
大型 GPU 集群的计算能力带来了前所未有的创新机会,并在创纪录的时间内为客户提供价值。然而,这些进步带来了各种挑战。在规模化方面,团队需要应对异构硬件、快速移动的软件堆栈、强大的计算能力以及庞大的多租户工作负载。单个热点、错误配置的驱动程序或细微的硬件故障都可能造成连锁反应,导致作业受限、错过服务水平协议 (SLA) 和浪费支出。
此外,大规模集群中涉及的组件的复杂性和数量可能令人望而生畏,因此保持对日常运营的可见性并了解任何特定时间的运营状态至关重要。在作业执行期间监控 GPU 利用率和识别瓶颈变得更加困难。确定利用率低的区域并将工作负载迁移到这些区域是确保获得高投资回报的最佳方式之一。
出于这些原因,GPU 感知监控对于大规模部署至关重要。除了节点是否启动之外,团队还需要可见性。他们需要知道每个加速器在任何特定时刻是否都能安全、稳定地按预期运行。
本文将介绍现已全面推出的 NVIDIA Fleet Intelligence,这是一项基于智能体的托管服务,可对 NVIDIA 数据中心 GPU 进行持续监控。
GPU 监控的重点关注领域是什么?
GPU 监控的重要领域包括功耗、温度、性能、运行状况和统一配置。
- 功耗: 跟踪功耗和节流情况,以保持在数据中心预算范围内,同时更大限度地提高每瓦性能。
- 温度: 尽早检测到热点和气流问题,以避免热节流和组件过早老化。
- 性能: 观看利用率、内存带宽、互连运行状况和节流原因,以发现整个集群中的回归和不平衡。
- 运行状况: 通过监控表面ECC和XID错误、坏页、HBM/NVLink/PCIe异常以及其他RAS信号,可在故障部件失效前及时发现潜在问题。
