
采用 NVIDIA Blackwell 架构的 NVIDIA GB200 NVL72 和 NVIDIA GB300 NVL72 系统是机架级超级计算机。它们采用 18 个紧密合的计算托盘、大型 GPU 网络和整体式高带宽网络设计。
对于 AI 架构师和 HPC 平台运营商而言,挑战不仅仅在于机架和堆叠硬件,还在于将基础设施转变为面向最终用户的安全、高性能且易于使用的资源。机架级硬件拓扑与调度器抽象之间的不匹配是大多数操作复杂性的问题。如果不解决这个问题,调度器会在平面 GPU 和节点池上运行,而忽略了系统的分层和拓扑敏感型设计。
这是 NVIDIA Mission Control 等经过验证的软件堆栈旨在弥合的差距。Mission Control 为 NVIDIA Grace Blackwell NVL72 系统 提供机架级控制平面。凭借对 NVIDIA NVLink 和 NVIDIA IMEX 域的原生理解,它与工作负载管理平台如 Slurm 和 NVIDIA Run:ai 集成。NVIDIA Vera Rubin 平台 (包括 NVIDIA Rubin NVL8) 也将支持这些功能。
本文将介绍 Mission Control、Slurm 和 NVIDIA Run:ai 如何将高级 GPU 架构概念 (例如 NVLink 和 IMEX 域) 转变为可扩展、可调度且易于管理的可操作 AI 工厂。
核心挑战:机架级拓扑与 AI 工作负载调度相结合
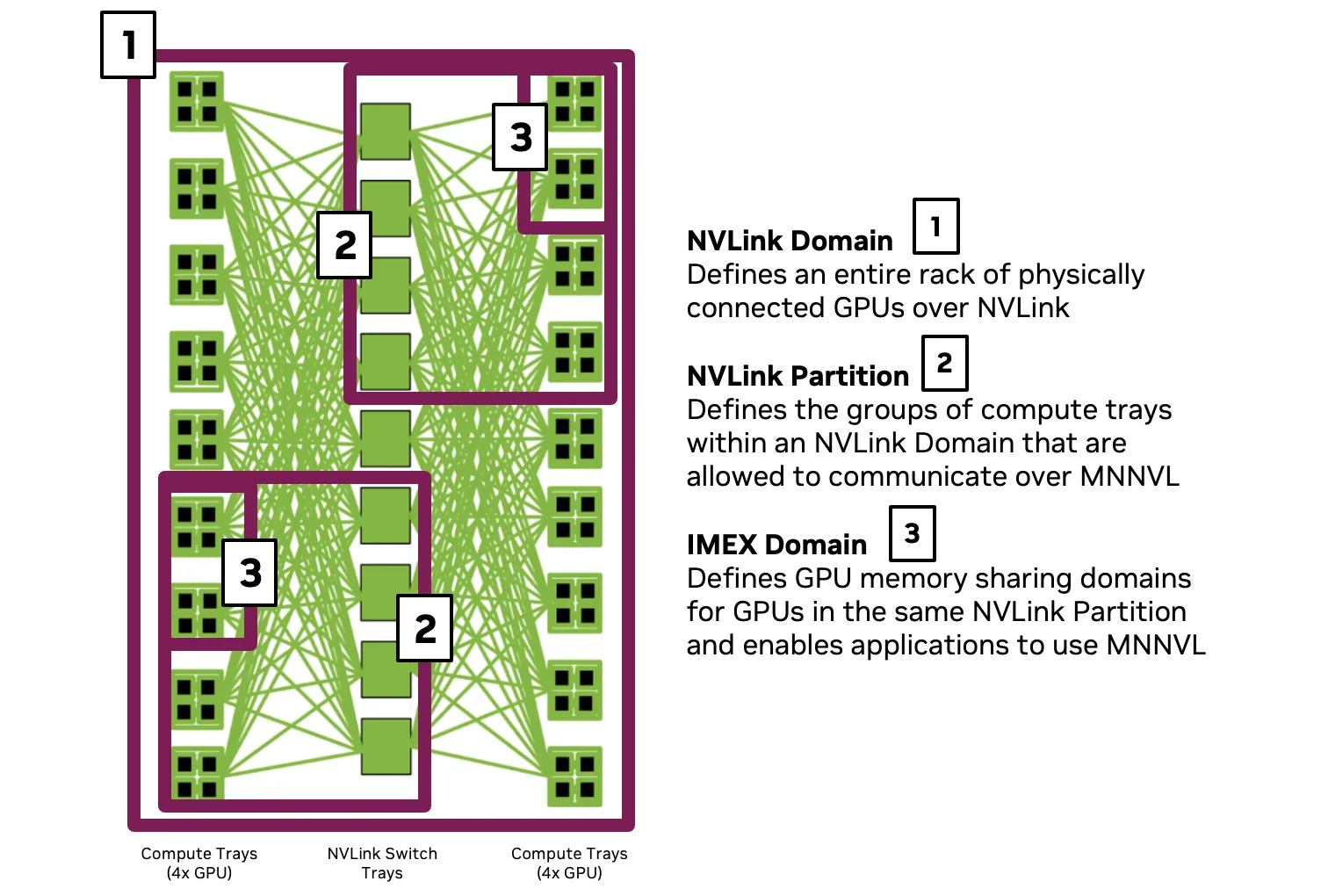
