
在生产 Kubernetes 环境中,模型要求与 GPU 大小之间的差异导致效率低下。轻量级自动语音识别 (ASR) 或文本转语音 (TTS) 模型可能只需要 10 GB 的 VRAM,但在标准 Kubernetes 部署中却会占用整个 GPU。由于调度程序将模型映射到一个或多个 GPU,并且无法轻松地跨模型在 GPU 之间共享,因此昂贵的计算资源通常仍未得到充分利用。
解决这个问题不仅仅涉及降低成本,还涉及优化集群密度,以便在相同的世界级硬件上为更多并发用户提供服务。本指南详细介绍了如何实施和基准测试 GPU 分区策略,特别是 NVIDIA 多实例 GPU (MIG) 和时间片,以充分利用计算资源。
我们使用生产级语音 AI 工作流作为测试平台,展示了如何组合模型,以更大限度地提高基础设施投资回报率,同时保持 > 99% 的可靠性和严格的延迟保证。

解决 GPU 资源碎片化问题
默认情况下,适用于 Kubernetes 的 NVIDIA 设备插件会将 GPU 显示为整数资源。POD 请求nvidia.com/gpu::1调度程序将其绑定到物理设备。
NVIDIA Nemotron、Llama 3 或 Qwen 7B/ 8B 等大语言模型 (LLM) 需要专用计算来维持首个词元 (TTFT) 的短时和高批量吞吐量。但是,生成式 AI 工作流中支持的模型 (嵌入模型、ASR、TTS 或护栏) 通常只使用显卡的一小部分。在专用 GPU 上运行这些轻量级模型可实现:
- 利用率低:GPU 计算利用率通常保持在 0-10% 附近。
- 集群膨胀:需要配置更多节点才能运行相同数量的 POD。
- 扩展摩擦:添加新功能需要新的物理 GPU。
要解决这个问题,我们必须打破 POD 与 GPU 之间的 1:1 关系。
架构:分区策略
我们评估了 NVIDIA GPU Operator 支持的两种主要 GPU 分区策略。
基于软件的分区:时间切片和 MPS
时间片技术使多个 NVIDIA CUDA 进程能够通过交错执行共享一个 GPU。其功能与 CPU 调度程序类似:上下文 A 运行、暂停,上下文 B 运行。
- 机制:通过 CUDA 驱动实现软件级调度。
- 优点:更大限度地提高利用率。启用“突发”– 如果 Pod A 处于空闲状态,Pod B 可以使用 100% 的 GPU 计算核心。