- 统一配置和完整性:在进行GPU库存验证时,需检查驱动程序、固件和BIOS设置的一致性,以确保结果可复现、操作安全,并验证固件的完整性。
什么是 NVIDIA Fleet Intelligence?
NVIDIA Fleet Intelligence 是一种与部署无关的低级托管服务,无论选择何种软件堆栈或调度程序,均可使用。首先,该服务支持管理自己基础设施的数据中心 GPU 和 CPU 客户,以及需要更深入地了解 GPU 和 CPU 行为的工程师。
该服务依托NVIDIA产品组合中的技术与知识产权,并结合在NVIDIA DGX云上运行由数十万个GPU组成的NVIDIA集群的丰富经验。
Fleet Intelligence 通过占用资源少、基于主机的智能体,将 GPU 遥测数据流式传输至完全托管的 Fleet Intelligence 云服务。NVIDIA 以开源形式发布 Fleet Intelligence 智能体,确保其可审计性。该智能体利用其他 NVIDIA 开源解决方案,例如 GPUd、NVIDIA 数据中心 GPU 管理器(DCGM),和 NVIDIA 远程认证 SDK。欲了解更多信息,请访问 NVIDIA/Fleet-intelligence-agent on GitHub。Fleet Intelligence 是根据包括 NVIDIA 云合作伙伴(NCP)、Lambda 和 IREN 在内的早期体验(EA)客户的反馈开发而成。
此通用版本主要关注三个方面:
- 清单和可视化
- 报告、警报和运行状况检查
- 完整性和认证
清单和可视化
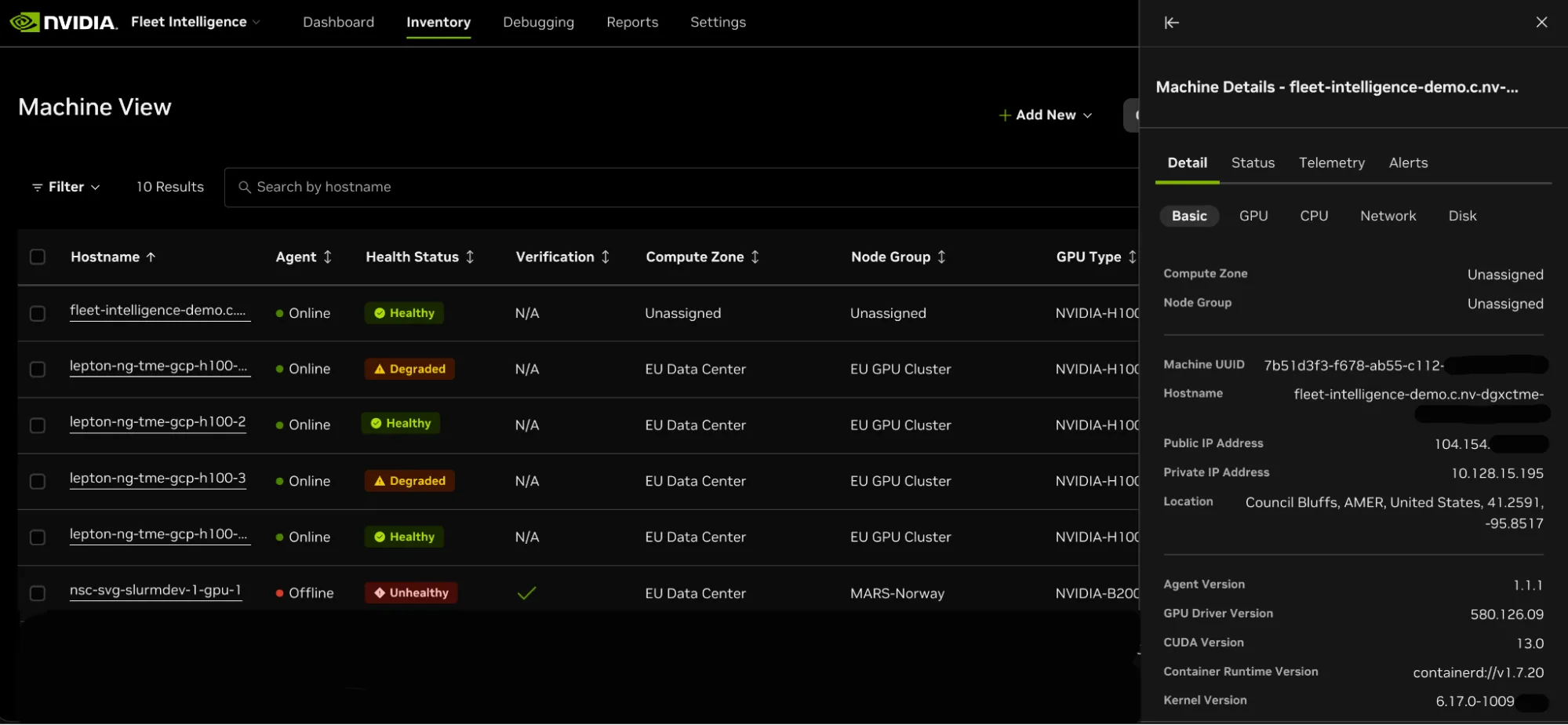
Fleet Intelligence 提供了一项丰富的功能,可跨数据中心和云可视化全球车队库存。通过 Linux 软件包管理器或 GPU 工作节点上的 Helm install 安装占用空间最小的代理。
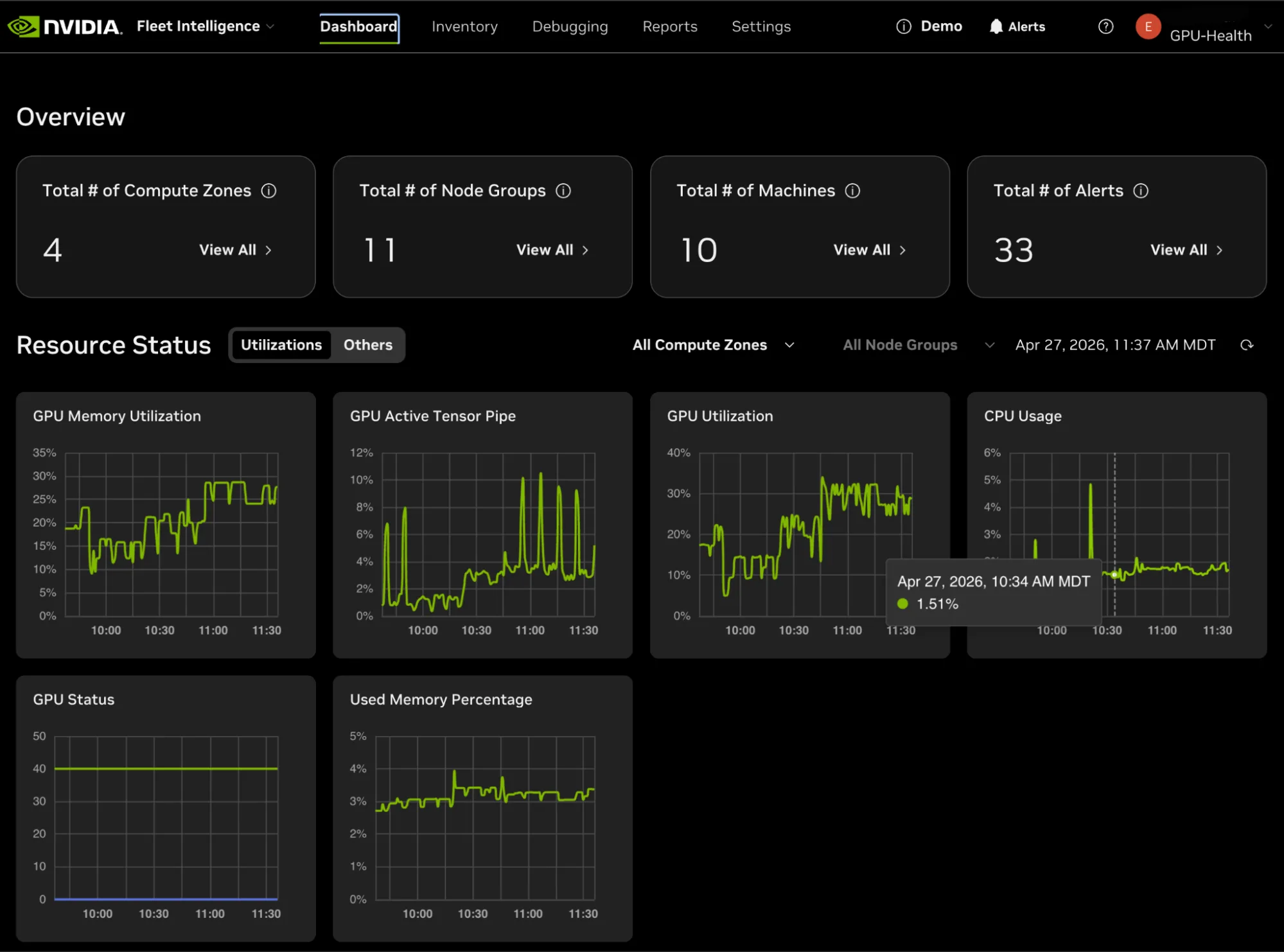
注册后,智能体将采集节点级别的信息,并显示在 NVIDIA NGC 的 Health 门户中。作为用户,您可在全球范围或按计算区域(包含在同一物理位置或云位置注册的节点组)查看 GPU 集群的利用率。
在基础设施的任何级别,都会立即出现异常情况,例如,由功耗或温度跨越的错误或值。这使得用户能够直接查看有关触发警报的原因的详细信息。
报告、警报和运行状况检查
Fleet Intelligence 智能体采用 GPUd 和 DCGM 技术,分析这两种工具提供的指标,并将结果反馈给医疗健康服务部门进行审核。该智能体使 Fleet Intelligence 能够近乎实时地监控车队运行状态,并执行定期健康检查。同时,它收集来自主机、GPU、NVLink,和网络的遥测数据,全面掌握整个系统的运行状况。
在收集信号时,该服务会根据当前状态和历史对错误进行分析,以提供补救措施建议。该代理是只读的,不会修改主机配置,并且只收集机器遥测和状态数据。要验证所收集的数据,您可以在本地编写示例输出,或查看公共存储库中的源代码。
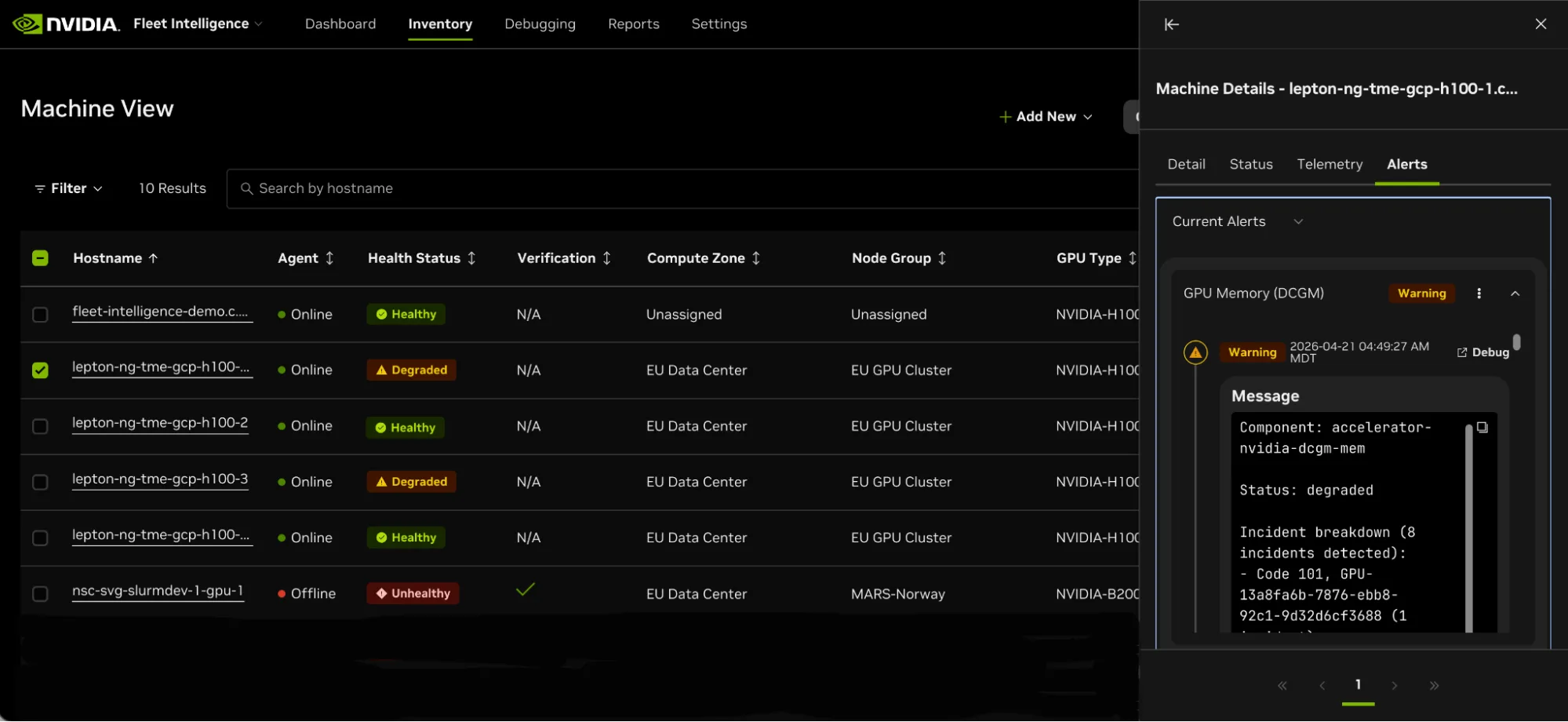
您还可以选择在发生错误或故障时通过电子邮件、Slack 和其他渠道接收警报消息,并针对低利用率值或其他相关领域配置自定义警报。用户可以配置报告,以查看功耗、温度趋势、错误和停机时间的库存和历史图表。
Fleet Intelligence 智能体采用被动运行状况检查和定期检查。这些运行状况检查已通过 DCGM 和 GPUd 提供。根据车队运营经验创建的新健康检查会在可用时添加。Fleet Intelligence 将不断收集匿名信号和其他元数据,以了解整个安装群体的故障和错误。这种方法可以提高数据的保真度,以应用于未来版本中提供的预测性故障分类模型。
完整性和认证
Fleet Intelligence 利用 NVIDIA 机密计算 解决方案中的技术,通过加密方式验证 GPU 的完整性,确保系统的真實性和可信度。Fleet Intelligence 智能体在运行时使用 Attestation SDK 从 GPU(或称为“证据”)获取测量数据,并利用基于 NVIDIA 信任根的本地证书对这些数据进行数字签名。
然后,证据会通过安全通道发送至 NVIDIA 远程认证服务(NRAS) 进行验证。NRAS 服务会使用 NVIDIA 参考完整性清单(RIM),该清单是在 vBIOS 构建过程中生成的结构。NRAS 服务将验证证据是否符合预期值,并将通过或失败的结果返回给 Fleet Intelligence 服务。
然后,您可以查看库存控制面板,并查看日常运行或按需运行的完整性检查结果。这些完整性检查可确保车队中的每个 GPU 都拥有已知的良好配置,这些配置不受篡改并保持最新状态。您还可以创建 Fleet Intelligence 报告,详细了解 GPU Fleet 信息以及当前的完整性状态。您可以下载这些报告并与其他报告工具一起使用。
