DEVELOPER
首页
博客
论坛
论坛 (英文)
文档
下载
培训
搜索
加入
Dynamo-Triton
2026年 7月 2日
基于硬件的 AI 安全性不会拖慢您的速度
AI 改变了组织的运营方式,推动了前所未有的生产力和创新水平。但是,数据隐私、主权以及如何保护使用中的数据,
2 MIN READ
基于硬件的 AI 安全性不会拖慢您的速度
2026年 5月 12日
如何在 AI 模型服务中消除管道摩擦
从训练好的AI模型到投入生产的路径本应顺畅,但实际情况往往并非如此。许多团队花费数周时间对模型进行微调,
2 MIN READ
如何在 AI 模型服务中消除管道摩擦
2026年 3月 23日
在 Kubernetes 上部署解 LLM 推理工作负载
随着大语言模型 (LLM) 推理工作负载的复杂性不断增加,单个单一的服务进程开始达到其极限。预填充和解码阶段具有截然不同的计算配置文件,
4 MIN READ
在 Kubernetes 上部署解 LLM 推理工作负载
2026年 3月 16日
NVIDIA Dynamo 1.0 如何助力量产级多节点推理
推理模型的规模正在迅速增长,并且越来越多地集成到与其他模型和外部工具交互的代理式 AI 工作流中。
4 MIN READ
NVIDIA Dynamo 1.0 如何助力量产级多节点推理
2020年 8月 27日
用 NVIDIA 模型分析器最大化深度学习推理性能
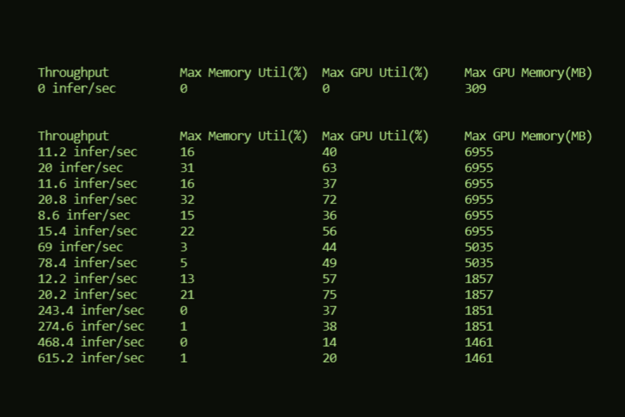
图 1 。模型分析仪截图。您已经构建了深度学习推理模型,并将其部署到 NVIDIA Triton 推理服务器上,以最大限度地提高模型性能。如何进一步加快模型的运行速度?进入 NVIDIA Model Analyzer ,即将发布的工具,用于收集模型的计算需求。没有这方面的信息,在。。。
2 MIN READ
用 NVIDIA 模型分析器最大化深度学习推理性能
加载更多