
从训练好的AI模型到投入生产的路径本应顺畅,但实际情况往往并非如此。许多团队花费数周时间对模型进行微调,却最终发现导出为部署格式时会破坏网络层,输入形状可能导致运行时错误,或版本不匹配会悄无声息地影响性能。这些问题统称为管道摩擦,会给企业带来时间、资金和竞争优势上的损失。
本文提供了切实可行的最佳实践,以消除 AI 模型服务流程中最常见的摩擦源。结果十分具体:API 在实际流量下的响应速度更快。每个 GPU 都会执行更多请求。在高峰时段扩大规模是一项平稳、低压力的工作。每次推理的成本有所下降。部署本身不再是每个发布中断的一部分。
AI 模型中的工作流摩擦服务于什么?
工作流摩擦是指减缓或中断模型从训练到生产推理过程的任何障碍。与会产生明显错误消息的错误不同,摩擦通常表现为细微的低效:例如,模型消耗的 GPU 显存是预期的两倍,推理服务器在负载下丢弃请求,或者在一个 GPU 架构上运行但在另一个 GPU 架构上失败的部署。
最常见的管道摩擦源可分为四类:
- 模型导出问题:当从 PyTorch 或 TensorFlow 等训练框架转换为优化的推理格式时,就会出现这些问题
- 不支持的操作: 目标运行时无法识别自定义层或最近引入的层
- 动态输入大小: 导致形状不匹配或强制进行不必要的重新编译
- 版本不匹配: 库、驱动程序和硬件之间的不匹配会导致无提示故障或性能回归
每个类别都需要特定的工具和技术。成熟的解决方案生态系统已经存在,系统地应用这些解决方案可以在投入生产之前消除绝大多数摩擦。以下各节将详细介绍每个类别,以及更多减少管道摩擦的方法。
如何解决模型导出问题
大多数团队在 PyTorch 或 TensorFlow 中训练模型,然后将其导出为 ONNX 中间表示,再使用 NVIDIA TensorRT 进行优化。但在转换过程中常遇到诸多问题:动态控制流不被支持、某些操作缺少对应的 ONNX 实现,以及训练框架生成的张量形状与导出工具所期望的形状不匹配。
最佳实践 1: 尽早并频繁验证导出结果。将导出验证集成到 CI/CD 工作流中,对每个模型检查点执行可导出性测试。这种方法能在有问题的架构决策固化到代码库前及时发现并处理。
最佳实践 2: 有意识地管理 ONNX 算子集 的版本。ONNX 支持多个算子集版本,较新的版本虽然提供更多算子支持,但可能与较旧的运行时不兼容。应明确指定并锁定算子集版本,并记录选择该版本的原因。在升级时,需针对目标推理运行时进行全面测试。
最佳实践 3: 导出前简化模型结构。移除仅用于训练的组件,例如丢弃层、辅助损失头和调试钩子。通过图优化流程合并批量归一化操作,并剔除冗余运算。更简洁的图结构可提升导出稳定性,并加快运行速度。
TensorRT 提供内置图形优化,可自动处理其中许多转换、融合层、为特定 GPU 选择最佳内核,并消除不必要的内存复制。
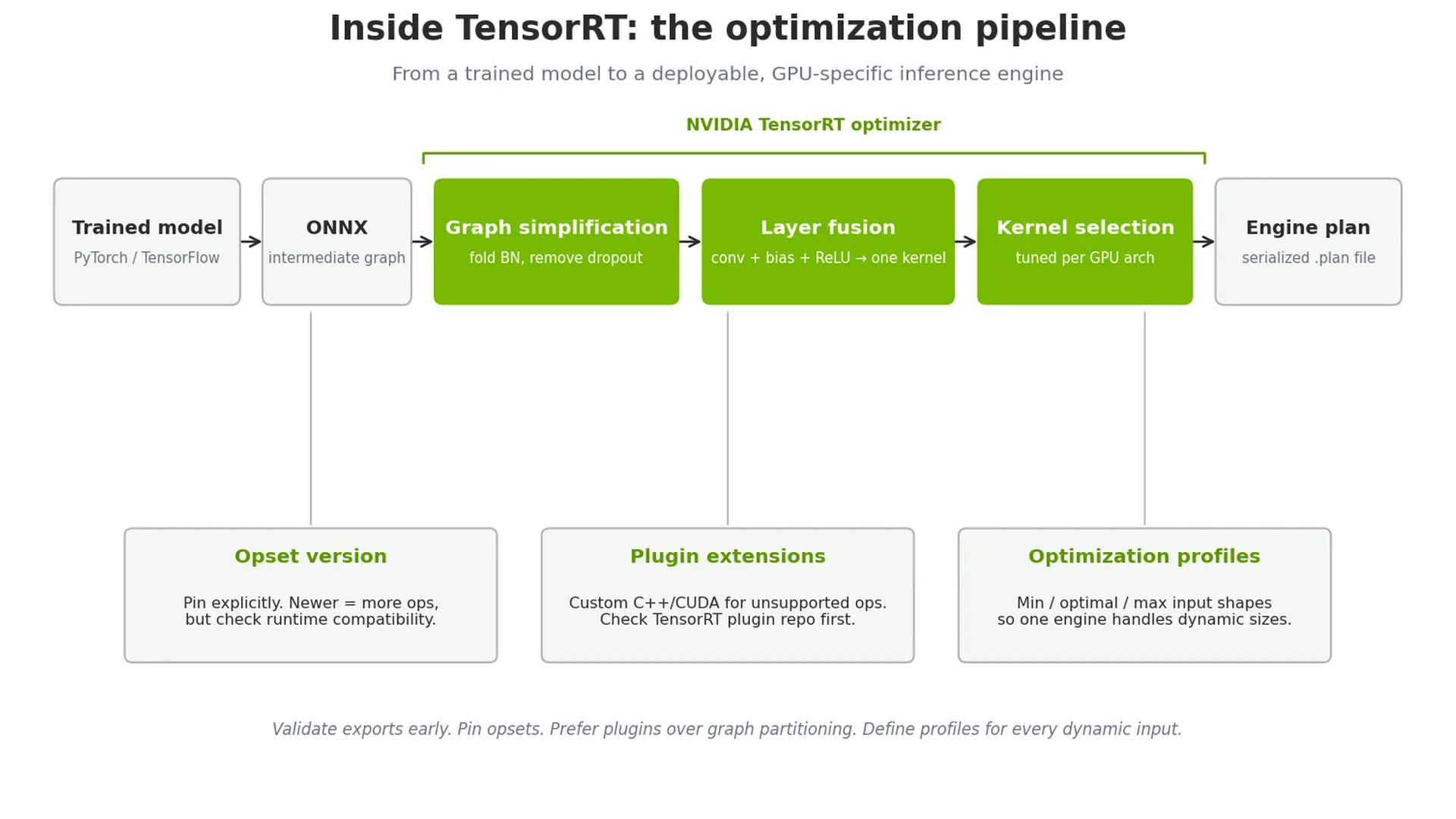
如何处理不受支持的操作
即使采用谨慎的导出实践,您偶尔也会遇到目标运行时原生不支持的操作。这种情况在引入新型注意力机制、自定义激活函数或专门归一化层的尖端架构中尤为常见。如果不进行干预,TensorRT 要么返回较慢的执行路径,要么完全无法完成构建。
最佳实践 4:对不支持的操作使用 TensorRT 插件进行扩展。通过插件,您可以使用 C++ 或 CUDA 编写自定义实现,直接集成到优化流程中,并享有与内置操作相同的内核选择和内存优化。相比图分割方法,此方式更优,因为图分割会在运行时引入额外的内存复制,并阻碍跨层优化。
最佳实践 5:在开发自定义插件前,请先查阅 TensorRT 插件库。NVIDIA 维护着该插件库,并持续通过社区贡献不断扩展其内容。
最佳实践 6:设计时需考虑模型的部署。在选择架构之初,应尽早评估其在实际部署中的运维成本。有时,存在功能相似但更易于运维的替代方案,选择此类方案可节省数周的工程工作量。
如何管理动态输入大小
许多 AI 应用必须管理不同大小的输入:不同长度的句子、不同分辨率的图像或随流量波动的批量。如果 TensorRT 引擎是针对固定的输入形状构建的,则任何偏差都需要填充 (浪费计算) 、调整大小 (可能会改变行为) 或重建引擎 (成本高昂且速度缓慢) 。
最佳实践 7: 在 TensorRT 中配置动态输入时,应为每个输入张量定义最小、最优和最大维度的优化配置文件,从而构建一个无需重新编译即可支持多种输入尺寸的推理引擎。例如,对于图像尺寸范围在 224×224 到 1024×1024 的情况,可使用该范围的边界值,并结合最常用分辨率设置最优尺寸,来定义输入轮廓。
最佳实践 8:针对不同的工作负载模式使用多个优化配置文件。如果您的应用在不同时间段处理明显不同的输入模式,例如在低流量时段进行单图像推理,而在高峰时段进行大批量推理,请为每种模式分别定义优化配置文件。TensorRT 能够在运行时以极低的开销在这些配置之间切换。
最佳实践 9:对整个输入范围进行基准测试,使用 trtexec 测量最小、最佳和最大维度下的延迟与吞吐量,以揭示引擎在不同内核实现间切换时的性能下降情况。
如何防止版本不匹配
版本不匹配是最潜在的摩擦来源之一,因为它们通常不会产生任何错误。模型的运行准确性可能会降低,或者运行时可能会回退到较慢的代码路径而不会发出警告。这些悄无声息的故障可能会持续数月。