Lambda 首席科学官 Chuan Li 表示:“NVIDIA Fleet Intelligence 以极简的配置,为 Lambda 研究团队提供了覆盖整个 NVIDIA Blackwell/Hopper GPU 集群的端到端可视性。其告警功能可捕捉主动故障和早期预警信号,报告则将整个集群的运行状态转化为可操作的洞察。”
开始使用 NVIDIA Fleet Intelligence
NVIDIA Fleet Intelligence 服务可提供有关 NVIDIA GPU 和 CPU 集群的功率、温度、性能、运行状况和配置的全面见解,确保每个芯片都能以最佳效率和可靠性运行。通过集成用于实时遥测的低占用空间智能体,结合强大的可视化和警报机制,企业能够更大限度地提高投资回报率并保持最佳运营标准。
开源的 Fleet Intelligence 智能体与先进的完整性和认证技术相结合,体现了 NVIDIA 对透明性和安全性的承诺。随着企业不断扩大 GPU 和 CPU 的部署,Fleet Intelligence 提供了应对现代数据中心复杂性所必需的工具,确保在各种环境中实现可持续且可预测的性能。
申请访问 NVIDIA Fleet Intelligence,亲身体验其如何提升 GPU 集群的可用性与完整性。目前,NVIDIA 数据中心 GPU 的所有者、运营商及云租户均可免费使用该平台。Fleet Intelligence 支持基于 Vera Rubin、Blackwell 和 Hopper 架构的 NVIDIA 数据中心级 GPU,但认证功能仅限于 Vera Rubin 和 Blackwell 架构。