在物理层面,GB300 NVL72 和 GB200 NVL72 系统是强大而复杂的系统。每个 GPU 都提供由 NVLink 交换机连接的密集 GPU 网络,在机架内支持 NVIDIA 多节点 NVLink (MNNVL) ,并包含支持 IMEX 的计算托盘,可在节点间共享 GPU 显存。
然而,调度程序无法在交换机和网络层面上运行。它们需要:
- 独立 GPU 资源池可预测地分配。
- 清晰的隔离边界保护工作负载免受其他工作负载的影响。
- 一致的性能特征满足用户期望。
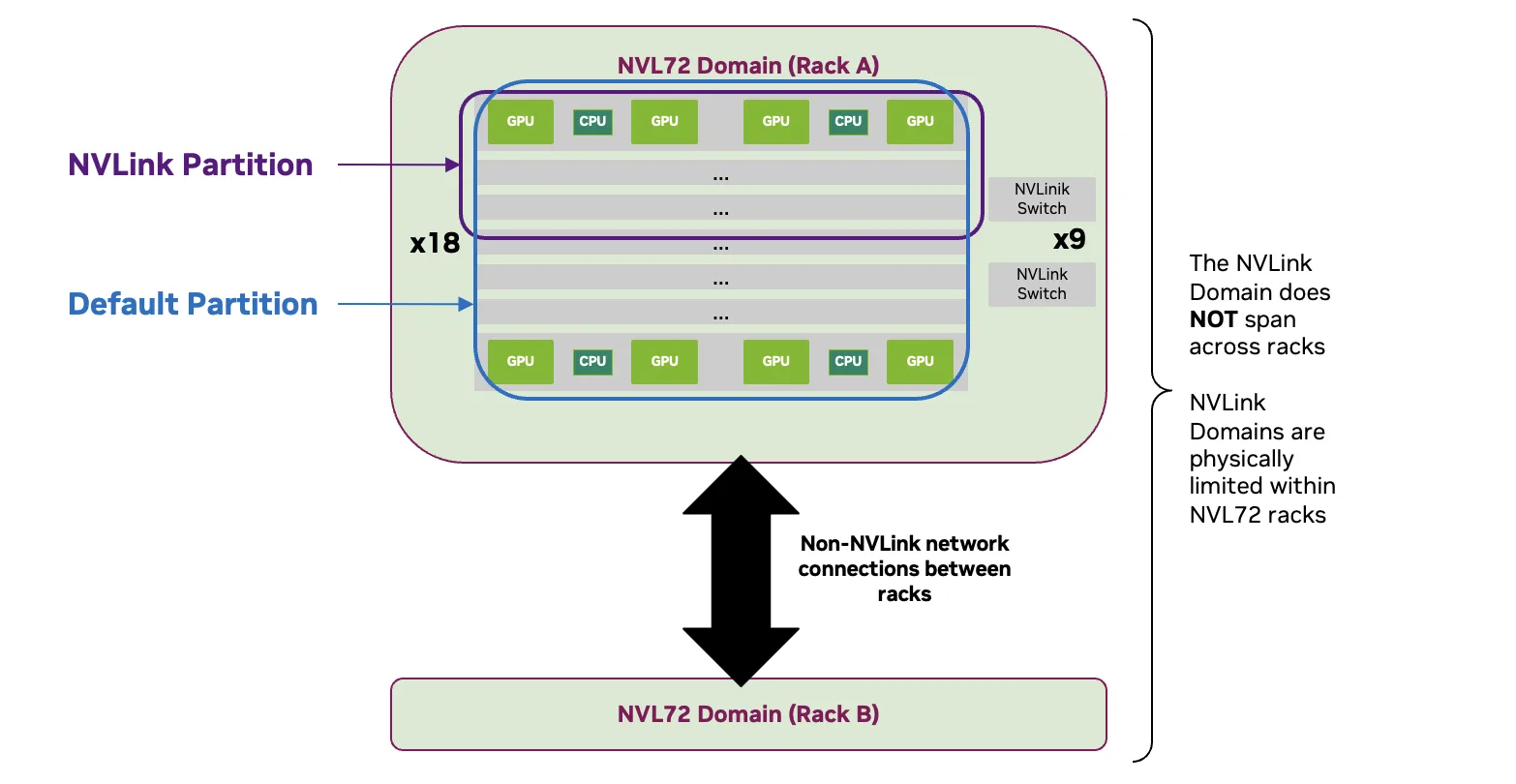
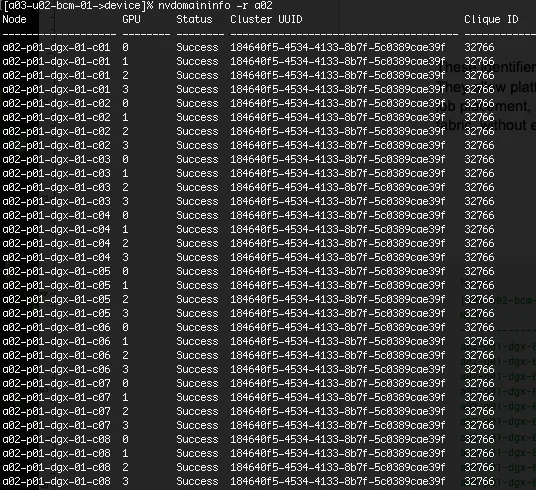
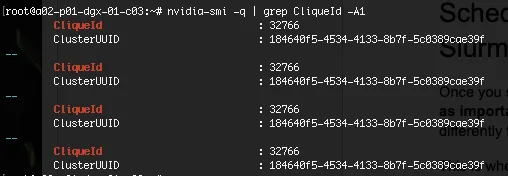
在幕后,Grace Blackwell NVL72 机架的 NVLink 拓扑结构通过一对系统级标识符: Cluster UUID 和 Clique ID 反映在软件堆栈上。
这些标识符进行编码a GPU’s position in the NVLink fabric– 以系统软件、调度程序和更高级别的工具可以推理的方式跨域或跨机架运行。
映射很简单:
- Cluster UUID 对应 NVLink 域。
- Clique ID 对应 NVLink 分区。
共享 Cluster UUID 意味着系统及其 GPU 属于同一 NVLink 域,并通过通用 NVLink 结构进行连接。在 Grace Blackwell NVL72 上,此 UUID 在整个机架上保持一致:同一 NVL72 机架中的所有 GPU 都报告相同的 Cluster UUID。