典型部署堆栈中的版本矩阵十分复杂:训练框架、ONNX 导出器、TensorRT、CUDA 工具包、cuDNN、GPU 驱动程序和操作系统,任何两者之间的版本不匹配都可能导致问题。
最佳实践 10: 固定并记录整个依赖堆栈。创建版本清单,列出每个组件及其确切的版本号。将其与模型构件一起存储。
最佳实践 11:使用容器实现可重复性。NVIDIA NGC 容器集成了兼容版本的 TensorRT、CUDA、cuDNN 以及主流框架,可有效消除开发、测试和生产环境中最常见的版本不匹配问题。
最佳实践 12:单独测试升级。一次仅更改一个组件,然后运行完整的测试套件,然后再继续。
在介绍了四个主要类别后,以下各节将探讨更多减少管道摩擦的方法。
如何配置和调试工作流
即使是无摩擦的管道也可能存在性能问题。有效的分析至关重要。
最佳实践 13:使用 TensorRT 命令行工具 trtexec 进行性能基准测试。在将模型集成到服务系统之前,先独立运行模型,以确定其基准延迟和吞吐量。若性能不理想,问题 likely 出在模型本身或引擎配置上。
最佳实践 14: 使用 NVIDIA Nsight 深度学习设计器 进行分析,实现层级细粒度剖析。它可为模型图中每个操作提供详细的时间信息,便于快速识别性能瓶颈,例如内存受限的操作、低效的数据布局或阻碍算子融合的操作。
最佳实践 15: 使用 NVIDIA Nsight Systems 进行系统级性能分析。Nsight Systems 能在统一的时间轴上清晰呈现 CPU 和 GPU 的活动,帮助识别数据预处理中的 CPU 瓶颈、多余的同步点,以及两次推理调用之间 GPU 的空闲时段。这对于优化整体端到端吞吐量至关重要,而不仅限于推理延迟的分析。
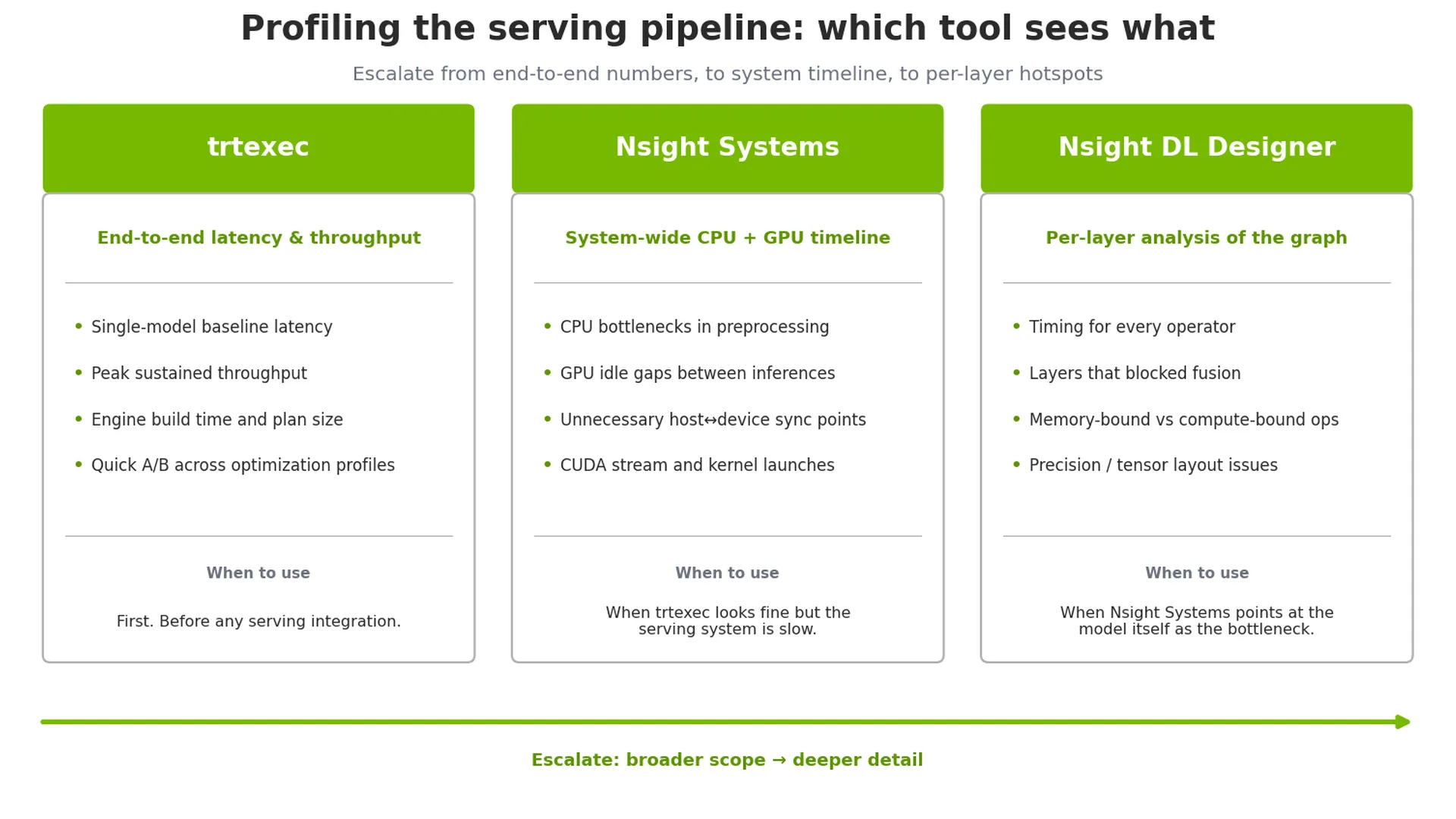
