
NVIDIA GB200 NVL72 通过在整个机架范围内扩展 NVIDIA NVLink 一致性,开创了一种全新的 GPU 集群构建方式。该设计不仅实现了百亿亿次级的计算性能,也打破了现有许多调度系统所依赖的传统假设。
因此,“机架级局部性”成为了一个硬性限制。当工作负载跨越域边界时,性能会急剧下降,如果调度程序将网络结构视为尽力而为的树状拓扑,则会以增加队列时间和降低应用程序性能的方式分散分配。
为解决这一问题,Slurm 工作负载管理器引入了拓扑/块插件,并通过分段调度进一步扩展其功能。该插件使管理员和用户能够将应用程序特定的 NVLink 需求表示为原子块,而不是松散优化的资源分配。
本文将介绍 NVIDIA GB200 NVL72 架构的独特设计,Slurm 块调度如何优化资源放置与性能表现,以及如何配置 topology.yaml、--segment 及相关功能,帮助您顺利从原型集群过渡到生产级机架规模的集群编排。
NVIDIA GB200 NVL72 架构有何独特之处?
NVIDIA GB200 NVL72 是一款安装在单个机架中的百亿亿次级计算机,代表了 GPU 集群设计的新范式。此前的服务器在单个机箱内使用 NVIDIA NVLink,而 GB200 NVL72 则將一致性显存域扩展至整个机架:72 块 NVIDIA Blackwell GPU 分布于 18 个计算托盘,通过第五代 NVLink 实现统一互联。
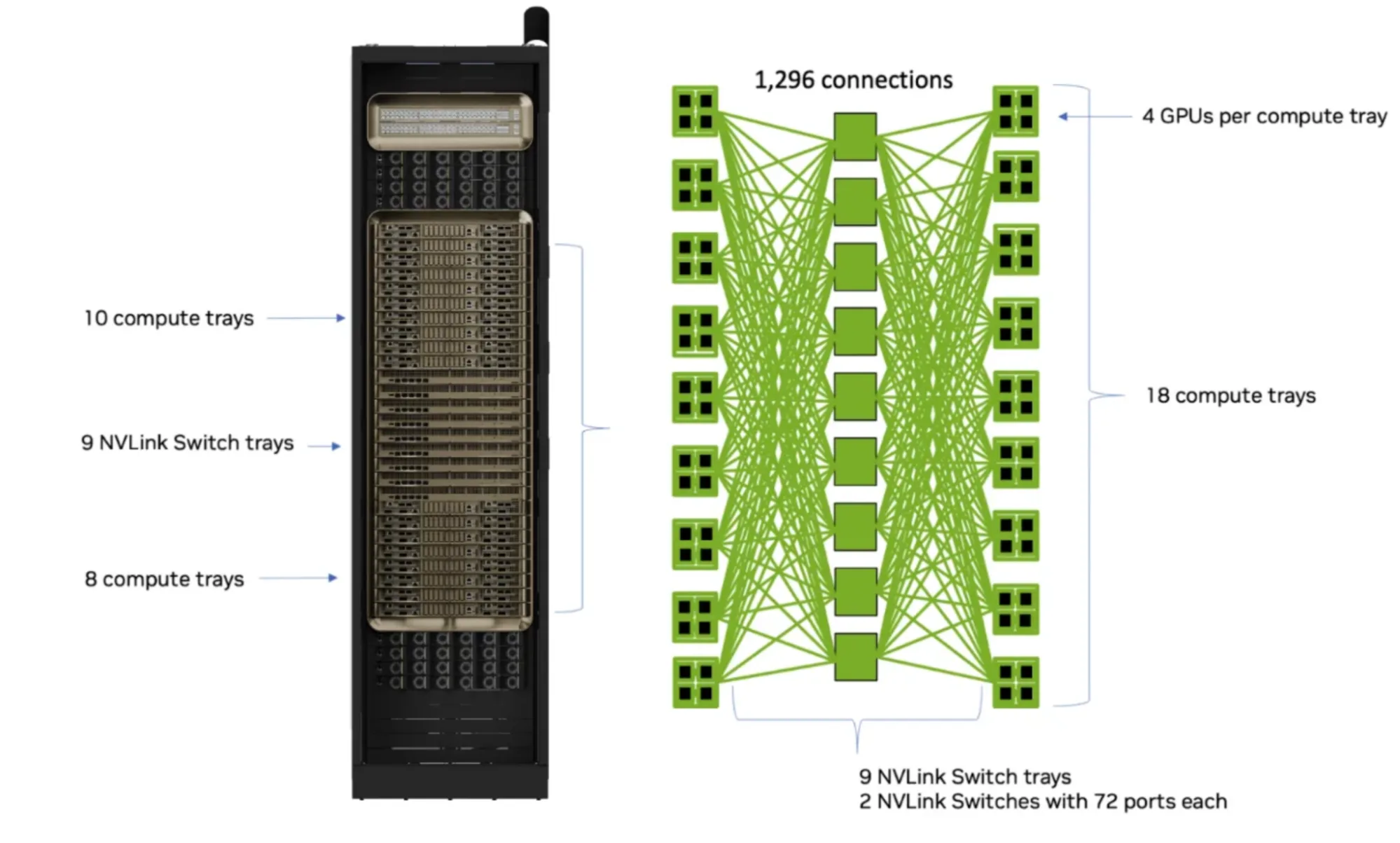
机架内的所有通信均以 NVLink 速度运行:NVIDIA GB200 NVL72 可为每个 GPU 提供 1.8 TB/s 的双向吞吐量,总计 130 TB/s 的总带宽。跨域通信边界面临着大幅的性能下降,通常是通过 InfiniBand 或以太网实现 50 GB/s (400 Gb/s) 的性能下降。
大规模运行 GB200 NVL72 集群需要新的工作负载调度算法,以将 NVLink 域视为作业的硬边界。虽然这些新算法对于高效的工作负载至关重要,但它们也需要围绕系统碎片化的管理意识。拓扑/ 块 Slurm 插件可帮助用户和管理员同时使用这两种功能。
如何在 Slurm 中进行块调度?
Slurm 长期以来一直支持拓扑感知型作业调度:拓扑/ 树插件一直是大规模集群的标准插件。它将网络计算结构建模为交换机和节点的层次树。虽然拓扑/ 树的主要目标是尽可能减少作业所涵盖的交换机数量,但这是一项尽力而为的尝试。为了更快开始,这项工作最终可能会在各个 Leaf 交换机之间严重分散。
对于使用连接所有计算节点的 InfiniBand 结构的集群,这种权衡是有意义的。跨多个 Leaf 交换机的作业拆分的运行速度可能比在单个 Leaf 交换机下运行的速度稍慢,但通常认为可以接受在开始时间和性能之间权衡取舍。
GB200 NVL72 和 GB300 NVL72 的推出需要一种新的方法。在 NVIDIA 和 SchedMD 的共同努力下,Slurm 23.11 版本中引入了新的拓扑/ 块插件,以支持 GB200 NVL72 等机架级架构。