- 缺点:没有硬件隔离。一个 POD 中的内存溢出 (OOM) 可能会影响共享执行上下文,而一个 POD 中的繁重计算会抑制近邻 (“噪声近邻”效应) 。
除了时间片之外,NVIDIA 多进程服务 (MPS) 还提供了一种基于软件的替代方法。MPS 支持多个进程通过使用服务器 – 客户端架构同时共享 GPU 资源。这提供了比 MIG 更高的灵活性,并且与标准时间切片相比,对内存泄漏等某些问题的弹性更高。
但是,在生产环境中,这两种方法共享一个执行上下文,限制了隔离。虽然现代 MPS 提供了隔离的虚拟地址空间,但它缺乏硬件级的故障隔离。这意味着一个进程中致命的执行错误或非法的内存访问将在共享的上下文中传播,这可能会导致 GPU 重置,从而影响共享该卡的其他进程。
MIG:硬件分区方法
MIG 以物理方式将 GPU 划分为单独的实例,每个实例都有自己的专用内存、缓存和流式多处理器 (SM) 。对于操作系统和 Kubernetes 而言,它们看起来像是独立的 PCI 设备。
- 机制:硬件级隔离。
- 优点:严格的服务质量 (QoS) 。一个工作负载不会影响另一个工作负载的性能或内存稳定性。
- 缺点:尺寸固定。如果分区处于空闲状态,则相邻分区无法“借用”其计算资源。
虽然时间片具有灵活性,但对于需要严格的硬件级故障隔离以满足企业 SLA 要求的生产环境而言,MIG 是首选。硬件分区可确保一个模型中的内存错误不会导致共享 GPU 发生级联故障,这是任务关键型语音 AI 的关键要求。
实验性设置:语音 AI 工作流
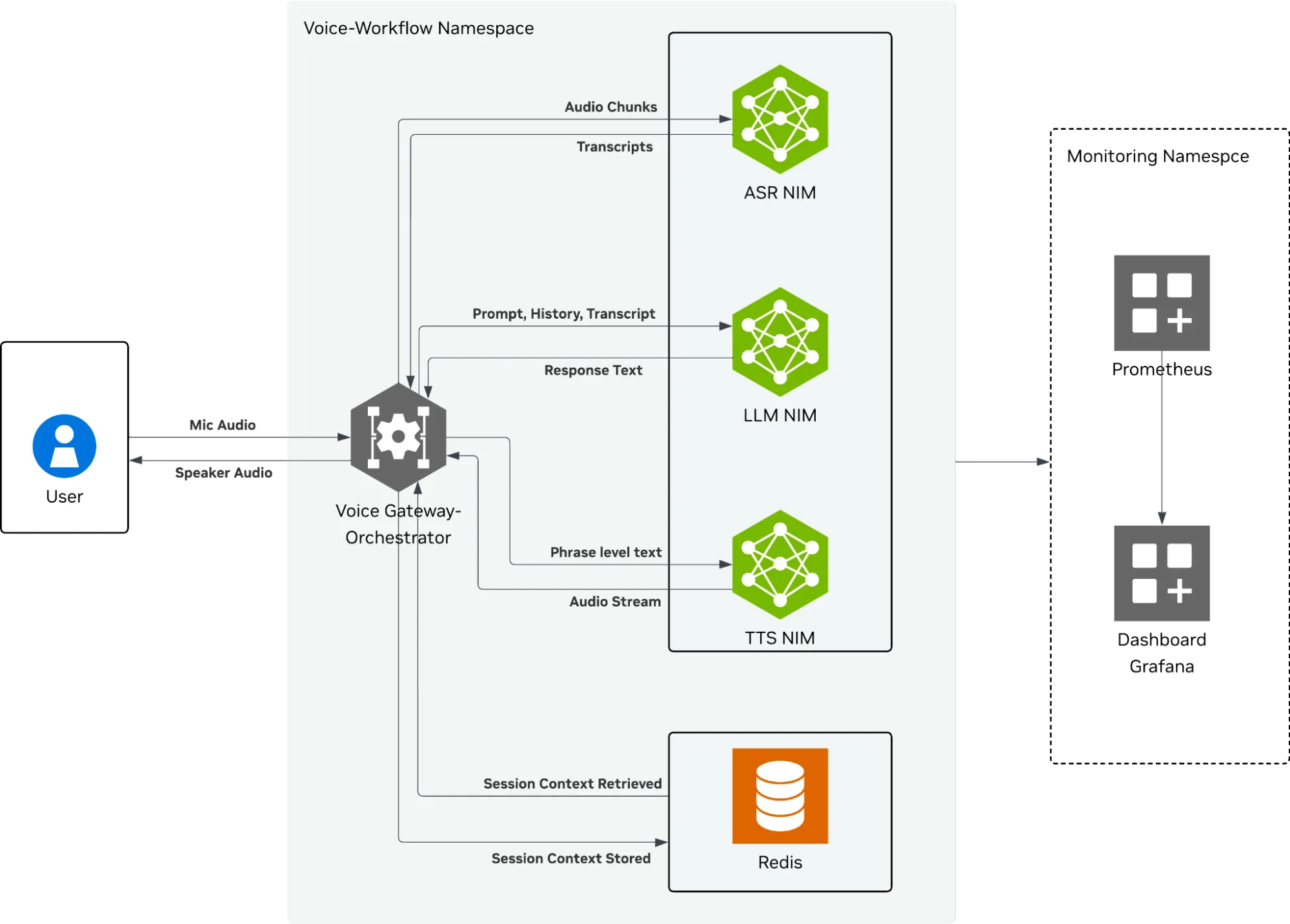
为了在逼真的生产场景中验证这些策略,我们使用了多模态语音到语音 AI 工作流。此工作负载非常适合进行基准测试,因为它混合了三种不同的流量模式:
- ASR (流式传输) :使用 NVIDIA Parakeet 1.1 B 持续进行低计算流处理
- TTS (突发) :借助 NVIDIA Magpie Multilingual,空闲几秒钟,然后峰值达到 100%,在几毫秒内生成音频
- LLM (重) :高计算、高内存占用,Llama-3.1-Nemotron-Nano-VL-8B-V1.
