 2048-token 输入时,冷启动 TTFT 从 158.3 – 180.2 秒降至使用交换时的 3.52 – 4.02 秒,性能稳定提升约 44 倍。
要点:与零扩展相比,GPU 显存交换可将 TTFT 的速度提升 44-61 倍,同时在与 GPU 分数结合使用时所需资源更少,从而消除对罕见模型的冷启动惩罚,无论部署在专用 GPU 还是分数 GPU 上均能实现。
开始使用 NVIDIA Run:ai 和 NVIDIA NIM
查看本指南,了解如何在 NVIDIA Run:ai 上将 NVIDIA NIM 部署为原生推理工作负载。 观看此网络会议,探索团队如何通过智能调度、细粒度 GPU 控制、Kubernetes 原生流量均衡和自动扩展来管理持续增长的 AI 工作负载,同时了解新平台更新在访问控制、端点管理和可见性方面的改进。




