
每个现代电子设备的核心都是一块硅芯片,它通过极为精密的制造工艺构建而成,微小的缺陷也可能决定其成败。随着半导体器件日益复杂,可靠的缺陷检测与分类已成为关键瓶颈。
过去,芯片制造商一直依靠卷积神经网络(CNN)来自动执行缺陷分类(ADC)。但随着制造业的扩展与多样化,基于CNN的方法正逐渐逼近其能力极限,需要大量标注数据集,频繁重新训练,仍难以应对新型缺陷实现有效泛化。
在本文中,我们将展示由生成式 AI驱动的 ADC 如何应对这些挑战。
以下工作流程利用 NVIDIA Metropolis 视觉语言模型 (VLM)、视觉基础模型 (VFM) 以及 NVIDIA TAO 微调工具包,实现缺陷分类的现代化。我们首先阐述基于 CNN 的传统系统存在的局限性,进而详细说明 VLM 与 VFM 如何有效应对这些挑战,并重点介绍其在解决特定方法与制造难题方面所发挥的作用。
CNN 在半导体缺陷分类中的局限性
长期以来,CNN 一直是半导体晶圆厂缺陷检测的核心技术,广泛应用于光学和电子束检测、光刻分析等领域。它们在从大规模数据集中提取视觉特征方面表现出色,但制造商仍面临数据需求高、语义理解困难以及需频繁重新训练等持续挑战。
高数据要求
要实现高准确度,通常每个缺陷类别都需要数千张已标注的图像。对于罕见或新出现的缺陷,往往缺乏足够数量的样本用于有效训练。
语义理解有限
虽然 CNN 能够捕捉视觉特征,但其无法解读上下文、进行根本原因分析或整合多模态数据。此外,它们在区分视觉上相似但操作上不同的缺陷模式时也面临困难,例如中心缺陷与局部缺陷。
频繁重新训练
现实世界的制造业具有动态性。工艺的变更、新工具的引入以及产品线的持续更新,都需要频繁地重新训练模型,以识别新出现的缺陷类型和不同的成像条件。
这些限制迫使晶圆厂不得不依赖人工检测,而人工检测不仅成本高昂、结果不一致,还难以适应当今制造所需的吞吐量。
借助 VLM 和 VFM 实现 ADC 现代化
为了应对这些挑战,NVIDIA 在半导体制造的多个阶段应用了 VLM、VFM 和自监督学习技术。图 1 展示了这些模型在生产线前端 (FEOL) 及后端封装流程中的部署方式。
在本文中,我们将展示 VLM 如何对晶圆贴图图像进行分类,以及 VFM 如何对裸片级图像(包括光学、电子束和后端光学显微镜(OM)检测数据)进行分类。通过进一步训练,VLM 还展现出在裸片级检查方面的重要潜力。

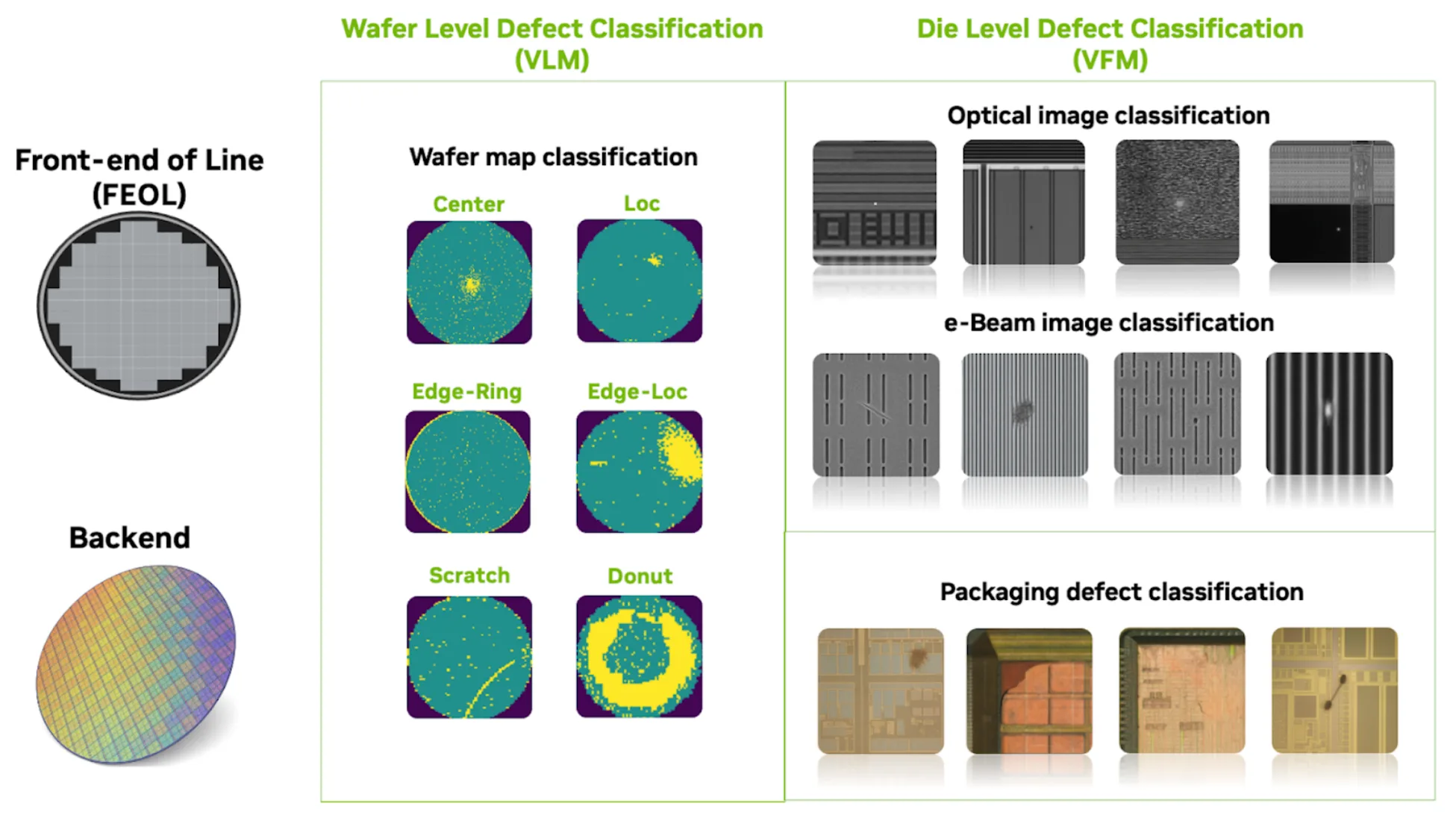
借助 VLM 实现晶圆级智能