在优化之前,了解我们的延迟曲线至关重要。在我们的语音到语音工作流中,LLM 是主要的瓶颈。在重负载下,LLM 的总处理时间约为 9 秒。这种延迟可能会因上下文长度而大幅波动;例如,与简短的提示相比,高输入场景 (如训练用户) 或不断增长的对话历史记录会增加处理开销。随着历史记录的不断累积,LLM 在生成响应之前必须处理更多的词元,从而进一步扩大了必须屏蔽的支持模型的瓶颈。
整合 ASR 和 TTS 等支持模型提供了一条战略路径,可在保持端到端响应能力的同时更大限度地提高硬件利用率。虽然整合可能会引入 100-200 毫秒的轻微延迟调整,但基础设施吞吐量和投资回报率的提升是显著的。
我们的假设
将 ASR 和 TTS 工作负载整合到单个 GPU 上可保持延迟和抖动,同时为其他 LLM 实例释放计算能力。
实验

我们设计了三种不同的测试配置。在每一轮测试中,我们使用了三个语音样本,等待 LLM+ TTS 的第一个响应完成。该设置使用 Kubernetes 集群,模型使用 NVIDIA NIM 部署,并由 NVIDIA NIM Operator 管理。工作节点可以访问三个 NVIDIA A100 Tensor Core GPU。
- 实验 1:三个 GPU 的基准
- 设置:每个模型 ( LLM、ASR、TTS) 一个专用 GPU。
- 目标:建立延迟和吞吐量的“黄金标准”,并据此衡量优化效果。
- 资源:
nvidia.com/ gpu: 1各 pod。