Clique ID 提供了更精细的区分。共享 Cluster ID 的 GPU 属于该域中的同一 NVLink 分区。当机架雕刻成多个 NVLink 分区时,Cluster UUID 保持不变 (因为 GPU 位于同一物理 NVLink 域中) ,但 Cluster ID 不同,以反映结构的逻辑分区。
从运营角度来看,这种区分非常重要:
- Cluster UUID 回答:哪些 GPU 在物理上共享一个机架,并且能够进行 NVLink 通信?
- Clique ID 回答:哪些 GPU 共享 NVLink 分区,并且打算针对给定的工作负载或服务层一起通信?
这些标识符构成了硬件拓扑和调度逻辑之间的结缔组织。它们使 Slurm、Kubernetes 和 NVIDIA Run:ai 等平台能够将作业放置、隔离和性能保证与 NVLink 结构的实际结构保持一致,而不会直接向最终用户暴露这种复杂性。
使用 Slurm 调度多节点 NVLink 工作负载
开始在基于 Blackwell 的 NVL72 系统上运行多节点工作负载后,布局变得与 GPU 数量一样重要。分布在错误节点上的 16-GPU 作业的行为方式可能与局限于单个 NVLink 结构的同一作业截然不同。
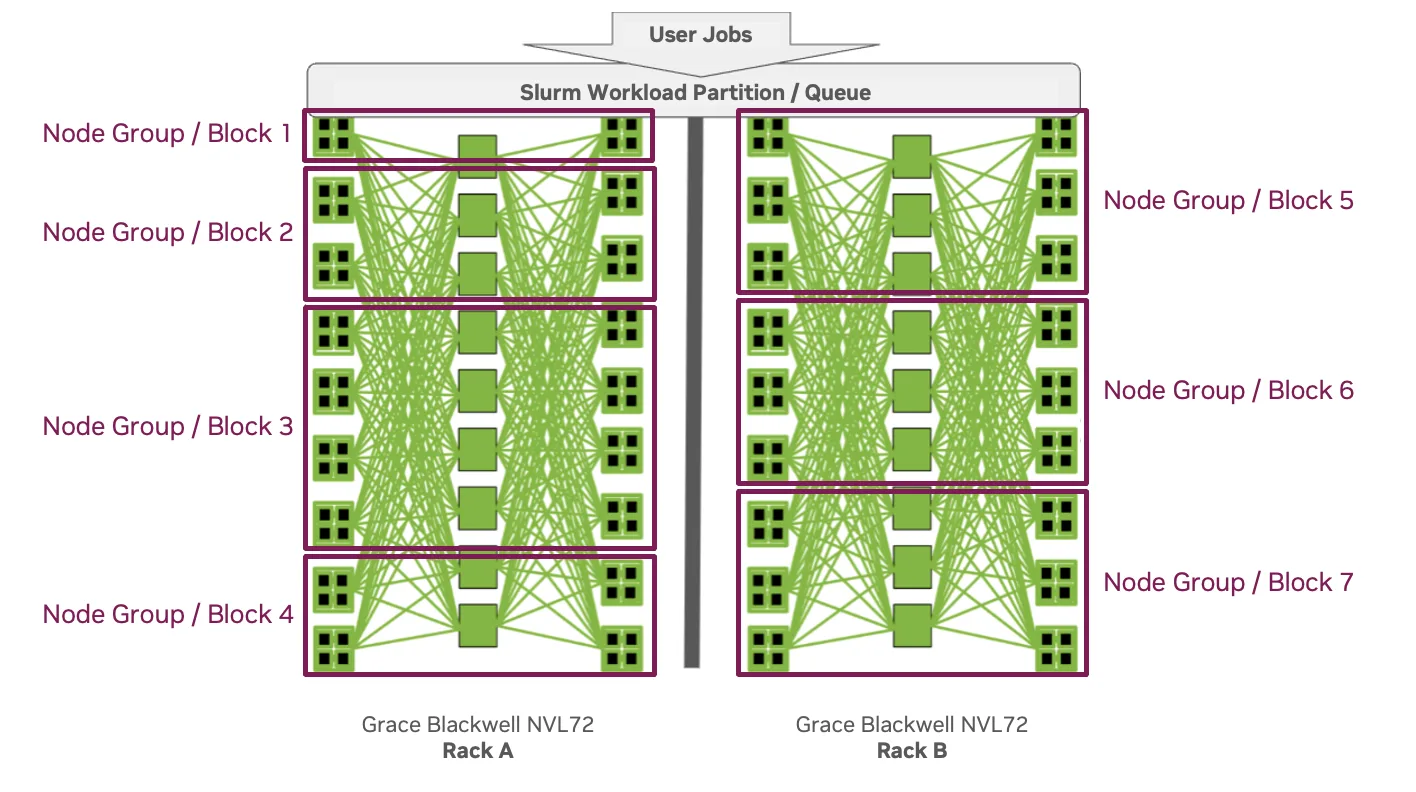
此时,Slurm 的拓扑/ 块插件变得至关重要,使 Slurm 能够识别并非所有节点都相同。
在 Grace Blackwell 上,具有低延迟连接的节点块直接映射到 NVLink 分区——共享高带宽 NVLink 结构的 GPU 组。