晶圆贴图可提供整个晶圆中缺陷分布的空间视图。VLM 将高级图像理解与自然语言推理相结合。经过微调后,NVIDIA 的推理 VLMs,如 Cosmos Reason,能够解析晶圆贴图图像,识别宏观缺陷、生成自然语言解释、执行交互式问答,并将测试图像与“黄金”参考进行比对,以支持初步的根本原因分析。

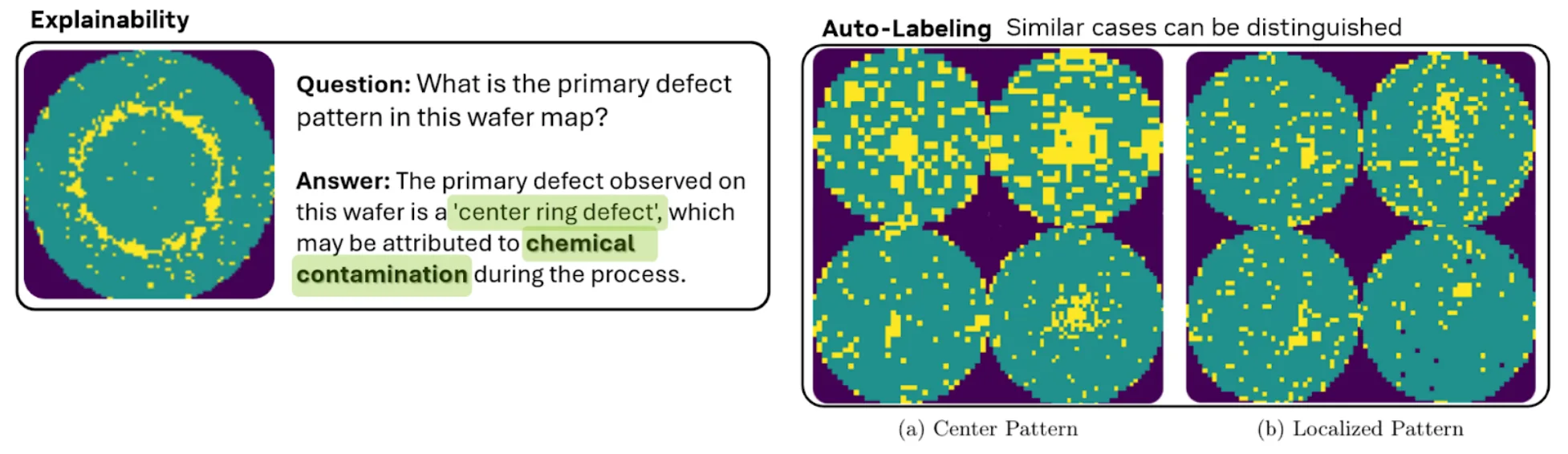
使用此方法具有以下优势:
- 少量样本学习: 仅需少量已标注样本即可对 VLM 进行微调,快速适应新的缺陷模式、工艺变化或产品变体。
- 可解释性: 如图 2 所示,Cosmos Reason 能够生成具备可解释性的结果,工程师可通过自然语言与其交互。例如,当询问“此晶圆贴图中的主要缺陷模式是什么?”时,系统可能返回“检测到的中心环缺陷可能是由于化学污染”。 这种语义推理能力超越了传统 CNN,有助于工程师快速识别潜在根本原因、加快纠正措施的实施,并减少人工审查的工作量。
- 自动数据标记: VLM 可以为下游 ADC 任务生成高质量标签,有效缩短模型开发周期并降低成本。在实践中,相比手动标记流程,该方法可将模型构建时间缩短至多两倍。
- 时间序列和批次级别分析:VLM 能够处理静止图像和视频序列,使其可主动监控流程随时间的变化,及时发现异常,并在错误引发严重故障前减少问题发生。在一项研究中,VLM 在 OK 和 NG 案例中均表现出较高的准确性,优于传统的基于 CNN 的方法。

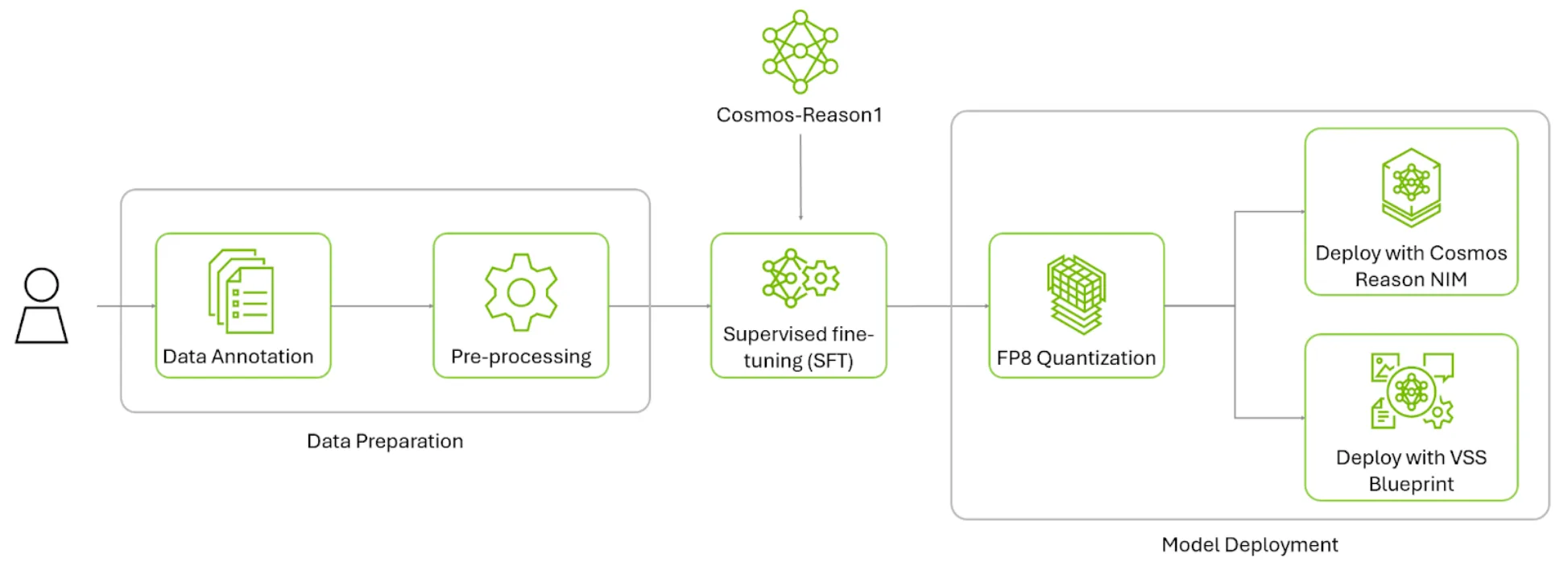
Cosmos 推理入门
这是一个微调 Cosmos Reason 1 的示例工作流,涵盖从数据准备到基于已准备好的晶圆图缺陷数据集进行监督微调及评估的完整过程。
- 前往 Cosmos Cookbook 晶圆贴图异常分类
- 创建示例训练数据集:下载由 Mir Lab 生成的开放版 WM-811k Wafermap 数据集,供公众使用。利用烹饪手册中提供的脚本,生成样本数据集及其对应标注。
- 采用监督式微调(SFT)进行后续训练:根据 cosmos-reason1 GitHub 仓库中的安装说明,安装 cosmos-rl 软件包,以便使用精心整理的训练数据集进行模型微调。
- 部署
结果:在微调晶圆贴图缺陷分类数据后,Cosmos Reason 可将缺陷分类任务的准确率从零样本水平提升至 96% 以上。
借助 VFM 与自监督学习实现裸片级精度