- 实验 2:使用两个 GPU 进行时间切片
- LLM 会保留专用 GPU。ASR 和 TTS 使用软件级时间切片共享 GPU 0。
- 目标:测试动态调度是否能够处理串流 ASR 和突发 TTS 之间的“相邻噪声”冲突。
- 资源:
nvidia.com/gpu:1 (通过replicas: 2)
- 实验 3:使用两个 GPU 进行 MIG 分区
- LLM 会保留专用 GPU。GPU 0 在物理上分为两个独立的实例。
- 目标:测试硬件隔离是否提供比软件调度更好的稳定性。
- 资源:
nvidia.com/mig-3g.40gb: 1各 pod 。
配置说明:为实现这些拓扑,我们在 NVIDIA GPU Operator 中使用了特定配置。
- 对于“实验 2”,我们使用了
timeSlicing为每个物理 GPU 发布多个副本的配置。 - 在“实验 3 ( Experiment 3) ”中,我们应用了自定义
mig_configsConfigMap 将 GPU 分为两个部分3g.40 gb实例。
(为了准确kubectl用于重现此设置的命令和 YAML 清单,请参阅本文末尾的实现附录。)
结果
为评估资源碎片化,我们使用两种不同的流量模式对系统进行了测试:
- 轻负载:5 位并发用户模拟约 135 秒的持续交互。
- 重负载:50 位并发用户模拟约 375 秒的持续交互。
