
生成式 AI 具有爆炸性的第一章由发送请求的人类和响应的模型定义。代理式章节有所不同。
智能体不会遵循预先确定的动作序列。它们可以调用工具,生成具有不同任务和模型的子智能体,在内存中保留信息,管理自己的上下文窗口,并自行决定何时完成。在此过程中,这些系统将词元消耗量、上下文长度和延迟要求推向了极其严苛的区域,而这正是目前塑造 NVIDIA 极致协同设计堆栈和 NVIDIA Vera Rubin 平台的压力。
本文将从三个部分对这种演变进行分析:
- 智能体如何使用词元
- 为什么他们的经济在传统服务下崩溃
- 专为智能体构建的基础架构堆栈是什么
从聊天机器人过渡到智能体
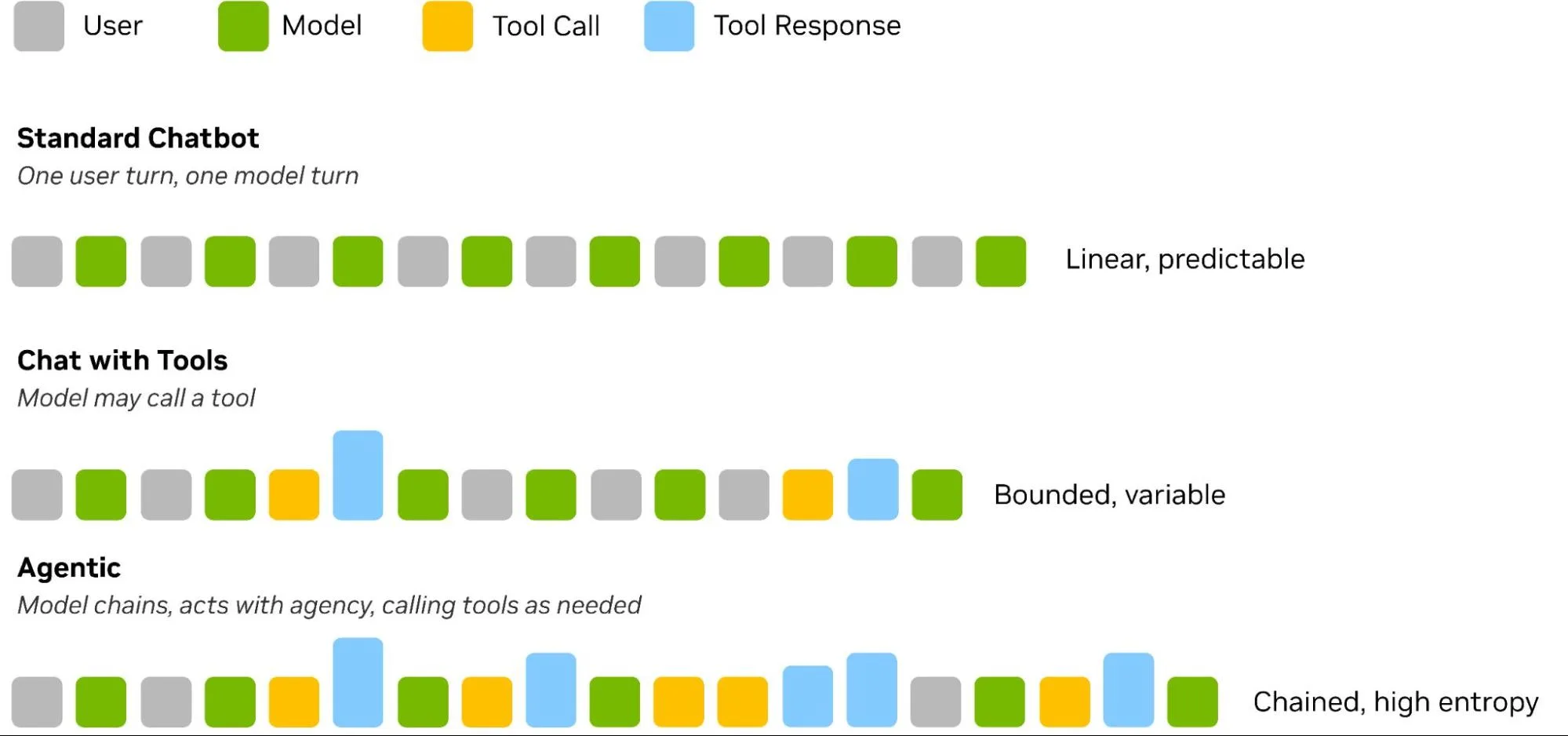
如下图 1 所示,生成式 AI 的普及始于一个简单的交互模型:一个用户消息,一个聊天机器人消息,重复。模型根据上下文窗口中的内存做出响应,聊天记录呈线性增长,并且对系统的需求是可预测的。
与工具聊天 (有界、可变) ;和代理式聊天 (链式、高)
工具调用的引入从根本上改变了 AI 聊天机器人的运作方式。一旦模型可以调用计算器而不是猜测数学运算,整个工作负载就会发生变化。由于工具响应直接添加到上下文窗口中,因此会给输入序列带来不可预测性。出现这种情况的原因是,工具输出的大小取决于特定查询和工具的设计,包括其处理相关数据的方式。即使这个过程仍然受到提示和最终答案的限制,标准聊天的简单可预测性也会丢失。