随着设备功能缩小到微观尺度,半导体行业将持续突破物理特性的界限。在此层面上,制造业的复杂性显著上升。即便是极其微小的异常(如杂散颗粒、图案偏差或材料缺陷),也可能导致芯片失效,直接影响产量与盈利能力。在这一高风险环境中,关键瓶颈在于能否快速且准确地检测并分类缺陷。多年来,CNN 一直支撑着这一工作流程,却难以应对现代晶圆厂日益增长的复杂性与数据需求。
训练制造业 AI 模型的核心挑战在于依赖精心标注的大型数据集。由于生产流程动态变化、产品线持续更新以及新型缺陷不断出现,维护完全标注的数据集变得极不现实。更棘手的是,数据集通常存在严重不平衡,正常样本的数量远超缺陷样本。
使用 NV-DINOv2 等先进的 VFM 具有以下优势:
- 自监督式学习 (SSL): NV-DINOv2 基于数百万张未标记图像进行训练,能够泛化至新的缺陷类型和不同的处理条件,在标记数据有限的情况下仅需极少的重新训练即可适应新场景。
- 强大的特征提取: 该模型可同时捕获精细的视觉细节与高层语义信息,显著提升在多种制造场景下的分类准确性。
- 运营效率:通过降低对数据标注和频繁重新训练的依赖,NV-DINOv2 有效简化了在快速变化的晶圆厂环境中缺陷检测系统的部署与维护流程。
但是,NV-DINOv2 等通用基础模型在电子束和光学显微镜图像等工业任务中,难以捕捉所需的特定细节。为了达到更高的准确性,模型需通过领域适应性进行专门化。
这是一个多阶段工作流程:
- 通用 VFM:基于强大的预训练 NV-DINOv2 模型,该模型从多样化的大型数据集中学习到了广泛的视觉理解能力。
- 领域适应性:利用大规模、无标注且特定领域的数据集(例如来自半导体晶圆厂的数百万张图像)对模型进行微调,使其更好地适应工业成像特征。
- 下游任务微调:通过少量已标注图像,针对特定分类任务进一步微调模型,此步骤称为线性探测。

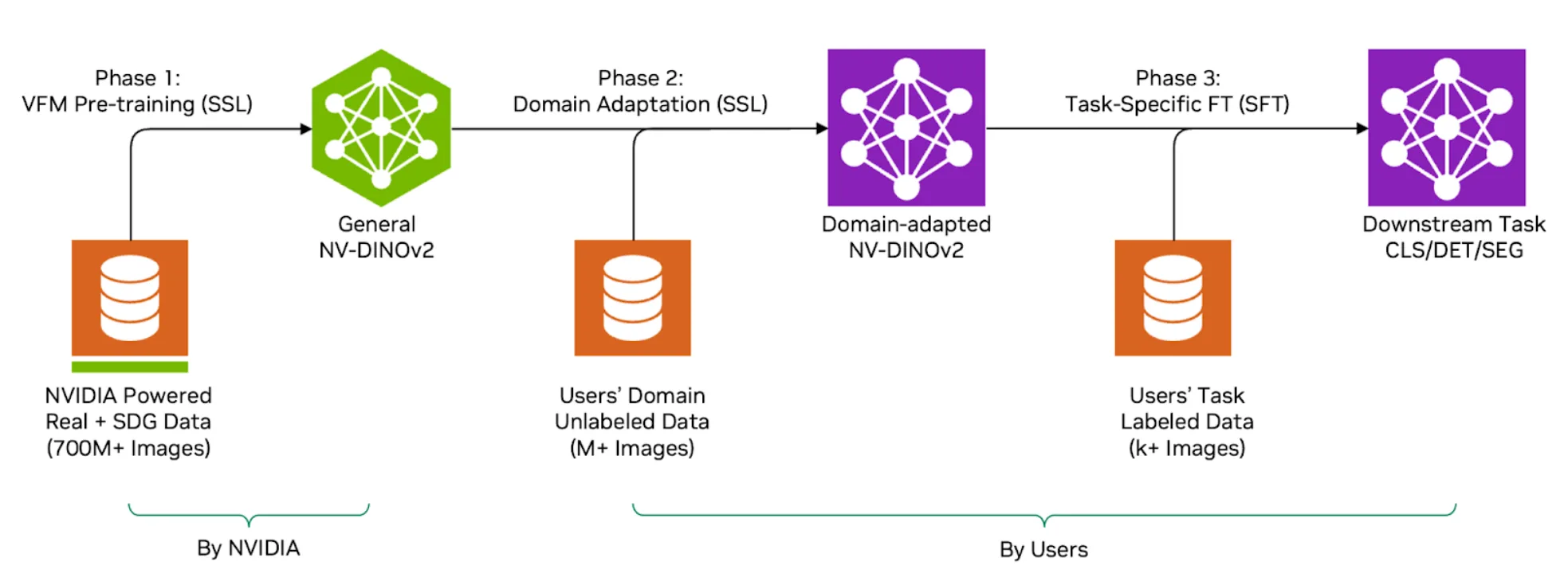
此过程的有效性在很大程度上取决于未标记域数据集的规模和质量。这些数据集可能包含从不到一百万张到数亿张图像不等,但仅靠数量并不足够。在训练开始前,细致的数据清理流程对于剔除冗余、模糊或不相关的图像尤为关键。
这种领域自适应方法可显著提升性能。一家领先的半导体制造商在一项研究中采用 NVIDIA TAO 工具套件,利用芯片生产过程中多层收集的无标记图像,将自监督学习(SSL)应用于 NV-DINOv2。相比未使用 SSL 训练的模型,引入 SSL 后性能实现持续提升,准确率最高提升达 8.9%,工作效率随之提高达 9.9%。
开始使用 NV-DINOv2 和 SSL
以下是使用自监督学习(SSL)对 NV-DINOv2进行端到端微调的工作流程,涵盖数据准备、域自适应、下游任务微调及部署。在本示例中,我们采用 NVIDIA TAO 工具套件,利用未标注的 PCB 图像进行自监督学习,以实现缺陷分类。
NV-DINOv2 工作流程采用渐进式三阶段方法,能充分提升大型无标记数据集的价值,同时将手动标注的需求减少至仅需几百个已标记样本。
1. 设置您的环境:从NVIDIA TAO 工具套件 6.0容器下载,该容器已预装所有依赖项:
# Pull the TAO Toolkit 6.0 container from NGC
docker pull nvcr.io/nvidia/tao/tao-toolkit:6.0.0-pyt
# Run the container with GPU support
docker run --gpus all -it -v /path/to/data:/data \
nvcr.io/nvidia/tao/tao-toolkit:6.0.0-pyt /bin/bash
2. 准备数据集:NV-DINOv2 接受以标准格式(JPG、PNG、BMP、TIFF、WebP)存储在单一目录中的 RGB 图像。在进行 SSL 域自适应时,只需提供未标记的图像,无需标注数据。
在 PCB 检测示例中,我们使用了:
- + 400 个带标记的测试样本,用于模型评估
- + 100 万张未标记的 PCB 图像,用于领域适应
- + 600 多个带标记的训练样本,用于下游任务微调
按以下方式整理数据:
/data/
├── unlabeled_images/ # For SSL domain adaptation
├── train_images/ # For downstream fine-tuning
│ ├── OK/
│ ├── missing/
│ ├── shift/
│ ├── upside_down/
│ ├── poor_soldering/
│ └── foreign_object/
└── test_images/ # For evaluation
数据清理最佳实践:训练前应执行细致的数据清理,剔除冗余、模糊或不相关的图像。领域适应性的效果在很大程度上依赖于未标记数据集的质量。
3. 配置训练规范:创建一个 YAML 规范文件,用于定义模型架构、数据集路径以及训练参数:
model:
backbone:
teacher_type: "vit_l"
student_type: "vit_l"
patch_size: 14
img_size: 518
drop_path_rate: 0.4
head:
num_layers: 3
hidden_dim: 2048
bottleneck_dim: 384
dataset:
train_dataset:
images_dir: /data/unlabeled_images
test_dataset:
images_dir: /data/test_images
batch_size: 16
workers: 10
transform:
n_global_crops: 2
global_crops_scale: [0.32, 1.0]
global_crops_size: 224
n_local_crops: 8
local_crops_scale: [0.05, 0.32]
local_crops_size: 98
train:
num_gpus: 8
num_epochs: 100
checkpoint_interval: 10
precision: "16-mixed"
optim:
optim: "adamw"
clip_grad_norm: 3.0
4. 针对领域适应性进行 SSL 训练:使用 TAO Launcher 执行训练,将通用 NV-DINOv2 模型适配至特定领域的图像:
tao model nvdinov2 train \
-e /path/to/experiment_spec.yaml \
results_dir=/output/ssl_training \
train.num_gpus=8 \
train.num_epochs=100
5. 执行下游任务微调: 在适应 SSL 域后,使用少量标记数据针对特定分类任务对模型进行微调。此步骤称为线性探测,仅需几百个标记样本即可:
tao model nvdinov2 train \
-e /path/to/finetune_spec.yaml \
train.pretrained_model_path=/output/ssl_training/model.pth \
dataset.train_dataset.images_dir=/data/train_images \
train.num_epochs=50
6. 运行推理:在测试图像上评估适应特定领域的模型:
tao model nvdinov2 inference \
-e /path/to/experiment_spec.yaml \
inference.checkpoint=/output/ssl_training/model.pth \
inference.gpu_ids=[0] \
inference.batch_size=32
7. 将训练好的模型导出为 ONNX 格式,以便进行生产部署:
tao model nvdinov2 export \
-e /path/to/experiment_spec.yaml \
export.checkpoint=/output/ssl_training/model.pth \
export.onnx_file=/output/nvdinov2_domain_adapted.onnx \
export.opset_version=12 \
export.batch_size=-1
导出的 ONNX 模型可利用 NVIDIA TensorRT 进行部署,以优化推理性能,也可集成至 NVIDIA DeepStream 工作流,实现高效的实时视觉检测。
结果:使用 NVIDIA TAO 通过自监督学习(SSL)对 NV-DINOV2 进行微调,同样适用于 PCB 检测。通过采用包含约 100 万张无标签图像的数据集进行工业领域自适应,并结合 600 个训练样本和 400 个测试样本完成下游任务微调,缺陷检测准确率从通用模型的 93.84% 提升至 98.51%。NV-DINOV2 降低了对数据标注和频繁重新训练的依赖,显著简化了缺陷检测方案在快速变化的晶圆厂环境中的部署。
为打造智能晶圆厂铺平道路
这些视觉模型的应用可立即提升准确性,并为晶圆厂内的代理式 AI系统奠定基础。通过结合加速计算与生成式 AI,NVIDIA 与领先的代工厂正共同推出新型 ADC 工作流,有望重新定义先进制造业中的良率提升与工艺控制。
通过简化半导体生产流程中的缺陷分析,生成式 AI 能显著缩短模型部署时间。其少量样本学习能力不仅简化了模型的持续维护,还提升了模型的鲁棒性,同时使针对不同晶圆厂环境进行模型微调变得更加便捷。
随着晶圆厂每天通过各类检测工具产生数百万张高分辨率图像,自动化ADC系统有望进一步提升分类准确性、降低人工工作量并提高整体生产效率。
除了缺陷检测,半导体制造商也开始采用基于 视频分析 AI 智能体 构建的 NVIDIA Blueprint for Video Search and Summarization (VSS)。这些智能体有助于监控工厂运营,提升工人安全,并加强制造现场对 PPE 和安全协议的合规性。
后续步骤
如需了解更多信息,请试用 NV-DINOv2 以及先进的 NVIDIA VLM,例如 Cosmos Reason。如遇到技术问题,请访问 论坛。