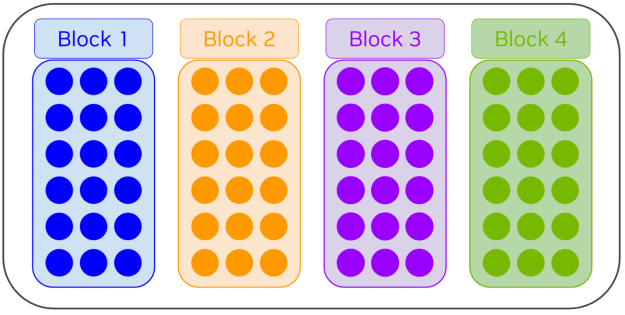
如果作业提交的分配请求适合单个块 ( 18 个或以下节点) ,则系统将始终从一个块分配节点,且作业不会碎片化。
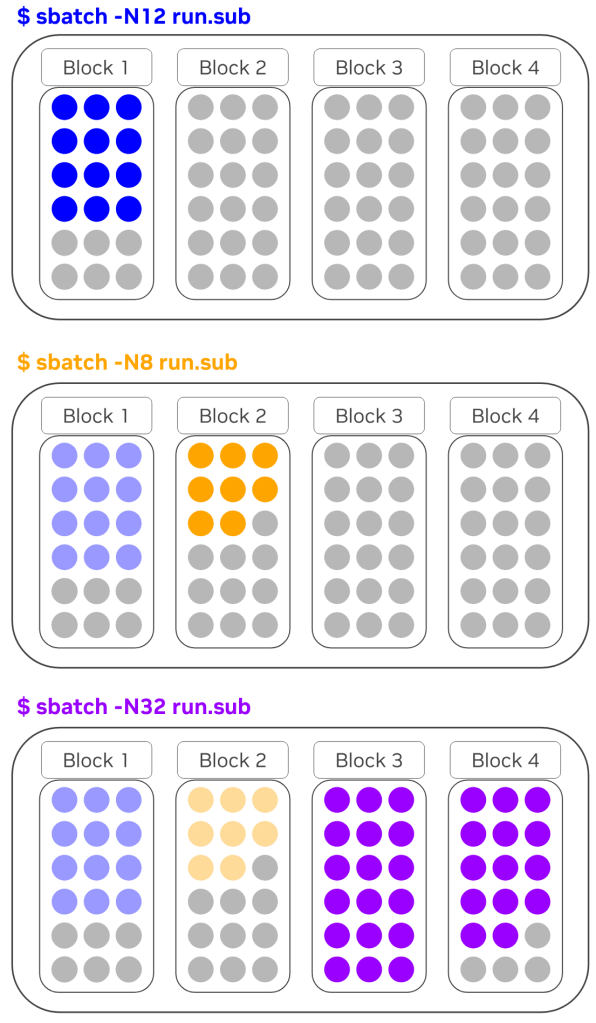
-N12, -N8, -N32) ,展示了如何在默认调度下跨块分配节点在默认行为为拓扑/ 块的情况下,请求 16 个节点的作业会强制调度程序等待具有 16 个空闲节点的单个多节点 NVLink 域。这可能会导致作业排队时间增加。实际上,应用程序的 NVLink 连接要求可能小于完整的 NVL72 域。
为使用户能够将其应用的拓扑要求传达给作业调度程序,Slurm 为拓扑/ 块作业引入了 --segment 参数。它充当一个旋钮,定义必须放置在同一块中的节点原子组,并有助于平衡调度器效率与应用程序的实际硬件局部性要求。
通过修改此参数,您可以显著缓解调度限制。例如,请求 12 个节点但指定 --segment=4 的作业可以拆分成三个单独的块。如果没有 --segment=4,这项新作业将无法运行,因为不存在具有 12 个节点的单一块。
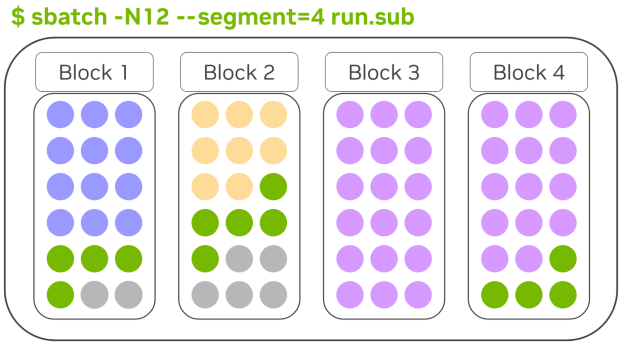
-N12 --segment=4) ,展示了如何在多个块之间分割作业Slurm 块调度如何优化性能?
Slurm 可以将同一作业的多个部分分配给同一区块,这一事实经常令用户感到惊讶。
分段的使用对于根据工作负载的特定局部性需求优化性能至关重要:张量并行(TP)可能需要较小且更紧凑的分段,以便在高速 NVLink 架构上维持对延迟敏感的通信;而专家并行(EP)则可能需要更大的分段尺寸,以确保 all-to-all 集合操作始终在单个网络内完成。
使用较大的段值(如 --segment=16)也能实现节点在各块之间的均衡分配。图 4 显示,32 个节点被划分为块 3 上的 18 个节点和块 4 上的 14 个节点;而采用 --segment=16 后,可确保每个块上恰好有 16 个节点,如图 5 所示。
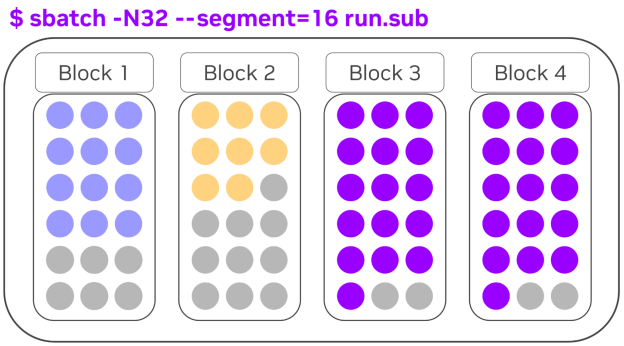
-N32 --segment=16) 显示节点在块之间的均匀分布Slurm 25.11 中引入的命令行参数 --consolidate-segments 和 --spread-segments 使用户能够影响片段的位置。
如何配置 Slurm 块调度
对于拓扑/ 块,我们建议 Slurm 管理员为集群中的每个 GB200 NVL72 域 ( 18 个节点) 定义一个块。对于小于 18 个节点且未指定 --segment 的作业,Slurm 不会跨块边界分割分配。相反,它会将作业一直排在队列中,直到集群中有足够的资源可用。
这保证了为此作业分配的所有节点都能够与 NVLink 通信,无论集群的当前状态如何,都能提供一致的性能。对于大于 18 个节点且未指定 --segment 的作业,Slurm 将以所需的最小块数量来拟合分配。
建议使用 topology.yaml 文件来配置拓扑或块,这是 Slurm 25.05 版本引入的功能。例如,若要定义两个 GB200 NVL72 域,可使用以下脚本:
---
- topology: gb200-nvl72
cluster_default: true
block:
block_sizes:
- 18
blocks:
- block: block01
nodes: node[0001-0018]
- block: block02
nodes: node[0019-0036]
Slurm 拓扑/ 块插件支持多层分层分组,其中第一层是 NVL72 域,而较高层次的块可以反映计算结构设计的物理现实,例如穿过数据中心行或数据中心大厅时的性能影响。
对于采用全棵胖树结构进行计算的 GB200 NVL72 集群,建议在多节点 NVLink 域中仅使用单层 Slurm 分区,因为跨叶交换机的性能上限低于跨 NVLink 域的性能上限。最小可调度单位为单个节点(四个 GPU)。 fat-tree for the compute fabric
可以使用以下命令验证 Slurm 创建的块拓扑:
$ scontrol show topology
BlockName=block01 BlockIndex=0 Nodes=node[0001-0018] BlockSize=18
BlockName=block02 BlockIndex=1 Nodes=node[0019-0036] BlockSize=18
为了充分受益于新功能,并提交应用程序可以从新增拓扑要求中受益的作业,集群用户希望提交具有 --segment 参数的作业,该参数现已在集群管理级别启用。当仅需要跨四个 GPU (一个节点) 使用 NVLink 时,应使用 --segment=1,因为这样可以更大限度地提高调度程序的放置灵活性。
建议使用 --segment=18 而非 --segment=16. 这能为 Slurm 提供更多机会来耗尽或下线节点块。集群管理员还可通过拒绝不符合集群规范的作业,将策略从指导转为强制执行,这一功能可通过简单的 cli_filter/lua 脚本实现:
function slurm_cli_pre_submit(options, pack_offset)
if options["segment"] == "18" then
slurm.log_error("error: using --segment=18 is currently not allowed.")
return slurm.ERROR
end
return slurm.SUCCESS
end
function slurm_cli_setup_defaults(options, early_pass)
return slurm.SUCCESS
end
function slurm_cli_post_submit(offset, job_id, step_id)
return slurm.SUCCESS
end
$ srun -N18 --segment=18 hostname
srun: error: lua: error: using --segment=18 is currently not allowed.
srun: error: cli_filter plugin terminated with error
如何配置 NVIDIA IMEX
除了配置块调度外,还需确保在 Slurm 中正确设置适用于 NVLink 网络的 NVIDIA IMEX 服务,以实现同一多节点 NVLink 域内作业间的驱动级隔离。
要在 NVLink 域中的节点之间启用 GPU 显存导入和导出,必须在集群的所有计算节点上启动 NVIDIA IMEX 服务。当 IMEX 配置文件为静态文件时,推荐的方法是在启动时启动 nvidia-imex systemd 服务,并在所有 Slurm 作业中保留相同的服务实例。
建议启用 switch/nvidia_imex 插件(Slurm 24.05 版本引入),以支持 Slurm 为每个作业管理 IMEX 通道 分配。该功能可实现作业间的驱动级隔离,避免意外干扰。启用方法:在 slurm.conf 中添加以下配置行:
SwitchType=switch/nvidia_imex
通过这种方法,IMEX 服务和通道管理无需在 Slurm Prolog 和 Epilog 脚本中自定义逻辑。
有哪些拓扑/ 线程块高级功能?
拓扑/ 块插件首次发布后,NVIDIA 一直与 Slurm 社区密切合作,引入新功能,以便更好地控制拓扑/ 块插件的行为。
从 Slurm 25.05 开始,您现在可以在 Slurm 拓扑文件中声明不完整块 (节点少于定义块大小的块) 。您甚至可以将一个完全没有节点的块声明为占位符。当域中的所有节点尚未联机时,这在集群的早期阶段很有用。从 Slurm 24.05 开始,还可以声明域中的备用节点:只需列出超过定义块大小的节点即可。
topology.yaml 文件的引入消除了传统方法的一个主要限制:现在可以在 Slurm 集群上同时使用多个拓扑插件,并为每个 Slurm 分区关联不同的拓扑插件。利用此功能为集群管理员定义了一种绕过拓扑/ 块插件进行故障排除的方法。这是通过在 topology.yaml 中定义“平面”拓扑来实现的:
- topology: gb200-flat
cluster_default: false
flat: true
然后,将此拓扑关联到 slurm.conf 中的管理员专用分区:
PartitionName=admin-flat AllowAccounts=admin Default=NO Nodes=nodes[0001-0036]
Hidden=YES Topology=gb200-flat
分段大小对节点可用性有什么影响?
为了研究适当设置 --segment 的重要性,可以使用简化的数学模型来演示段大小对给定作业的有效可用集群容量的影响。管理员需要了解分段大小会如何影响节点可用性。
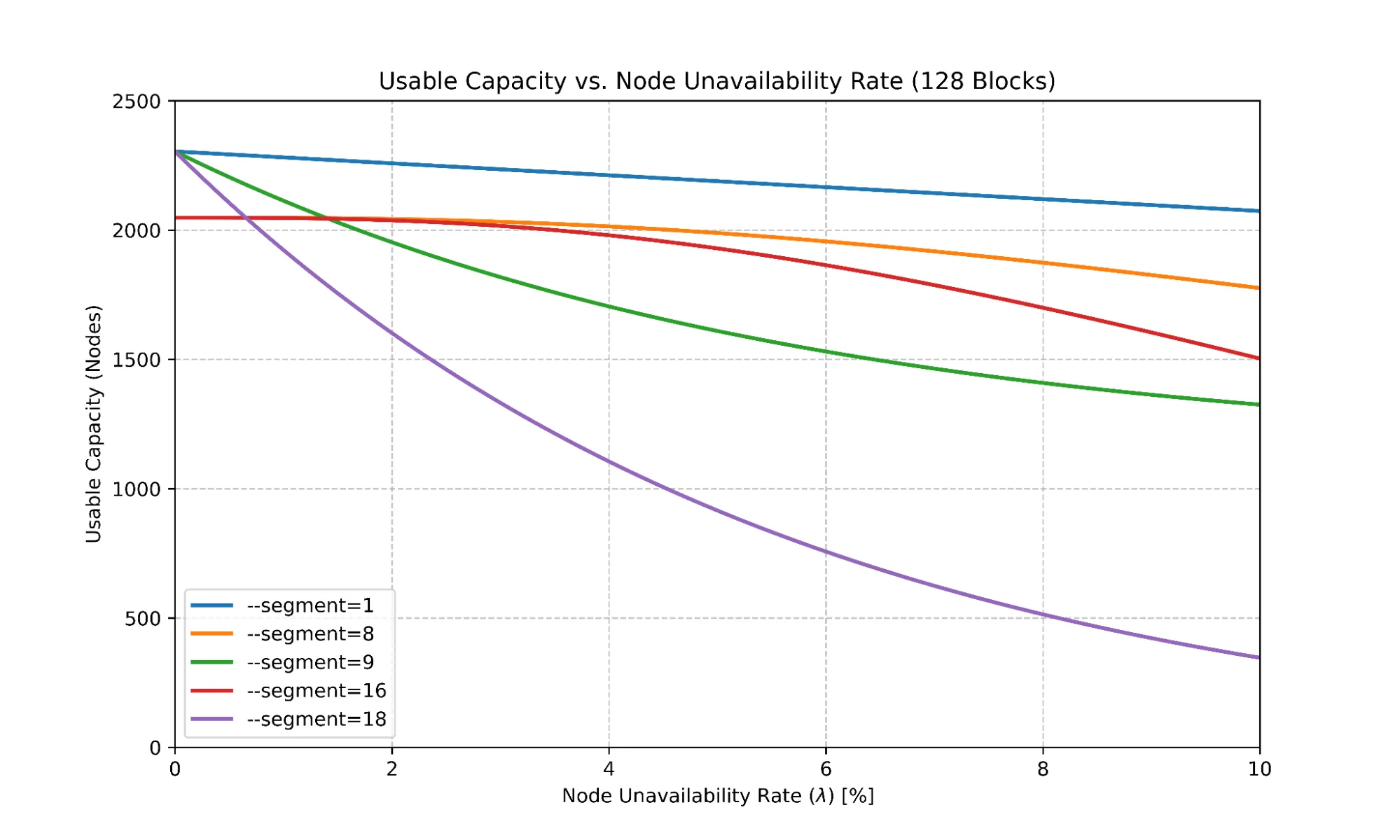
--segment 作为不可用率时,对可用集群容量的影响* 增加您还可以观察到 --segment=9 的影响:随着节点不可用率* 的上升,预期可用容量会迅速下降,因为只要有一个节点不可用,该域对使用 --segment=9 的作业就只能提供 9 个节点。而对于 --segment=16,只要不可用节点少于三个,该域仍可提供 16 个节点。
开始优化您的机架级架构
机架级架构是 AI 计算的未来,NVIDIA Blackwell GB200 NVL72 是该设计的首次迭代,因为技术正在转向更大的领域规模。软件基础架构需要不断发展以支持这种新范式。Slurm 拓扑/ 块插件提供了继续与 Slurm 社区合作的基础和承诺,使其更易于大规模部署、理解、优化和运营。
准备好优化您的机架级资源编排了吗?请查阅 Slurm topology.yaml 文档 和 NVIDIA MNNVL 用户指南,开始在 Blackwell 集群上实施块调度。