当我们引入智能体时,这种动态会变得更加复杂。如果模型能够调用某个工具,它也有权决定要使用的工具数量以及使用顺序。例如,负责起草电子邮件的智能体可能会:
- 读取现有的对应内容
- 查看驱动的上下文
- 确认收件人的身份
- 然后起草电子邮件
在这种链中,模型成为智能体,工作负载从“通过概率峰值线性预测”转变为“在结构上具有概率”,这样每个智能体会话的行为方式可能截然不同。
代理式架构的特征
现代代理式架构混合了智能体层次结构和优化技术,可实现有效的上下文管理、工具使用和任务优化:
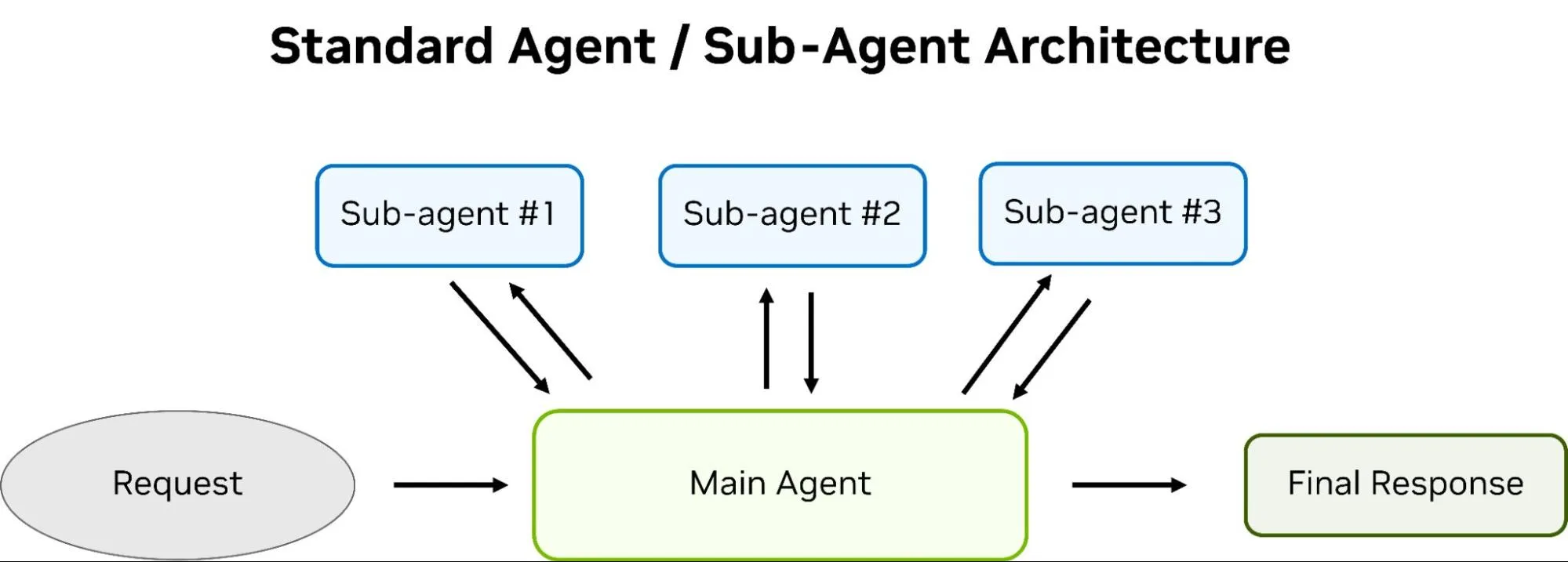
- 主代理:负责整个任务的端到端交付。可以编排处理子任务的子智能体。通常,主智能体由最智能的模型提供支持,并直接与用户对话。
- 子代理:由主代理创建,用于处理更具体、范围更窄的任务,能够像主代理一样自主管理上下文窗口。通常情况下,子代理在架构上与主代理相同或高度相似,区别仅在于主代理分配给子代理的任务提示范围更为有限。
- 文件系统状态:额外的状态来自代理将内存和工具调用输出写入文件,然后搜索或重新读取其内容。这是一种上下文管理和记忆方法。
- 总结和规整: 一种对智能体的上下文窗口进行总结和压缩的技术,可为新信息腾出空间并降低输入处理成本。
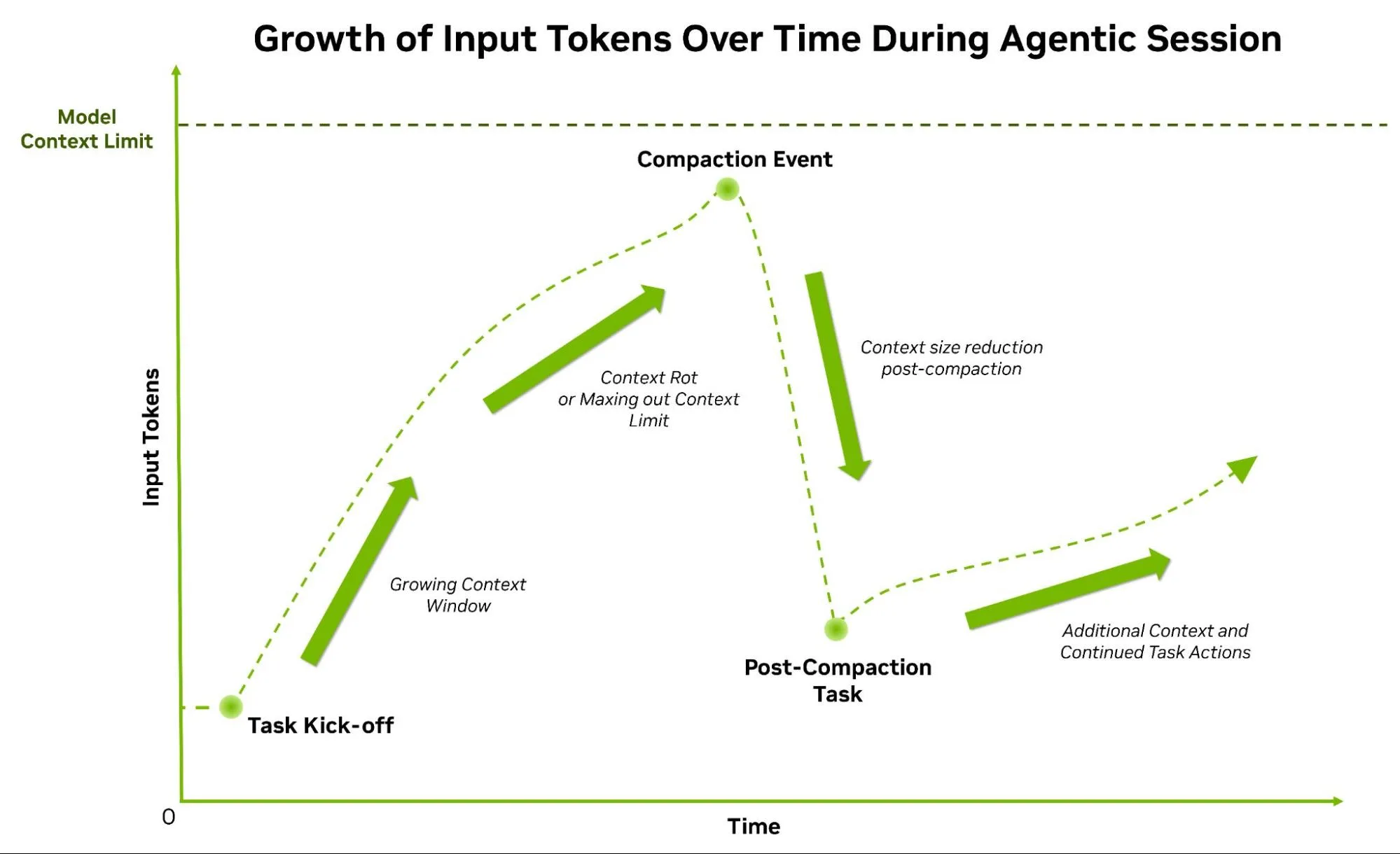
如今一些最热门的代理式工具也采用了类似的架构。例如,像 Cloud Code 这类工具中的主智能体会经常将任务分配给子智能体,以利用更小的上下文窗口并实现任务的并行处理。由于系统在每个推理步骤中都必须处理输入词元,使用较小的上下文窗口有助于提升效率,并降低处理输入词元的成本。这种架构还能有效应对一种被称为情境恶化的现象——即随着上下文不断扩展,输出质量会不可避免地下降。当任务变得复杂时,系统会主动触发规整机制,迅速缩小主代理的上下文窗口,以弥补词元无法无限扩展的限制。
代理式系统的工作负载动态和经济性
在关于构建多智能体系统的报告中,Anthropic 估计,与标准聊天系统相比,这些系统的能耗最高可达每词元的 15 倍。如此显著的增长意味着必须提升每词元的经济效益,才能实现这些应用的大规模经济可行性。应对这一推理成本挑战,需要深入理解影响代理经济的系统级词元吞吐量和延迟需求。
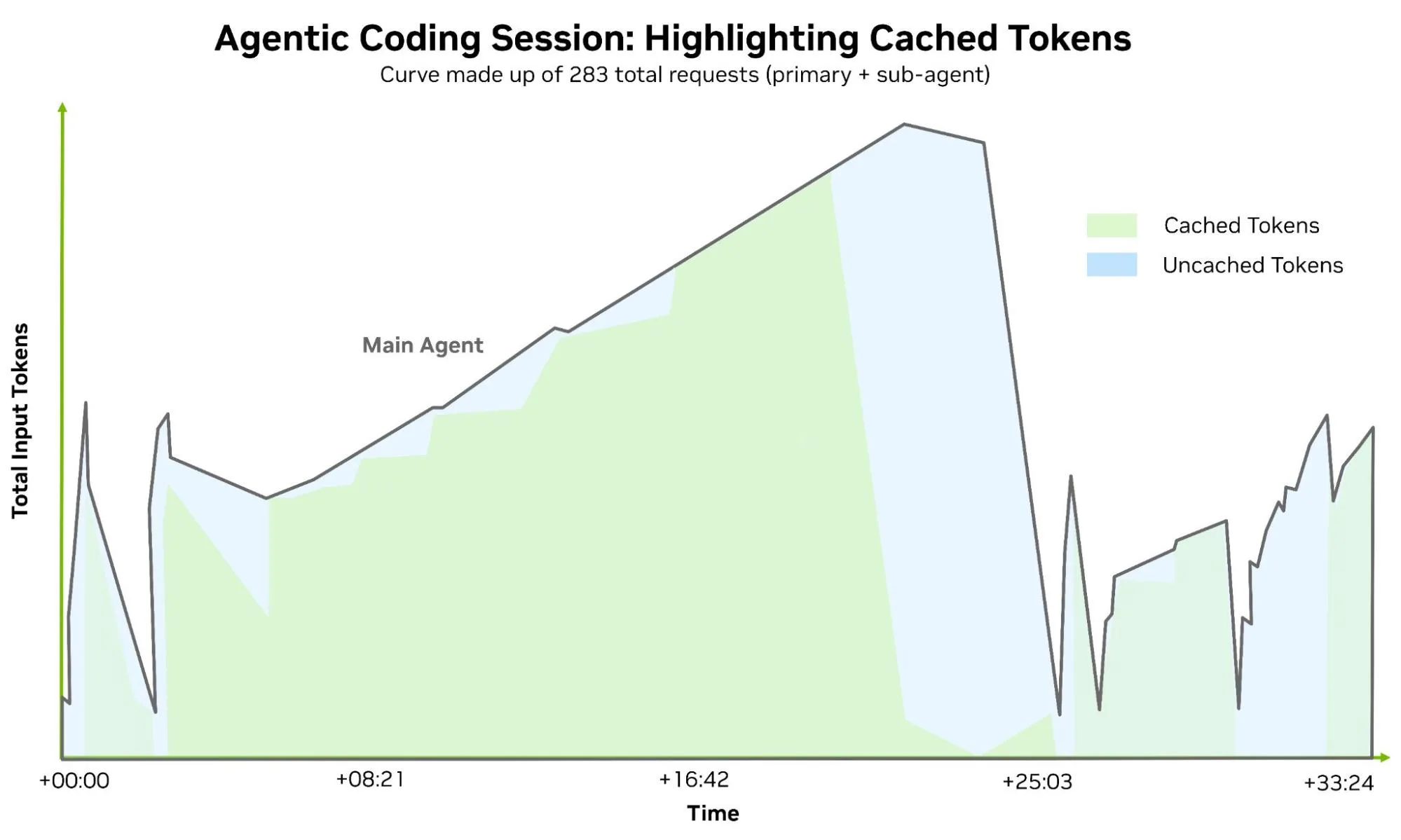
通过分析真实的代理式会话,可以更好地了解这些工作负载的成本和复杂性。图 4 提供了克劳德代码编码任务的测量示例。图表上的行表示子代理 (橙色) 和主代理 (灰色) 在会话期间发出的每个请求的输入序列长度 (上下文+ ISL) 。即使在单个会话中,追踪也能明确说明长上下文能力、缓存可编程性和可预测的 per-词元延迟为何与原始模型质量一样重要。
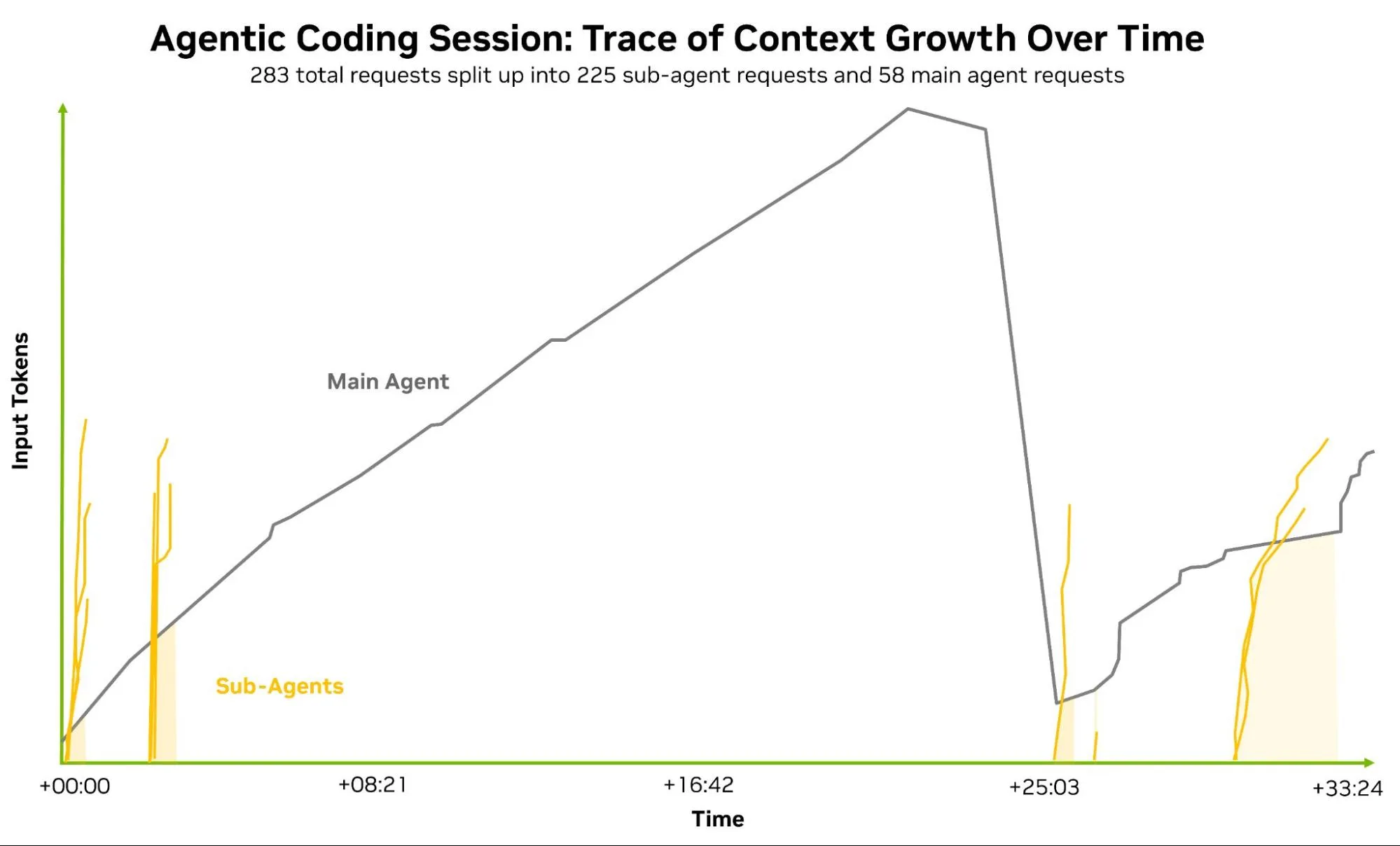
此会议时长 33 分钟,跟踪 58 次主代理轮次协调 225 次子代理调用。在处理 283 个推理请求时,上下文窗口从 1.5 万个词元增长到峰值 1.56 万个,然后上下文压缩事件将其减少到约 2 万个。该追踪清楚地表明,代理词元的消耗既受代理式系统行为的影响,也受任务性质的影响。
在不委托或压缩上下文的情况下,主代理会快速累积输入上下文,这会导致缓存读取的输入词元成本在每次回合中反复出现。在前 40 个回合中,主智能体的上下文平均值约为 85,000 词元,总共处理了约 3.5 万个输入词元,然后在规整后的会话中再增加 100 万个。这些正是高带宽显存 (HBM) 、高吞吐量平台 (例如 Vera Rubin NVL72) 变得相关的条件,因为长上下文提示需要保持经济可控性,而预填充需求继续扩大。
提示缓存使这种模式可行。如果不重复使用 KV 缓存,则每个输入词元都需要完全重新处理。热门 API 提供商将缓存命中率降低了约 90%,因此在 95% 的缓存命中率下,输入处理成本降低了约 85%;如果没有提示缓存,成本将高出约 6 倍。编码代理通常可维持 95-98% 的缓存命中率,尤其是在工具输出保持较小的情况下。这就是提示缓存日益成为系统问题而不仅仅是 API 功能的原因:保持高缓存命中率取决于高效的 CPU 端 KV 缓存管理和专用的大容量上下文存储 (例如 NVIDIA CMX) ,以保留长前缀,并随着会话规模的扩大而快速恢复。
子代理追踪中的 225 个请求突出显示了单独的推理会话,每个会话都利用独特的上下文和特定的工具定义。子代理通常会增加词元的总输出量,但它们从新的上下文窗口开始,仅继续推进与委托任务相关的内容,从而降低输入成本。它们还可以在较小的模型上运行,从而降低延迟和成本,同时仍能在较小的任务中保持准确性。
上下文压缩同样重要。它提供了一种避免达到上下文窗口限制的机制,减少了上下文腐蚀的影响,并提供了成本管理副作用。将上下文窗口从 156K 词元缩小到 2 万,强制立即减少缓存输入词元支出,并为下一组任务创造空间。
在下面的图 5 中,可以定性地看出,大多数处理过的词元都是从缓存中检索的。一旦发生这种情况,网络和内存系统行为开始直接影响用户感知的延迟,而 NVLink 6、ConnectX-9、BlueField-4 和 Spectrum-X 等低延迟结构有助于保持共享上下文的可访问性,并在多个智能体之间扇出会话时减少重新计算的损失。
从本示例中可以明显看出,智能体词元动态非常复杂,而且词元的消耗可以在主要智能体和子智能体之间快速扩展。为了了解在这种不断增长的词元需求下扩展这些应用程序所面临的挑战,我们必须考虑所提供的性能要求。
代理式工作负载的性能要求
释放智能体工作负载的价值需要高模型智能、大背景和低延迟。这些智能体产生见解的速度越快,它们的价值就越高。这种速度缩短了研发周期,改善了线束控制,并实现了复杂的多智能体循环。由于支持这些功能的词元的处理成本本身就很高,因此所提供的性能是使这些系统具有可扩展性和盈利能力的关键手段。
为了降低这些词元的成本,生产商需要在高交互性区域保持大型模型在大型环境中的规模。下面的图 6 通过标准推理性能并行说明了这一瓶颈。曲线的左侧提供高吞吐量,但在交互性的较低极端情况下,智能体工作负载无法正常运行。
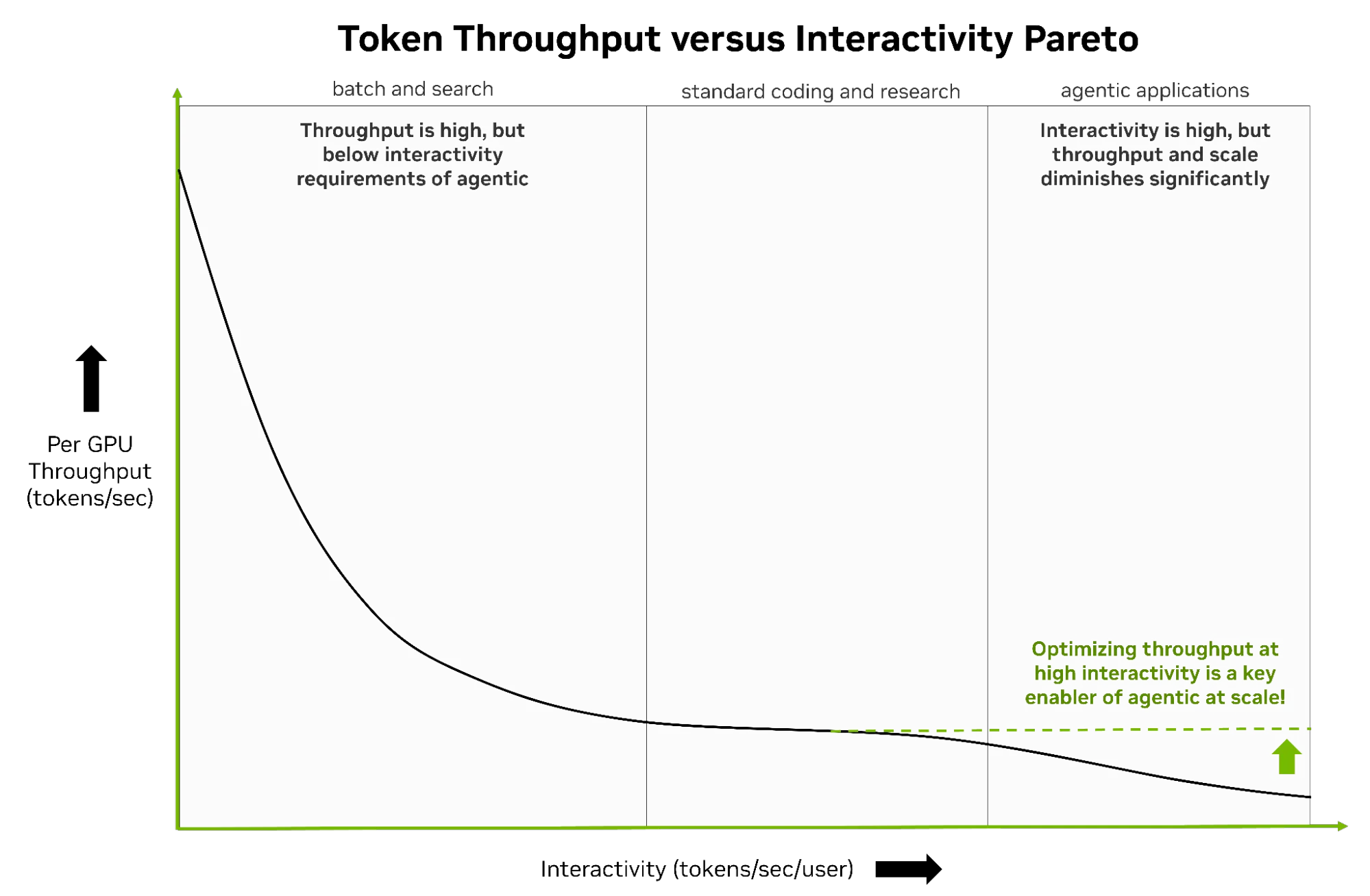
相反,这些工作负载必须转移到曲线的高交互性侧 (右) 才能成功运行。代理式系统需要消耗大量的词元数据,同时需要快速生成以保持最终用户交互性。问题在于,实现这种低延迟通常会导致系统吞吐量大幅下降。吞吐量下降导致每词元的成本高得令人望而却步,这使得代理式系统在大规模部署时面临经济挑战。
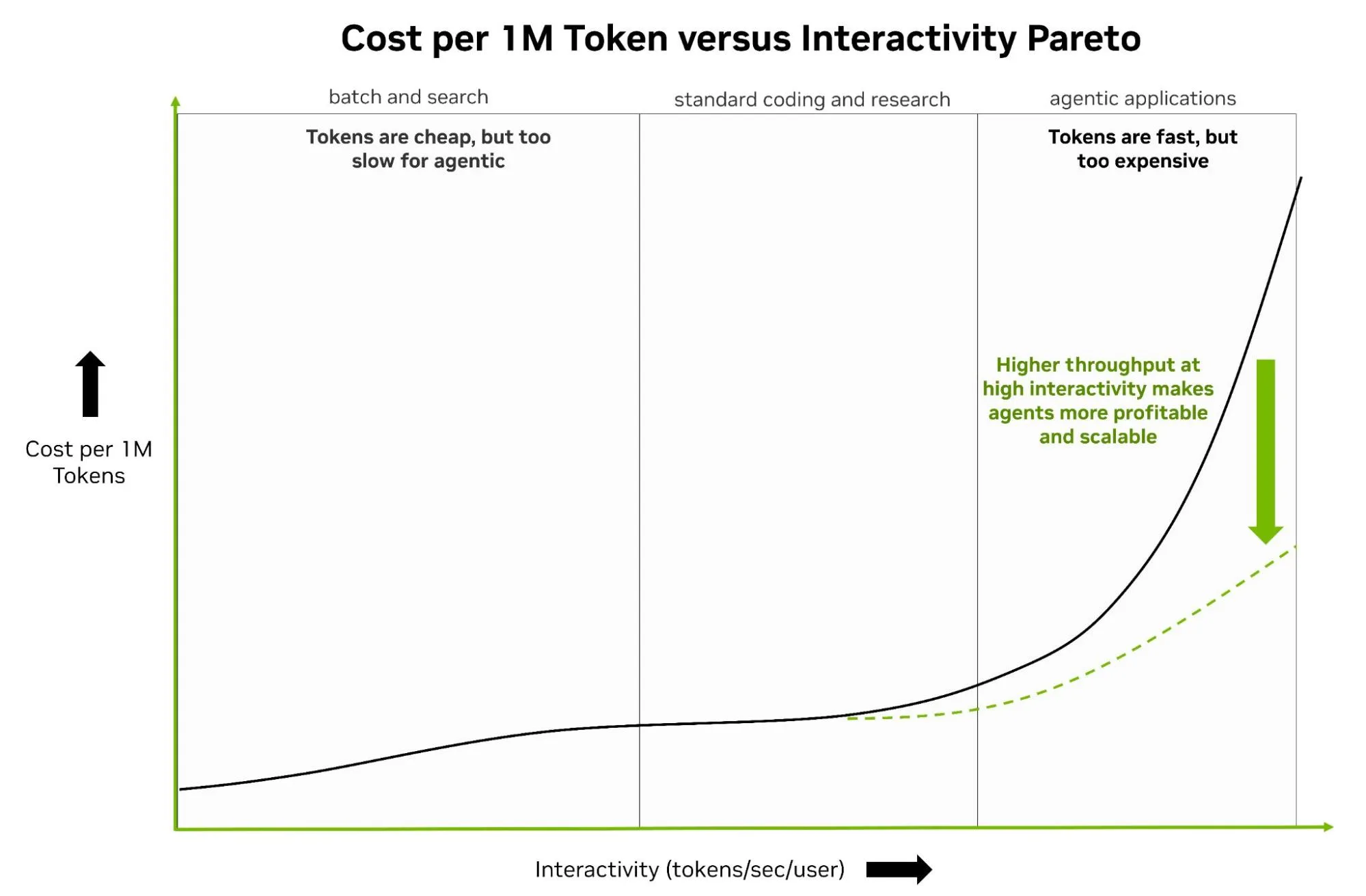
打破这一瓶颈需要彻底转变基础架构设计。现代 GPU 可提供庞大的计算能力和充足的带宽,但在低延迟下维持规模所需的性能远超任何单一架构。答案是极致协同设计。这种方法优化了每个阶段专用硬件的推理,并将这些独特的挑战委托给整个平台,而不仅仅是一个处理器。
为什么单颗处理器还不够
仅仅增加更多的计算浮点运算能力和内存容量无法满足这些独特的需求。这些需求源于智能体工作方式的架构特性,没有任何单一处理器能够同时解决这些问题。
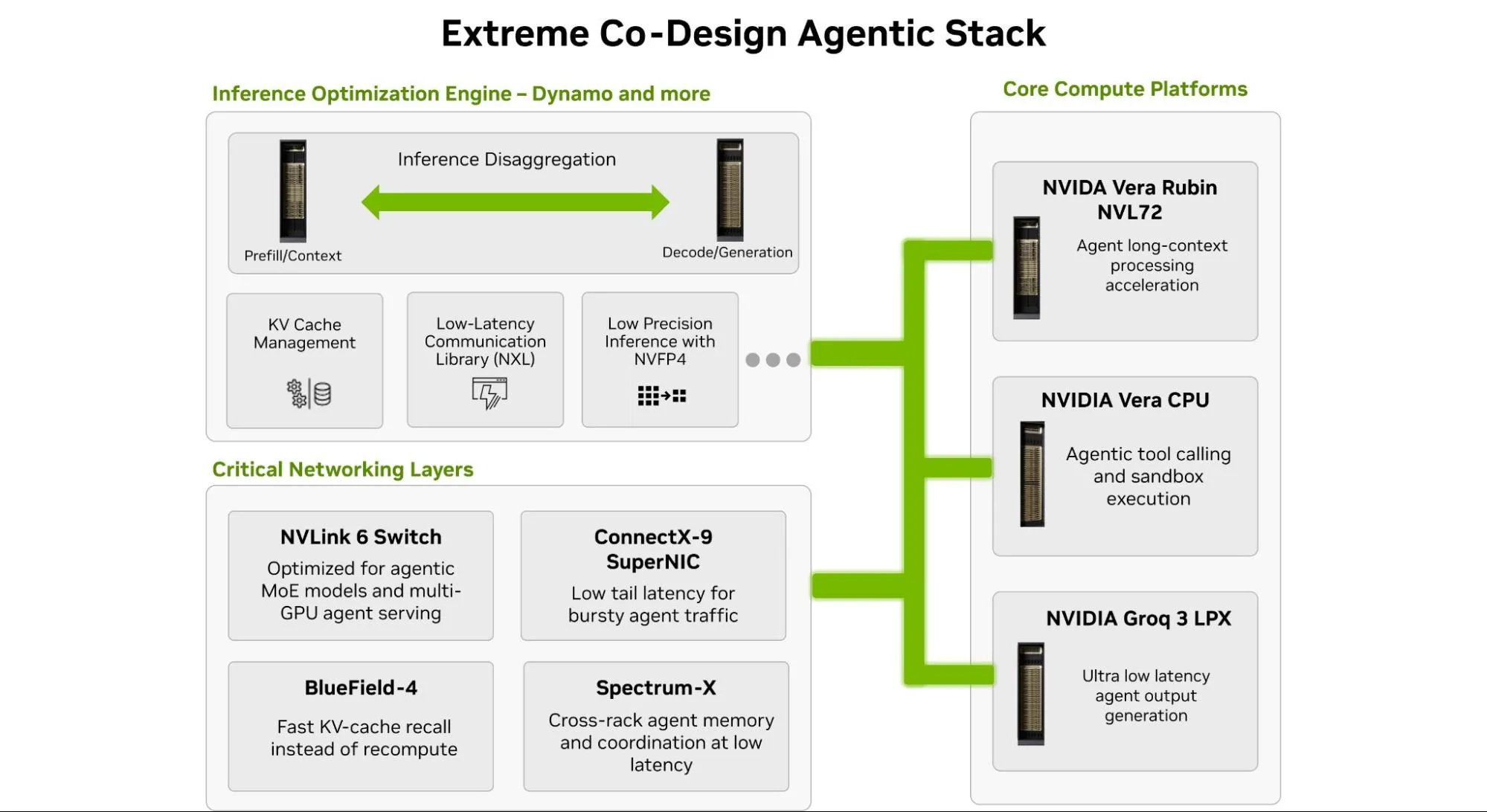
我们需要一个平台,将每个瓶颈映射到专用硬件,并将其编排为具有极端协同设计的统一系统 (请参见上图 8) :
- 平台
- Vera Rubin NVL72 的处理容量和计算成本仅为 Blackwell 每百万词元的十分之一。大容量 HBM 让长上下文工作流更易处理,高计算密度可大规模分摊预填充成本。
- Vera CPU 通过更低的代理延迟、无缝的 KV 缓存卸载以及统一的 CPU-GPU 执行,弥补了工具执行中的关键空白。
- Groq 3 LPX 打破了吞吐量与延迟之间的权衡。其以 SRAM 为核心的架构可实现边界紧凑、低抖动的词元生成,这在单个智能体中的微小方差会随工作流传播时尤为关键。
- 网络芯片(NVLink 6 Switch、ConnectX-9 SuperNIC、BlueField-4 DPU 和 Spectrum-X 以太网) 为代理类工作负载构建了统一的低延迟服务架构,使智能体能够更快协调、维持可访问的共享上下文,并避免随着会话延长而产生的高昂重新计算成本。
- 软件堆栈组件:
- Dynamo and Attention-FFN Disaggregation (AFD) 通过将任务分配至最合适的处理器并协调执行,减少资源争用和延迟,从而构建稳定一致的服务路径。同时,Dynamo 还为智能体线束提供缓存可编程能力。
- NVFP4 可降低精度带来的开销,使 MoE 代理在不损失智能水平的前提下,实现更低延迟、更高吞吐量和更小内存压力的运行。
- TRT-LLM WideEP 针对前沿的 MoE 架构优化了大规模专家并行,使智能体能够以更低延迟和更高吞吐量提供高智能响应。
- Speculative Decoding 通过并行生成候选词元并快速验证,有效降低智能体的响应延迟,加速大模型的低延迟推理。
通过极端协同设计将这七个芯片和一个软件堆栈相结合,Vera Rubin 平台可以在具有 40 万个大背景的万亿参数 MoE 模型上为每位用户提供每秒 400+ 词元的性能。这种性能水平改变了智能体的历史权衡范式,您不再需要为了提供高的每个用户速度和高系统吞吐量而牺牲较小的模型和有限的上下文窗口的质量。在该地区,代理式架构不再是昂贵的实验,而是成为规模化的可行产品。
有关 Vera Rubin 平台规格和 LPX 的更多详细信息,请查看其各自的发布日博客: