
神经网络技术越来越多地用于计算机图形,以提高图像质量、性能和简化内容创作。超分辨率、降噪和神经网络渲染等方法有助于实时引擎更高效地工作,在考虑性能的同时提供新的创意可能性。
虚幻引擎5(UE5)通过引入神经网络引擎(NNE)向这一目标迈进了一大步。NNE作为一个抽象层,能够统一多种后端的推理工作负载。开发者可以在GPU上使用多种运行时,也可以根据可用硬件回退到CPU,从而在实时图形工作流中无缝集成神经网络功能。
本博文介绍了添加 NVIDIA TensorRT for RTX 作为 NNE 运行时选项 (NNERuntimeTRT) 的新插件,该插件可在 NVIDIA RTX GPU 上实现高效推理。为了展示其优势,我将使用一个运行后处理 AI 模型的简化 UE 项目来突出显示相较于其他 GPU 运行时 (如 DirectML) 的收益。
首先,我们来简要讨论一下项目中涉及的不同组件。
TensorRT for RTX 概述
TensorRT for RTX 使用户能够在 RTX GPU 上更高效地部署 AI 模型。它在运行时环境中使用即时 (JIT) 优化器来生成针对用户 GPU 的定制推理引擎。此编译在用户的机器上执行一次,并针对其特定硬件优化模型。
因此,与默认执行提供程序相比,TensorRT for RTX 能够实现更高的吞吐量。例如,在不同模型间的吞吐量对比中,使用 TensorRT for RTX 相较于使用 DirectML(在 NVIDIA GeForce RTX 5090 GPU 上测得)表现出性能提升。
从 Turing 架构 (计算能力 7.5) 到 NVIDIA Blackwell 架构 (计算能力 10.0) ,TensorRT for RTX 仅与 NVIDIA RTX GPU 兼容。
虚幻引擎神经网络引擎概述
NNE 支持多个运行时,用于调用推理任务以及在 CPU 和 GPU 之间进行选择。TensorRT for RTX 适用于 GPU,本概述重点介绍 NNE GPU 运行时。
神经网络 (NNE) 可以在 GPU 上运行推理,具体如下:
- 从 CPU 同步,需要内存同步。
- 异步通过* 渲染依赖图 (RDG) ,与帧渲染保持一致。
这种同步方法非常适合编辑器和基于事件的推理任务 (如 LLM) ,无需在主机和设备之间复制数据。相比之下,RDG 将模型评估与渲染资源联系在一起,使其成为 AI 后处理、放大或降噪的理想选择。
适用于 RTX 的 NNE TensorRT 插件支持 GPU 和 RDG 方法,可为渲染、动画、语言和语音等各种 AI 应用提供灵活性,同时在消费级设备上保持强劲性能。
风格迁移后处理示例项目
我构建了一个基本的 UE5 项目来测试 NNE TensorRT for RTX 插件,该插件可在后处理期间应用风格迁移模型。在测试方面,我使用一些基本基元和固定摄像头设置了一个简单的关卡,以便在 DirectML 和 TensorRT 之间切换时保持视觉效果的一致性,从而更容易比较结果和性能。
预备知识
虽然该项目即将投入使用,但建议您具备 UE5、后处理材质和引擎源代码编译方面的经验。
要运行风格迁移推理和管理渲染资源,您需要 NNE 实现。UE5 通过神经后处理插件提供了这一点,该插件通过 RDG 在 GPU 上执行推理。在此项目中,我们将使用 NNERuntimeTRT RDG 方法。
只需训练或下载合适的风格模型即可。我们将使用 ONNX Zoo 提供的预训练模型。
项目已包含导入的模型 (candy-9-720.uasset) 。
项目设置
尽管适用于 RTX 的 NNE TensorRT 插件与启动器提供的 5.7 二进制引擎版本兼容,但神经后处理插件在其神经配置文件资产中包含硬编码的运行时列表。有必要更新其代码,以便将 NNERuntimeTRT 包含在神经配置文件资产的可用运行时列表中。
开始使用:
- 从 GitHub 获取引擎源代码。
如果您是首次访问引擎代码库,需要先将您的 GitHub 账户与 Epic 账户进行关联。请阅读 以下文档,了解访问引擎代码库的具体流程:
- 完成初始引擎设置后,您将获得一个 Visual Studio 解决方案。请打开该解决方案,并依次导航至“Engine”(引擎)→“Source”(源代码)→“Runtime”(运行时)→“Engine”(引擎)→“Classes”(类)→“Engine”(引擎),找到其中的
neuralprofile.h/cpp文件。 Engine\Source\Runtime\Engine\Classes\Engine - 在
neuralprofile.h中,将NNERuntimeTRT添加到ENeuralProfileRuntimeType(第 59 行) ,如下所示:
UNNERuntimeRDGTensorRT UMETA(DisplayName = "NNERuntimeTRT"),
4. 完整的枚举类应如下所示:
UNNERuntimeRDGTensorRT UMETA(DisplayName = "NNERuntimeTRT"), UENUM(BlueprintType)
enum class ENeuralProfileRuntimeType : uint8
{
NNERuntimeORTDml UMETA(DisplayName = "NNERuntimeORTDml"),
/** Does not have full operator support*/
NNERuntimeRDGHlsl UMETA(DisplayName = "NNERuntimeRDGHlsl"),
UNNERuntimeRDGTensorRT UMETA(DisplayName = "NNERuntimeTRT"),
MAX UMETA(Hidden)
};
5. 在 neuralprofile.cpp 中,找到 GetNeuralProfileRuntimeName 并将其添加到 kRuntimeNames 数组中 (第 28 行) :
,TEXT("NNERuntimeTRT")
6. 完整的 kRuntimeNames 数组应为:
static const TCHAR* const kRuntimeNames[] = {
TEXT("NNERuntimeORTDml"),
TEXT("NNERuntimeRDGHlsl"),
TEXT("NNERuntimeTRT")
};
- 从 插件 获取 Fab 或 NVIDIA 开发者页面。
- 解压此路径中引擎插件文件夹下的插件:… 引擎插件运行时 NVIDIA
您也可以在项目中放置插件,但就我们而言,将其放在引擎插件下会更简单。 - 构建引擎。使用这些详细说明编译引擎。第一次编译需要时间,所以可以考虑休息一下或喝杯咖啡。
- 开始使用示例项目。
- (
LVL_PPStyleTest)
- (

性能分析
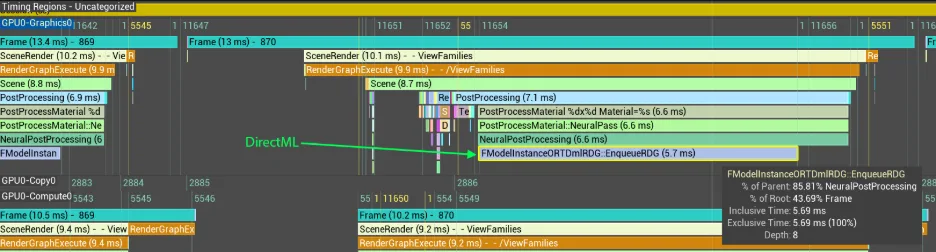
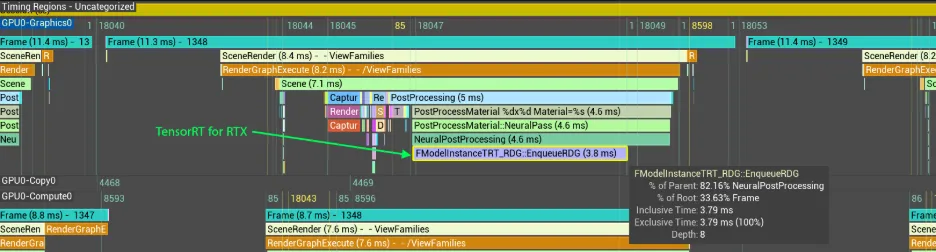
测试时,启用引擎统计信息,并在 TensorRT for RTX(TRT)与 DirectML(DML)之间切换,以评估性能提升。如需更全面的分析,可使用 Unreal Insights 捕获帧信息及 DML 与 TRT 的详细性能分解。
在采用 NVIDIA GeForce RTX 5090 D GPU、1080p 分辨率的系统上,在 Unreal Insights 中,DML 需要 5.7 毫秒,而 TRT 只需 3.8 毫秒即可完成,性能提高了 1.5 倍。
使用其他风格迁移模型
您可以使用 ONNX Zoo 中的任何风格迁移模型,也可以训练自己的模型。请注意,ONNX Zoo 模型的输入和输出张量的维度固定为 1x3x224x224。神经过程插件可将小型模型平铺到更大的帧缓冲区。虽然这会提供视觉上可接受的结果,但不建议这样做,因为每帧会生成多个推理任务,导致 NVIDIA CUDA 和图形之间频繁进行上下文切换。为避免多个上下文切换产生额外开销,请将模型维度更改为 1x3x720x720,以便在不平铺的情况下运行推理,同时保持良好的视觉质量。
在示例项目库中,我包含一个 Python 脚本,用于调整风格迁移 ONNX 模型的输入和输出张量维度。
有关使用 NNE 构建自己的 AI 应用的更多信息,请参阅 官方文档