以两个 NVL72 机架为例。这两个机架可能属于同一个 Slurm 分区 (队列) ,但这并不意味着作业可以自由地跨越它们。从性能的角度来看,每个机架 (或从中雕刻的每个 NVLink 分区) 都是一个独特的高带宽块。
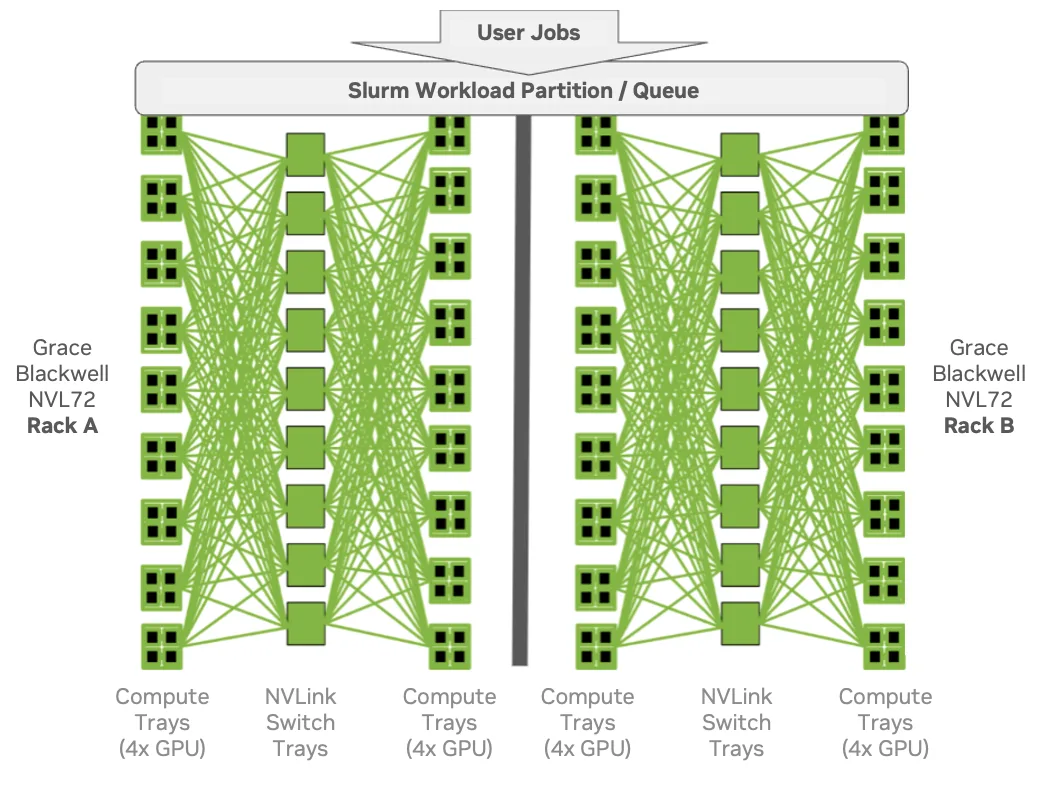
通过启用拓扑/ 块插件并将 NVLink 分区作为块公开,Slurm 可获得做出更明智决策所需的上下文。默认情况下,作业置于单个 NVLink 分区 (或块) 内,从而保持 MNNVL 性能。必要时,较大的作业可以跨块执行,但需要权衡取舍,而非偶然取舍。
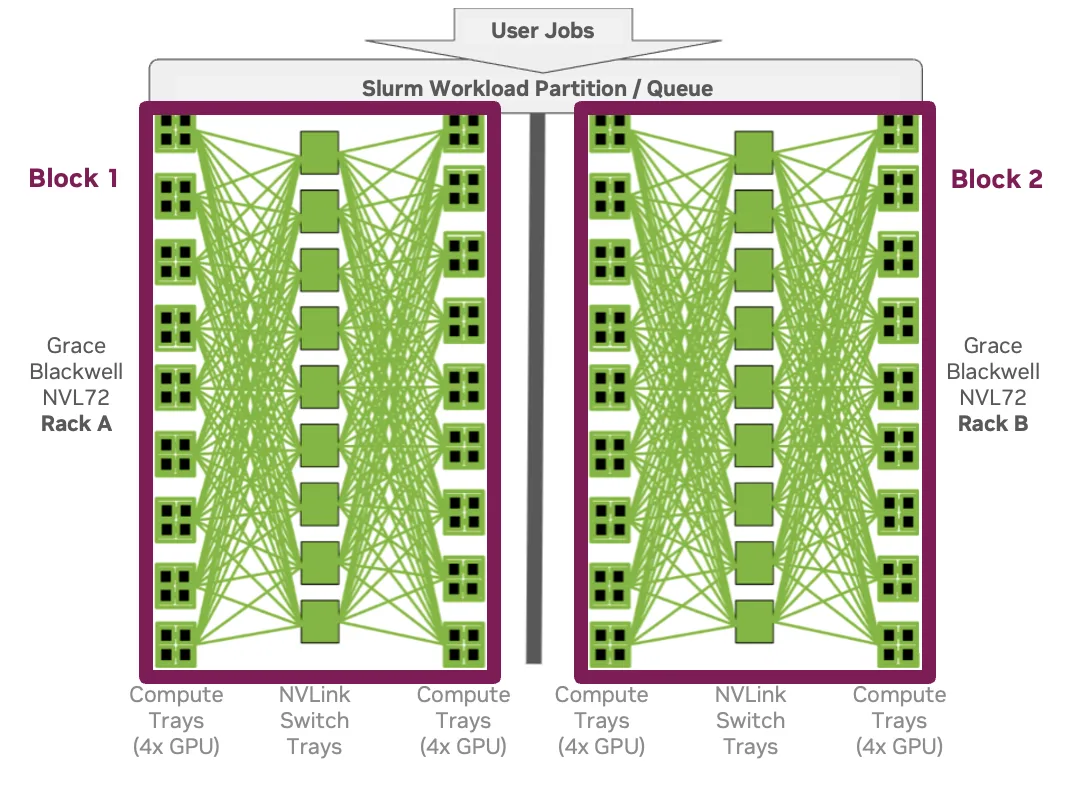
在实践中,这意味着:
- 每个机架一个块/ 节点组在用户或组级别应用 Slurm QoS 来管理对共享分区的访问。
- 每个机架有多个块/ 节点组提供更小、独立的高带宽 GPU 池。在此模型中,每个块/ 节点组都会映射到 Slurm 分区,从而为每个分区提供服务层。用户可通过 Slurm 分区自动进入目标 NVLink 分区,而无需了解底层结构。
使用 Slurm 进行 IMEX 管理:从机架级服务到逐项作业隔离
对于依赖 MNNVL 的多节点 NVIDIA CUDA 工作负载,IMEX 使不同计算托盘上的 GPU 能够参与共享内存编程模型。
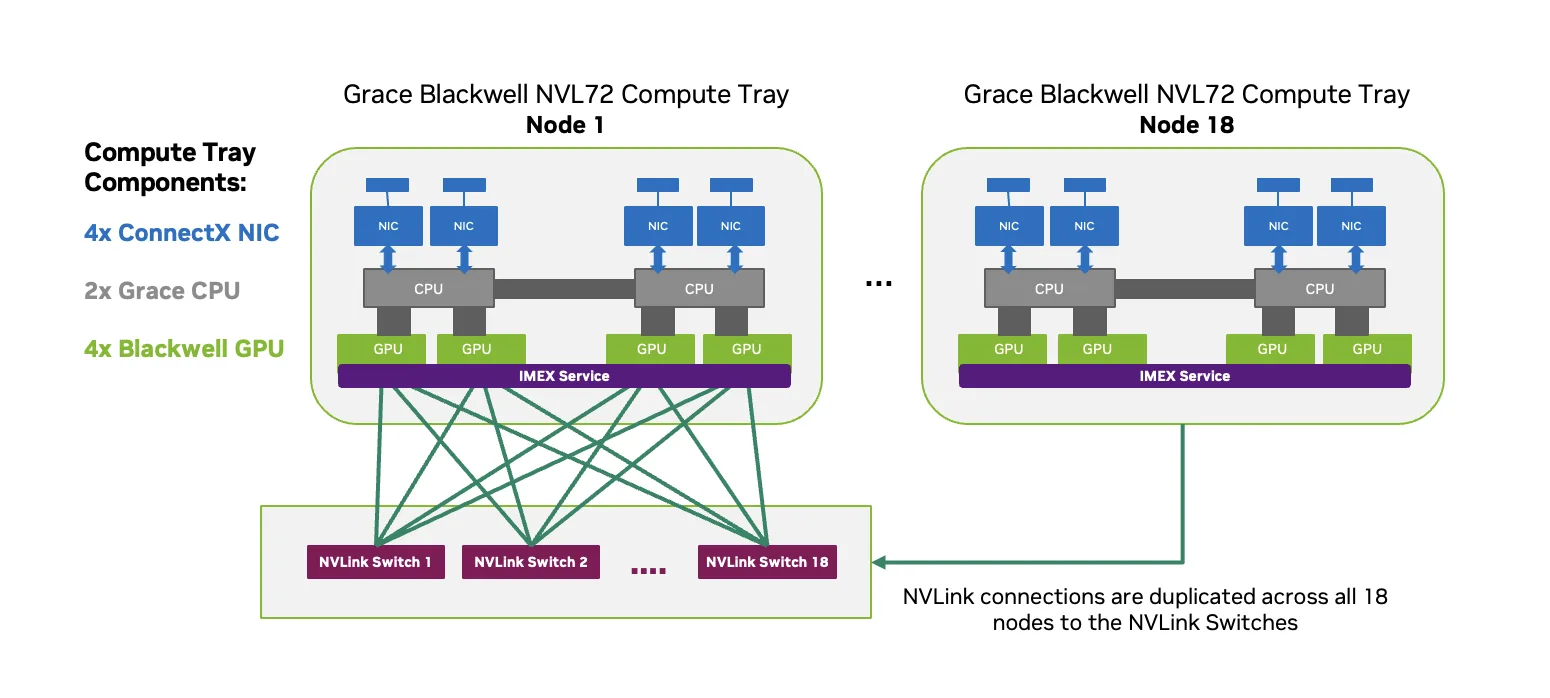
从应用程序的角度来看,使用 MNNVL 看起来很简单。但实际上,在使用 Slurm 运行 MNNVL 作业时,Mission Control 可确保以下几项保持一致:
- IMEX 运行在确切地说参与作业的一组计算托盘。
- 这些托盘属于常见的 NVLink 分区。
- IMEX 生命周期可靠、安全,范围足够紧密,可避免交叉作业干扰。
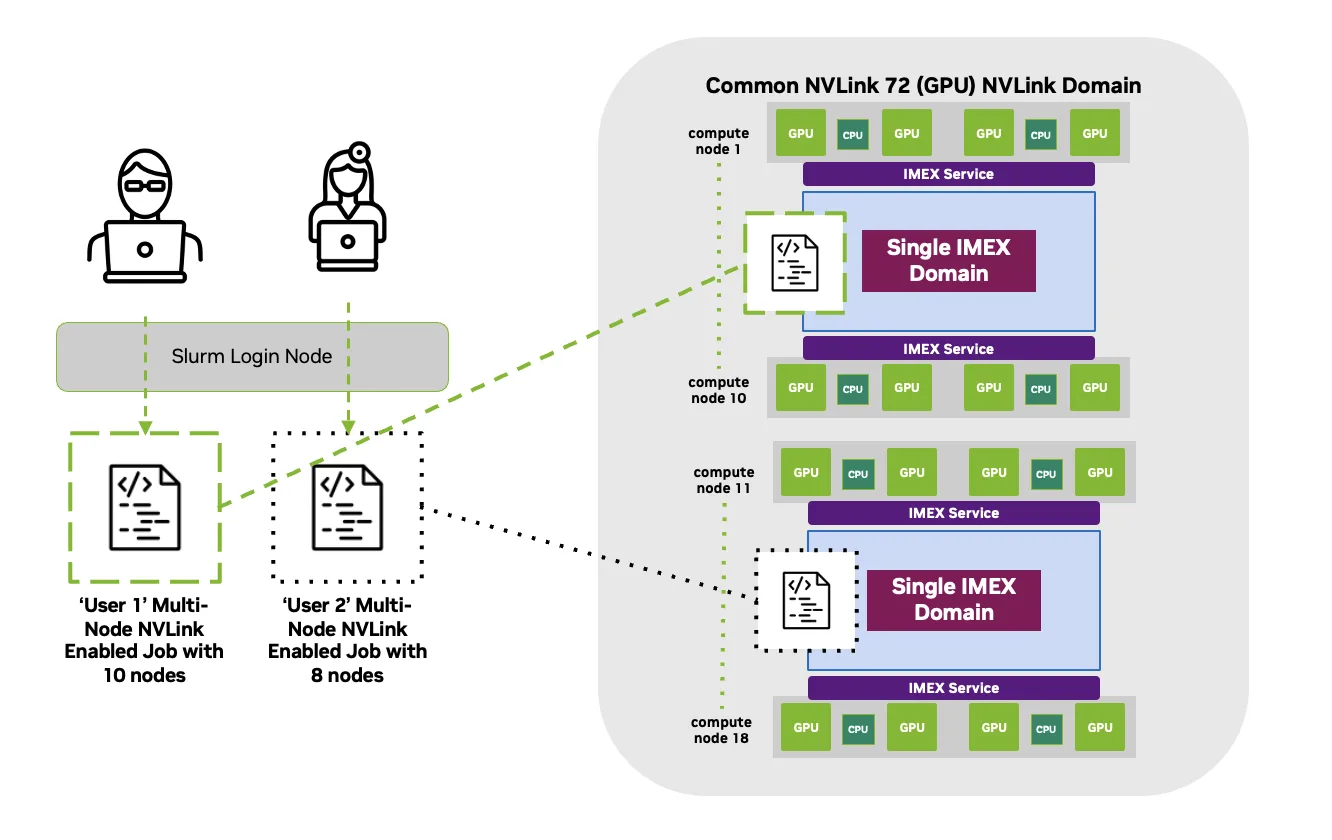
IMEX 是在每个计算托盘的主机操作系统中运行的系统级守护程序。它提供了 CUDA 库所依赖的内存共享和同步机制。如果 IMEX 范围错误、运行得过于宽泛或出现噪音故障,多节点工作负载很快就会变得脆弱。
将多节点 NVLink 支持扩展到 Kubernetes 和 NVIDIA Run:ai
正如 Slurm 需要帮助理解 NVLink 结构以优化调度 Grace Blackwell NVL72 作业一样,Kubernetes 也缺乏对 NVLink 等机架级高带宽互连的原生感知。
为解决这一问题,NVIDIA 生态系统结合了计算域(通过 NVIDIA 动态资源分配 (DRA) GPU 驱动)和NVIDIA Run:ai 集成——将 NVLink 和 IMEX 概念提升为域感知、调度器就绪的基元。
在 Kubernetes 中,动态资源分配 (DRA) 提供了一个 API,用于对专用硬件进行灵活、精细的管理。
NVIDIA k8s-dra-driver-gpu 可为 GPU 和计算域实现此 API。该驱动包括用于 GPU 分配和计算域的单独 kubelet 插件,启用后,管理 GPU 多节点 NVLink 域,将跨节点的 GPU 分组为安全、高带宽、内存一致性的域,用于 HPC 和 AI 工作负载。
Kubernetes:从平面调度程序到 NVLink 感知布局
