
代理式推理通过引入非确定性轨迹(即AI智能体在执行任务时生成的动作、观察结果和决策),从根本上改变了推理工作负载的运行时特性。这些轨迹会导致每个会话产生数百个推理请求,显著增加端到端延迟。
NVIDIA Vera Rubin NVL72 作为 NVIDIA Vera Rubin 平台的核心计算引擎,能够处理大多数推理负载。对于要求极为严苛的新兴多智能体工作负载,需在具备长上下文窗口的万亿参数 MoE 模型上,持续实现低延迟和高吞吐量的生成。
迄今为止,尚无任何平台能以经济高效的方式支持此类新兴工作负载。 NVIDIA Groq 3 LPX,与 Vera Rubin NVL72 强强联手,首次在帕累托曲线的这一位置实现了高吞吐量与低延迟。
本文将探讨 NVIDIA Vera Rubin 平台如何通过极致协同设计解决这一挑战,将高吞吐量计算与数百到数千个芯片的低延迟确定性执行相结合。
为什么代理式工作负载需要可预测的纵向扩展网络
传统的数据中心网络结构针对大型训练作业和大规模推理工作负载进行了优化,在这些工作负载中,少量网络抖动会在大批量中平均产生。相比之下,高级 AI 服务需要更高的模型能力和响应迅速的用户可见性能。在这一层,代理解码带来了一系列截然不同的要求,包括:
- 多轮模型请求
- 更小批量
- 超低延迟
长上下文和大型 MoE 模型 (用于高级 AI 服务) 带来了额外的网络挑战 (图 1) 。多智能体工作流中的每个智能体都有自己的扩展 KV 缓存、系统提示、工具定义和对话历史记录。该 KV 缓存和任何新的词元必须通过万亿参数模型及其相关专家在不同加速器中进行路由。
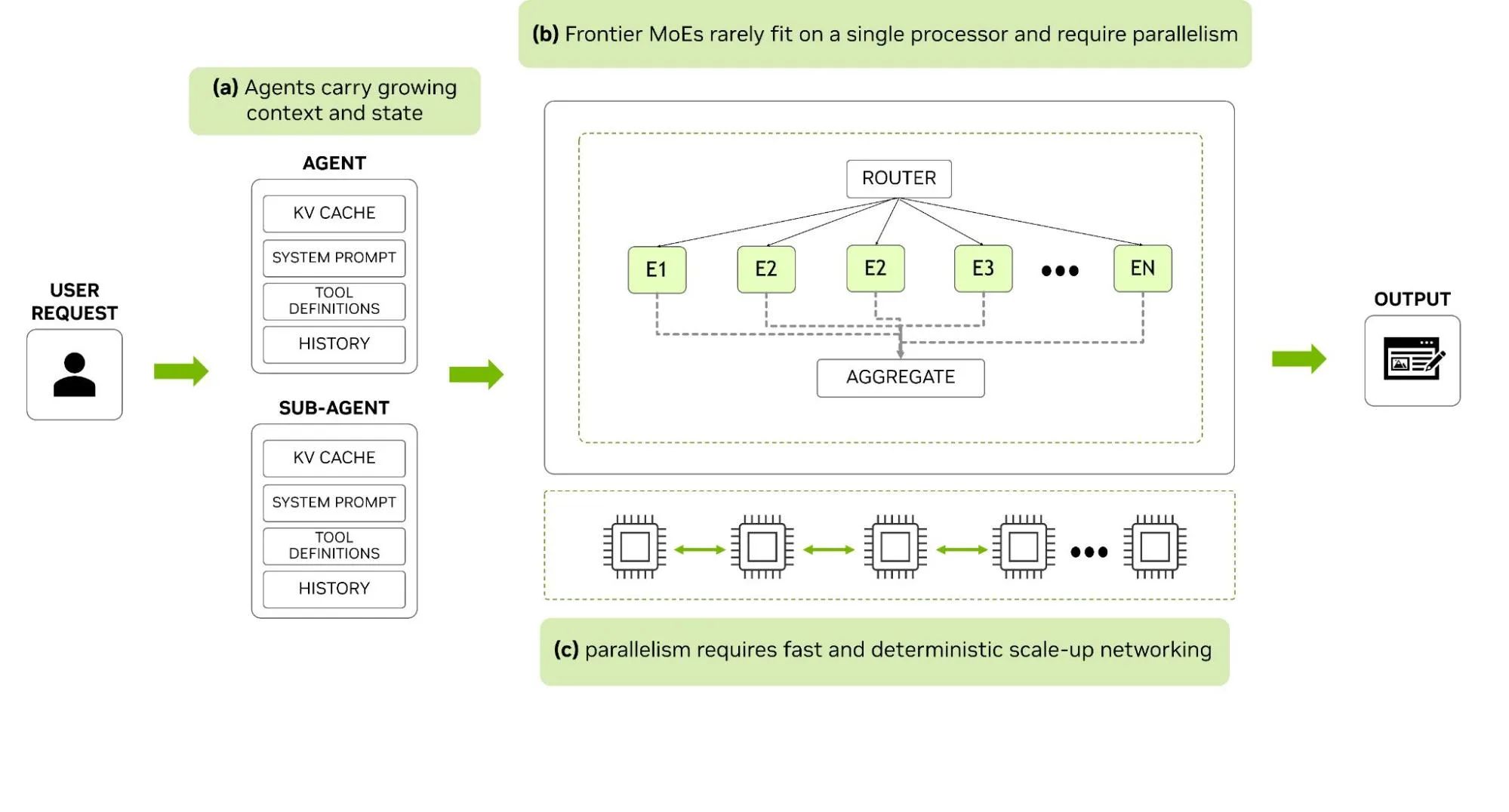
为此,网络级编排必须确保将芯片之间的 hop 变化降至最低。在任何基于 SRAM 且无法在单个芯片上容纳模型的架构中,这种跨芯片交换都是不可避免的。交换发生的物理机制成为服务系统的关键瓶颈。