trtexec 作为基准数字,在服务系统运行缓慢时使用 Nsight Systems,在模型本身成为瓶颈时使用 Nsight Deep Learning Designer如何将 TensorRT 与 Dynamo-Triton 集成
优化模型仅是成功的一半。在生产环境中,您还需应对并发请求、管理模型版本、均衡 GPU 间的负载,并确保高可用性。 NVIDIA Dynamo-Triton(原名为 NVIDIA Triton 推理服务器)是一个开源服务平台,原生支持 TensorRT 引擎及其他框架,助力构建可用于生产的完整技术栈。
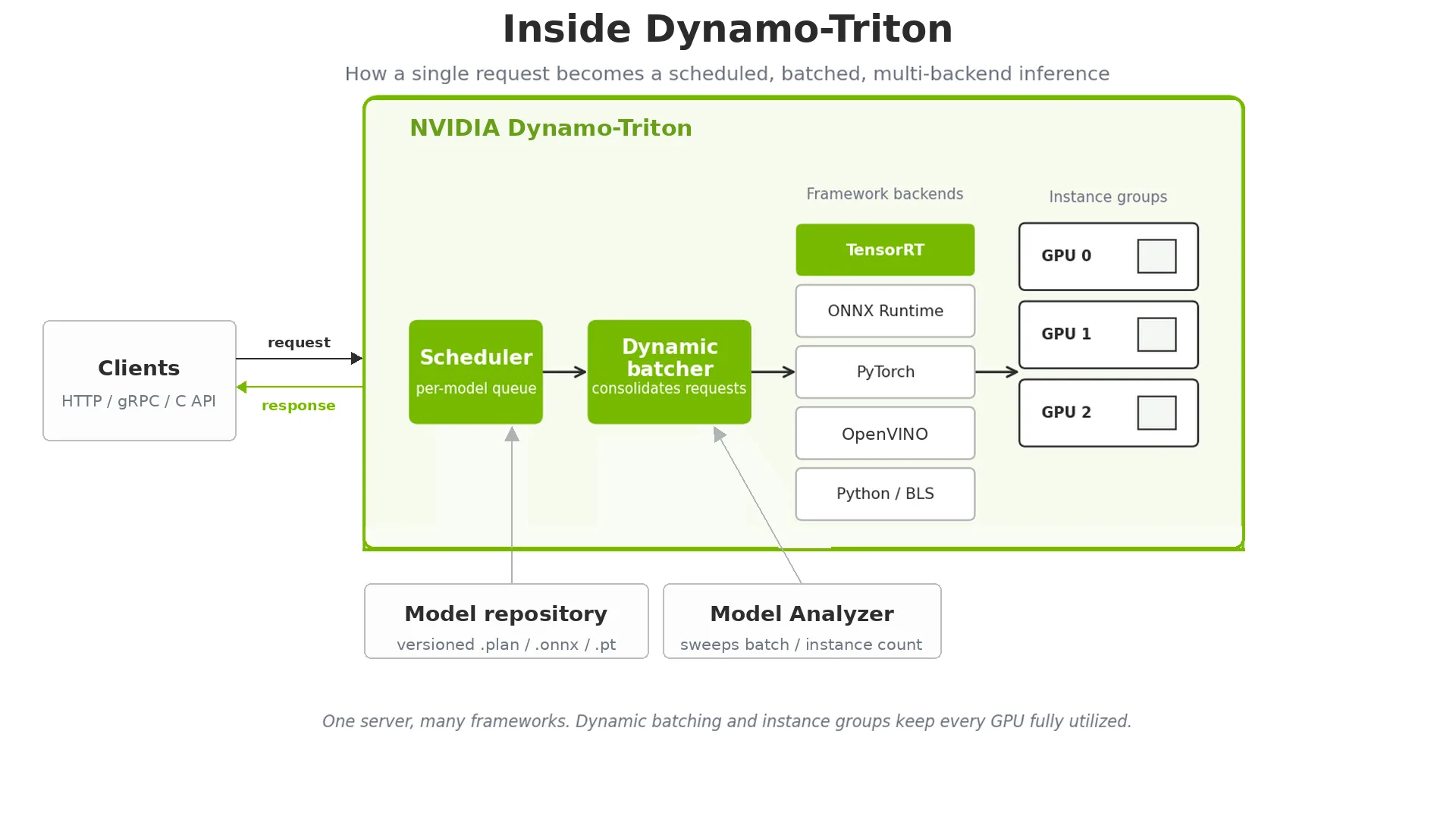
最佳实践 16:在 Dynamo-Triton 中配置动态批处理时,应将其最大批量大小设置为与 TensorRT 优化配置文件中的最大批量维度一致,确保动态批处理请求始终处于优化范围内。
最佳实践 17:使用 Dynamo-Triton 模型分析器寻找最优配置。它会系统性地测试不同的批量大小、实例数量和并发级别组合,在满足延迟要求的同时,最大化吞吐量。
最佳实践 18:使用 Dynamo-Triton 模型库实现模型版本控制。Dynamo-Triton 支持同时服务多个版本,便于进行金丝雀发布和渐进式上线。将其与您的版本清单结合使用,以确保兼容性。
有关建立顺畅工作流的更多提示
消除管道摩擦需要在工作流程中构建实践,防止其累积。创建部署检查清单,内容涵盖导出验证、性能基准测试、版本兼容性和生产配置。通过 CI/ CD 工作流实现自动化。
投资监控,检测生产中的回归。跟踪推理延迟、吞吐量、GPU 利用率和模型准确性。如果有任何指标偏离基准,请立即调查。
促进训练和部署团队之间的沟通。在训练过程中,许多摩擦源源于架构决策,会产生意想不到的部署后果。早期协作使团队能够做出明智的决策和权衡取舍。
开始使用,消除管道摩擦
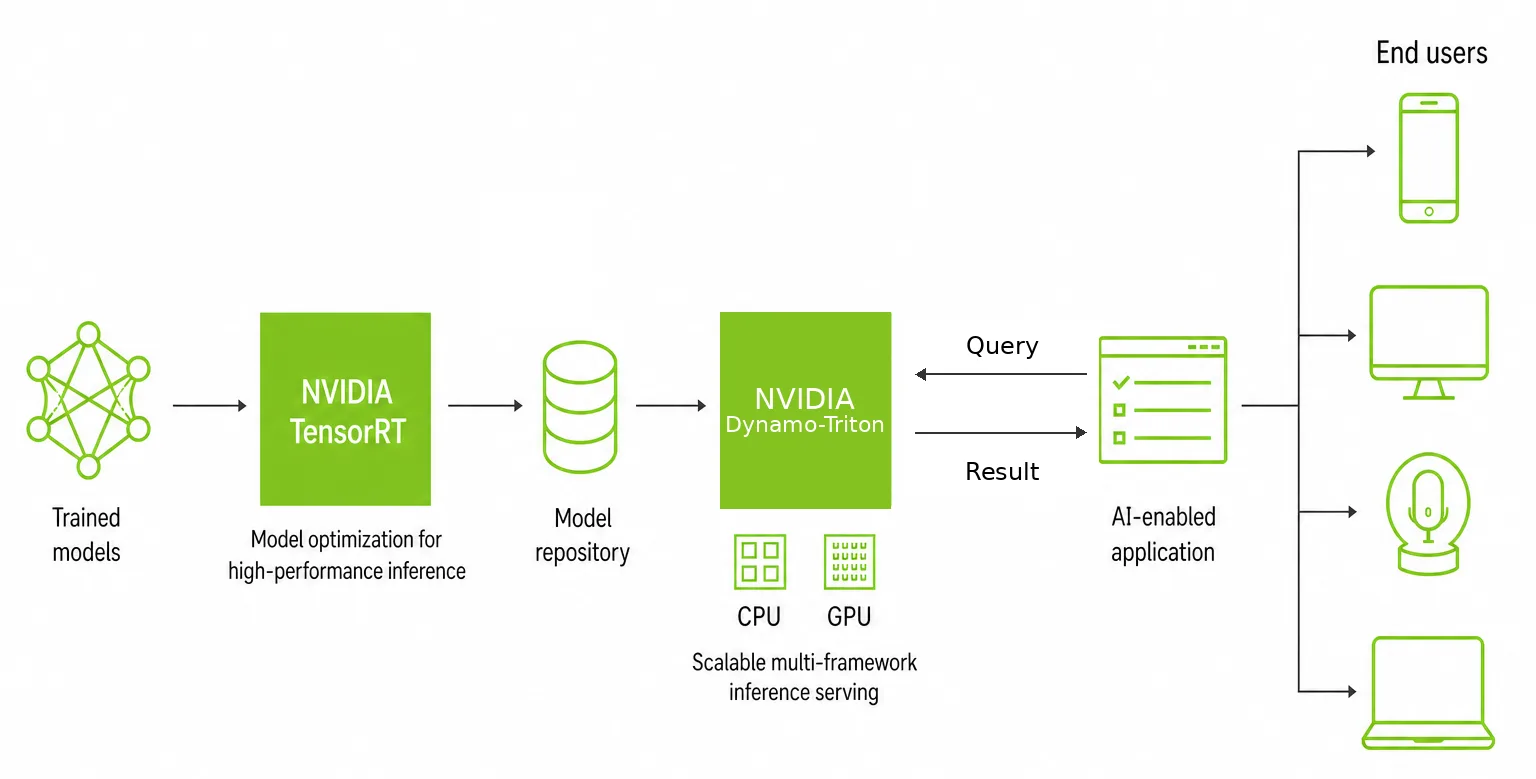
为管道摩擦提供服务的 AI 模型是一个可以解决的问题。TensorRT 通过动态输入配置文件和插件扩展提供优化。分析工具 (如 trtexec、Nsight Deep Learning Designer 和 Nsight Systems) 提供了对每一层的可见性。Dynamo-Triton 负责生产服务和交通管理。
关键是要系统地应用这些工具。尽早验证导出,设计部署,仔细管理版本,全面分析并持续监控。最终可为最终用户提供更快的迭代速度、高效的资源利用和一致的性能。
TensorRT 和 Dynamo-Triton 在 NVIDIA/TensorRT 和 triton-inference-server/server GitHub 仓库中均为完全开源项目。TensorRT 采用 C++ 编写,其 API 支持 C++ 和 Python;Dynamo-Triton 则提供 C++、Python 和 Java 三种语言的客户端库。
两者均支持 Linux(Ubuntu、RHEL),Windows 支持 TensorRT。最快实现可复现环境的方法是从 NGC 目录 中提取预构建的容器。
首先,浏览 TensorRT 示例目录。trtexec 基于 ONNX 模型构建引擎并进行性能基准测试。ONNX 转 TensorRT 的示例包含导出验证、优化配置文件以及插件扩展。如需了解模型库、动态批处理和 模型分析器 配置的详细信息,请参考 Dynamo-Triton 快速入门指南。