在 Kubernetes 中,核心挑战类似于 Slurm。Kubernetes pods need to be placed on nodes that share high-bandwidth connectivity.Kubernetes 本身无法理解 NVLink 域,因此工作负载可能分散在缺乏高效多节点执行所需的结构连接的节点上。
解决方案是 NVIDIA DRA 驱动为 GPU 提供的计算域概念。计算域是一个 计算域 概念,由 NVIDIA DRA 驱动为 GPU 提供。计算域:
- 表示共享 NVLink/ MNNVL 域的一组节点。
- 工作负载提交必须创建计算域对象并通过资源声明当分布式工作负载 (训练或推理) 提交时。
- 与参与工作负载的确切 pod 集绑定。
- 工作负载结束时拆解。
通过这样做,计算域使高性能网络在调度方面处于领先地位。ComputeDomain 还可确保 IMEX 通道等底层资源得到正确实例化,并针对工作负载确定范围。
---apiVersion: resource.nvidia.com/v1beta1kind: ComputeDomainmetadata: name: compute-domainspec: numNodes: 18 channel: resourceClaimTemplate: name: compute-domain-resource-claim---apiVersion: apps/v1kind: Deploymentmetadata: name: test-workload labels: app: test-workloadspec: replicas: 18 selector: matchLabels: app: test-workload template: metadata: labels: app: test-workload spec: containers: - name: ctr image: ubuntu:22.04 command: ["test-workload"] resources: limits: nvidia.com/gpu: 4 claims: - name: compute-domain resourceClaims: - name: compute-domain resourceClaimTemplateName: compute-domain-resource-claim |
NVIDIA Run:ai 如何简化 NVLink 域上的分布式工作负载
NVIDIA Run:ai 基于 Kubernetes 和 ComputeDomain 构建,使 Grace Blackwell NVL72 系统可用,而无需让用户接触 NVLink 拓扑、IMEX 域或低级调度机制。用户需要分布式 GPU。NVIDIA Run:ai 负责处理其余工作。
在幕后,NVIDIA Run:ai 可自动执行以下几个关键部分:
- 自动检测和标记:GB200 NVL72 节点根据其 NVLink/ MNNVL 域成员身份进行识别和标记。这些标签构成了 NVLink 感知布局的基础。
- 由计算域支持的工作负载放置:提交作业后,系统会自动创建并附加计算域。Pod 放置在共享 NVLink 连接和正确范围的 IMEX 域的节点上。
