NVIDIA 正在与威斯康星大学麦迪逊分校合作,通过开源 Sirius 引擎将 GPU 加速分析引入 DuckDB。
DuckDB 因其简洁、高效和通用性,已在 DeepSeek、Microsoft 和 Databricks 等组织中获得迅速采用。由于分析类工作负载天然适合大规模并行处理,相较基于 CPU 的数据库,GPU 已成为顺理成章的演进方向,能够提供更高的性能、更大的吞吐量以及更优的总体拥有成本(TCO)。然而,从零构建数据库系统所面临的挑战,制约了对 GPU 加速日益增长的需求。
联合开发的 Sirius,是一个适用于 DuckDB 的可组合 GPU 原生执行后端,在保留其高级子系统的同时,利用 GPU 加速查询执行。通过集成 NVIDIA CUDA-X 库,Sirius 实现了高效的 GPU 加速。
本博文概述了 Sirius 架构,并展示了其在广泛使用的分析基准测试 ClickBench 上实现的卓越性能。
Sirius:GPU 原生 SQL 引擎

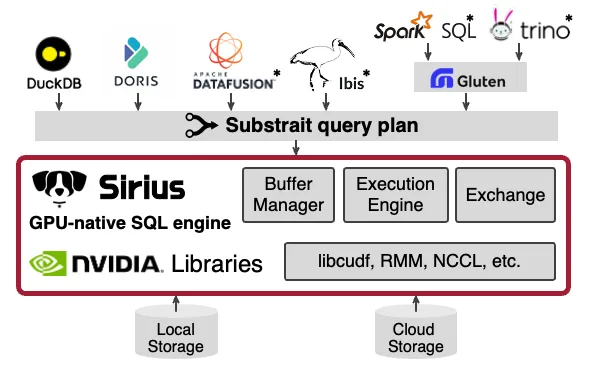
Sirius 是一个 GPU 原生的 SQL 引擎,可为 DuckDB 及未来其他数据系统提供即插即用的加速能力。
该团队近期发表了一篇文章,详细介绍了 Sirius 架构,并在 SF100 上展示了 TPC-H 的卓越性能。
作为 DuckDB 扩展程序,Sirius 无需修改 DuckDB 的代码库,仅需对面向用户的界面进行少量调整。在执行边界,Sirius 采用通用的 Substrait 格式表示查询计划,确保与其他数据系统兼容。为尽可能减少工程工作量并提升系统可靠性,Sirius 基于成熟的 NVIDIA 库构建:
- NVIDIA cuDF: 专为 GPU 原生设计的高性能列式关系运算符(例如连接、聚合、投影)。
- NVIDIA RAPIDS Memory Manager (RMM): 高效的 GPU 显存分配器,可减少内存碎片化并降低分配开销。
Sirius 在这些高性能库的基础上构建其 GPU 原生执行引擎和缓冲区管理,同时复用 DuckDB 的高级子系统,包括其查询解析器、优化器和扫描运算符(如适用)。通过整合这一成熟生态系统,Sirius 获得了显著优势,得以以极低的工程投入刷新 ClickBench 记录。

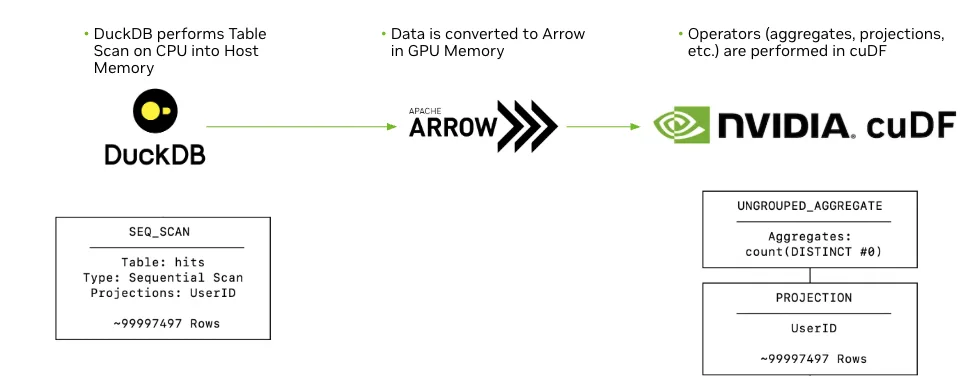
如图 2 所示,当 Sirius 从 DuckDB 的内部格式中接收到已优化的查询计划时,该流程即开始,以确保逻辑与物理优化的稳健性。对于表格扫描,Sirius 调用 DuckDB 的扫描功能,该功能提供极小值 – 极大值过滤、区域跳过和动态解压缩等特性,从而高效地将相关数据加载到主机内存中。
接下来,表格扫描的结果将从 DuckDB 的原生格式转换为 Sirius 数据格式(与 Apache Arrow 紧密对齐),随后传输至 GPU 显存。在 ClickBench 等基准测试中,Sirius 能够在 GPU 上缓存频繁访问的表,从而加快重复查询的执行速度。
Sirius 格式可直接映射到 cudf::table,实现零拷贝互操作性,使后续所有 SQL 运算符(聚合、投影和连接)均可通过 cuDF 基元以 GPU 速度执行。计算完成后,结果被传回 CPU,转换为 DuckDB 预期的输出格式,再返回给用户,兼顾高效运算速度与无缝、熟悉的分析体验。
在 Clickbench 中排名第一
针对 ClickBench 上排名前五的系统,评估了在 Lambda Labs 的 NVIDIA GH200 Grace Hopper 超级芯片 实例上运行的 Sirius(1.5 美元/小时)。替代系统在纯 CPU 实例上运行,包括 AWS c6a.metal(7.3 美元/小时)、AWS c8g.metal-48xl(7.6 美元/小时)和 AWS c7a.metal-48xl(9.8 美元/小时)。遵循 ClickBench 方法,报告热运行执行时间和相对运行时,其中较低的值表示性能更优,1.0 表示基准得分。图 3 显示了所有基准查询中相对运行时的几何平均值。在 ClickBench 测试中,Sirius 在成本更低的硬件上实现了最小的相对运行时间,因此在此配置下,成本效益提升了至少 7.2 倍。请注意,这些基准测试结果基于评估时的数据,未来可能会发生变化。

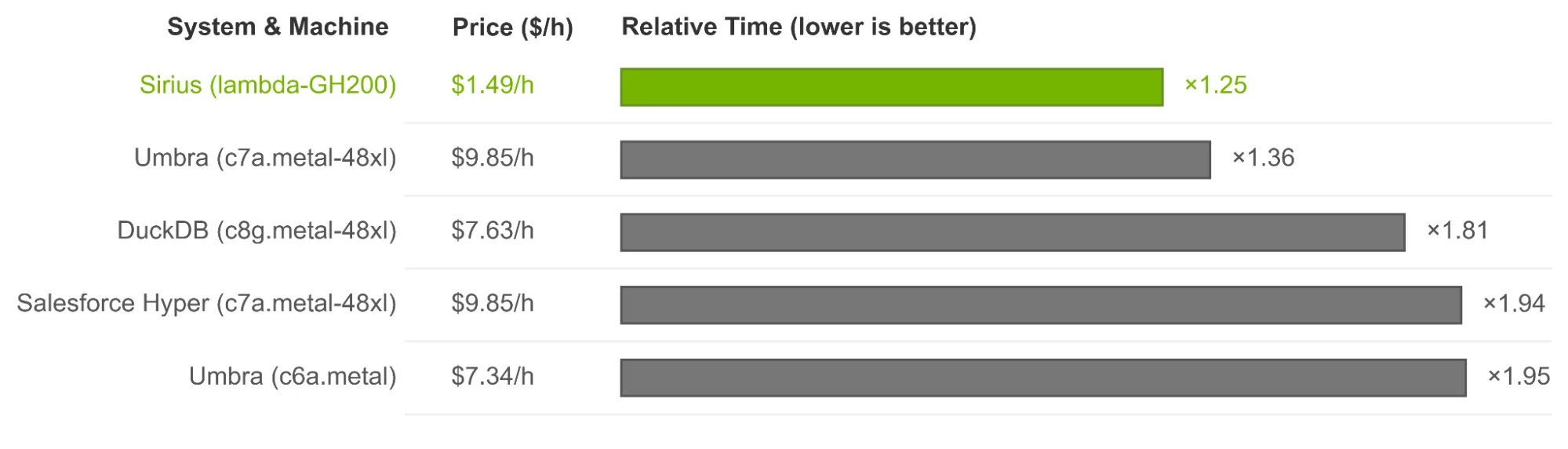
图 4 显示了 Sirius 与 ClickBench 中前两个系统(Umbra 和 DuckDB)在热运行下的查询性能对比。在 cuDF 高效的 GPU 计算支持下,Sirius 在多数查询中表现出更优的相对运行时性能。例如,在 q4、q5 和 q18 查询中,Sirius 在过滤、投影和聚合等常用算子上均实现了显著的性能提升。
但是,一些查询表明仍存在进一步改进的空间。例如,q23 受限于字符串列的“包含”运算,q24 和 q26 受限于前 N 个运算符,q27 则受限于大规模输入的聚合操作。Sirius 的未来版本将持续优化这些运算符的性能。

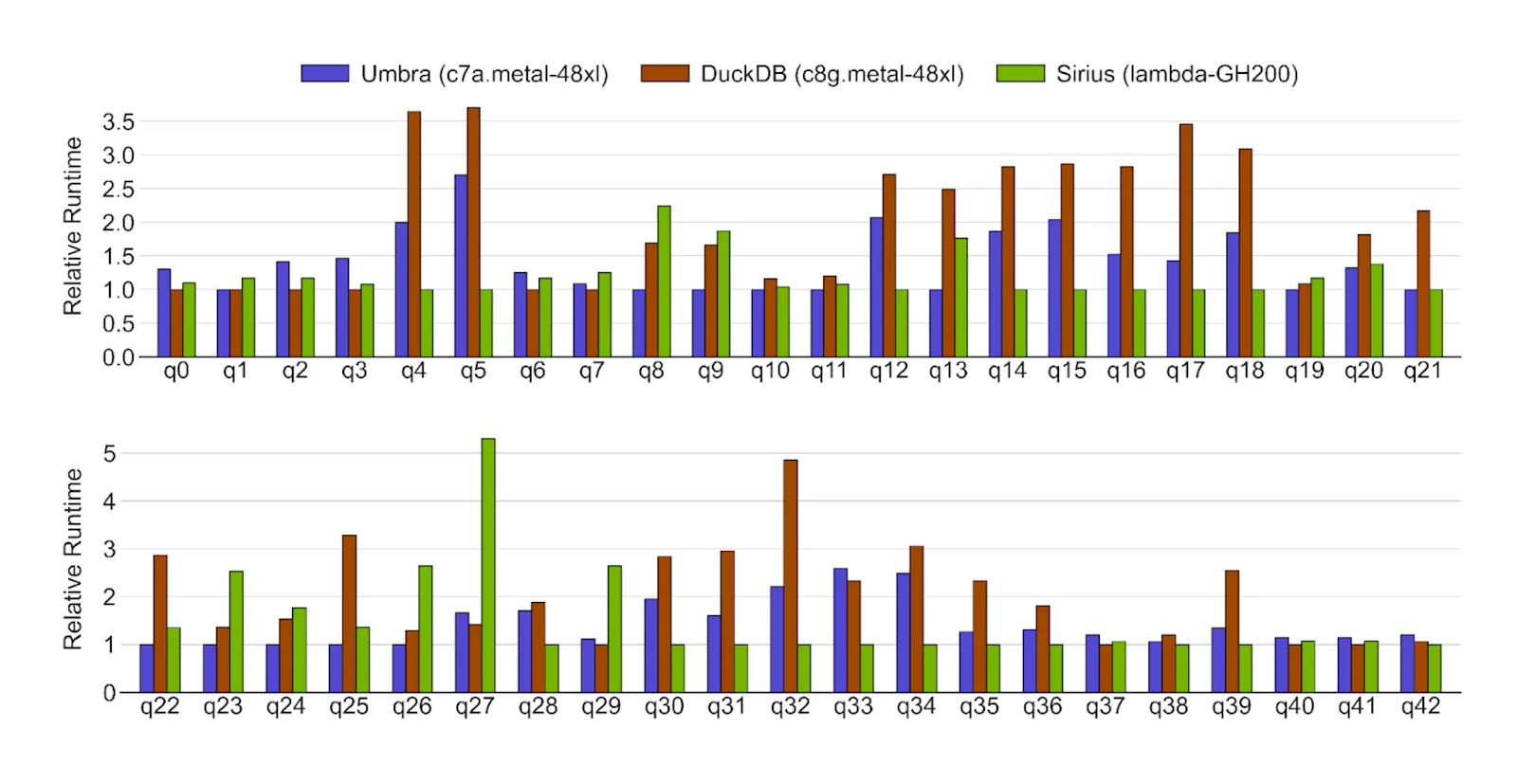
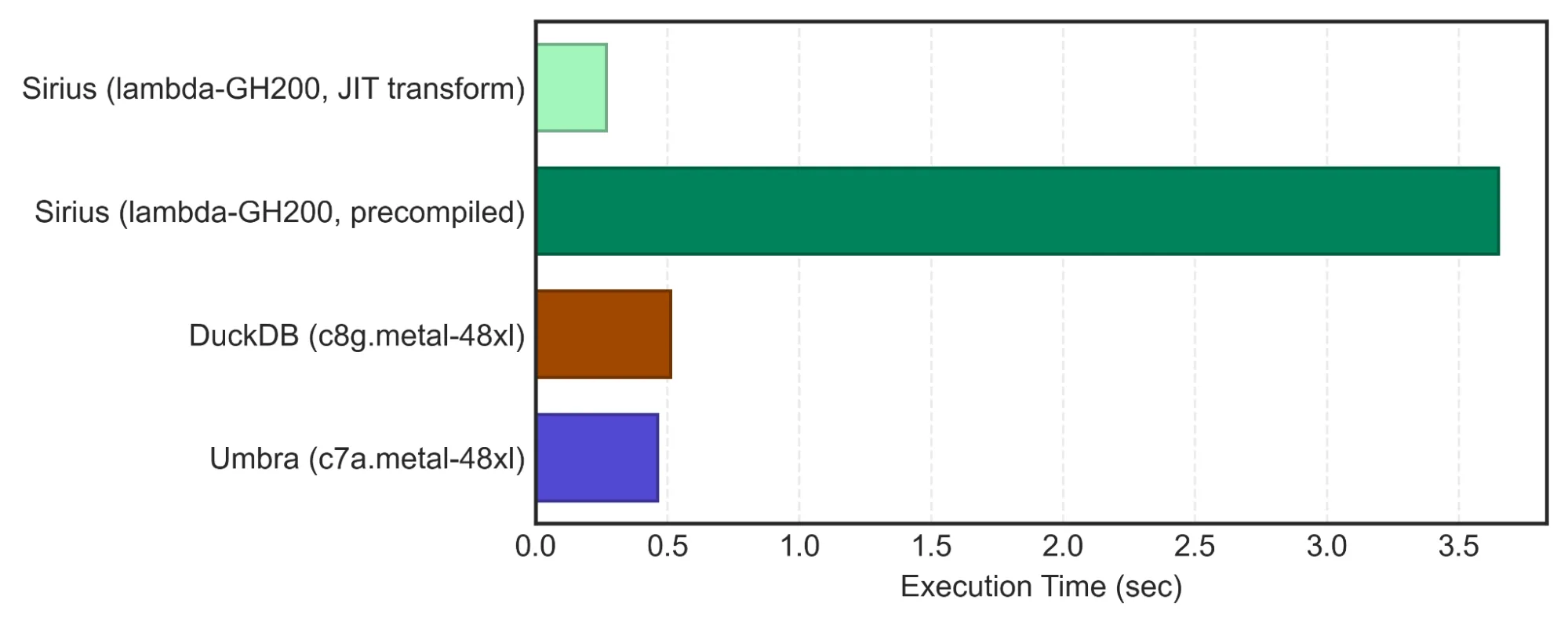
图 5 详细介绍了 ClickBench 查询中较为复杂的正则表达式查询 (q28)。如果简单地实施,GPU 上的正则表达式匹配会产生具有高寄存器压力和复杂控制流的大量内核,从而导致严重的性能下降。
为了解决这一问题,Sirius 利用 cuDF 的 JIT 编译字符串转换框架 来实现用户定义的函数。图 5 对比了 JIT 方法与 cuDF 预编译 API(cudf::strings::replace_with_backrefs)的性能,结果显示速度提升了 13 倍。
JIT 转换后的内核可实现 85% 的线程束占用率,而预编译版本仅为 32%,表明 GPU 利用率显著提升。通过将正则表达式分解为标准字符串操作(例如字符比较和子字符串操作),cuDF JIT 框架能够将这些操作融合到单个内核中,从而改善数据局部性并降低寄存器压力。

Sirius 的未来发展方向
展望未来,NVIDIA 与威斯康星大学麦迪逊分校正合作开发用于 GPU 数据处理的可共享基础模组,并遵循可组合 Codex 所述的模块化、可互操作、可组合、可扩展(MICE)原则。我们的重点方向包括:
- 高级 GPU 显存管理:开发可靠的策略以高效管理 GPU 显存,支持数据无缝溢出至超出物理 GPU 限制的存储空间,保障性能与扩展能力。
- GPU 文件读取器与智能 I/O 预取:集成支持 GPU 原生的文件读取器,结合智能预取机制,加快数据加载速度,显著减少停机时间并缓解 I/O 瓶颈。
- 面向工作流的执行模型:将 Sirius 的核心演进为完全可组合的工作流架构,简化 GPU、主机与磁盘间的数据流动,高效重叠计算与通信过程,同时实现与开放标准的即插即用互操作性。
- 可扩展的多节点、多 GPU 架构:拓展 Sirius 的能力,实现跨多节点与多 GPU 的高效横向扩展,释放 PB 级规模数据处理的潜力。
通过投资符合 MICE 标准的组件,Sirius 旨在让 GPU 分析引擎更易于构建、集成和扩展,不仅服务于 Sirius 自身,也惠及整个开源分析生态系统。
加入 Sirius
Sirius 是开源的,采用宽松的 Apache-2.0 许可证。该项目由 NVIDIA 与威斯康星大学麦迪逊分校共同领导,欢迎研究人员和从业者加入,携手推动数据分析领域迈入 GPU 时代。
我们邀请您:
- 在 ClickBench 上体验 Sirius。
- 探索我们的 GitHub 仓库。
- 了解 GPU 时代下分析处理的重新构想 并在 CIDR 2026 获取更多资讯。
- 加入 Sirius Slack 社区