
模型量化是一种有效的方法,可减少显存占用并提升消费级设备(如 NVIDIA GeForce RTX GPU)上的推理性能。通过降低计算和内存需求,同时保持模型质量,量化使 AI 模型在资源受限的环境中能够更高效地运行。
本文将介绍如何使用 NVIDIA Model Optimizer,通过后训练量化(PTQ)方法对 FP8 格式的 CLIP 模型进行量化。如需了解模型量化的基础知识,请参阅 模型量化:概念、方法和重要性。
什么是 NVIDIA Model Optimizer?
NVIDIA Model Optimizer(ModelOpt)库采用先进的模型优化技术,可对 AI 模型进行压缩和加速。这些技术包括量化、蒸馏、剪枝、预测解码和稀疏化。ModelOpt 支持以 Hugging Face、PyTorch 或 ONNX 格式输入的模型,并提供 Python API,方便用户灵活组合多种优化技术,生成优化后的模型检查点。
ModelOpt 支持 FP4、FP8、INT8 和 INT4 等高性能量化格式,以及 SmoothQuant、AWQ、SVDQuant 和双量化等先进算法,同时支持 PTQ 和 量化感知训练(QAT)。
什么是 CLIP?
CLIP(对比语言-图像预训练),由 OpenAI 于 2021 年推出,是一种基础视觉语言模型(VLM),通过在大规模图像-文本对上进行对比学习,来构建图像与文本的共享嵌入空间。它能够生成语义对齐的表示,因而成为现代多模态系统的核心组成部分。
CLIP 文本编码器被广泛用作文本转图像 (例如 Stable Diffusion) 和文本转视频 (例如 AnimateDiff) 合成的调节模块。其视觉编码器可作为多模态 LLM (例如 LLaVA) 和开放词汇感知模型 (例如 OWL-ViT) 的视觉主干。OpenCLIP 和 SigLIP 等后续产品可扩展数据并优化目标,同时保留双编码器对比范式。
量化方法
本文将以下量化方法用作使用 ModelOpt 运行 CLIP 模型量化的分步指南,以了解该过程的工作原理。
首先,准备对应的模型和数据集,如下所示:
- 基础 CLIP 模型:CLIP-ViT-L-14-laion2B-s32B-b82K
- 量化校准数据集:MS-COCO 的 1 万个子集
- 模型准确性评估任务主要关注 CLIP_benchmark 中的以下三项:
- cifar100(零样本分类)
- imagenet1k(零样本分类)
- mscoco_captions(零样本检索)
如何使用 ModelOpt 运行 PTQ
以下代码示例展示了如何使用 ModelOpt 在 FP8 中为 CLIP 模型运行 PTQ:
import torchfrom torch.utils.data import DataLoader, Subsetfrom transformers import CLIPModel, CLIPTokenizer, CLIPImageProcessorfrom transformers.models.clip.modeling_clip import CLIPAttentionimport modelopt.torch.opt as mtoimport modelopt.torch.quantization as mtqfrom modelopt.torch.quantization.plugins.diffusion.diffusers import _QuantAttention# FP8 (E4M3) per-tensor static quantizationFP8_CFG = { "quant_cfg": { "*weight_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"}, "*input_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"}, "*[qkv]_bmm_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"}, "*bmm2_output_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"}, "default": {"enable": False}, }, "algorithm": "max",}mto.enable_huggingface_checkpointing()mtq.QuantModuleRegistry.register({CLIPAttention: "CLIPAttention"})(_QuantAttention)model = CLIPModel.from_pretrained(args.model_ckpt, attn_implementation="sdpa").half().eval().cuda()tokenizer = CLIPTokenizer.from_pretrained(args.model_ckpt)processor = CLIPImageProcessor.from_pretrained(args.model_ckpt)calib_set = Subset(CLIP_COCO_dataset(ANN, IMG_DIR, tokenizer, processor), range(8192))loader = DataLoader(calib_set, batch_size=512, num_workers=4)# Calibration: 8k MS-COCO image-text pairsdef calibrate(m): for img, txt in loader: m.get_text_features(input_ids=txt.cuda()) m.get_image_features(pixel_values=img.cuda())q_model = mtq.quantize(model, FP8_CFG, forward_loop=calibrate)# Save quantized modelopt checkpointq_model.save_pretrained(ckpt_path)mtq.print_quant_summary(q_model) |
FP8_CFG 只是其中一种方法:W8A8 (权重和激活函数均为 FP8) ,每张量,静态量化,使用简单的 AbsMax 算法进行校准。ModelOpt 支持更多维度选择 (每通道/ 每块粒度、动态激活量化、高级校准算法 (例如 AWQ/ GPTQ 等) 。
有关详细配置模式,请参考 ModelOpt 量化指南。量化配置中的超参数可根据需要随时微调,通常需经过若干次迭代才能找到最优值。
mtq.quantize 返回后,CLIP 的 Linear 层均携带权重和激活量化器,但注意力块仍然未动。这是因为多头注意力会被分配到 torch.nn.functional.scaled_dot_product_attention,这是 ModelOpt 模块 walker 无法自行拦截的函数式 API。
要将注意力引入量化范围,请注册 CLIPAttention 的量化替换:
mtq.QuantModuleRegistry.register({CLIPAttention: "CLIPAttention"})(_QuantAttention) |
现在,每个 CLIPAttention 实例都已从 ModelOpt diffusers 插件升级到 _QuantAttention。在其正向传递中,_QuantAttention 透明地截取 SDPA 调用,并在融合后的内核周围插入四个量化器:
q_bmm_quantizer、k_bmm_quantizer、v_bmm_quantizer在投影 Q/ K/ V 张量进入内核之前对其进行封装bmm2_output_quantizer会在核函数输出 (softmax @ V) 流入out_proj之前对其进行封装
这可确保对整个注意力机制进行正确的量化。
为了恢复一定的准确性,通常建议使用 mtq.disable_quantizer 禁用一些量化器。这将以函数作为输入,而函数本身则以模块名称作为输入。通过使用正则表达式或字符串匹配,您可以选择要禁用的层。在以下示例中,量化器在 CLIP 模型的 patch_embedding 层中处于禁用状态。
import redef filter_func(name): pattern = re.compile( r".*(patch_embedding).*" ) return pattern.match(name) is not Nonemtq.disable_quantizer(q_model, filter) |
CLIP 基准评估
保存的 ModelOpt 检查点可被恢复至任意下游评估脚本中。具体细节请参见恢复 ModelOpt 模型。量化的 CLIP 检查点在三个基准上进行评估:零样本分类(CIFAR-100、ImageNet-1k)和零样本检索(MS-COCO Captions)。FP16 CLIP 模型作为基准模型使用。
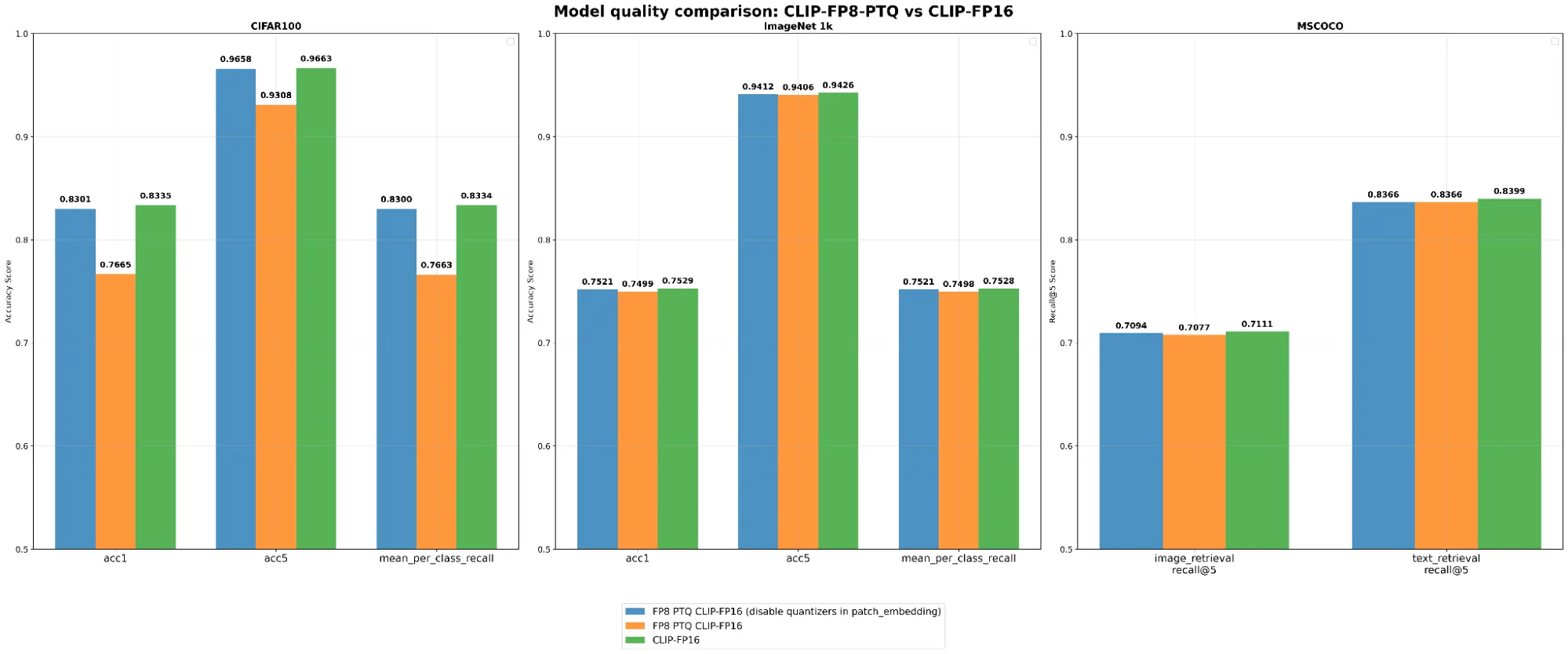
根据评估结果,CLIP-FP8 量化模型的质量可与 CLIP-FP16 模型相美。值得注意的是,在补丁嵌入层中禁用量化器时,量化对模型质量的影响可以忽略不计。
深入了解 ModelOpt PTQ 流程
请务必理解,这个阶段涉及使用“虚假量化”,因为模型的实际数据类型没有改变。相反,这些插入的量化器可充当观察者,在保持模型原始浮点格式的同时模拟量化效果。
假量化过程的工作原理主要有两种:
- 统计收集: 数据经过量化器时,量化器会收集张量的统计信息(如最小值和最大值),并利用这些信息计算最优的量化参数,例如缩放系数。
- 量化模拟: 量化器会对流经网络的张量执行量化后反量化(QDQ)操作。它仅模拟低精度计算,真正的加速和内存节省需通过将模型导出至 NVIDIA TensorRT 等部署框架来实现。
这种模拟至关重要,因为它使您能够在投入实际量化之前评估模型的准确性。量化器应用的舍入和精度限制与使用下游推理框架部署的量化模型相同,因此您可以:
- 在部署前测量准确性影响
- 试验不同的量化配置
- 识别可能需要特殊处理的问题层
一般来说,ModelOpt PTQ 流程分为六个阶段:
- 准备:设置量化配置,围绕模型的权重和/ 或激活函数插入量化器模块。
- 校准: 通过模型转发少量具有代表性的数据,以便每个量化器可以收集统计数据 (例如,激活 Amax) 并推导出其缩放系数。
- 虚假量化: 量化器现以浮点运算方式执行 Q = DQ 往返过程,准确模拟目标格式的精度损失,同时模型仍运行在 FP16/BF16 精度下。
- 评估: 测量延迟评估集的准确性,并与未量化的基准进行比较。
- 迭代: 如果差距不可接受,则调整量化配置 (粒度、算法、量化层) ,禁用敏感层的量化,然后重新校准。
- 导出与部署: 当准确率达到可接受水平后,伪量化的权重将被压缩为真正的低精度格式,并导出为下游引擎的检查点。在本例中,我们将 PyTorch 检查点导出为 ONNX 格式,并使用 TensorRT 执行推理,从而实现加速和内存节省。

QAT 通过冻结量化器状态来微调模型权重,从而恢复因量化导致的质量损失。相比 PTQ,QAT 计算量更大,但能更有效地提升量化模型的质量。更多详细信息请参考 ModelOpt 示例。
开始使用 NVIDIA Model Optimizer
本文介绍了 NVIDIA Model Optimizer,并通过使用实用代码示例将 CLIP 模型量化为 FP8,演示了典型的后训练量化工作流。三个评估数据集的结果表明,FP8 量化可以保持模型质量,同时实现更高效的部署路径。
准备好开始将 ModelOpt 用于您自己的模型了吗?遵循此工作流程:准备模型和校准数据,设置量化配置,校准,根据任务特定的质量指标验证量化模型,保存和恢复 ModelOpt 检查点。
如需探索其他工作流程并根据您自己的用例调整 ModelOpt,请参阅 ModelOpt 文档。