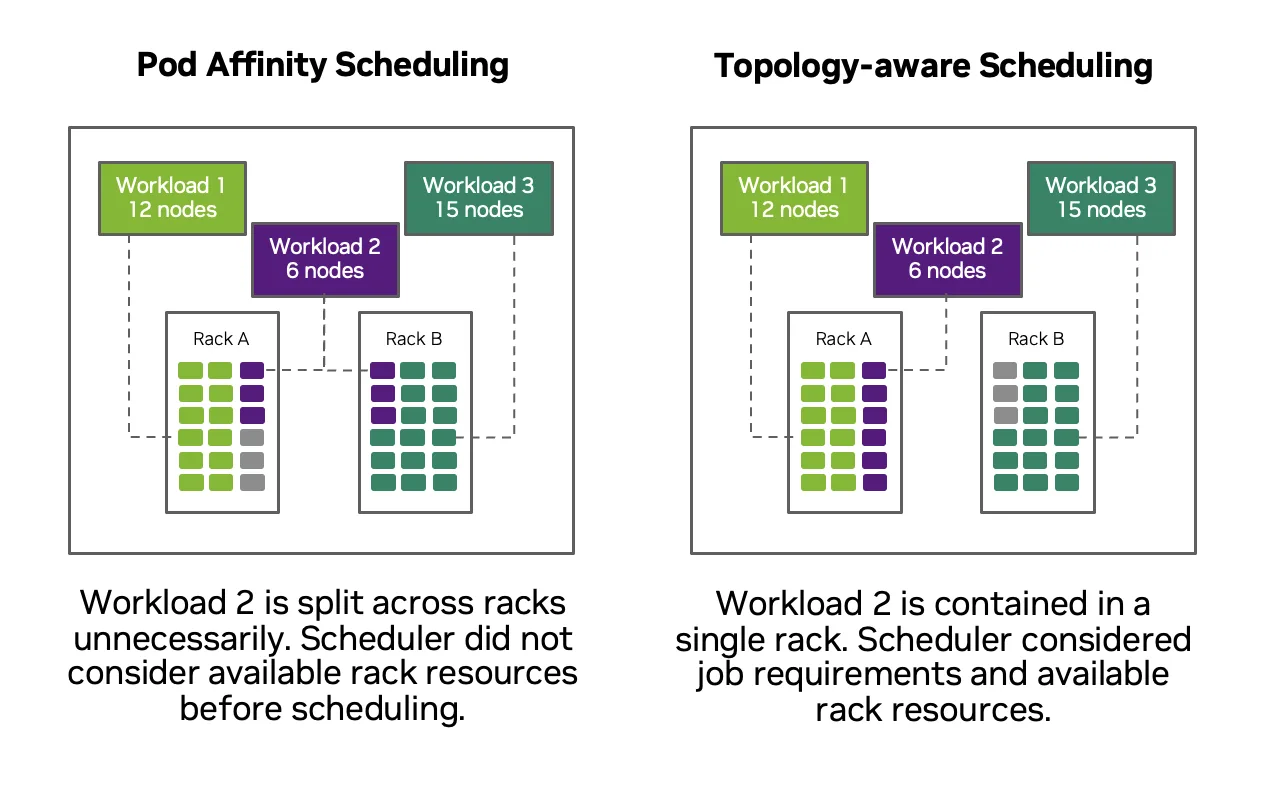
- 拓扑感知调度:为节点池定义网络拓扑时,NVIDIA Run:ai 会应用拓扑感知型调度首选项,以尽可能靠近分布式工作负载中的所有 Pod,仅在必要时向外扩展。这可降低延迟并避免意外的跨域放置。
使用 Topograph 进行自动拓扑检测
所有这些方法都依赖于对底层硬件和网络拓扑的准确了解。对于平台工程师而言,手动定义 NVLink 域、机架边界或网络层次结构无法在大型或频繁变化的环境中进行扩展。这正是 NVIDIA 开源工具 Topograph 的用武之地。
Topograph 通过收集节点级和基础设施元数据并将其转换为调度程序可使用的表示,自动发现集群拓扑。它可以跨机架、交换机或网络层次结构检测节点的连接方式,并通过更高级别的系统可以使用的 API 揭示此结构。调度器可以获得有关邻近距离和带宽关系的具体视图,而不是假设为平面集群。
与 Slurm 和 Kubernetes 以及 ComputeDomain 和 NVIDIA Run:ai 结合使用时,Topograph 可实现完全自动化的流程。拓扑结构是被发现而不是手动建模的,节点的标记是一致的,拓扑感知的放置决策可以在最少的操作员干预下做出。这缩小了物理基础设施与逻辑调度抽象之间的差距。
详细了解高级 AI 运营
请查看 Mission Control 管理员指南 或 用户指南,了解有关实施的更多信息。
点播观看礼来公司的 NVIDIA GTC 2026 会议,了解他们如何借助强大的智能软件从机架级硬件发展为可调度的 AI 基础设施。