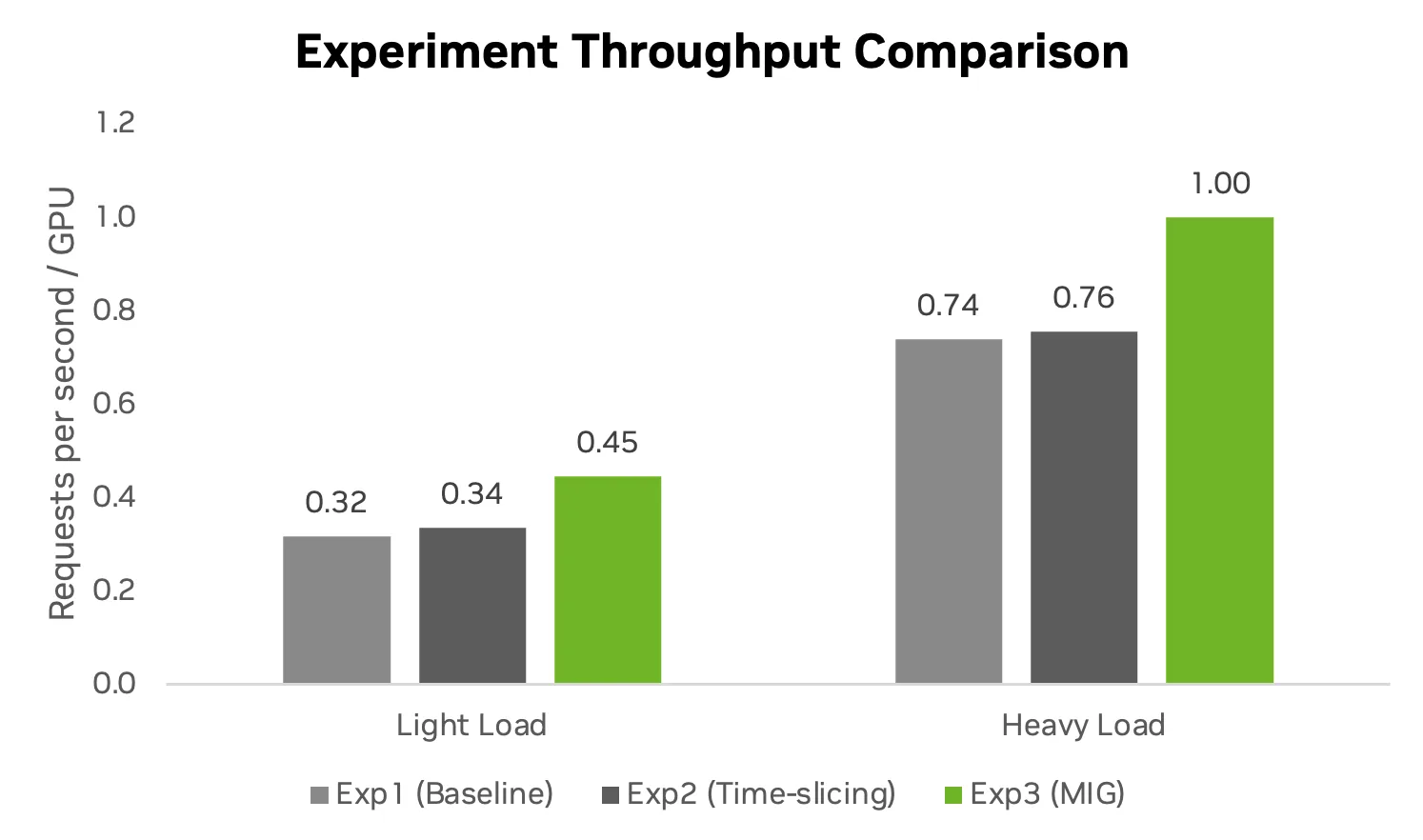
图 5 比较了不同流量模式下的生成式 AI 推理吞吐量。这些数据显示了在轻负载和重负载下,跨基准 (专用 GPU) 、时间片 (软件共享) 和 MIG (硬件分区) 分区会如何影响并发性增加时的进程请求。所有实验都有 100% 的成功率,没有失败。当前的 req/s 是导致工作流中 LLM 出现瓶颈的原因。
平均延迟指标
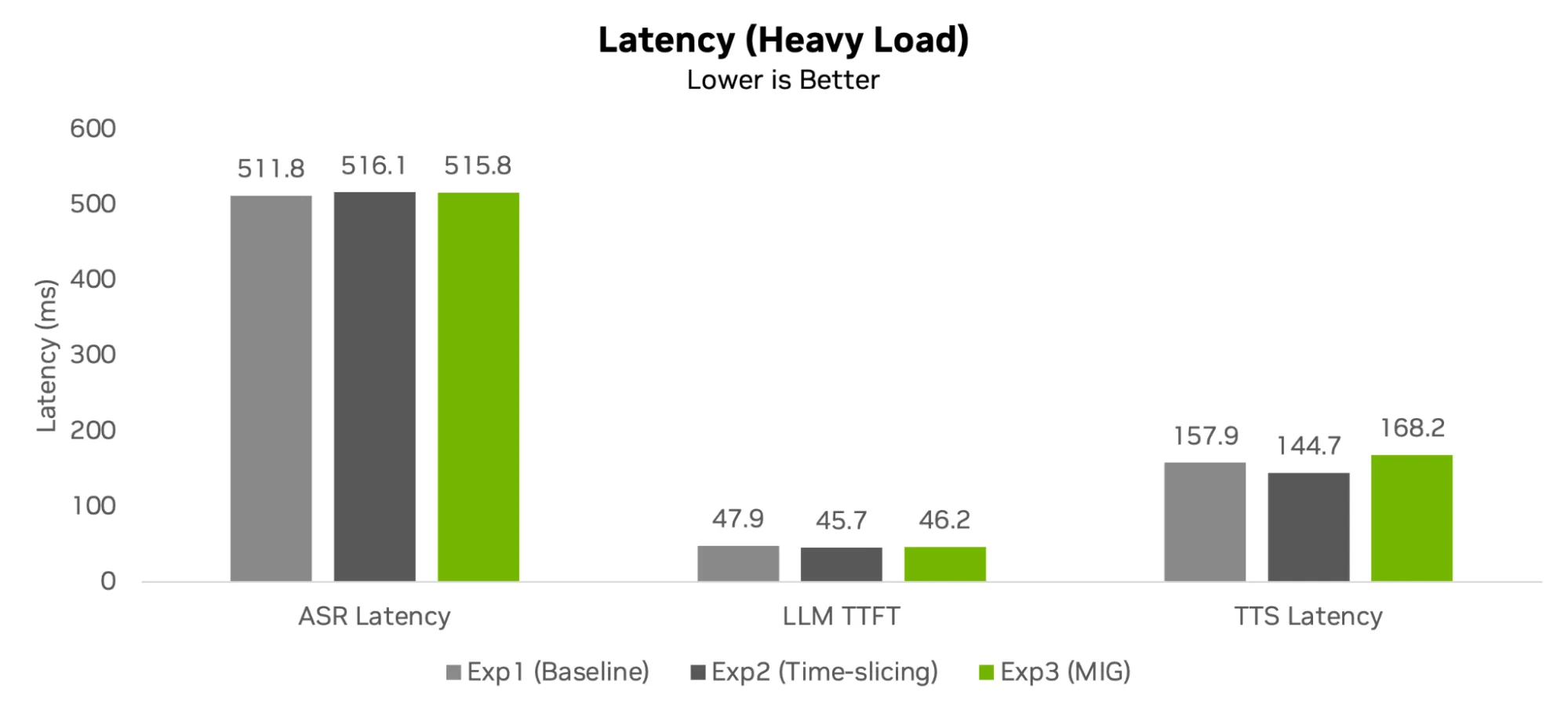
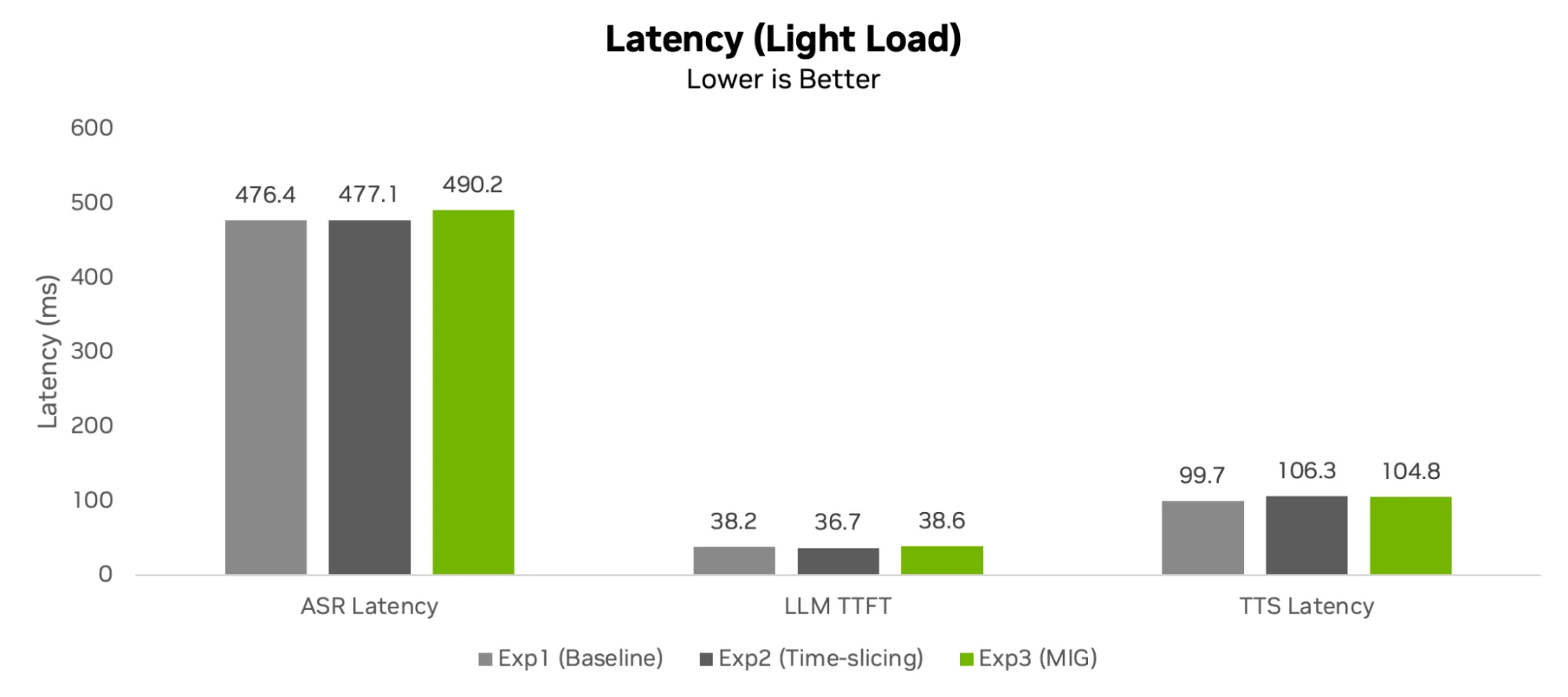
以下分析评估了不同的 GPU 分区策略如何影响整体系统效率和响应能力。
吞吐量与延迟对比
将 ASR 和 TTS 工作负载整合到单个 GPU 上可优化工作流,使集群能够支持更多同步 AI 流。但是,我们的基准测试表明,两种分区策略之间存在严重的性能差异:
- MIG (硬件) :更高的效率
实验 3 实现了最高的单位生产力,每个 GPU 达到约 1.00 req/s。通过为每个实例提供专用硬件路径,MIG 可消除资源争用。组织可以实现近乎完整的系统容量,同时有效释放整个 GPU 来处理其他繁重的 LLM 工作负载。
- 时间片划分 (软件) :密度更高且开销更高
实验 2 表明,与基准相比,软件级共享还可以提高每个 GPU 的密度,每个 GPU 的请求/ 秒约为 0.76。但是,CUDA 驱动程序管理流式传输和突发模型之间的快速上下文切换会产生调度用度。这种基于软件的方法虽然有效,但并没有达到硬件分区提供的总体吞吐量效率。
延迟和突发因素
时间片处理单个突发任务的速度略快,平均 TTS 延迟为 144.7 毫秒,而 MIG 延迟为 168.2 毫秒。但是,这种 23.5 毫秒的差异只占当前规模下端到端工作流响应时间总数的一小部分。在高负载下,LLM 占据了总交互时间的绝大部分。由于最终用户无法在多秒响应内感知 20 毫秒的增量,因此 MIG 的吞吐量稳定性是更有价值的生产指标。
分区建议
根据基准数据,我们推荐使用以下决策矩阵:
- 生产规模和稳定性默认为 MIG
- 实验 3 表明,MIG 只需稍微牺牲延迟,即可处理更高的请求量 ( 2 req/s) 。
- 严格的硬件级故障隔离可防止一个进程中的内存溢出导致另一个进程崩溃。
- 非常适合以吞吐量和 100% 可靠性为重点的生产环境。
- 将时间片用于开发应用或低并发应用
- 这包括将总吞吐量和共享资源依赖项减少 32%。
- 非常适合开发、CI/ CD 和 PoC,可在最小的硬件占用空间上运行完整的工作流。
开始使用
- 进一步试验:试用存储库。
- 实现分区:按照我们的实现指南配置 MIG 配置文件,并使用提供的 YAML 清单来消除集群中的资源碎片化。
- 借助 NIM 进行扩展:部署 NVIDIA NIM 工作流,充分利用 ASR、TTS 和 LLM 工作负载,实现更高的投资回报率。