传统上,该行业通过以下方式应对这一挑战:
- 运行时仲裁的网络结构其中流控制是反应式的,并且计时是统计边界而非保证的。
- 裸片上的计算和内存高度集中,导致网络问题延迟到模型和上下文窗口大小要求其纵向和横向扩展之前,从而导致多芯片性能下降。
要打破代理式规模的吞吐量 – 延迟权衡,需要使用芯片、编译器和服务堆栈设计网络结构。LPU C2C 通过极致协同设计实现了这一目标,可大规模实现数万亿参数模型。
NVIDIA Groq 3 LPX 如何应对纵向扩展挑战
NVIDIA Groq 3 LPX LPU C2C 旨在直接解决纵向扩展难题。LPU C2C 并未将互连视为传统网络(需在运行时承受争用和时间不确定性),而是将 Groq 的确定性执行模型扩展至多个 LPU。其实现方式依赖于三种紧密集成的技术:
- 高基数点对点链路
- LPU 编译器调度的数据移动
- 硬件驱动的同步计时
这些技术共同使 Groq 3 LPU 加速器能够灵活扩展到数千个芯片,同时保持可预测的通信、固定延迟和低抖动执行。以下各节将依次进行研究。
高基数点对点链路
每个 LPU 可提供 96 条 112 Gbps 的 C2C 链路,每个 LPU 可提供约 2.5 TB/s 的扩展带宽,机架级可提供约 640 TB/s 的扩展带宽。该设计基于 NVIDIA MGX 机架级扩展架构,使用无线缆托盘和点对点、高基数的 C2C 拓扑,在托盘和机架之间紧密合计算和通信。
直接对等连接、专用路径、负载下的对称路由以及低跃点计数可实现高效的集合通信,而编译器则以静态方式而不是在运行时规划每次传输。
编译器调度的数据移动
LPU C2C 扩展采用软件调度。LPU 之间的通信以 320 字节向量 (用于计算的固定大小单元) 进行,并且在编译时作为一级功能单元以及矩阵、向量和交换机执行模块进行流控制和调度。编译器会提前规划每一次传输,包括当每个向量离开其源 LPU 时,接收到的链路,以及到达时,因此负载平衡、路线选择和同步将以静态方式解决,而不是由处于争用状态的硬件调度程序解决。因此,编译器将数千个互连的 LPU 视为单个调度执行面,更接近一个裸片上功能单元之间的线缆,而不是独立芯片网络。
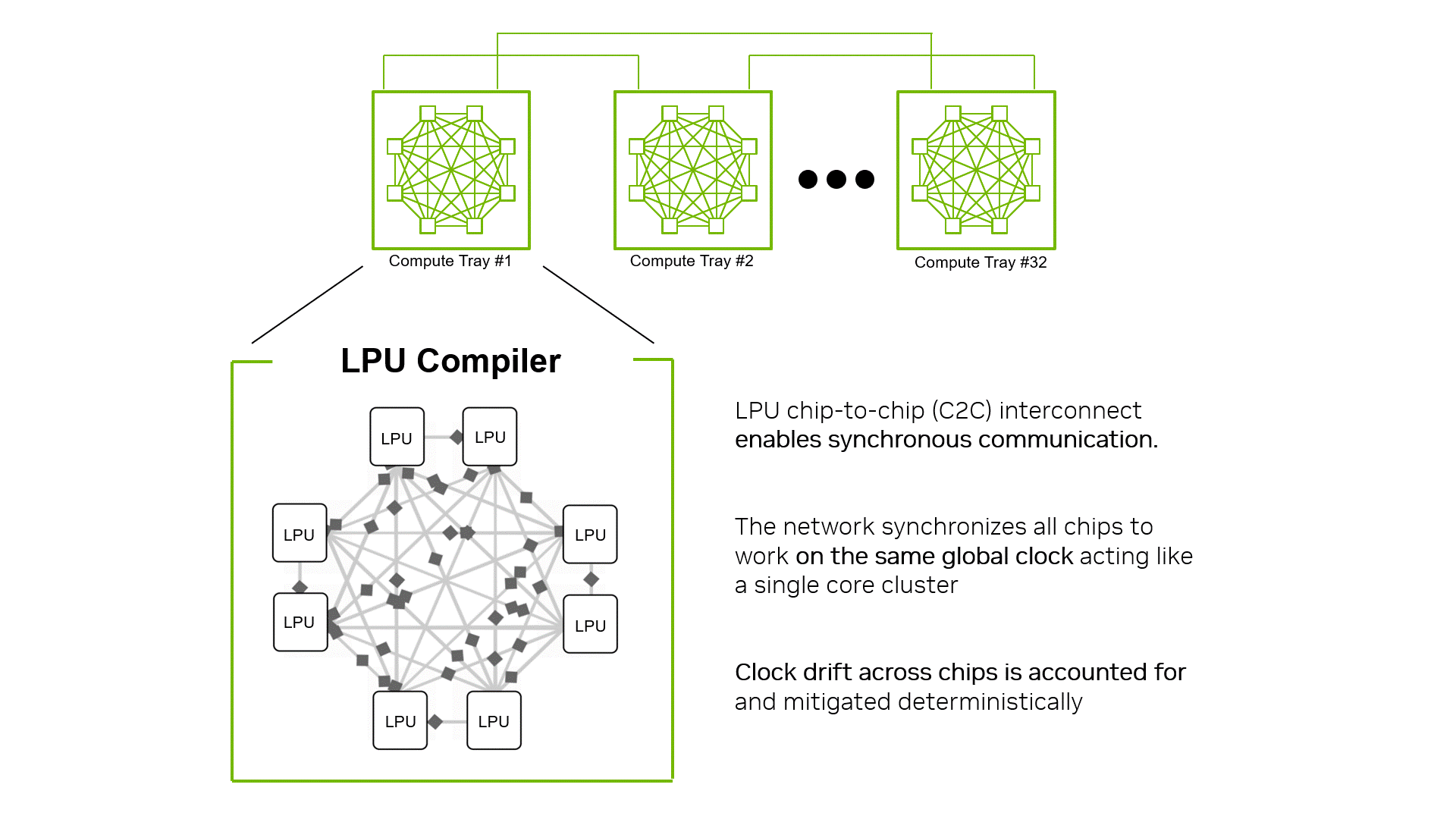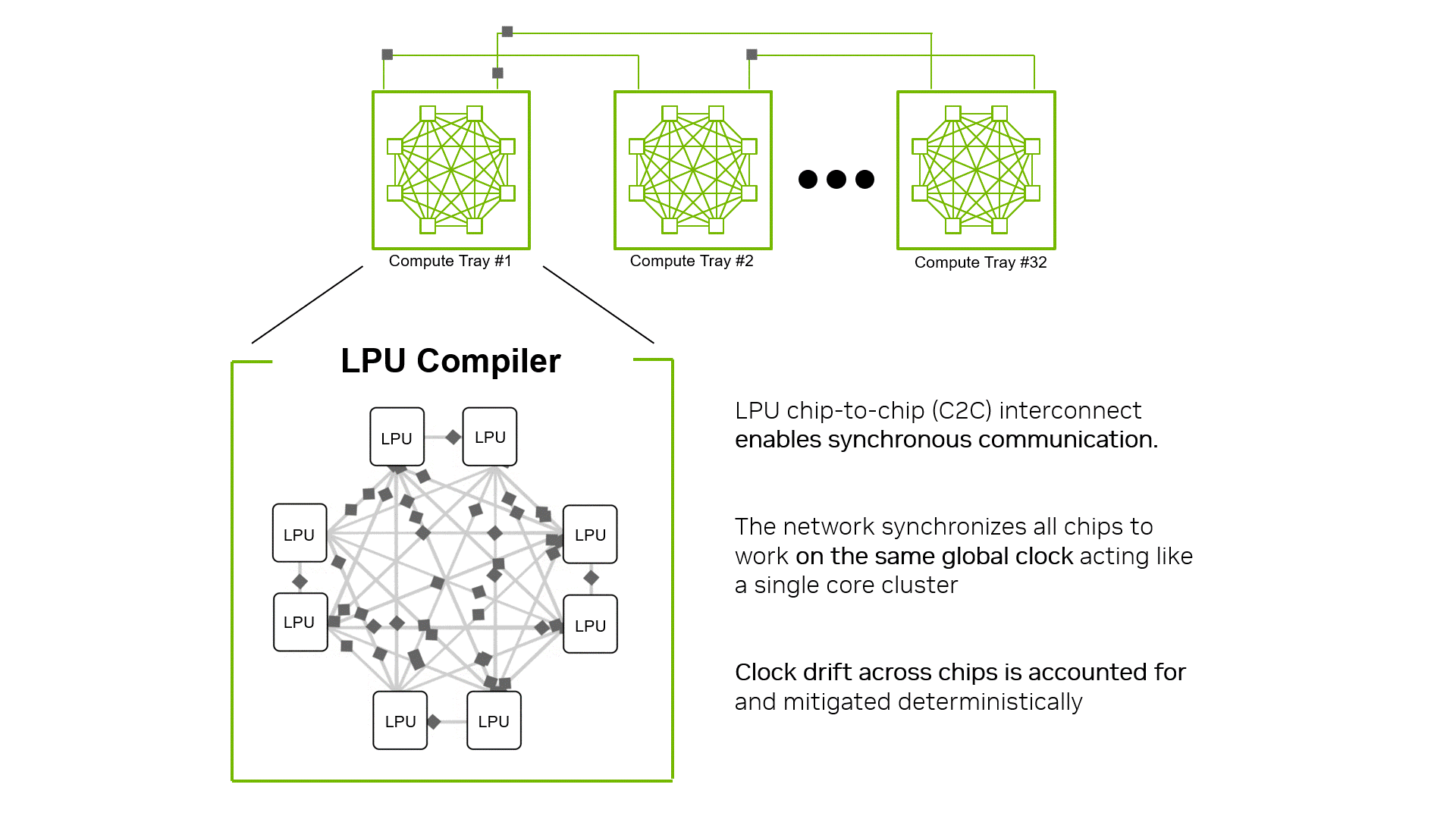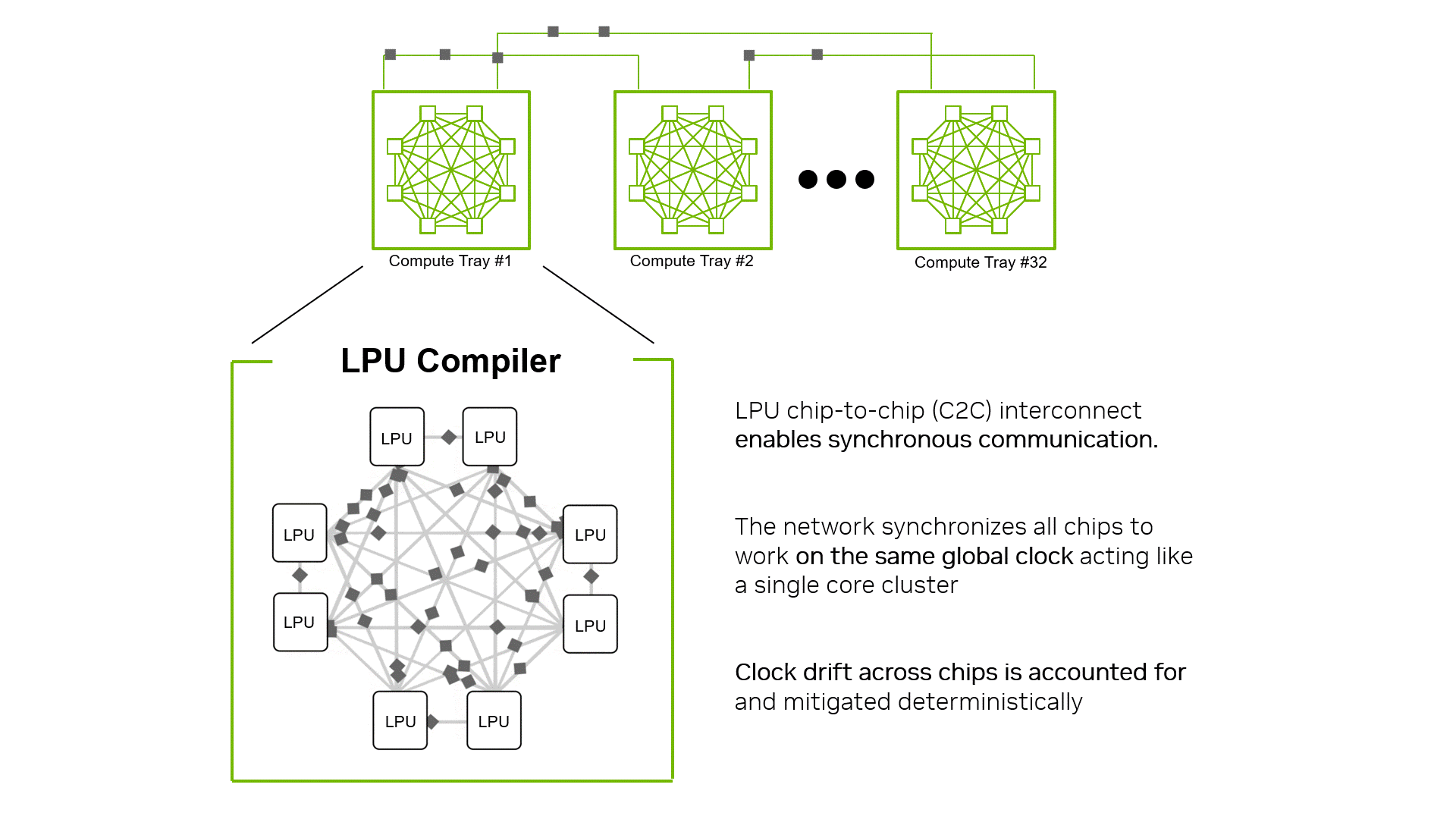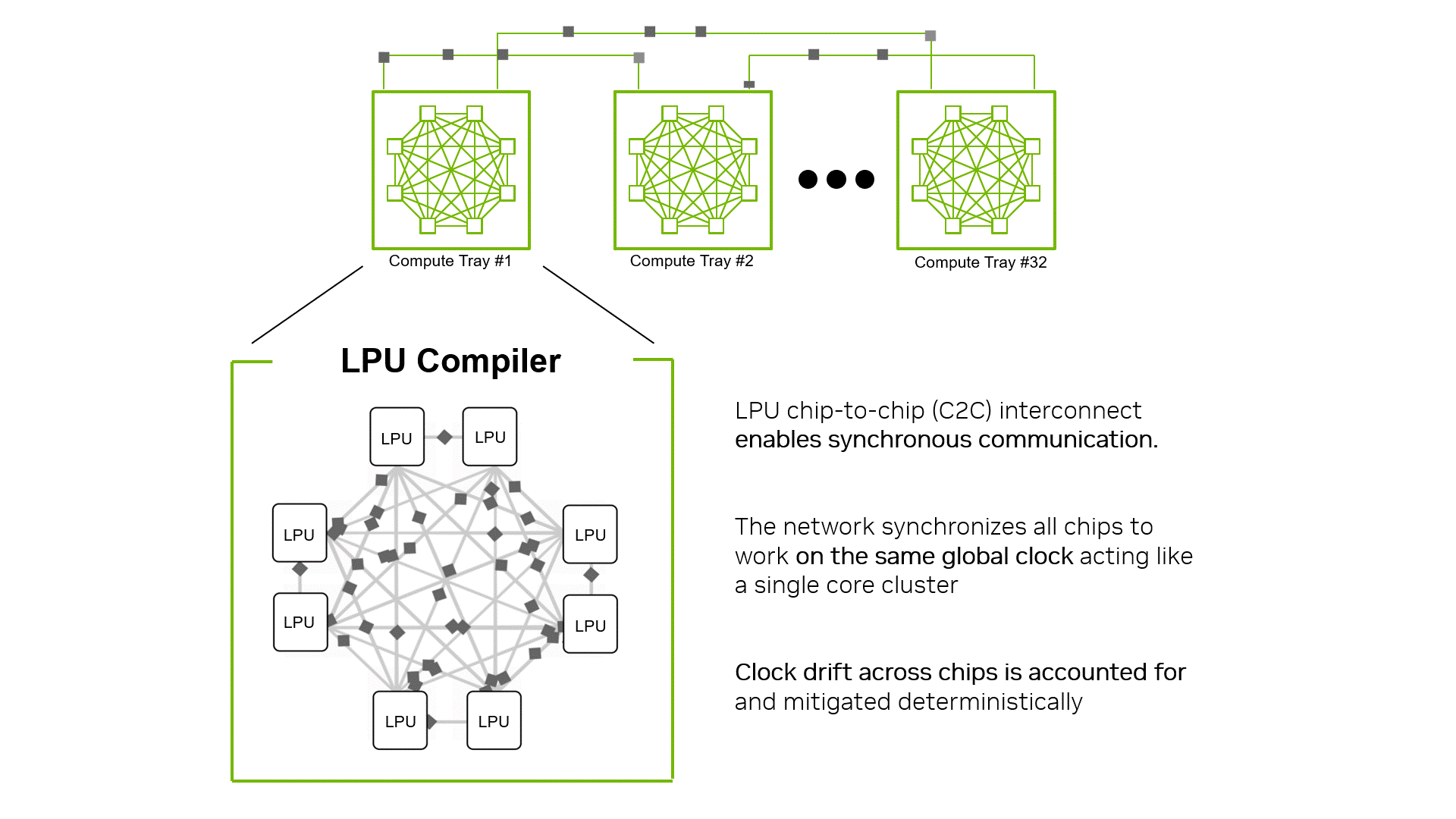
硬件驱动的同步计时
每个 LPU 都在自己的时钟上运行,由于时钟会自然漂移,LPU C2C 扩展使用 plesiosynchronous 或近乎同步的 C2C 协议来消除漂移并对齐数千个 LPU,使其成为单个核心。借助可预测的数据到达和定期软件同步,运行时可避免防御性缓冲,从而以大多数架构无法比拟的规模实现编译时已知的网络延迟。