
将量化检查点转换为 NVIDIA TensorRT 引擎可以弥合模型优化与生产部署之间的差距,从而实现更快的推理速度、更高的吞吐量和更高效的 GPU 大规模利用率。
在上一篇文章中,我们使用 NVIDIA TensorRT Model Optimizer 生成了高质量的 FP8 量化对比语言图像预训练 (CLIP) 检查点。
本文将介绍我们中断的部分,介绍如何将检查点导出到 ONNX,并将其编译成 NVIDIA TensorRT 引擎,以便进行生产推理。我们还根据 FP16 基准分析生成的 FP8 TensorRT 引擎,以测量量化模型在现实世界中的加速效果。
图 1 显示了典型的端到端量化工作流程的五个阶段。这是部署量化 CLIP 模型的标准工作流。量化 LLM 通过 TensorRT-LLM 遵循不同的路径,本教程将对此进行介绍。

将模型导出为 ONNX 格式
第一步是将 ModelOpt 检查点导出到 ONNX。以下伪代码使用 Modelopt 的内置辅助程序针对 FP8 量化 CLIP 检查点执行此操作 (导出目标是 ONNX opset 20%,其中完全支持 FP8 QuantizeLinear/ DequantizeLinear) 。它将每个权重侧量化 – 然后量化 (Q-DQ) 对折叠到一个仅由 FP8 存储的 DQ 链中,显著缩小了 ONNX 文件。
原则上,原生 torch.onnx.export 也可以正常工作,但需要我们编写自定义转换脚本。
import torchfrom transformers import CLIPModel, CLIPTokenizerfrom transformers.models.clip.modeling_clip import CLIPAttentionimport modelopt.torch.opt as mtoimport modelopt.torch.quantization as mtqfrom modelopt.torch._deploy.utils import OnnxBytes, get_onnx_bytes_and_metadatafrom modelopt.torch.quantization.plugins.diffusion.diffusers import _QuantAttention# Thin wrappers expose a single forward to the ONNX exporterclass TextEncoder(torch.nn.Module): def __init__(self, m): super().__init__(); self.m = m def forward(self, x): return self.m.get_text_features(x)class ImageEncoder(torch.nn.Module): def __init__(self, m): super().__init__(); self.m = m def forward(self, x): return self.m.get_image_features(x)def prepare_for_fp8_onnx_export(model): # 1) turn on FP8 attention fusion (off by default, lost on reload). # 2) clear CLIP's float `scale` — exporter chokes on it. for _, mod in model.named_modules(): if isinstance(mod, _QuantAttention): mod._disable_fp8_mha = False if isinstance(mod, CLIPAttention) and getattr(mod, "scale", None) is not None: mod.scale = Nonedef export(wrapper, dummy, axis_name, out_name): """ModelOpt's exporter folds Q+DQ on weights into FP8-stored DQ-only chains and rewrites TRT custom ops to native ONNX QDQ — output is TRT-ready.""" onnx_bytes, _ = get_onnx_bytes_and_metadata( model=wrapper, dummy_input=(dummy,), model_name=out_name, dynamic_axes={axis_name: {0: "batch"}}, onnx_opset=20, weights_dtype="fp16", ) OnnxBytes.from_bytes(onnx_bytes).write_to_disk("./onnx_output", clean_dir=False)# Restore the FP8-quantized CLIPModel from the ModelOpt checkpointmto.enable_huggingface_checkpointing()mtq.QuantModuleRegistry.register({CLIPAttention: "CLIPAttention"})(_QuantAttention)model = ( CLIPModel.from_pretrained(modelopt_ckpt, attn_implementation="sdpa", torch_dtype=torch.float16) .eval().cuda())prepare_for_fp8_onnx_export(model)# Export Text encoder to ONNXtok = CLIPTokenizer.from_pretrained(model_ckpt)dummy_text = tok(["a photo of a cat"], return_tensors="pt", padding="max_length", max_length=77)["input_ids"].cuda()export(TextEncoder(model), dummy_text, "text_input", "text_clip_fp8")# Export Image encoder to ONNX dummy_image = torch.randn(16, 3, 224, 224, dtype=torch.float16).cuda()export(ImageEncoder(model), dummy_image, "image_input", "image_clip_fp8") |
| 模型组件 | FP8 Modelopt 检查点 | FP16 HuggingFace 检查点 | 尺寸缩小 |
| CLIP 文本编码器 ONNX | 156 MB | 237 MB | 增加 34% |
| CLIP 图像编码器 ONNX | 292 MB | 582 MB | 增加 50% |
表 1 比较了 FP8 ModelOpt 检查点导出的 ONNX 文件大小与原始 FP16 HuggingFace 检查点导出的 ONNX 文件大小。FP8 检查点文件导出会生成更小的 ONNX 文件,其中文本编码器的文件大小约为 34%,图像编码器的文件大小约为 50%。
请注意,压缩 ONNX 文件是一种方便,而非必要条件。TensorRT 会在引擎构建时将权重侧 Q 节点折叠到 FP8 权重中。ModelOpt ONNX 导出工具会在 ONNX 侧折叠之前的内容,以减小磁盘上的文件。
我们可以使用 NVIDIA Nsight 深度学习设计器,用于 ONNX 模型编辑、性能分析和 TensorRT 引擎构建的高效工具 检查导出的 ONNX 文件。
图 2 显示了在 Nsight Deep Learning Designer 中可视化的导出 ONNX 图形的一部分。我们可以看到,该图现在包含 QuantizeLinear/ DequantizeLinear (Q/ DQ) 节点,标记了 FP8 边界。
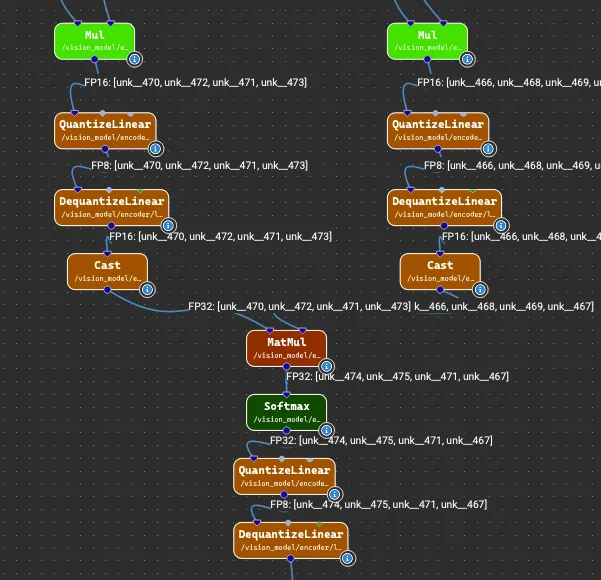
在构建引擎期间,TensorRT 会将这些节点与相邻层融合,以优化推理性能。这种融合消除了不必要的量化 – 再量化 – 量化转换,支持使用优化的 FP8 内核进行计算。
使用 TensorRT 分析 ONNX 模型
导出 FP8 ONNX 模型后,下一步是将其传递给 TensorRT 并测量其运行速度。在开始之前,请按照本教程的操作,确保正确下载并安装 TensorRT。准备就绪后,我们将使用 trtexec (TensorRT 命令行包装器) ,使用以下命令对 ONNX 模型进行基准测试:
# Set up the TensorRT environmentexport PATH=<TensorRT-${version}/bin>:$PATHexport LD_LIBRARY_PATH=<TensorRT-${version}/lib>:$LD_LIBRARY_PATH# Benchmark the ONNX model with trtexectrtexec --onnx=text_clip_fp8.onnx \ --shapes=text_input:128x77 \ --stronglyTyped \ --saveEngine=text_clip_fp8.plantrtexec --onnx=image_clip_fp8.onnx \ --shapes=image_input:128x3x224x224 \ --stronglyTyped \ --saveEngine=image_clip_fp8.plan |
--onnx指定 TensorRT 用于构建引擎的输入 ONNX 模型。--shapes会固定输入形状,以便 TensorRT 针对该确切大小构建经过优化的引擎。--stronglyTyped强制 TensorRT 遵守 ModelOpt 烘焙到 ONNX 图形中的精度标注,确保 FP8 权重和激活函数在 FP8 中实际执行。--saveEngine将构建的 TensorRT 引擎写入磁盘,以便以后重用,无论是用于独立的 TensorRT 推理运行时,还是通过 NVIDIA Triton 推理服务器 提供服务 (请参阅此示例 )。
需要注意的是:ModelOpt 的导出器将注意力缩放封装在 FP32 往返行程中,而 --stronglyTyped 会拒绝 (您可能会看到 Float vs Half 类型不匹配错误) 。在进行 trtexec 基准测试之前,我们投射这些缩放常量,并将运算结果投射回 FP16,以获得清晰、强类型的引擎。
# Re-type all FP32 initializers and Cast(to=FP32) ops in the FP8 ONNX to FP16.import numpy as npimport onnxfrom onnx import TensorProto, numpy_helper, shape_inferencemodel = onnx.load("clip_fp8.onnx")for init in model.graph.initializer: if init.data_type == TensorProto.FLOAT: arr = numpy_helper.to_array(init).astype(np.float16) init.CopyFrom(numpy_helper.from_array(arr, name=init.name))for node in model.graph.node: if node.op_type == "Cast": to_attr = next(a for a in node.attribute if a.name == "to") if to_attr.i == TensorProto.FLOAT: to_attr.i = TensorProto.FLOAT16model = shape_inference.infer_shapes(model, data_prop=True, check_type=False)onnx.save(model, "clip_fp8_strongtyped.onnx") |
或者,我们还可以按照官方用户指南中的性能分析部分,使用 Nsight Deep Learning Designer 使用 TensorRT 分析 ONNX 模型。请参考官方用户指南。
我们使用 trtexec 命令在 TensorRT 10.16 的 NVIDIA RTX 6000 Ada GPU 上运行基准测试,静态批量大小为 128。每个报告的延迟是默认测量窗口内所有推理迭代的中值。请注意,FP8 仅适用于 Ada 及更高架构 (计算能力 8.9 或更高) 上的矩阵乘法 (GEMM) 。如需详细了解哪些 GPU 支持哪些数据类型,请参阅 TensorRT 支持矩阵。
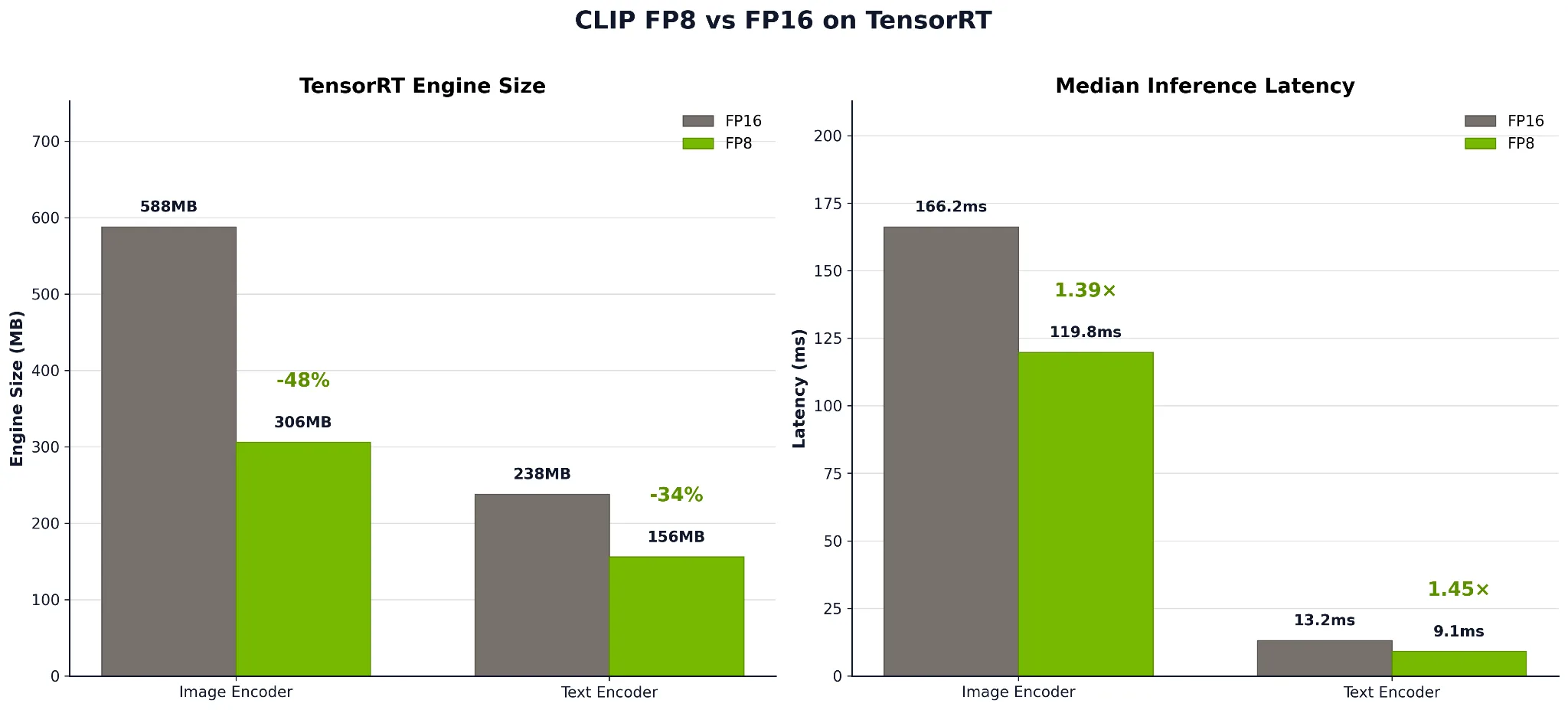
图 3 显示了在 TensorRT 引擎大小和推理延迟方面,FP8 量化相较于 FP16 的优势。左侧的图像编码器从 588 MB 缩小到 306 MB (减少 48%) ,文本编码器从 238 MB 缩小到 156 MB (减少 34%) ,将磁盘总占用空间减少近一半。由于较小的引擎需要更少的内存来加载和运行,因此在推理时,GPU VRAM 的使用也节省了同样的成本。
在右侧,延迟案例同样引人入胜。图像编码器从 166.2 毫秒降至 119.8 毫秒,文本编码器从 13.2 毫秒降至 9.1 毫秒,图像和文本的速度分别提高了 1.39 倍和 1.45 倍。
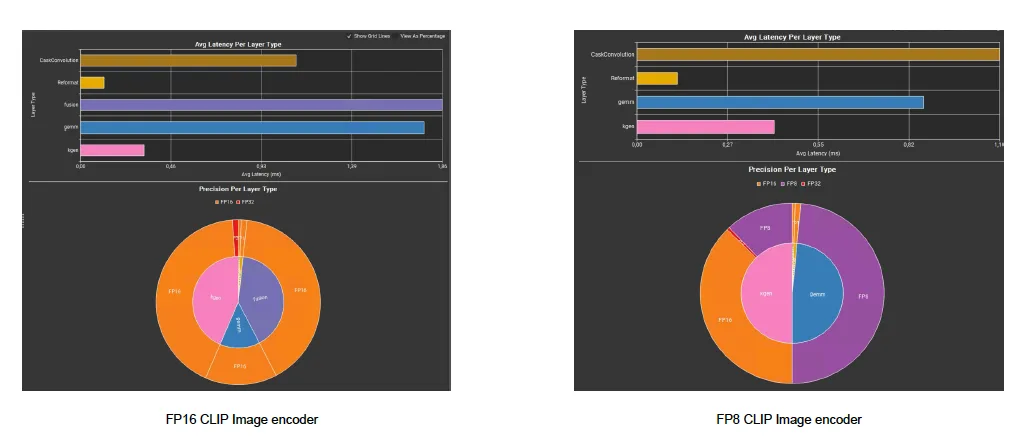
FP8 加速究竟来自哪里?除了原始数据 trtexec 报告之外,Nsight Deep Learning Designer 还提供了更丰富的视觉分解,为我们提供了一个清晰的答案。
图 4 将 FP16 和 FP8 图像编码器配置文件并排放置,其中有三个区别显而易见。
- GEMM 柱形图从约 1.8 毫秒降至 0.84 毫秒,在主要的 Matmul 层 (由 NVIDIA RTX 6000 Ada GPU 的 FP8 Tensor Core 内核提供) 上,速度提升了 2 倍以上。
- FP16 配置文件中可见的“融合”层类别在 FP8 配置文件中消失了,因为 TensorRT 现在通过专用的 FP8 MHA 内核来路由整个注意力块,并生成更精简的执行路径。
- 精确的甜甜圈会从橙色为主 (FP16) 的图形转变为紫色为主 (FP8) 的图形。这些信号证实了我们的量化权重和激活函数在 FP8 Tensor Core 上运行,这正是 FP8 增益的来源 — — 在每个矩阵密集型步骤中,更高的计算吞吐量和更低的内存带宽占用。
量化在 TensorRT 中的工作原理
导入 ONNX 模型时,TensorRT 会查找 QuantizeLinear/ DequantizeLinear (Q/ DQ) 节点,这些节点会标记图中张量在全精度和低精度数据类型 (如 FP8) 之间转换的点。
在内部,TensorRT 要求每个可量化层的每个输入都有一个 Q/ DQ 层对。在引擎构建时,优化器将这些 Q/ DQ 节点融合到其相邻层中,并将原始层替换为直接在低精度张量上运行的专用内核。这消除了往返量化 – 再 – 去量化过渡,并使引擎能够以更高的计算吞吐量和更低的内存带宽执行任务。
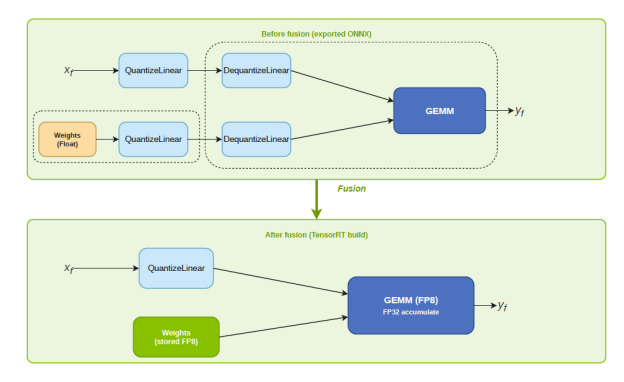
图 5 显示了 FP8 GEMM 的这种转换。在导出的 ONNX 中,激活 \(x_f\) 和权重张量都封装在 QuantizeLinear/ DequantizeLinear 对中,在 TensorRT 的优化器融合它们后,剩下的是单个 FP8 GEMM 内核,该内核直接接受 FP8 量化激活和预存储的 FP8 权重张量。
如需深入了解 TensorRT 量化机制,请参阅文档。
开始使用
在本文中,我们介绍了用于部署量化模型的完整 ModelOpt → ONNX → TensorRT 工作流。我们使用 Q/ DQ 节点将 CLIP 检查点导出到 ONNX,构建了 TensorRT 引擎,并使用 trtexec 和 Nsight 深度学习设计器根据 FP16 基准对其进行了基准测试。
结果表明,与 RTX 6000 Ada GPU 上的原始 FP16 模型相比,FP8 量化可显著提高速度和显存占用。我们还简要介绍了 TensorRT 如何在构建时将 Q/ DQ 节点融合到专用的低精度内核中,从而实现这些收益。
试用 NVIDIA Model Optimizer 和 NVIDIA TensorRT,探索模型量化可以带来的效率提升。