通过消除不可预测的网络跳跃、协调数据移动并修复编译时的延迟,这些纵向扩展技术使 Groq 3 LPX 能够将数百或数千个 LPU 作为一个连贯、低抖动的系统运行,用于必须快速协调工具、内存和多步骤计划的代理式工作负载。
代理式工作负载如何从 LPU C2C 中受益
LPU C2C 的核心回报是机架级确定性:128 GB 统一的片上 SRAM,其性能可随着您的扩展而随时预测 (图 3) 。在所有基于 SRAM 的 ASIC 中,张量并行域中的 SRAM 数量是最大的,这表明 LPU 架构在扩展 SRAM 方面的优势。
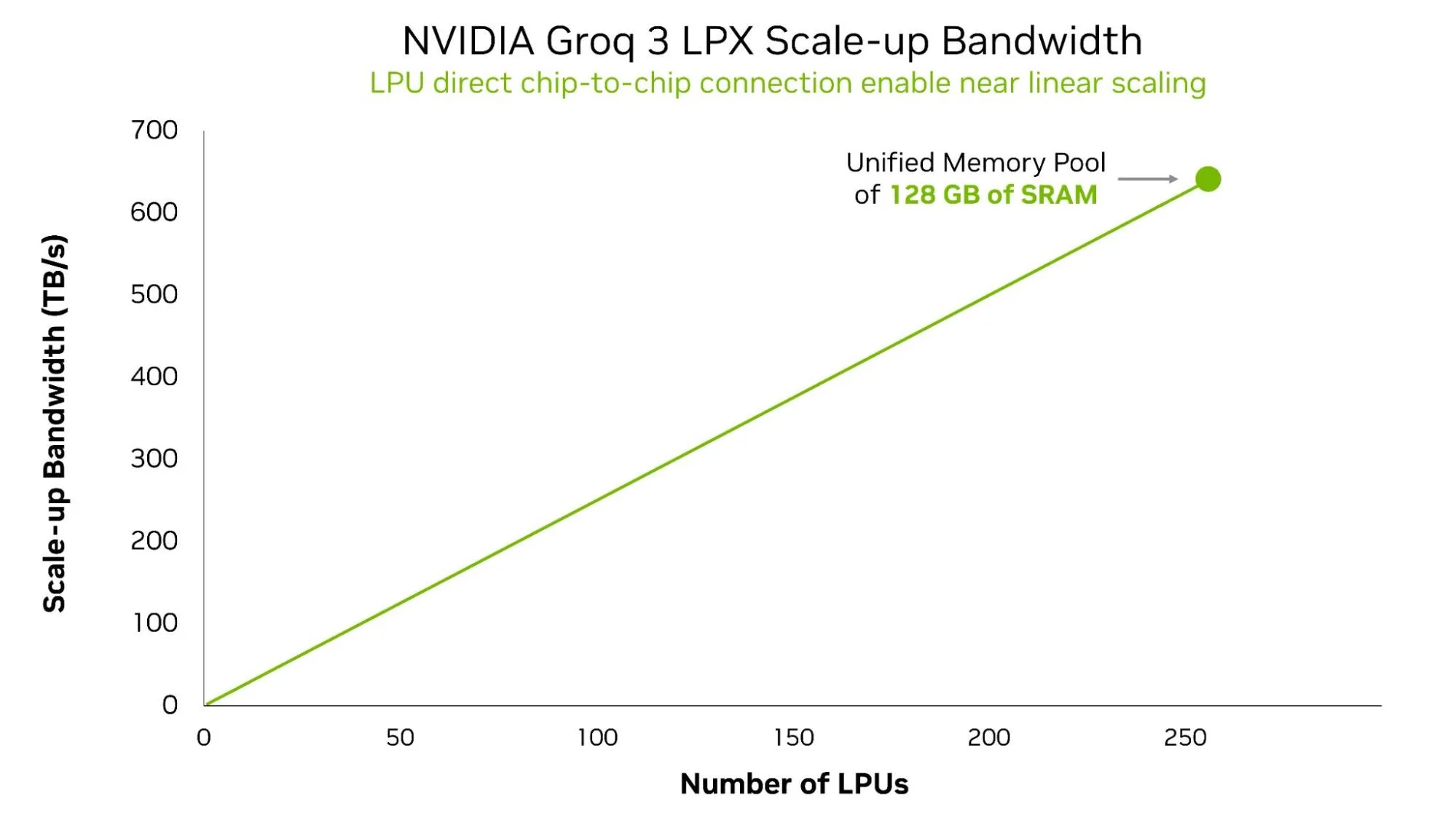
LPU 编译器使用逐层分区等策略对该池中的万亿参数模型进行分区,因此片内 SRAM 的结合可充当远超任何单个芯片所能提供的工作内存。对于代理式工作负载,这等同于前沿 MoE 模型,这些模型以低延迟运行,而无需在上下文窗口或准确性方面进行强制权衡。在多智能体会话的突发扇出模式下,尾部延迟保持有限,并且每词元延迟是可预测的。
到目前为止,低延迟仅仅是其自身存在的问题。AI 工厂部署还需要大型 GPU 池提供的计算能力、吞吐量和并发服务。这就是与 Vera Rubin NVL72 进行联合设计的用武之地。Vera Rubin NVL72 可提供高达 3600 PFLOPS 的 NVFP4 计算能力、20.7 TB 的 HBM4 以及每个机架 1.6 PB/s 的显存带宽,从而处理预填充、长上下文解码注意力和高并发服务。当延迟预算进一步收缩时,NVIDIA Dynamo (图 4) 使用注意力 – FFN 分解 (AFD) 编排异构解码循环。此 AFD 循环按以下方式编排:
- Rubin GPU 在累积的 KV 缓存上运行解码注意力
- LPX 加速 FFN 执行
- 每个词元的中间激活函数通过低用度、KV 感知的传输进行交换
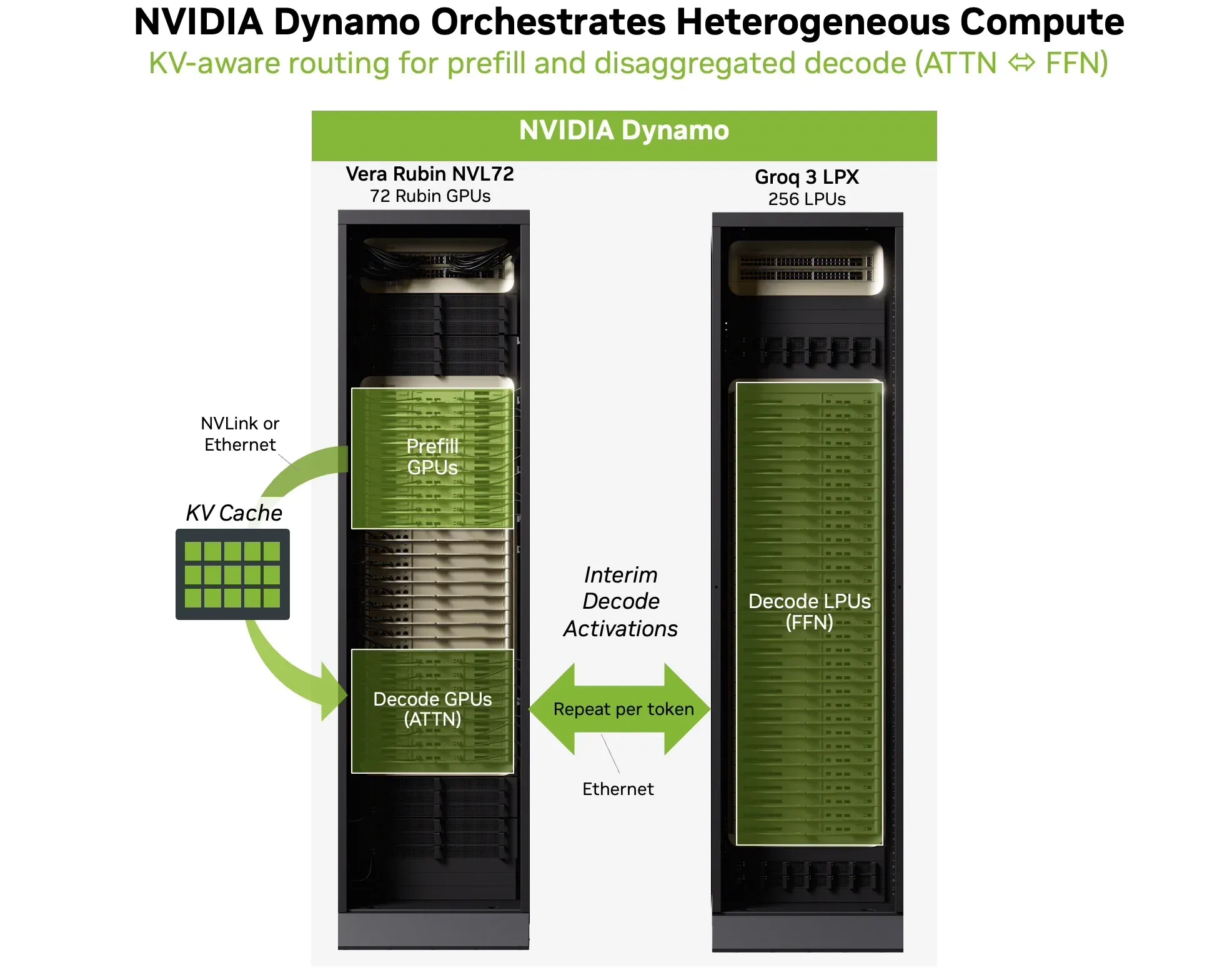
由于这两个引擎针对的是不同的计时机制,因此工作分工是有效的。预填充和解码注意力以吞吐量为主,批量较大,KV-cache 读取会在许多词元 (与 NVLink 的高带宽纵向扩展互连非常匹配的配置文件) 上摊销。FFN 解码循环采用顺序词元生成,以小批量运行,其中微抖动开始主导用户可见延迟。编译时调度的 C2C 专为该机制而构建。
Groq 3 LPX、Vera Rubin NVL72 和 Dynamo 共同组成了一个平台,可在相同的服务路径中提供确定性的低延迟、前沿模型规模、长上下文支持和高吞吐量。在采用 400K-词元上下文的万亿参数 MoE 模型上,NVIDIA 协同设计可为每个用户提供每秒 400 词元的吞吐量,比 NVIDIA GB200 NVL72 高 35 倍,并为代理式工作负载带来高达 10 倍的创收机会。
如需详细了解 Vera Rubin 平台规格和 LPX,请查看以下博客文章: